Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Jiwoon Lee | -- | 1550 | 2024-01-20 06:56:31 | | | |
| 2 | Sirius Huang | Meta information modification | 1550 | 2024-01-22 02:29:00 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Lee, J.; Kang, H. Anomaly Detection in Video Surveillance. Encyclopedia. Available online: https://encyclopedia.pub/entry/54141 (accessed on 25 July 2026).
Lee J, Kang H. Anomaly Detection in Video Surveillance. Encyclopedia. Available at: https://encyclopedia.pub/entry/54141. Accessed July 25, 2026.
Lee, Ji-Woon, Hyun-Soo Kang. "Anomaly Detection in Video Surveillance" Encyclopedia, https://encyclopedia.pub/entry/54141 (accessed July 25, 2026).
Lee, J., & Kang, H. (2024, January 20). Anomaly Detection in Video Surveillance. In Encyclopedia. https://encyclopedia.pub/entry/54141
Lee, Ji-Woon and Hyun-Soo Kang. "Anomaly Detection in Video Surveillance." Encyclopedia. Web. 20 January, 2024.
Copy Citation
The escalating use of security cameras has resulted in a surge in images requiring analysis, a task hindered by the inefficiency and error-prone nature of manual monitoring. Research on anomaly detection in CCTV videos is being actively conducted using various techniques.
deep learning
Transformers
video surveillance
anomaly detection
1. Introduction
The increasing prevalence of crime, ranging from minor offenses to violent acts, as highlighted in the “2022 Crime Analysis” report by the Supreme Prosecutors’ Office of Korea, and shown in Figure 1, underscores the necessity of enhanced security measures. In this regard, the field of the video-based detection of abnormal situations, as referenced in numerous studies ([1][2][3][4][5][6][7][8]), is experiencing a surge in interest. Research in this area, especially studies investigating surveillance video anomaly detection (SVAD) using deep learning [9], is progressing rapidly. This research domain has evolved to encompass a broader scope, extending beyond behavior-based detection to include advanced areas like human facial emotion recognition for anomaly detection [10], illustrating the expanding reach and depth of investigations in this field. These systems function by capturing real-time images across various indoor and outdoor settings, both public and private. However, the proliferation of security cameras leads to the generation of an immense volume of images, making manual monitoring susceptible to human error, as well as being labor-intensive and costly. Therefore, the automation of anomaly recognition in video footage is imperative.
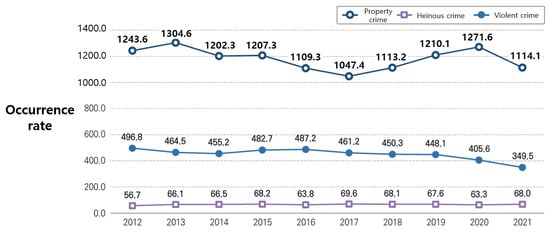
Figure 1. Trends in accrual costs by major criminal crimes of prosecution in 2012–2021. (Source: “2022 Crime Analysis” by the Supreme Prosecutors’ Office of Korea).
Video-based anomaly detection, in essence, aims to identify any unusual or non-standard activities and situations captured in video data, including incidents like violence, fires, health emergencies, unauthorized entry, and abduction. Unlike still images, which contain only spatial information, video data encompass temporal elements as well, necessitating the fusion of spatial and temporal data for accurate analysis due to the correlation between neighboring frames.
Approaches to video-based anomaly detection, integrating both spatial and temporal aspects, encompass various learning paradigms: supervised, unsupervised, and semi-supervised (one-class) learning. Supervised learning, which utilizes labeled data for both normal and abnormal instances, generally achieves higher accuracy. Nonetheless, it is limited by the need for diverse atypical samples. To address the limitations of semi-supervised learning methods, which require labeled normal samples, unsupervised learning techniques are being investigated. These techniques operate under the assumption that the majority of the data consist of normal samples and can be learned without labels. A prime example of this approach is the autoencoder [11][12], featuring an encoder that compresses the input into a feature vector and a decoder that reconstructs the original input from this feature vector.
2. Anomaly Detection in CCTV Videos
Currently, research on anomaly detection in CCTV videos is being actively conducted using various techniques. This section will introduce diverse methodologies. First, Bilinski, P. [13] proposed an extension of Improved Fisher Vectors (IFV) for videos, which enables the spatiotemporal localization of features to increase accuracy. Additionally, they re-formalized IFV and proposed a sliding window approach that utilizes aggregated region table data structures for violence detection. Subsequent advancements in technology have enabled more sophisticated analysis. Some techniques utilize optical flow [14][15][16][17] before training the network. Optical flow refers to the visible motion pattern of an object captured in consecutive video frames. When the movement of an object occurs in an image, it is projected onto a 2D image space, where a myriad of vectors from the 3D space can be projected as vectors in the 2D image space because the dimensions are reduced. Examples of these advanced techniques include the following.
Skeleton-based anomaly detection utilizes graph convolutional networks (GCNs). A GCN predicts the label of each node in a given input graph and updates its hidden state using Equation (1), where H represents the hidden state matrix of the lth hidden layer, A represents the adjacency matrix with self-connections and an identity matrix, and W represents the weight matrix.
Skeleton-based anomaly detection [18] converts human images into graphs and analyzes the interactions within these graphs to detect anomalies. For example, Garcia-Cobo, G. [19] proposed an architecture using human pose extractors and ConvLSTM. The author relied on what they considered to be the most essential information to detect human bodies and their interactions, using human pose extractors and optical flow for this purpose. The architecture consists of RGB and motion detection pipelines, each of which analyzes image distributions and skeletal movements. Su, Y. [20] proposed an architecture that learns interactions between skeletal points using 3D skeleton point clouds. They aimed to represent videos as human skeleton point clouds using the multi-head Skeleton Points Interaction Learning (SPIL) module and perform inference for violence recognition in videos.
There are also studies on anomaly detection techniques using Conv3D. Typically, CNNs apply operations to images using two-dimensional (2D) kernels. However, this method can only be applied to static images. Meanwhile, CCTV image analysis includes both still images and the analysis of temporal data, making it impossible to perform analysis using a generic CNN. Therefore, the passage of time should be incorporated into the 2D CNN, and a Conv3D network has been developed for this purpose. Conv3D takes inputs in three dimensions, and its kernel is also three-dimensional (3D). The rest of the computation is the same as that of a conventional 2D CNN; however, the direction of movement of the kernel occurs along the x-, y-, and z-axes, and the convolution operation is applied to convert the 𝑛×𝑛×𝑛 3D inputs into a single output.
In previous studies, several techniques have incorporated optical flow or attention modules [21]. For instance, Cheng, M. [22] proposed a flow-gated network that leveraged both 3D-CNN and optical flow. Video frames were divided into RGB and optical flow channels, each processed through Conv3D networks. The outputs from the last layers of the RGB and optical flow channels underwent ReLU and sigmoid operations before concatenation. The resulting output was used for anomaly detection. Sultani, W. [4] used multiple instance learning (MIL) and 3D convolution to differentiate between normal and abnormal scenarios. The author separated normal and abnormal video clips into positive and negative bags, respectively. Features were extracted using 3D convolution, and a multiple instance ranking objective function was proposed to rank the two instances with the highest anomaly scores within each bag. Degardin, B. [23] introduced an approach to detect abnormal events in surveillance videos using a recurrent learning framework, a random forest ensemble, and novel terms for score propagation. The author used a weakly supervised network model to classify videos into bags with positive and negative instances and detected abnormal situations in unlabeled data using 3D convolution and a Bayesian classifier. Degardin, B.M. [2] utilized a Gaussian Mixture Model (GMM) composed of a soft clustering technique to connect data points to clusters. The author introduced a new MIL solution with a loss function that incorporated both a two-kernel GMM and the estimated parameters of normal distributions. Features were extracted using 3D convolution. Mohammadi, H. [24] improved the model accuracy by adding hard attention to semi-supervised learning, utilizing the optical flow extracted from input data, and applying 3D convolution.
There are also studies on anomaly detection techniques using ConvLSTM. To understand ConvLSTM [25], we must first examine long short-term memory (LSTM) [26]. In conventional RNNs, when long intervals of data are input, backpropagation requires a long time, and slope loss occurs. To prevent this, an LSTM with a state store, an input gate, and an output gate was developed. LSTM is faster than conventional methods because each gate unit is trained to appropriately open and close the flow, which solves the slope loss problem.
ConvLSTM introduces convolutional recurrent cells into the basic LSTM structure and applies convolutional operations to the images as inputs. Consequently, it can effectively learn the spatial characteristics of the image. Moreover, because it has the characteristics of LSTM, it can also learn the temporal continuity among image frames.
Utilizing these characteristics, research has been conducted on anomaly detection techniques using ConvLSTM [27]. For example, Islam, Z. [28] proposes an efficient two-stream deep learning architecture. The architecture leverages separable convolution LSTM (sepconvlstm) and a pre-trained MobileNet. One stream takes suppressed frames as input to model the background, while the other stream processes the differences between adjacent frames. Additionally, the author presents three fusion methods to combine the output feature maps of the two streams. Sudhakaran, S. [29] introduces a combined architecture of 2D convolution and ConvLSTM. Features are extracted frame-wise using a pre-trained AlexNet, followed by convlstm layers with 256 filters, batch normalization, and ReLU activation functions to detect anomalies.
Additionally, there are anomaly detection techniques based on Transformers, which serve as the foundation for the present study. Deshpande, K. [30] conducted anomaly detection using Videoswin Transformer feature extraction, attention layers, and the Robust Temporal Feature Magnitude (RTFM). Furthermore, Jin, P. [31] proposed a new model called ANomaly Detection with Transformers (ANDT) to detect abnormal events in aerial videos. In this approach, videos are processed into a sequence of tubes, and a Transformer encoder is employed to learn spatiotemporal features. Subsequently, the decoder combines with the encoder to predict the next frame based on the learned spatiotemporal representation.
Liu, Y. [32] provides a hierarchical GVAED taxonomy that systematically organizes the existing literature by supervision, input data, and network structure, focusing on the recent advances, such as weakly supervised, fully unsupervised, and multimodal methods. Furthermore, focal loss [33] is employed as part of the network architecture.
References
- Popoola, O.P.; Wang, K. Video-based abnormal human behavior recognition—A review. IEEE Trans. Syst. Man Cybern. Part (Appl. Rev.) 2012, 42, 865–878.
- Degardin, B.M. Weakly and Partially Supervised Learning Frameworks for Anomaly Detection. Ph.D. Thesis, Universidade da Beira Interior (Portugal), Beira, Portugal, 2020.
- Wang, T.; Qiao, M.; Lin, Z.; Li, C.; Snoussi, H.; Liu, Z.; Choi, C. Generative neural networks for anomaly detection in crowded scenes. IEEE Trans. Inf. Forensics Secur. 2018, 14, 1390–1399.
- Sultani, W.; Chen, C.; Shah, M. Real-world anomaly detection in surveillance videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6479–6488.
- Ravanbakhsh, M.; Nabi, M.; Sangineto, E.; Marcenaro, L.; Regazzoni, C.; Sebe, N. Abnormal event detection in videos using generative adversarial nets. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 1577–1581.
- Flaborea, A.; Collorone, L.; di Melendugno, G.M.D.; D’Arrigo, S.; Prenkaj, B.; Galasso, F. Multimodal Motion Conditioned Diffusion Model for Skeleton-based Video Anomaly Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Vancouver, BC, Canada, 18–22 June 2023; pp. 10318–10329.
- Rodrigues, R.; Bhargava, N.; Velmurugan, R.; Chaudhuri, S. Multi-timescale trajectory prediction for abnormal human activity detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 2–5 March 2020; pp. 2626–2634.
- Flaborea, A.; di Melendugno, G.M.D.; D’arrigo, S.; Sterpa, M.A.; Sampieri, A.; Galasso, F. Contracting Skeletal Kinematic Embeddings for Anomaly Detection. arXiv 2023, arXiv:2301.09489.
- Şengönül, E.; Samet, R.; Abu Al-Haija, Q.; Alqahtani, A.; Alturki, B.; Alsulami, A.A. An Analysis of Artificial Intelligence Techniques in Surveillance Video Anomaly Detection: A Comprehensive Survey. Appl. Sci. 2023, 13, 4956.
- Kalyta, O.; Barmak, O.; Radiuk, P.; Krak, I. Facial Emotion Recognition for Photo and Video Surveillance Based on Machine Learning and Visual Analytics. Appl. Sci. 2023, 13, 9890.
- Hasan, M.; Choi, J.; Neumann, J.; Roy-Chowdhury, A.K.; Davis, L.S. Learning temporal regularity in video sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 733–742.
- Chong, Y.S.; Tay, Y.H. Abnormal event detection in videos using spatiotemporal autoencoder. In Proceedings of the Advances in Neural Networks-ISNN 2017: 14th International Symposium, ISNN 2017, Sapporo, Hakodate, and Muroran, Hokkaido, Japan, 21–26 June 2017; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2017; pp. 189–196.
- Bilinski, P.; Bremond, F. Human violence recognition and detection in surveillance videos. In Proceedings of the 2016 13th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Colorado Springs, CO, USA, 23–26 August 2016; pp. 30–36.
- Ilg, E.; Mayer, N.; Saikia, T.; Keuper, M.; Dosovitskiy, A.; Brox, T. Flownet 2.0: Evolution of optical flow estimation with deep networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 2462–2470.
- Xu, H.; Zhang, J.; Cai, J.; Rezatofighi, H.; Yu, F.; Tao, D.; Geiger, A. Unifying flow, stereo and depth estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 13941–13958.
- Weinzaepfel, P.; Lucas, T.; Leroy, V.; Cabon, Y.; Arora, V.; Brégier, R.; Csurka, G.; Antsfeld, L.; Chidlovskii, B.; Revaud, J. CroCo v2: Improved Cross-view Completion Pre-training for Stereo Matching and Optical Flow. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Vancouver, BC, Canada, 18–22 June 2023; pp. 17969–17980.
- Zhao, S.; Sheng, Y.; Dong, Y.; Chang, E.I.; Xu, Y. Maskflownet: Asymmetric feature matching with learnable occlusion mask. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6278–6287.
- Hachiuma, R.; Sato, F.; Sekii, T. Unified keypoint-based action recognition framework via structured keypoint pooling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 22962–22971.
- Garcia-Cobo, G.; SanMiguel, J.C. Human skeletons and change detection for efficient violence detection in surveillance videos. Comput. Vis. Image Underst. 2023, 233, 103739.
- Su, Y.; Lin, G.; Zhu, J.; Wu, Q. Human interaction learning on 3d skeleton point clouds for video violence recognition. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part IV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 74–90.
- Zhu, B.; Hofstee, P.; Lee, J.; Al-Ars, Z. An attention module for convolutional neural networks. In Proceedings of the Artificial Neural Networks and Machine Learning–ICANN 2021: 30th International Conference on Artificial Neural Networks, Bratislava, Slovakia, 14–17 September 2021; Proceedings, Part I 30. Springer: Berlin/Heidelberg, Germany, 2021; pp. 167–178.
- Cheng, M.; Cai, K.; Li, M. RWF-2000: An open large scale video database for violence detection. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 4183–4190.
- Degardin, B.; Proença, H. Iterative weak/self-supervised classification framework for abnormal events detection. Pattern Recognit. Lett. 2021, 145, 50–57.
- Mohammadi, H.; Nazerfard, E. Video violence recognition and localization using a semi-supervised hard attention model. Expert Syst. Appl. 2023, 212, 118791.
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28.
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780.
- Abdali, A.M.R.; Al-Tuma, R.F. Robust real-time violence detection in video using cnn and lstm. In Proceedings of the 2019 2nd Scientific Conference of Computer Sciences (SCCS), Baghdad, Iraq, 27–28 March 2019; pp. 104–108.
- Islam, Z.; Rukonuzzaman, M.; Ahmed, R.; Kabir, M.H.; Farazi, M. Efficient two-stream network for violence detection using separable convolutional lstm. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8.
- Sudhakaran, S.; Lanz, O. Learning to detect violent videos using convolutional long short-term memory. In Proceedings of the 2017 14th IEEE international Conference on Advanced Video and Signal Based Surveillance (AVSS), Honolulu, HI, USA, 21–26 June 2017; pp. 1–6.
- Deshpande, K.; Punn, N.S.; Sonbhadra, S.K.; Agarwal, S. Anomaly detection in surveillance videos using transformer based attention model. In Proceedings of the International Conference on Neural Information Processing, Virtual Event, 22–26 November 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 199–211.
- Jin, P.; Mou, L.; Xia, G.S.; Zhu, X.X. Anomaly detection in aerial videos with transformers. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 1–13.
- Liu, Y.; Yang, D.; Wang, Y.; Liu, J.; Song, L. Generalized video anomaly event detection: Systematic taxonomy and comparison of deep models. arXiv 2023, arXiv:2302.05087.
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988.
More
Information
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
877
Revisions:
2 times
(View History)
Update Date:
22 Jan 2024
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No