Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Shanran Tang | -- | 2215 | 2024-03-30 06:42:17 | | | |
| 2 | Catherine Yang | Meta information modification | 2215 | 2024-04-01 02:44:39 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Liu, K.; Peng, L.; Tang, S. Underwater Object Detection Using TC-YOLO with Attention Mechanisms. Encyclopedia. Available online: https://encyclopedia.pub/entry/56533 (accessed on 13 June 2026).
Liu K, Peng L, Tang S. Underwater Object Detection Using TC-YOLO with Attention Mechanisms. Encyclopedia. Available at: https://encyclopedia.pub/entry/56533. Accessed June 13, 2026.
Liu, Kun, Lei Peng, Shanran Tang. "Underwater Object Detection Using TC-YOLO with Attention Mechanisms" Encyclopedia, https://encyclopedia.pub/entry/56533 (accessed June 13, 2026).
Liu, K., Peng, L., & Tang, S. (2024, March 30). Underwater Object Detection Using TC-YOLO with Attention Mechanisms. In Encyclopedia. https://encyclopedia.pub/entry/56533
Liu, Kun, et al. "Underwater Object Detection Using TC-YOLO with Attention Mechanisms." Encyclopedia. Web. 30 March, 2024.
Copy Citation
Underwater object detection is a key technology in the development of intelligent underwater vehicles. Object detection faces unique challenges in underwater applications: blurry underwater images; small and dense targets; and limited computational capacity available on the deployed platforms. TC-YOLO, is an image enhancement technique using an adaptive histogram equalization algorithm, and the optimal transport scheme for label assignment.
object detection
underwater image
YOLOv5
coordinate attention
transformer
1. Introduction
Ocean exploration and exploitation have become commanding heights of the economy in many countries. Underwater object detection enables intelligent underwater vehicles to locate, identify, and classify underwater targets for various tasks, which is a vital sensing technology that has extensive applications in ocean exploration and salvage, offshore engineering, military operations, fishery, etc. [1]. Compared with sonar detection [2], cameras can obtain close-range information so that intelligent underwater vehicles can better perceive the surrounding environment. Image-based underwater object detection has been developed rapidly in recent years, along with the development and application of deep learning in computer vision. However, compared with other typical computer vision tasks, underwater object detection presents unique challenges, including poor image quality, small and dense targets difficult to detect, and limited computation power available within underwater vehicles.
Image enhancement is an effective method to improve underwater image quality and thus improve the accuracy of underwater object detection [3]. Both traditional image enhancement algorithms, such as multi-scale Retinex with color restoration [4] and defog [5], and deep learning algorithms, such as generative adversarial network (GAN) [6], have been applied to improve image quality. Particularly for underwater object detection, several researchers applied image enhancement algorithms based on the Retinex theory and obtained clearer underwater images, but the final prediction results were not significantly improved because only enhancing underwater images does not guarantee better prediction results [7][8]. GAN was used for color correction in underwater object detection tasks [9], but the resulting detection network is rather large and requires costly computation. The image enhancement technique employed should be computationally efficient and combined with other approaches to improve the overall performance of underwater object detection.
Targets of underwater object detection are often small and dense. Deep convolutional neural networks (CNNs) enable multi-layer non-linear transformations that effectively extract the underlying features into more abstract higher-level representations, allowing effective detection when there is target occlusion or the target size is small. YOLO (You Only Look Once) is a series of widely-used CNNs for object detection tasks [10][11][12][13][14][15]. Sung et al. proposed a YOLO-based CNN to detect fish using real-time video images and achieved a classification accuracy of 93% [16]. Pedersen et al. adopted YOLOv2 and YOLOv3 for marine-animal detection [17]. Other researchers applied attention mechanisms to detection networks for better identification of small and dense targets [18][19][20].
Applications of attention mechanisms have been proven effective for object detection; nevertheless, most existing research improves detection performance at the considerable expense of computational cost, as the demand for attention computation is high. Computational capacity and power supply available to underwater vehicles are usually very limited. Increasing computational demand for object detection would result in the need for underwater vehicles to be connected with cables for data transfer or power supply, dramatically limiting the operating range and the level of autonomy of underwater vehicles. Therefore, attention mechanisms should be carefully integrated with detection networks, such that the increases in model size and computational cost are minimized for underwater applications.
2. YOLOv5
In order to achieve real-time underwater object detection, many researchers have chosen the YOLO series as the basis for further development. Wang et al. [21] reduced the network model size of YOLOv3 and replaced batch normalization with instance normalization in some early layers, thus enabling underwater deployment while improving detection accuracy. Al Muksit et al. [22] developed the YOLO-Fish network by modifying the upsampling steps and adding a spatial pyramid pool in YOLOv3 to reduce the false detection of small fishes and to increase detection ability in realistic environments. Zhao et al. [23] and Hu et al. [24] improved the detection accuracy by optimizing the network connection structure of YOLOv4 and updating the original backbone network.
YOLOv5, like other YOLO series, is a one-stage object detection algorithm. YOLOv5 includes four variants, namely YOLOv5s, YOLOv5m, YOLOv5l, and YOLOv5x, whose network size and number of parameters increase successively. Figure 1 shows the overall structure of the YOLOv5 network. An image is first processed by the backbone for feature extraction, followed by the neck for feature fusion, and finally is outputted as the head for the prediction of objects. The backbone is used to extract features from images, containing a total of 53 convolutional layers for various sizes of image features. The CSPDarknet53 structure proposed in YOLOv4 is slightly modified and continuously employed in YOLOv5 [25]. The spatial pyramid pooling module in YOLOv4 is replaced by the spatial pyramid pooling-fast module to improve computational efficiency. The neck is used to reprocess the extracted features for various spatial scales, which consists of top-down and bottom-up paths to form a cross-stage partial path aggregation network [26]. The feature pyramid network [27] is used to fuse the features from the top to the bottom, and a bottom-up path augmentation is used to shorten the path of low-level features. The fused features are integrated into the head structure, and three prediction paths are used. Each path fuses the low-level features of different receptive fields and finally outputs the bounding box, confidence, and category of the detected objects.
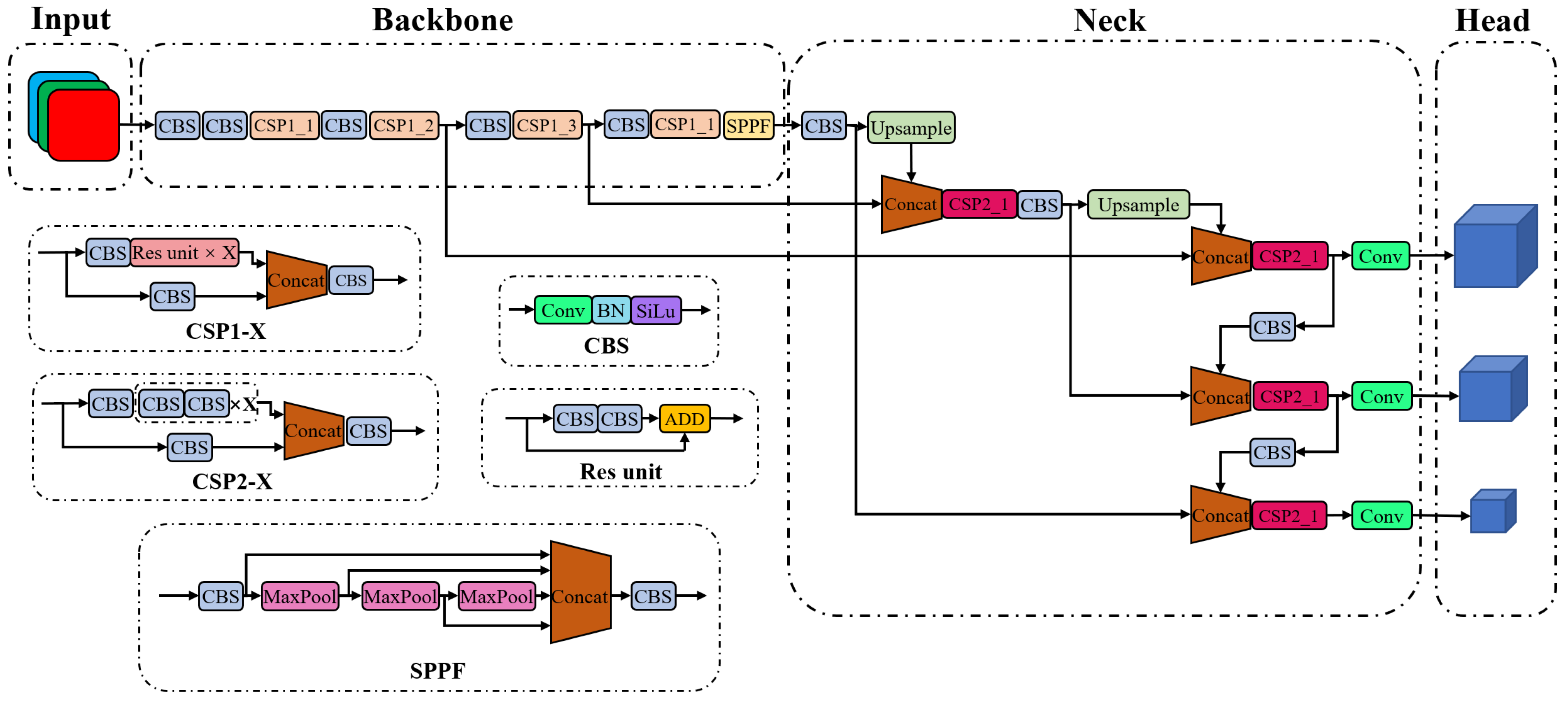
Figure 1. Original YOLOv5 network structure.
Mosaic, mix-up, copy–paste, and several other methods are employed in YOLOv5 for data augmentation [10]. YOLOv5 uses complete intersection over union (IoU) loss [28] to compute the bounding box regression loss, in which the distance between the center points of the bounding box and ground truth (GT) and the aspect ratio of the bounding box are rigorously considered. Similar to YOLOv4, the basic anchor size is computed in YOLOv5 using the k-mean algorithm, but YOLOv5 introduces a priori judgment called auto-anchor to enhance the versatility of anchor boxes. If the preset anchor size matches well with a dataset, the recalculation of anchor boxes can be avoided. YOLOv5 inherits the non-maximum suppression method from its predecessors [29], in which two bounding boxes are considered to belong to the same object if the IoU of two bounding boxes is higher than a certain threshold.
The proposed TC-YOLO network was developed based on YOLOv5s. The overall structure of YOLOv5 and the data augmentation methods were preserved, while self-attention and coordinate attention mechanisms were integrated with the backbone and the neck, respectively.
3. Attention Mechanism
Most of the targets for underwater detection are small and dense, so researchers have introduced attention mechanisms to improve the detection performance. Sun et al. [30] attempted to design a new network using Swin Transformer as the backbone for underwater object detection and obtained similar performance as the Cascade R-CNN with the ResNeXt101 backbone. Other researchers chose to combine attention mechanisms with existing networks to improve the detection accuracy for underwater targets [31][32]. For example, Wei et al. [20] added squeeze-and-excitation modules after the deep convolution layer in the YOLOv3 model to learn the relationship between channels and enhance the semantic information of deep features.
The attention mechanisms used in computer vision are traditionally divided into three types: spatial attention, channel attention, and hybrid attention. Applying the attention mechanism in the spatial domain gives neural networks the ability to actively transform spatial feature maps, for example, the spatial transformer networks [33]. Applying the attention mechanism in the channel domain enables strengthening or suppressing the importance of a channel by changing the weight of this channel, for example, the squeeze-and-excitation networks [34]. Later works, such as the convolutional block attention module (CBAM), employ a hybrid mechanism that combines spatial attention and channel attention modules together and is widely used in convolutional network architectures [35].
Coordinate attention (CA) is another hybrid attention mechanism recently proposed in 2021 [36]. Improved from channel attention, CA factorizes channel attention into two 1-dimensional feature-encoding processes, each of which aggregates features along one of the two spatial coordinates. It encodes both channel correlations and long-range dependencies with precise positional information in two steps: coordinate information embedding and coordinate attention generation. Compared with the CBAM, which computes spatial attention using convolutions, the CA can preserve long-range dependencies that are critical to vision tasks. Additionally, the CA avoids expansive convolution computations, improving its efficiency compared with other hybrid attention mechanisms and enabling its application to mobile networks.
In addition to the above attention mechanisms commonly used in computer vision, Transformer was introduced in 2017 for natural language processing [37], and since then, it has been successfully applied in different neural network architectures for various tasks. Convolutional networks have the problem of limited perceptual fields. Multi-layer stacking is required to obtain global information, but as the number of layers increases, the amount of information is reduced, such that the attention of extracted features is concentrated in certain regions. Transformer, on the other hand, employs the self-attention mechanism that can effectively obtain global information. Furthermore, the multi-head structure used in the Transformer allows better fusion and more expressive capability, in which feature maps can be fused in multiple spatial scales. The Transformer mechanism has been applied to computer vision, such as Vision Transformer [38] and Swin Transformer [39]. However, Transformer modules require a large amount of computation, so they are mostly adopted in large networks and hardly used in mobile networks.
4. Label Assignment
Label assignment aims to determine positive and negative samples for object detection. Unlike labeling for image classification, label assignment in object detection is not well defined due to the variation in bounding boxes. Zheng et al. [40] proposed a loss-aware label assignment for a one-stage detector for dense pedestrian detection. Xu et al. [41] proposed a Gaussian receptive field-based label assignment strategy to replace IoU-based or center-sampling methods for small object detection. Optimal transport assignment (OTA) was proposed in 2021 for object detection [42]. OTA is an optimization-theory-based assignment strategy, in which each GT is considered a label supplier, and its anchors are regarded as label demanders. The transportation cost between each supplier–demander pair is defined by the weighted summation of its classification and regression losses, and then the label assignment is formulated into an optimal transport problem, which aims to transport labels from GT to anchors at minimal transportation cost.
In YOLOv5, the ratios in height and width between a GT and an anchor box are computed as 𝑟ℎ and 𝑟𝑤, and then max(𝑟ℎ,𝑟𝑤,1/𝑟ℎ,1/𝑟𝑤) is compared with a threshold value of 4. If the maximum is smaller than 4, a positive sample is built for this GT; otherwise, the sample is assigned as negative. This label assignment mainly considers the difference in the aspect ratio between the GT and its anchor boxes, which is a static assignment strategy. Improved from the earlier versions of YOLO, a GT can be assigned to multiple anchors in different detection layers in YOLOv5. However, YOLOv5’s label assignment is still not sufficient for underwater object detection because the same anchor may be assigned multiple times, resulting in missed detection.
5. Underwater Images Enhancement
The quality of underwater images is often poor due to harsh underwater conditions, such as light scattering and absorption, water impurities, artificial illumination, etc. Enhancement and restoration techniques are applied to underwater images to improve the performance of underwater object detection. Li et al. [43] proposed an underwater image enhancement framework consisting of an adaptive color restoration module and a haze-line-based dehazing module, which can restore color and remove haze simultaneously. Li et al. [44] developed a systematic underwater image enhancement method, including an underwater image dehazing algorithm based on the principle of minimum information loss and a contrast enhancement algorithm based on the histogram distribution prior. Han et al. [45] combined the max-RGB method and the shades-of-gray method to achieve underwater image enhancement and then proposed a CNN network to deal with low-light conditions. There are other methods used for underwater image enhancement, including spatial domain methods, transform domain methods, and deep learning methods, among which spatial domain methods are considered the most effective and computationally efficient [46].
Several spatial domain image enhancement methods are introduced below. The histogram equalization (HE) algorithm computes the grayscale distribution of an image, stretches its histogram evenly across the image, and therefore improves the image contrast for better separation between foreground and background [47]. However, the HE algorithm increases the sparsity of grayscale distribution and may cause a loss of detailed image-related information. Adaptive histogram equalization (AHE) improves the local contrast and enhances edge details by redistributing the local grayscale multiple times, but it has the disadvantage of amplifying image noise [48]. On the basis of AHE, contrast-limited adaptive histogram equalization (CLAHE) imposes constraints on the local contrast of the image to avoid excessively amplifying image noise in the process of enhancing contrast [49]. Computations of field histograms and the corresponding transformation functions for each pixel are very expensive. Therefore, CLAHE employs an interpolation scheme to improve efficiency at the expense of a slight loss of enhancement quality. Histogram equalization methods only solve the problem of image brightness without adjusting image colors. The Retinex theory can be applied for image enhancement to achieve a balance in three aspects: dynamic range compression, edge enhancement, and color constancy. There are several image enhancement methods developed based on the Retinex theory [50], such as single-scale Retinex, multi-scale Retinex, multi-scale Retinex with color restoration (MSRCR), etc. Retinex-based methods can perform adaptive enhancement for various types of images, including underwater images, but the computational cost is much higher than histogram equalization methods.
References
- Sun, K.; Cui, W.; Chen, C. Review of Underwater Sensing Technologies and Applications. Sensors 2021, 11, 7849.
- Wang, Z.; Wang, B.; Guo, J.; Zhang, S. Sonar Objective Detection Based on Dilated Separable Densely Connected CNNs and Quantum-Behaved PSO Algorithm. Comput. Intell. Neurosci. 2021, 2021, 6235319.
- Tao, Y.; Dong, L.; Xu, L.; Xu, W. Effective solution for underwater image enhancement. Opt. Express. 2021, 29, 32412–32438.
- Rahman, Z.; Jobson, D.J.; Woodell, G.A. Multi-scale retinex for color image enhancement. In Proceedings of the 3rd IEEE International Conference on Image Processing, Lausanne, Switzerland, 19 September 1996; pp. 1003–1006.
- He, K.; Sun, J.; Tang, X. Single Image Haze Removal Using Dark Channel Prior. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 2341–2353.
- Han, Y.; Huang, L.; Hong, Z.; Cao, S.; Zhang, Y.; Wang, J. Deep Supervised Residual Dense Network for Underwater Image Enhancement. Sensors 2021, 21, 3289.
- Yeh, C.H.; Lin, C.H.; Kang, L.W.; Huang, C.H.; Lin, M.H.; Chang, C.Y.; Wang, C.C. Lightweight Deep Neural Network for Joint Learning of Underwater Object Detection and Color Conversion. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6129–6143.
- Song, S.; Zhu, J.; Li, X.; Huang, Q. Integrate MSRCR and Mask R-CNN to Recognize Underwater Creatures on Small Sample Datasets. IEEE Access 2020, 8, 172848–172858.
- Katayama, T.; Song, T.; Shimamoto, T.; Jiang, X. GAN-based Color Correction for Underwater Object Detection. In Proceedings of the OCEANS 2019 MTS/IEEE SEATTLE, Seattle, WA, USA, 27–31 October 2019; pp. 1–4.
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788.
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767.
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525.
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934.
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976.
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696.
- Sung, M.; Yu, S.-C.; Girdhar, Y. Vision based real-time fish detection using convolutional neural network. In Proceedings of the OCEANS 2017—Aberdeen, Aberdeen, UK, 19–22 June 2017; pp. 1–6.
- Pedersen, M.; Haurum, J.B.; Gade, R.; Moeslund, T. Detection of Marine Animals in a New Underwater Dataset with Varying Visibility. In Proceedings of the IEEE Conference on Computer Vision and Pattern recognition Workshops, Long Beach, CA, USA, 16–20 June 2019.
- Wang, W.; Wang, Y. Underwater target detection system based on YOLO v4. Int. Conf. Artif. Intell. Inf. Syst. 2021, 107, 1–5.
- Zhao, Z.; Liu, Y.; Sun, X.; Liu, J.; Yang, X.; Zhou, C. Composited FishNet: Fish Detection and Species Recognition From Low-Quality Underwater Videos. IEEE Trans. Image Process. 2021, 30, 4719–4734.
- Wei, X.; Yu, L.; Tian, S.; Feng, P.; Ning, X. Underwater target detection with an attention mechanism and improved scale. Multimed. Tools Appl. 2021, 80, 33747–33761.
- Wang, L.; Ye, X.; Xing, H.; Wang, Z.; Li, P. YOLO Nano Underwater: A Fast and Compact Object Detector for Embedded Device. In Proceedings of the Global Oceans 2020: Singapore—U.S. Gulf Coast, Biloxi, MS, USA, 5–30 October 2020; pp. 1–4.
- Al Muksit, A.; Hasan, F.; Hasan Bhuiyan Emon, M.F.; Haque, M.R.; Anwary, A.R.; Shatabda, S. YOLO-Fish: A robust fish detection model to detect fish in realistic underwater environment. Ecol. Inform. 2022, 72, 101847.
- Zhao, S.; Zheng, J.; Sun, S.; Zhang, L. An Improved YOLO Algorithm for Fast and Accurate Underwater Object Detection. Symmetry 2022, 14, 1669.
- Hu, X.; Liu, Y.; Zhao, Z.; Liu, J.; Yang, X.; Sun, C.; Chen, S.; Li, B.; Zhou, C. Real-time detection of uneaten feed pellets in underwater images for aquaculture using an improved YOLO-V4 network. Comput. Electron. Agric. 2021, 185, 106135.
- Wang, C.Y.; Liao, H.-Y.; Yeh, I.-H.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 390–391.
- Wang, K.; Liew, J.; Zou, Y.; Zhou, D.; Feng, J. PANet: Few-shot image semantic segmentation with prototype alignment. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9197–9206.
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125.
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666.
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; pp. 850–855.
- Sun, Y.; Wang, X.; Zheng, Y.; Yao, L.; Qi, S.; Tang, L.; Yi, H.; Dong, K. Underwater Object Detection with Swin Transformer. In Proceedings of the 2022 4th International Conference on Data Intelligence and Security (ICDIS), Shenzhen, China, 24–26 August 2022.
- Li, J.; Zhu, Y.; Chen, M.; Wang, Y.; Zhou, Z. Research on Underwater Small Target Detection Algorithm Based on Improved YOLOv3. In Proceedings of the 2022 16th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 21–24 October 2022.
- Zhai, X.; Wei, H.; He, Y.; Shang, Y.; Liu, C. Underwater Sea Cucumber Identification Based on Improved YOLOv5. Appl. Sci. 2022, 12, 9105.
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuogl, K. Spatial transformer networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9.
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 42, 2011–2023.
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018: 15th European Conference, Munich, Germany, 8–14 September 2018.
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722.
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017.
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929.
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October2021; pp. 10012–10022.
- Ge, Z.; Wang, J.; Huang, X.; Liu, S.; Yoshie, O. LLA: Loss-aware label assignment for dense pedestrian detection. Neurocomputing 2021, 462, 272–281.
- Xu, C.; Wang, J.; Yang, W.; Yu, H.; Yu, L.; Xia, G.-S. RFLA: Gaussian receptive field based label assignment for tiny object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 526–543.
- Ge, Z.; Liu, S.; Li, Z.; Yoshie, O.; Sun, J. OTA: Optimal transport assignment for object detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 303–312.
- Li, T.; Rong, S.; Zhao, W.; Chen, L.; Liu, Y.; Zhou, H.; He, B. Underwater image enhancement using adaptive color restoration and dehazing. Opt. Express 2022, 30, 6216–6235.
- Li, C.-Y.; Guo, J.-C.; Cong, R.-M.; Pang, Y.-W.; Wang, B. Underwater image enhancement by dehazing with minimum information loss and histogram distribution prior. IEEE Trans. Image Process. 2016, 25, 5664–5677.
- Han, F.; Yao, J.; Zhu, H.; Wang, C. Underwater image processing and object detection based on deep CNN method. J. Sens. 2020, 2020, 6707328.
- Sahu, P.; Gupta, N.; Sharma, N. A survey on underwater image enhancement techniques. Int. J. Comput. Appl. 2014, 87, 160–164.
- Mustafa, W.A.; Kader, M.M.M.A. A review of histogram equalization techniques in image enhancement application. J. Phys. Conf. Ser. 2018, 1019, 012026.
- Pizer, S.M.; Amburn, E.P.; Austin, J.D.; Cromartie, R.; Geselowitz, A.; Greer, T.; ter Haar Romeny, B.; Zimmerman, J.B.; Zuiderveld, K. Adaptive histogram equalization and its variations. Comput. Vis. Graph. Image Process. 1987, 39, 355–368.
- Reza, A.M. Realization of the contrast limited adaptive histogram equalization (CLAHE) for real-time image enhancement. J. Vlsi Signal Process. Syst. Signal Image Video Technol. 2014, 38, 35–44.
- Rahman, Z.; Woodell, G.A.; Jobson, D.J. A Comparison of the Multiscale Retinex with Other Image Enhancement Techniques; NASA Technical Report 20040110657; NASA: Washington, DC, USA, 1997.
More
Information
Subjects:
Engineering, Ocean
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
1.1K
Revisions:
2 times
(View History)
Update Date:
01 Apr 2024
Table of Contents




Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No