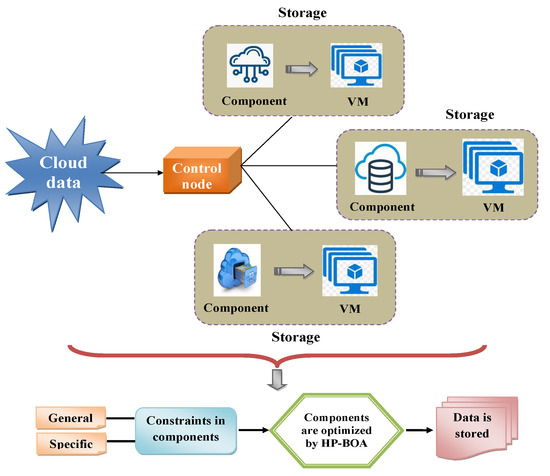
The prime objective of the cloud data storage process is to make the service, irrespective of being infinitely extensible, a more reliable storage and low-cost model that also encourages different data storage types. Owing to the storage process, it must satisfy the cloud users’ prerequisites. Nevertheless, storing massive amounts of data becomes critical as this affects the data quality or integrity. Hence, this poses various challenges for existing methodologies. An efficient, reliable cloud storage model is proposed using a hybrid heuristic approach to overcome the challenges. The prime intention of the proposed system is to store the data effectively in the cloud environment by resolving two constraints, which are general and specific (structural). The cloud data were initially gathered and used to analyze the storage performance. Since the data were extensive, different datasets and storage devices were considered. Every piece of data as specified by its corresponding features, whereas the devices were characterized by the hardware or software components. Subsequently, the objective function was formulated using the network’s structural and general constraints. The structural constraints were determined by the interactions between the devices and data instances in the cloud. Then, the general constraints regarding the data allocation rules and device capacity were defined. To mitigate the constraints, the components were optimized using the Hybrid Pelican–Billiards Optimization Algorithm (HP-BOA) to store the cloud data. Finally, the performance was validated, and the results were analyzed and compared against existing approaches. Thus, the proposed model exhibited the desired results for storing cloud data appropriately.
- cloud data storage
- cloud computing
- resource allocation
- virtualization
1. Introduction
| Author [Citation] | Methodology | Features | Challenges |
|---|---|---|---|
| Fan et al. [12] | CMPSO | • It provides highly secure and reliable resource allocation over wireless networks. | • It does not provide a fine-tuned strategy for accommodating connectivity. |
| • It has a low computational cost. | • The power consumption of the entire system is very high. | ||
| Li et al. [13] | ANC | • It is easy to implement with high network performance in terms of robustness and fidelity. | • This strategy is not flexible because of the changing channel qualities in wireless networks. |
| • The communication throughput is very high. | • It decreases the total response time of a user when the workload is high. | ||
| Assi et al. [14] | Tabu meta-heuristic |
• It meets the wireless requirements such as heterogeneity, reliability, and lowlatency. | • If an unexpected power outage occurs, the valuable data stored in the data center could be lost and unrecoverable. |
| • It provides high synchronization and updating of the data over wireless networks. | • It has a high cost for protectingthe cloud storage system. | ||
| Zaharie et al. [15] | OMT | • It provides automatic services when the customer requires more services over the network channel. | • It has a higher offloading failure probability; therefore, the transmission reliability is decreased. |
| • It can easily interface with the applications and data sources. | • It has less scalability in the search space. | ||
| Suba et al. [16] | EMSA algorithm |
• It is highly elastic, has a lower cost, and is trustworthy. | • It does not meet the bandwidth requirements and has a low maturity level. |
| • The information is quickly accessible by the users, and it is more reliable. | • It does not have any loop-back connectivity and access control. | ||
| • It has high, virtually limitless storage capacity. | |||
| Shao et al. [17] | PKI-based signature scheme |
• It provides greater hardware redundancy. | • The packet loss ratio is very high. |
| • It has the ability of automatic storage failover. | • The signal-to-noise ratio is very high during packet transmission. | ||
| Akash et al. [18] | ACO | • It achieves better performance by balancing the network load. | • It may result in large network delays, and it has a high overhead. |
| • It provides high security and integrity of the information over the network channel. | • The quality of service is low in terms of cost, security, and latency. | ||
| Sangeetha et al. [19] | Fibonacci cryptographic |
• It can handle the network traffic. | • It has a high consumption of network resources. |
| • It provides lowcomputational complexity. | • It has poornode authentication and a high transmission time. | ||
| • The caching ability is less. |
2. Reliable Cloud Data Storage: System Model and Problem Formulation
2.1. System Model
- 1
-
File storage: The files are hierarchically placed in this type. The information is stored in the metadata format of every file. Hence, the files are managed in higher-level abstraction types. Thus, it aids in improving performance.
- 2
-
Block storage: Here, the data or files are segmented into different chunks and represented with block addresses. This process does not contain the server for authorization.
- 3
-
Object storage: The encapsulation is performed with the object and metadata. Since the data belong to any type, they are distributed over the cloud. This also ensures the scalability and reliability of the system.
-
Data reliability and availability: By storing the data with more machines or servers, the data user can obtain the encoded data to be deciphered further as the original data. When any of the servers has a fault, they are then used by the other effective servers, thereby enhancing the data integrity and reliability of the cloud network.
-
Security: The better system enhances the security level. It also verifies the data integrity and confidentiality, which protects the network from any corrupted services.
-
Offline data owner: Once the data are outsourced to a server or machine, there is no need to check the integrity of the stored data in the system.
-
Efficiency: Due to this objective, the system’s efficacy is reached in terms of less storage space, resolving the overhead problem in communication and computation, and so on.