Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Fu, Y.; Yuan, S.; Zhang, C.; Cao, J. Emotion Recognition in Conversations. Encyclopedia. Available online: https://encyclopedia.pub/entry/52800 (accessed on 24 July 2026).
Fu Y, Yuan S, Zhang C, Cao J. Emotion Recognition in Conversations. Encyclopedia. Available at: https://encyclopedia.pub/entry/52800. Accessed July 24, 2026.
Fu, Yao, Shaoyang Yuan, Chi Zhang, Juan Cao. "Emotion Recognition in Conversations" Encyclopedia, https://encyclopedia.pub/entry/52800 (accessed July 24, 2026).
Fu, Y., Yuan, S., Zhang, C., & Cao, J. (2023, December 15). Emotion Recognition in Conversations. In Encyclopedia. https://encyclopedia.pub/entry/52800
Fu, Yao, et al. "Emotion Recognition in Conversations." Encyclopedia. Web. 15 December, 2023.
Copy Citation
As a branch of sentiment analysis tasks, emotion recognition in conversation (ERC) aims to explore the hidden emotions of a speaker by analyzing the sentiments in utterance. In addition, emotion recognition in multimodal data from conversation includes the text of the utterance and its corresponding acoustic and visual data. By integrating features from various modalities, the emotion of utterance can be more accurately predicted.
emotion recognition in conversation
speaker dependency
context construct
1. Context Construction
1.1. Sequential Models
The preliminary endeavors in modeling the inter-dependencies among contextual utterances encompassed sequential models, such as LSTM, recurrent neural networks (RNNs) [1], and gated recurrent units (GRUs) [2]. These models iteratively extract historical utterances and retain the sequential organization of the conversational components, ensuring the suitability of the models for preserving the chronological continuity of the conversation. Wollmer et al. [3] adopted an LSTM-based RNN that could explicitly learn to perform clustering in the emotional space and simulate contextual knowledge to achieve improved performance. Nevertheless, in models such as LSTM, constructing a context capable of distinguishing between individual speakers still needs to be addressed.
Majumder et al. [4] posited that the emotional attributes in a conversation are contingent upon three primary factors: the speaker, the contextual information provided by the preceding utterance, and the contextual information embedded within the prior utterance. Hence, DialogueRNN incorporates these three factors, employing three GRUs to encode the overarching context (global state), participant-specific context (party state), and emotional nuances (emotion representations). The DialogueRNN model can comprehensively consider this information and perform joint coding for emotion recognition tasks through such a division of labor.
An alternative Transformer-Based Context and Speaker-Sensitive Model context modeling approach involve utilizing expansive, pre-trained language models such as BERT and RoBERTa to comprehend the contextual intricacies in conversation. Researchers leverage these models to augment the process of integrating contextual information. Transformer-Based Context- and Speaker-Sensitive Model(HiTrans) [5] combines multiple utterances marked with [CLS] and packs them into an input sequence. An utterance sequence with a length exceeding 512 first divides itself into blocks, passes through BERT, and then passes through another transformer. The low-level transformer generates the current discourse representation, and the high-level transformer further generates global contextual information embedded in the discourse representation. Kim et al. [6] integrates the speaker’s identity into the context, enriching the context extracted by the transformer model. Although pre-trained on massive data texts provides a large-scale pre-trained model with more powerful semantic capabilities, difficulties concerning computing resources and context sequence length limitations still need to be solved.
Furthermore, the conventional sequential modeling approach needs to be improved in its ability to capture the impact of prior states on the current utterance, as it needs to pay more attention to the influence of future states on the present situation. This approach must fully exploit the bidirectional dependencies inherent in contexts, prompting researchers to shift their focus toward bidirectional historical modeling. A bidirectional model can represent the history from the past to the present and from the present to the past. It simultaneously considers the forward and backward information in the dialogue history, facilitating a more comprehensive understanding of the context.
Researchers have employed bidirectional RNNs, LSTM networks, and transformer models to establish chronological records for bidirectional dialogue modeling. C-LSTM [7] takes the features of each utterance as its inputs and processes them through a bidirectional LSTM unit. One approach involves sequentially processing utterances in the forward direction, while another entails reverse sequential processing. This methodology enables the model to concurrently incorporate the contextual information preceding and following each utterance, subsequently merging the resulting output features from both directions to construct a holistic, contextual feature. Bidirectional LSTM models capture the context of utterances better than unidirectional LSTMs. Models such as a bidirectional GRU (BiGRU) [8] and BiTransformer [9] are committed to improving the expression ability of dialogue history through bidirectional modeling to understand the emotions and context more comprehensively, and these approaches have achieved specific results in ERC tasks. The success of this method offers valuable insights for advancing research in emotion recognition and contextual understanding.
1.2. Graph-Based Methods
The primary method for modeling context is stacking utterances, thus incorporating facial structural constraints to effectively capture extensive, multimodal, and diverse contextual information across longer distances. Simultaneously, researchers have observed that conversation can be construed as innate graph structures. The evident correlations and inter-dependencies prevail among these sentences. Furthermore, conversation conventionally involves multi-turn exchanges marked by intricate dependencies and interaction patterns. The evident correlations and inter-dependencies prevail among these sentences.
These interaction patterns can ideally exploit GNNs’ edges to facilitate the holistic modeling of the emotional dynamics within the conversation. They were additionally driven by advancements in human-computer interaction technology and contextual scenarios; diverse node types can be employed within a graph structure for modeling multimodal conversation data, encompassing the text, audio, and video modalities. Dynamically adapting to the dimensions and intricacies of conversation, GNNs can process dialogic graphs with varying dimensions and configurations. This adaptability enables them to capture finer and more intricate dependencies in interactions.
In graph-based ERC tasks, conventionally, utterances in conversation are represented as nodes, and predefined composition rules establish the connections. Graph-based research typically centers on utilizing GNNs and Graph Convolutional Networks(GCNs) [10] within the graph construction paradigm. This approach encompasses the following principal components.
-
Node definitions: Nodes represent nodes in a session, and standard graph-based conversations are represented by G = (V, E). When only considering the text modality, the set of nodes V corresponds to the number of sentences in the conversation, represented as V = N. However, in cases where the conversation involves multimodal settings, including videos, audio, and text, the size of the node set V is expanded to 3 N.
-
Edges: Edge construction relationships mainly depend on the conversation context, such as the temporal, speaker’s relationship. In contrast, the weight of an edge represents the strength of the association between two nodes. Ghosal et al. [11] distinguish the links of utterance nodes according to their temporal relationships for the first time, and this approach clarifies the characteristics by which other speakers influence the target speaker. Experiments have proven that it is essential to distinguish between different contexts and speaker dependencies in relational modeling cases. On this basis, the Multimodal Fusion via Deep Graph Convolution Network(MMGCN) [12] models relationships under multimodal dialogue settings.
As depicted in Figure 1, MMGCN establishes two distinct categories of edges that connect internal interactions within the same modality and interactions across different modalities. DAG-ERC [13] treat each conversation as a Directed Acyclic Graph(DAG); each utterance only accepts information from some previous utterances and cannot propagate information back to itself and the words of its predecessor. However, DAG-ERC focuses on computing the information flow between utterances and does not consider the interactions among conversations under the multimodal data setting.
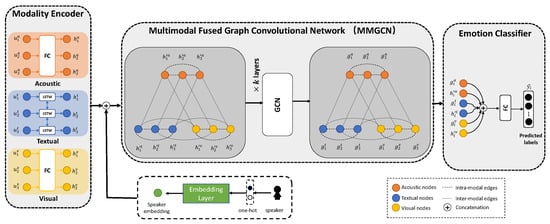
Figure 1. Multimodal Fusion via the Deep GCN (MMGCN) Proposed by Hu et al. [12].
On this basis, Xu et al. [14] proposed a multimodal DAG, which transmits information flows between nodes with the same modality and nodes across modalities. Information is only allowed to flow from previous utterances to the current utterance, and the current utterance is prohibited from passing information to itself or the previous utterances. Furthermore, due to the importance of the textual modality, this model only allows the visual and acoustic modalities to convey information to the textual modality, limiting the interaction and information flow between nonverbal modal features. This approach further improves the ability of a directed multimodal dialogue graph to capture multimodal conversation characteristics.
-
Weights: In the Edge weight setting, the MMGCN assumes that the higher the similarity between two nodes is, the more critical the information interaction between them is, so the edge weight between them is also greater. The MMGCN uses angular similarity to represent the weights between nodes. The graph comprises two distinct categories of edges: the connection between the same modality, as exemplified by Equation (1), and the connection between different modalities, as represented by Equation (2). In these equations, 𝑛𝑖
and 𝑛𝑗 refer to the feature representations of the i-th and j-th nodes within the graph, respectively. The symbol 𝛾 denotes a hyperparameter. The edge weight computation is performed as follows:
Since the neighboring nodes influence the current utterance node differently, GAT [15] is used to compute the edge weights. The traditional GAT, as defined in Equations (3) and (4), computes the scoring functions:
𝑒𝑖𝑗 indicates the importance of the node’s features to node i when incorporating the graph structure into the mechanism by considering 𝑁𝑖, which represents the neighborhood of node i in the graph. These values are subsequently normalized across all choices of j using the softmax function. Furthermore, the attention coefficients remain static in traditional GAT. Therefore, GATv2 [16] strategically relocates the LeakyReLU activation function between the weight matrix (W) and the subsequent non-linear layer, followed by the concatenation before applying a linear transformation with W. Empirical findings validate that GATv2 yields a more expressive attention mechanism, resulting in enhanced experimental performance:
In this context, 𝑥𝑖 corresponds to the feature representation of node 𝑢𝑖. Both 𝑢𝑗 and 𝑢𝑘 are neighboring nodes of 𝑢𝑖. Here, 𝑢𝑘∈𝑁(𝑢𝑖) represents the neighborhood of 𝑢𝑖. 𝜔𝑖𝑗 denotes the edge weight between 𝑢𝑖 and 𝑢𝑗, and 𝜎 indicates the leaky rectified linear unit (LeakyReLU) non-linear activation function. 𝑊𝜔 and 𝑎𝜔 are adjustable parameters.
Each modality (e.g., text, sound, and images) uniquely expresses information and emotions in a multimodal ERC task. In addition to classic modeling methods based on intra-modal contextual relations and inter-modal interactions, Zhang et al. [17] transforms the task into a node classification problem; each sub-graph in the graph represents a conversation, and each node is an utterance in the conversation. In addition, nodes represent speakers in the whole graph. When constructing an edge, each utterance in each conversation is first connected, and the weight of the connecting edge using angular similarity. Then, each utterance is connected with the corresponding speaker with an edge, and the weight of the edge is from the inverse speaking frequency of the speaker. Then, the graph is sent to a two-layer GCN to train and classify its nodes.
Graph-related research has yet to fully explore how to integrate the differences between different modalities effectively. Therefore, future research should further study a strategy for fusing multimodal features better to utilize the relationships and complementary information between different modalities.
1.3. Transformer-Based Methods
Transformers [18] are widely used in various downstream tasks in NLP(Natural language processing technology) due to their powerful sequence modeling and relationship capture capabilities. The multimodal emotion recognition task focuses mainly on the ability to represent different modal features and their fusion. Early ERC tasks in multimodal settings focused on improving the representation capabilities achieved for each modality. They improved the performance of traditional text-based emotion recognition models by enhancing the interaction and fusion of features. However, due to the representation capability differences among different modalities and data heterogeneity, interaction modeling introduces noise, which blurs the ability to represent multimodal information. Transformer’s self-attention mechanism can capture the dependencies between utterances, making it an ideal choice for multimodal interaction modeling and learning that applies to various tasks and datasets.
DialogueTRM (A Novel Multi-Grained Interactive Fusion) [19], shown in Figure 2 below, explores different emotional behaviors from intra-modal and inter-modal perspectives. It builds a new layered transformer that can easily switch between sequential and feed-forward structures according to the contextual preferences within each modality. To achieve multimodal interaction fusion, it applies neuron- and vector-level feature interactions to learn the different contributions of individual modalities.
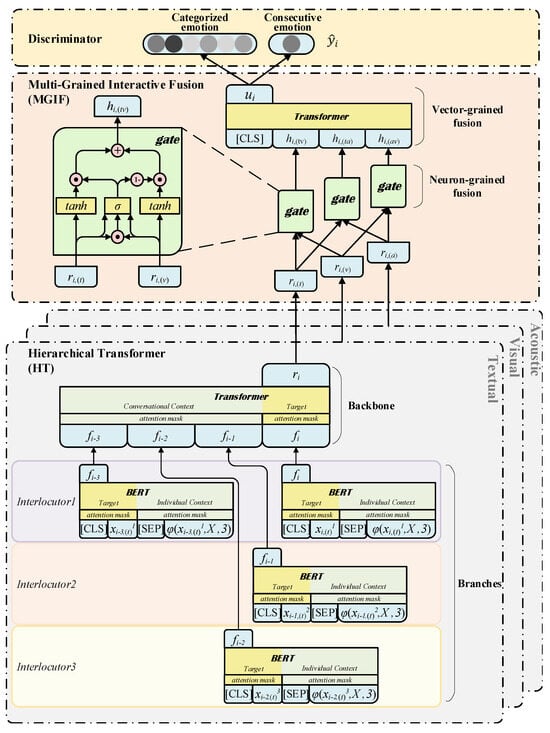
Figure 2. The DialogueTRM Method Proposed by Mao et al. [19].
Li et al. [20] propose a new structure named Emoformer to extract multimodal emotion vectors from different modalities and fuse them with sentence vectors to be an emotion capsule and obtain emotional classification results through a context analysis model. A sequence-based approach employs a transformer-based context- and speaker-sensitive EDC model (Trans). It consists of two transformers. First, a pre-trained bidirectional transformer encoder generates a global utterance representation. Then, another high-level transformer captures the global information in the given dialogue, generates a global context, and combines speaker-sensitive tasks to judge whether sentences belong to the same speaker.
The Main Modal Transformer (MMT) [21] model utilizes a transformer architecture and consists of two attention mechanisms: cross-modal attention (Cm) and cross-task attention (Ct). Cross-modal attention learns the fusion relationships between different modalities. In contrast, cross-task attention learns the relationships between different tasks (e.g., sentiment analysis and emotion recognition). The main task of the MMT is to improve its multimodal feature fusion effect. It uses a two-level emotional cue extractor to extract emotional evidence. In addition, a cross-modal transformer (CMT) preserves the integrity of the dominant modal features and enhances the representations of weak modal features. Liu et al. [22] proposed a hierarchical dialog understanding model named HiDialog, shown in Figure 3, which performs sequence modeling by inserting unique tokens in conversations and introduces multi-turn and turn-level attention to learn embedding representations. In addition, the model utilizes a heterogeneous graph network [23] to optimize the learned embeddings.
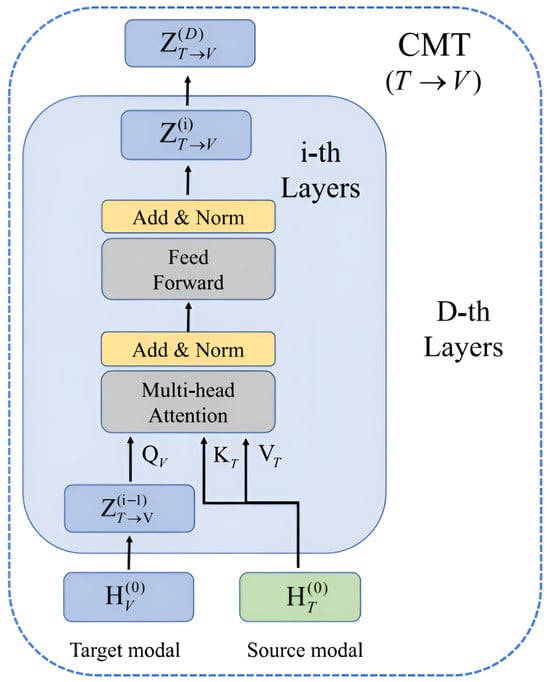
Figure 3. The architecture of CMT proposed by Zou et al. [21].
This subsection summarizes the experimental results of different models in context modeling and comparisons among their performances. The performance of the models compared in terms of accuracy and generalizability, and the advantages and disadvantages of different models. The future direction is to examine the complementarity and redundancy in multimodal context features to improve the robustness and performance of prediction methods. By intensely studying the correlations and interactions between different modalities, more powerful multimodal feature fusion methods can be designed better to capture the rich information in these different modalities. In summary, there is some progress in multimodal ERC research. However, further in-depth research and explorations are still needed to give full play to the advantages of multimodal differences and rich features.
2. Speaker Dependency
Speaker dependency plays a pivotal role in conversational dynamics. It encompasses two distinct facets: intra-speaker dependency and inter-speaker dependency. Figure 3, sourced from the publicly accessible IEMOCAP dataset, illustrates a dialogue where Participant A (𝑃𝑎) begins distressed during the initial exchanges (𝑈1 and 𝑈3) and seeks consolation. Participant B (𝑃𝑏), however, responds with sarcasm. Consequently, this interaction influences the speaker’s emotional state to remain ostensibly neutral throughout the dialogue. In contrast, 𝑃𝑎 persists in a state of distress at utterances 𝑈1 and 𝑈3, and due to the intra-speaker dependency, this state carries through to 𝑈5. Here, 𝑃𝑎 is further influenced by 𝑃𝑏’s state—illustrative of inter-speaker dependency—and reacts with anger. This exemplification underscores the importance of examining speaker dependency within ERC tasks, offering insights into speakers’ nuanced and implicit emotions in complex conversation environments.
2.1. Embedded Speaker Dependency
Embedded speaker dependency modeling refers to the implicit exploration of speaker dependencies by representing speaker information as sentence features, and the research concerning such methods has focused on how to obtain speaker features efficiently. Conversational Transformer Network (CTNet) [24] was primarily designed to address the intricate task of bimodal emotion recognition within conversational contexts, encompassing both textual and audio modalities. In pursuit of explicitly incorporating speaker-related information into multimodal sentence representations, CTNet undertakes a multistep process. CTNet extracts a 512-dimensional utterance-level speaker embedding from audio MFCCs through the x-vector system and combines the speaker embedding with the unimodal speaker embedding. The speaker embedding concatenated with the subsequent modeling steps’ unimodal and cross-modal input features.
Unlike CTNet, which uses a sequential structure to simulate conversation, the Multimodal Dynamic Fusion Network (MM-DFN) [25] and MMGCN simulates the structure of an undirected graph. Before building the graph, to incorporate the speaker’s information into the graph, the MMDFN and MMGCN first convert the speakers involved in the current dialogue into one-hot codes and then obtain the corresponding speaker features from the one-hot codes of the current sentence through a linear layer. Then, they splice the speaker features with the three modalities of the corresponding sentence to obtain the three modal features containing the speaker information. ConGCN primarily focuses on the textual unimodal aspect of conversations, representing dialogues as undirected graphs. Unlike conventional approaches, ConGCN initializes nodes in a graph, excluding those of the dialogue sentences, as random vectors. These initialized nodes serve a specific purpose within the graph (known as ’speaker nodes’) and are dynamically updated during graph evolution. This update mechanism aids the model in exploring speaker-related characteristics, thereby facilitating the modeling of speaker dependencies. The strength of this embedded speaker dependency modeling approach lies in its simplicity. However, it needs to be improved in effectively capturing evolving speaker states throughout a dialogue, as this issue poses challenges in comprehensively modeling intricate speaker dependencies.
2.2. Dynamic Speaker Dependency Based on Sequential Structures
Due to the limitations of embedded speaker dependency modeling, researchers proposed dynamic speaker dependency modeling to improve the ability of models to capture the speaker dependencies that interact in conversations. Dynamic speaker dependency modeling means the utilized model generates or updates speaker-specific information based on historical dialogue or historical speaker information during the dialogue process. The existing dynamic speaker dependency modeling approaches are mainly divided into two categories, sequential structure-based and graph-based methods, according to their dialogue modeling techniques; this section provides an overview of the existing sequential structure-based dynamic speaker dependency modeling approaches.
Earlier work on ERC focused on conversational context, often using structures such as LSTM to integrate contextual information. However, this method ignores the essential impacts of the influence relationships between speakers and themselves on speaker sentiment in a dialogue. The Conversational Memory Network (CMN) [26] is the first method to consider the ERC task’s inter-speaker dependency and intra-speaker dependence features. The CMN first obtains the three modal features corresponding to the current sentence, splices them to obtain multimodal features, and feeds the sentence within the context window to a GRU to obtain the features corresponding to the current moment containing contextual information. Afterward, the CMN sifts through the information between the current sentence features and the previously obtained sentence features containing contextual information through an attention mechanism, obtains the degree of influence between the two types of features in the form of weights, and performs a weighted summation operation to obtain the speaker features corresponding to the current sentence.
Interactive Conversational Memory Network(ICON) [27], on the other hand, introduces an interactive memory unit for multiparty conversation based on the CMN, and its self-influence module (SIM) designed to model intra-speaker dependency by integrating all historical sentences of the speaker corresponding to the current moment with the help of a GRU. Then, the GRU in the dynamic global influence module (DGIM) is used to model the influence between the SIM memory obtained from the SIM module at the current moment and the global memory obtained from the DGIM at the previous moment for the speakers; this step obtains the global state at the current moment and stores it in the memory unit. Subsequently, the memory unit is fused with the current discourse representation using the attention mechanism to determine the final emotion prediction. DialogueRNN is used to model the conversational utterance, the context, and the current speaker’s emotional state with the help of three GRU units, representing the global state, the party-state, and the emotion representation, respectively.
Similar to DialogueRNN, Shenoy proposed a Context-Aware RNN (Multilogue-Net) [28], which uses multiple GRUs to account for the interlocutor state, the interlocutor’s intention, the previous and future emotions, and the context of the dialogue. Unlike DialogueRNN, Multilogue-Net interacts with the information based on pairwise attention to obtain information for judging the speaker’s emotion from different modalities. However, DialogueRNN and Multilogue-Net only consider intra-speaker dependency and ignore inter-speaker dependency. To this end, Zhao et al. [29] designed a Mutual Conversational Detachment Network (MuCDN) that splits the whole conversation into multiple sub-conversations, regarded as potential influence relations between speakers and calculates the relative lengths between sentences based on the discourse tree. Inter-speaker and intra-speaker GRUs can capture the dependencies between speakers within each sub-conversation. The former processes all sentences of the current speaker, while the latter handles all sentences of the non-current speaker. The drawbacks of this approach include disrupting the conversational flow, impeding the comprehension of contextual and posing challenges in revealing the intricacies of inter-speaker dependencies.
To address these issues, Bao et al. [30] introduces a novel structure for modeling speaker dependencies (SGED). SGED comprises two core components: a Conversational Context Encoder (CCE) and a Speaker State Encoder (SSE). The CCE generates current sentence features enriched with contextual information, while the SSE explores intra- and inter-speaker dependencies. Intra-speaker dependencies are established by attending to the speaker dependency from the SSE in the previous moment for the current speaker, encompassing all sentences preceding the current moment. Eventually, the intra- and inter-speaker dependencies derived from the SSE undergo activation through a function, resulting in the speaker dependency at the present moment. The key advantages of this method lie in its effectiveness in probing the intricate interactions within a dialogue, and the SGED module seamlessly integrates with existing methods, enhancing overall performance.
2.3. Dynamic Speaker Dependency Based on Graph Structures
The previous section introduced a methodology for representing dialogues sequentially and modeling dynamic speaker dependencies. However, the disadvantage of a sequential structure is that distance limitations are observed between sentences, which makes it challenging to perform interactions between sentences at longer distances. Similarly, it is difficult for speaker features far from each other to interact effectively, limiting the sequential structure in terms of modeling long-distance contexts and speaker dependencies. With the continuous development of GNNs, researchers in the ERC field have found that simulating dialogues with graph structures can effectively address the shortcomings of sequential structures in cases with speaker interactions. During the process of simulating dialogue with a graph structure, the nodes in the graph often represent sentences at different moments. These sentences can be directly connected through edges, which means that no matter how far apart the sentences are, as long as they connect with edges, they can directly interact to explore the influence relationships between the speakers more effectively. In addition, the research development of GNNs and the advantages of graph structures in speaker interaction tasks have made exploring speaker dependencies with graph structures a mainstream strategy in recent years.
DialogueGCN defines various types of edges based on speaker identities. Sequential relationships help the model understand the flow of discourse and the corresponding speaker relationships, thus enabling it to simulate dialogues more accurately. Joshi et al. [31] proposed that the information reflecting speakers’ emotions in dialogues comes from two primary sources: global information and local information. The global information is the context, and the local information includes the inter-/intra dependence between speakers. COGMEN uses the transformer encoder part of its position embedding module to obtain the global information and then constructs a directed graph by taking the sentence features containing global information as nodes, with four types of edges: past sentences of the current speaker, past sentences of the other speaker, future sentences of the current speaker, and future sentences of the other speaker. Different edges represent the relationships between the speaker’s identities and the temporal information. The constructed directed graph is then fed into a Relational Graph Convolutional Network(R-GCNs) [32] and a graph transformer [33] to obtain sentence features with contextual dependencies and inter-/intra speaker dependencies.DAG-ERC combines the advantages of graphs and the constraints of conversation to determine the construction rules of the DAG: a direction constraint and a tele-information constraint. This compositional approach provides the relative position of the conversation and the speaker’s identity, which helps the model better capture real-life contextual relationships and speaker dependencies.
In addition to the above methods, some speaker dependency modeling methods have also been developed from other perspectives, such as HiTrans, which designs an auxiliary task, determining whether two sentences are from the same speaker, and places the result into a final loss function to improve the model’s sensitivity to speaker information. In addition, with the emergence and development of large-scale text pretraining models, some approaches centered on such models have emerged because training on a large corpus of conversation gives them strong speaker dependency comprehension capabilities. For example, Emoberta uses pre-trained RoBERTa as its core; for it to be able to grasp the influence relationships between speakers, Emoberta splices the sentences and their corresponding speaker names before inputting them in RoBERTa, which enables the model to obtain both contextual and speaker information and thus integrate the influences of both aspects to give better judgments. However, the ERC method based on large pre-trained models is limited by the arithmetic power of the computer and the amount of training data, which makes it difficult to migrate between different scenarios effectively.
3. Multimodal Fusion
In prior research on ERC, a common oversight has been the neglect of differential emotional behaviors exhibited within and across various modalities when modeling conversational context. Developing effective modeling strategies for handling multimodal contextual information is instrumental in yielding more precise emotion prediction results. Furthermore, it is crucial to acknowledge the distinct contributions of emotional expression in multimodal settings. Words and sounds have proven more beneficial in predicting neutral emotions than the visual modality. Hence, when integrating multimodal information for emotion prediction, it becomes imperative to comprehend the unique contributions of each modality and transform them into fusion weights. However, a fundamental challenge arises because different modalities are often represented in distinct feature spaces, making assessing and quantifying their contributions directly intricate. Consequently, a significant avenue of research pertains to the effective fusion of multimodal contextual information in the context of multimodal ERC.
Compared with unimodal emotion recognition, multimodal emotion recognition has many advantages, including expressing richer information with the help of multiple representations. Integrating visual information can reveal verbal cues such as facial expressions and body movements, while audio information helps convey characteristics such as the pitch and volume of a sound. This representation method for fusing multimodal data helps to consider emotional information from different perspectives comprehensively, thus making predictions more accurate, especially for classification situations that are easily confused in unimodal settings. In unimodal emotion recognition experiments, specific dialogue sentences can be incorrectly categorized as ‘angry’ or ‘neutral,’ particularly in the case of the ’frustrated’ emotion category. However, when integrating concurrent analyses of the audio and video modalities, including visual cues such as frowning expressions in the video features and auditory characteristics such as increased volume in the audio features, the model enhances its ability to comprehend emotions, resulting in more precise classifications.
In early studies, to introduce multimodal features to ERC tasks with multimodal settings, researchers typically used cascading methods to integrate features to guide emotion recognition. The researchers proposed the CMN model by concatenating features from all three modalities but ignoring the interactions between the modalities. The CMN first uses the three modal features acquired from the input video, improving the accuracy and enhancing the robustness of emotion recognition from video. However, this method completely ignores the interactions between the processes of extracting helpful information in interactive scenarios. On this basis, researchers further proposed GME-LSTM [34] to perform multimodal information fusion in emotion recognition tasks for each utterance. The experiments showed that multimodal features to the LSTM model without an attention mechanism would lead to declines in the F1 score, proving that although audio and video features provide rich content, they may also have noise.
Researchers in recent years have begun to explore more effective multimodal feature fusion methods, retain high-quality and adequate information during the fusion process, and reduce the influences of redundancy and noise, thereby improving the performance and accuracy of multimodal emotion recognition. Therefore, GME-LSTM uses a gating mechanism at each time step and passes the features through a temporal attention layer. At the same time, works such as DialogueTRM adopt attention mechanisms to guide effective multimodal feature fusion procedures.
However, as researchers have gradually discovered that GNNs can model long-distance contexts and different types of relationships, graph-based methods have become the mainstream approach. These methods ensure that their GNNs select the critical internal context and multimodal interaction information during learning by defining different types of multimodal sentence nodes and designing multimodal interaction information. The MMGCN was the first model to consider the combination of multimodal and contextual information. It uses undirected graphs to explore a more effective method for fusing multimodal interaction and contextual information. However, directly concatenating utterances from various modalities may introduce additional noise.
Furthermore, the MMGCN embeds utterances in a single GNN simultaneously with utterances within other modalities, which poses challenges for multimodal fusion. To solve the above problems, GraphMFT [35] adopts multiple improved GATs to extract the contextual dependencies within modalities and the complementary dependencies between modalities, thus effectively promoting the current discourse and intra-modal and inter-modal discourse interactions. For example, GraphMFT introduces a loss function with four subspaces to constrain the extracted multimodal features for alleviating the heterogeneity problem encountered in multimodal ERC, and it incorporates the PairCC strategy to solve the information propagation direction limitation.
In the current research, the problem with the utilized multimodal feature fusion algorithms is that the interactions among heterogeneous information from different modes must be more fully considered, and it is not sufficient to reflect real emotions under conflicts and differences between modal features. In response to this problem, researchers have explored different fusion strategies. For example, they proposed weighing different modalities while considering the importance differences among multimodal features and assigning weights via importance attention networks. Despite these efforts, multimodal ERC research still needs to be improved, and further consideration needs to be given to the existence of certain complementary and differential information in different modalities and the combination of contextual interactions. Aspects such as speaker dependence and dialogue context are also understudied in multimodal settings. In addition, in multimodal ERC tasks, multimodal connection fusion methods exist in various forms but cannot solve the modal conflict problem effectively. Therefore, when different modalities conflict, the fused modalities of the existing models interfere with each other, producing inaccurate results. Therefore, the current research focusing on multimodal fusion methods should consider how to use the relationships between modalities to eliminate modal conflicts, enabling the constructed models to describe better multimodal fusion features for recognizing emotions in dialogues.
To solve the above-mentioned problems, additional research can delve into the following avenues. First, more intricate and potent modality fusion strategies can be contemplated, ensuring the comprehensive incorporation of the variances between different modalities throughout the feature fusion phase. Second, it is imperative to underscore the pivotal role of contextual cues in enhancing the accuracy of multimodal emotion recognition methods during conversational interactions. This necessitates a comprehensive exploration of strategies for optimizing the utilization of context and speaker-specific dependencies. In addition, introducing more advanced model structures handles multimodal conflicts. Improved multimodal fusion can provide more accurate and effective solutions for tasks such as emotion recognition. In future research, these directions should be further explored, and the existing methods should be continuously improved to advance the field of ERC.
References
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent neural network regularization. arXiv 2014, arXiv:1409.2329.
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734.
- Wöllmer, M.; Metallinou, A.; Eyben, F.; Schuller, B.; Narayanan, S.S. Context-sensitive multimodal emotion recognition from speech and facial expression using bidirectional LSTM modeling. Interspeech 2010. Available online: https://opus.bibliothek.uni-augsburg.de/opus4/frontdoor/deliver/index/docId/76287/file/wollmer10c_interspeech.pdf (accessed on 15 November 2023).
- Majumder, N.; Poria, S.; Hazarika, D.; Mihalcea, R.; Gelbukh, A.; Cambria, E. Dialoguernn: An attentive RNN for emotion detection in conversations. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 6818–6825.
- Li, J.; Ji, D.; Li, F.; Zhang, M.; Liu, Y. HiTrans: A Transformer-Based Context- and Speaker-Sensitive Model for Emotion Detection in Conversations. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 4190–4200.
- Kim, T.; Vossen, P. EmoBERTa: Speaker-aware emotion recognition in conversation with RoBERTa. arXiv 2021, arXiv:2108.12009.
- Sedoc, J.; Gallier, J.; Foster, D.; Ungar, L. Semantic Word Clusters Using Signed Spectral Clustering. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, Canada, 30 July–4 August 2017.
- Ghosal, D.; Akhtar, M.S.; Chauhan, D.; Poria, S.; Ekbal, A.; Bhattacharyya, P. Contextual Inter-Modal Attention for Multi-Modal Sentiment Analysis. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3454–3466.
- Kiela, D.; Bhooshan, S.; Firooz, H.; Perez, E.; Testuggine, D. Supervised Multimodal Bitransformers for Classifying Images and Text. arXiv 2019, arXiv:1909.02950.
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017.
- Ghosal, D.; Majumder, N.; Poria, S.; Chhaya, N.; Gelbukh, A. DialogueGCN: A Graph Convolutional Neural Network for Emotion Recognition in Conversation. arXiv 2019, arXiv:1908.11540.
- Hu, J.; Liu, Y.; Zhao, J.; Jin, Q. MMGCN: Multimodal Fusion via Deep Graph Convolution Network for Emotion Recognition in Conversation. arXiv 2021, arXiv:2107.06779.
- Shen, W.; Wu, S.; Yang, Y.; Quan, X. Directed acyclic graph network for conversational emotion recognition. arXiv 2021, arXiv:2105.12907.
- Xu, S.; Jia, Y.; Niu, C.; Zan, H. MMDAG: Multimodal Directed Acyclic Graph Network for Emotion Recognition in Conversation. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, Marseille, France, 13 June 2022; pp. 6802–6807.
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903.
- Brody, S.; Alon, U.; Yahav, E. How Attentive Are Graph Attention Networks? arXiv 2021, arXiv:2105.14491.
- Zhang, D.; Wu, L.; Sun, C.; Li, S.; Zhu, Q.; Zhou, G. Modeling Both Context-and Speaker-Sensitive Dependence for Emotion Detection in Multi-Speaker Conversations. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 10–16.
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J. Attention is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008.
- Mao, Y.; Sun, Q.; Liu, G.; Wang, X.; Gao, W.; Li, X.; Shen, J. DialogueTRM: Exploring the Intra- and Inter-Modal Emotional Behaviors in the Conversation. arXiv 2020, arXiv:2010.07637.
- Li, Z.; Tang, F.; Zhao, M.; Zhu, Y. Emocaps: Emotion capsule based model for conversational emotion recognition. arXiv 2022, arXiv:2203.13504.
- Zou, S.; Huang, X.; Shen, X.; Liu, H. Improving multimodal fusion with Main Modal Transformer for emotion recognition in conversation. Knowl.-Based Syst. 2022, 258, 109978.
- Zou, S.; Huang, X.; Shen, X.; Liu, H. Hierarchical Dialogue Understanding with Special Tokens and Turn-level Attention. arXiv 2023, arXiv:2305.00262.
- Zhang, C.; Song, D.; Huang, C.; Swami, A.; Chawla, N.V. Heterogeneous Graph Neural Network. arXiv 2020, arXiv:2003.02102.
- Lian, Z.; Liu, B.; Tao, J. CTNet: Conversational Transformer Network for Emotion Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 985–1000.
- Hu, D.; Hou, X.; Wei, L.; Jiang, L.; Mo, Y. MM-DFN: Multimodal Dynamic Fusion Network for Emotion Recognition in Conversations. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022.
- Hazarika, D.; Poria, S.; Zadeh, A.; Cambria, E.; Morency, L.-P.; Zimmermann, R. Conversational Memory Network for Emotion Recognition in Dyadic Dialogue Videos. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LO, USA, 1–6 June 2018; pp. 2122–2132.
- Hazarika, D.; Poria, S.; Mihalcea, R.; Cambria, E.; Zimmermann, R. Icon: Interactive Conversational Memory Network for Multimodal Emotion Detection. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2594–2604.
- Shenoy, A.; Sardana, A. Multilogue-net: A Context-Aware RNN for Multi-Modal Emotion Detection and Sentiment Analysis in Conversation. arXiv 2020, arXiv:2002.08267.
- Zhao, W.; Zhao, Y.; Qin, B. MuCDN: Mutual Conversational Detachment Network for Emotion Recognition in Multi-Party Conversations. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 7020–7030.
- Bao, Y.; Ma, Q.; Wei, L.; Zhou, W.; Hu, S. Speaker-guided Encoder-Decoder Framework for Emotion Recognition in Conversation. arXiv 2022, arXiv:2206.03173.
- Joshi, A.; Bhat, A.; Jain, A.; Singh, A.V.; Modi, A. COGMEN: COntextualized GNN based Multimodal Emotion recognition. arXiv 2022, arXiv:2205.02455.
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; Van Den Berg, R.; Titov, I.; Welling, M. Modeling Relational Data with Graph Convolutional Networks. In Proceedings of the Semantic Web: 15th International Conference, Crete, Greece, 3–7 June 2018.
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph Transformer Networks. In Proceedings of the NeurIPS, Montreal, QC, Canada, 2–8 December 2018.
- Chen, M.; Wang, S.; Liang, P.P.; Baltrušaitis, T.; Zadeh, A.; Morency, L.-P. Multimodal Sentiment Analysis with Word-Level Fusion and Reinforcement Learning. In Proceedings of the ICMI ’17: Proceedings of the 19th ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017.
- Li, J.; Wang, X.; Lv, G.; Wang, X.; Lv, G.; Zeng, Z. GraphMFT: A Graph Network Based Multimodal Fusion Technique for Emotion Recognition in Conversation. Neurocomputing 2023, 550, 126427.
More
Information
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
1.3K
Revisions:
3 times
(View History)
Update Date:
29 Dec 2023
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No