Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Otthein Herzog | -- | 3175 | 2023-12-13 08:35:43 | | | |
| 2 | Rita Xu | -3 word(s) | 3172 | 2023-12-13 08:42:48 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Herzog, O.; Jarke, M.; Wu, S.Z. Digital Twins for Industrie 4.0 in Urban Planning. Encyclopedia. Available online: https://encyclopedia.pub/entry/52655 (accessed on 26 July 2026).
Herzog O, Jarke M, Wu SZ. Digital Twins for Industrie 4.0 in Urban Planning. Encyclopedia. Available at: https://encyclopedia.pub/entry/52655. Accessed July 26, 2026.
Herzog, Otthein, Matthias Jarke, Siegfried Zhiqiang Wu. "Digital Twins for Industrie 4.0 in Urban Planning" Encyclopedia, https://encyclopedia.pub/entry/52655 (accessed July 26, 2026).
Herzog, O., Jarke, M., & Wu, S.Z. (2023, December 13). Digital Twins for Industrie 4.0 in Urban Planning. In Encyclopedia. https://encyclopedia.pub/entry/52655
Herzog, Otthein, et al. "Digital Twins for Industrie 4.0 in Urban Planning." Encyclopedia. Web. 13 December, 2023.
Copy Citation
Digital twins are emerging as a prime analysis, prediction, and control concepts for enabling the Industrie 4.0 vision of cyber-physical production systems (CPPSs) as well as for modeling complex tasks such as urban planning. Today’s growing complexity and volatility cannot be handled by monolithic digital twins but require a fundamentally decentralized paradigm of cooperating and competing digital twins.
multi-agent systems
digital twin
data architecture
Industrie 4.0
Logistics 4.0
urban planning
1. The Evolving Concept of Digital Twins
Over the past 60 years, digitalization has augmented the classical scientific methods of theory and experiment first by simulation and, since the turn of the century, by data-driven methods and machine learning. In engineering, physical and digital simulation programs were initially separated from formal models and physical systems. Since the late 1980’s, model-driven designs emerged in which software systems could be generated to drive physical systems, leading to early versions of cyber-physical systems. In parallel, several projects—adapting the 1990s idea of data warehouses for production settings—pursued the idea of a “product memory” [1][2][3], proposing the collection of data over the lifecycle of products as a basis for product maintenance, improvement, and recently also recycling and other sustainability-oriented “re-” technologies.
Nevertheless, all these approaches looked at either data collection and analytics or at model-driven development and control but rarely at both of them. Only around 2003, Michael Grieves and colleagues at NASA pointed out that these two partial developments needed to be combined in what they called “twinning” [4]. Twinning requires a continuous synchronization loop between observing the real-world (also called physical) twin through a physical-to-virtual link to a digital twin, which in turn controls the real-world twin through a virtual-to-physical link.
Figure 1 visualizes the twinning interplay in the co-evolution of real-world and related digital twins but additionally highlights that the physical-to-virtual link consists of two traditionally separately investigated parts: collected data from controlled sensing (metrology) need to be transformed into purpose-oriented digital shadows (DSs) as a basis for detailed analysis and decision making.
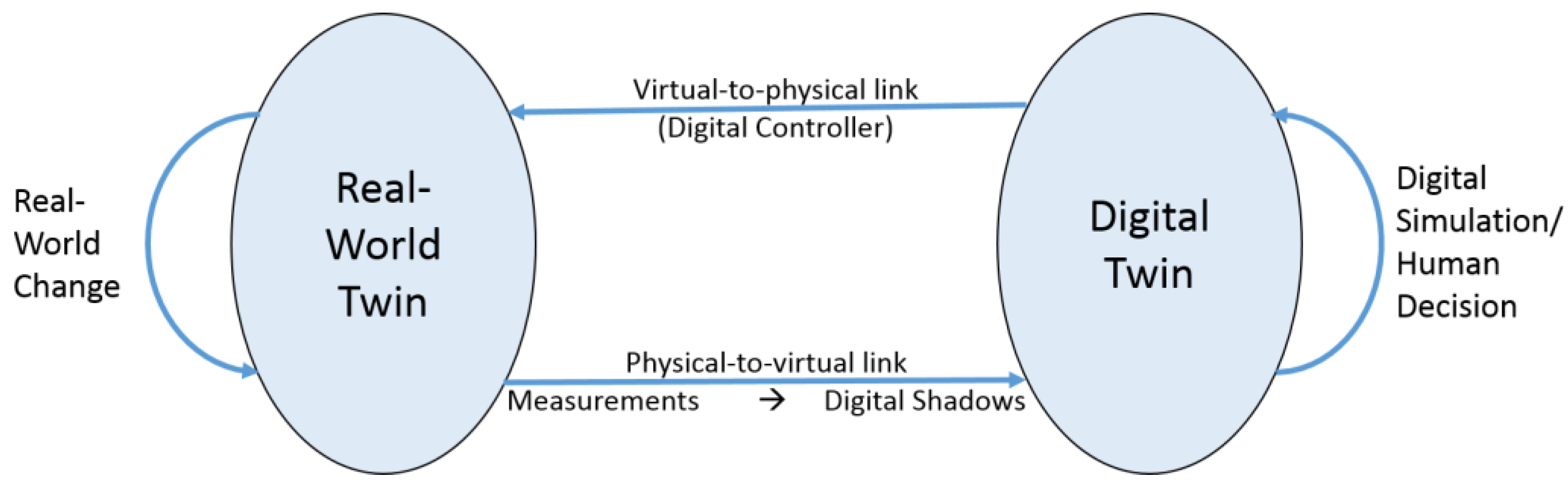
Figure 1. The twinning concept in cyber-physical systems.
Basic twinning systems, as shown in Figure 1, can be interpreted as atomic building blocks within a larger cyber-physical production system (CPPS), which is again monitored and controlled by a higher-level digital twin and can also interact with other CPPSs. Real-world applications do not just involve individual digital shadow links from sources to aggregated data for digital twins. They also demand controlled sharing of such DSs among interoperating digital twins within and across organizations [5].
2. Agent-Oriented Approaches for Cooperating and Competing Digital Twins
Obviously, connectivity and interoperability are the minimal necessary preconditions for supporting cooperating or competing digital twins. For example, in [6] (p.1), a connected digital twin is defined as “a virtual representation of a physical object or process capable of collecting information from the real environment to represent, validate and simulate the physical twin’s present and future behavior. It is a key enabler of data-driven decision making, complex systems monitoring, product validation and simulation and object lifecycle management”.
Today, digital twins are integral parts not only of Industrie 4.0 concepts (named there as “Asset Administration Shells”) in order to secure Industrie 4.0 requirements like ever shorter innovation cycles and mass production with lot size 1 [7]. They are also the technology of choice in all other areas in which the digitization of the analogue world is followed by the digitalization of object and process descriptions: the use and the analysis of data allows for creating autonomous models at a semantic level for the specific real-world aspects, e.g., for process control, simulation and optimization of processes, transportation, logistics, automotives, energy, health, smart cities, and also for mitigating climate change.
The generality of this approach indicates that a versatile technology must be used that is capable of implementing demanding requirements such as rationality, environmental data interpretation, learning, reactivity, pro-active planning according to objectives and goals, and communication, cooperation, and/or competition skills. Digital twins communicate with the environment, including with other digital twins. Therefore, there is a need for a communication infrastructure together with standardized interaction protocols in order to ensure a meaningful communication among digital twins and with the environment. As the concurrency and the complexities of real-world processes can be mapped quite naturally to concurrently acting (autonomous) digital twins, a system of autonomous digital twins might act in a completely decentralized way or in a combination of centralized and decentralized control, depending on the communication structure of the processes to be “twinned”.
Digital twin systems can be made up of several digital twins that interact with each other in order to reach their own and/or system objectives. Consequently, digital twins can act in egoistic and/or cooperative ways, depending on the requirement to maximize their own benefits or to reach a common (sub-) goal.
The technologies that are necessary for the implementation of digital twins can be taken from some Artificial Intelligence fields that have been developed during the past 30 years, such as knowledge representation and knowledge processing, machine learning, and planning, software agents, and multi-agent systems, cf. [8][9]. Systems of agents can be established by several agents that interact with each other, trying to satisfy their own objectives and/or the objectives established for the system.
2.1. AI Perspective: Agent Frameworks and Interaction Protocols
Using AI technologies, goal-oriented or utility-oriented digital twins can be conceptualized as AI-based software agents, as shown in Figure 2.
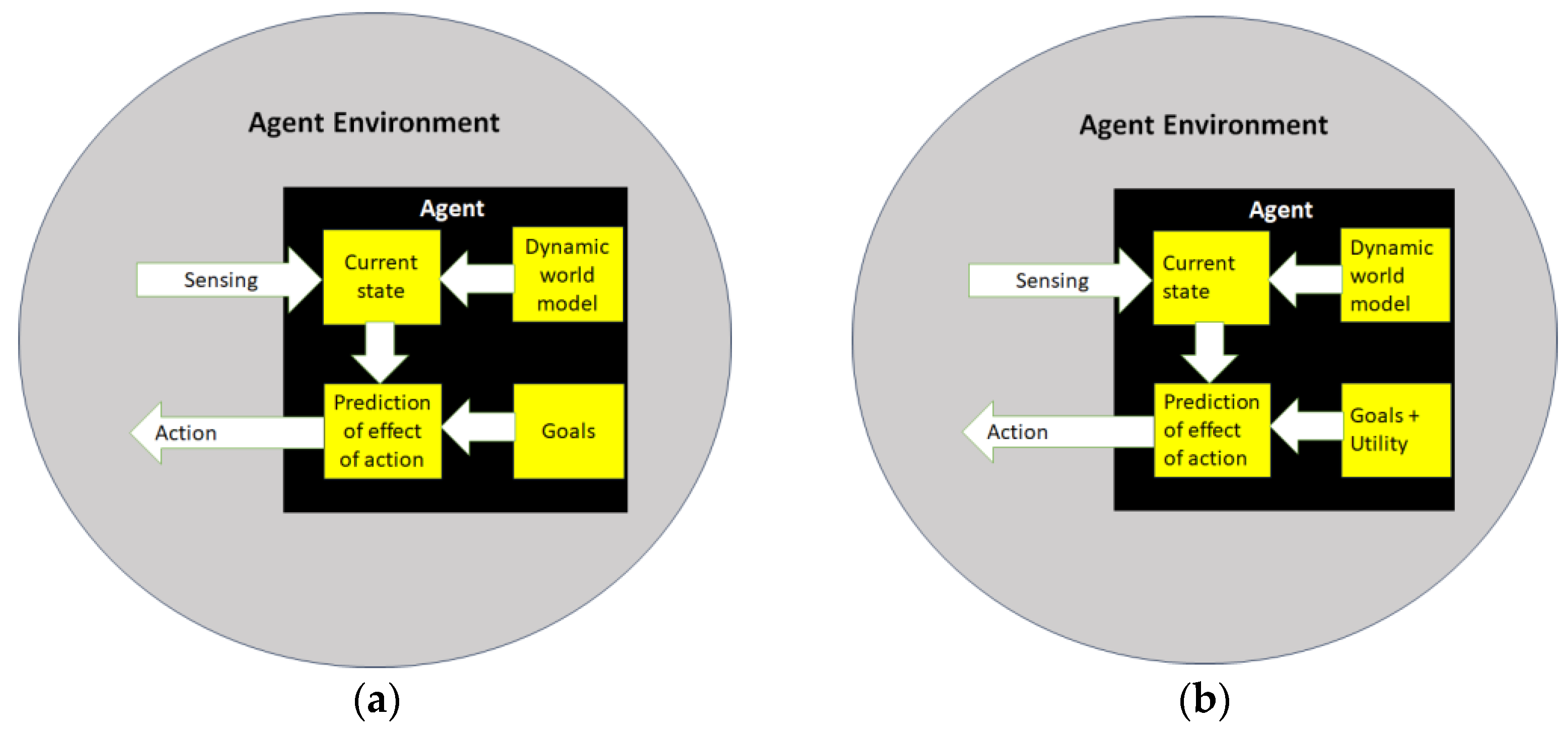
Figure 2. (a) Model-based, goal-oriented and (b) model-based, utility-oriented agent.
Utility-oriented software agents. Cooperation among software agents was deemed necessary for distributed problem solving, as it was obvious that no single agent in a distributed system would have sufficient expertise, resources, or information to solve a problem on its own. This leads to the basic assumption that these agents are benevolent, sharing common goals without the potential for conflicts of interest between agents.
Goal-oriented software agents. However, in many real-world scenarios, it turned out that distributed problems are not always solved by benevolent agents in cooperative settings: the agents could be self-interested actors without sharing common goals. Therefore, the agents in such a competitive setting must act strategically in order to reach their goals, i.e., they must be capable of dynamically coordinating their actions with other agents according to the utilities of their moves. A simplified approach would thus distinguish between cooperative and competitive agents, even if in cooperative settings, specific coordination mechanisms could also be based on competition, e.g., auction protocols.
Using cooperative or competitive multi-agent systems and other AI technologies such as learning and planning, digital twins can be employed for local autonomous process control. Systems of autonomous digital twins which use the Internet of Things and Services can also act together to implement functionalities such as:
-
removing typical blind spots in manufacturing facilities across assets and facilities, e.g., machine health, tank levels, and temperature or humidity levels.
-
Providing resilience of processes when the environment changes.
-
Globally optimizing processes to reduce cost and maximize asset uptime to overcome increasing supply chain pressures, and to satisfy the need to improve sustainability.
-
Implementing digitalized tools and applications for the control and visibility needed to meet these demands, which also aligns with global security and access controls.
-
Enabling systems of digital twins for centralized global data availability and for monitoring remote facilities.
The communication between software agents was standardized already early on and supported through multi-agent frameworks. The Foundation for Intelligent Physical Agents (FIPA) [10] standardized middleware functions in 1996, and it transferred itself to the IEEE Computer Society as a standards committee in 2005. Among the platforms implementing FIPA specifications (for a comparison, see [11]), the JADE framework (Java Agent Development) [12] appears to be one of the active agent frameworks:
It “provides a simple yet powerful task execution and composition model, peer-to-peer agent communication based on asynchronous message passing, a yellow pages service supporting publish subscribe discovery mechanism and many other advanced features that facilitates the development of distributed systems.
A JADE-based system can be distributed across the Internet and can transparently deploy agents on Android and J2ME-CLDC MIDP 1.0 devices. The platform configuration as well as the agent number and locations can be changed at run-time, as and when required. Furthermore, suitable configurations can be specified to run JADE agents in networks characterized by partial connectivity…”
Interaction protocols for advanced communication among agents are an important feature of most frameworks, as they establish semantically limited but powerful interactive conversation methods beyond simple messages. The FIPA framework offers a considerable amount of interaction protocols that can initiate interactions, e.g., to establish auctions in order to optimize sparse resources, e.g., through an English, first-price sealed-bid, Dutch, Vickrey, or all-pay auction. Another interaction offered is an implementation of the contract net protocol [13][14], which is applicable to a fine resolution of controlling tasks in a distributed environment.
The FIPA contract net protocol specifies an anytime algorithm, since it only approximates an optimal solution. This characteristic is useful in dynamic and stochastic environments where the available running times are not known in advance [15]. It has been shown to be adequate for the scheduling of concurrent processes and to result in superior solutions compared with allocation algorithms [16].
2.2. Data Perspective: Efficient Data2Knowledge Mappings and Sovereign Data Exchange
As mentioned in the introduction, data management for interconnected digital twins is an important issue in many domains (cf., e.g., [17] for a detailed analysis in the construction sector). Digital twins face at least two key data challenges: firstly, a high effort for transiting from the metrology to the analytics (digital shadow) stages of data supply for digital twins; secondly, how data exchange and interoperation among multiple digital twins and digital shadows can be architected considering the tension of undisturbed high-performance transfer and preservation of the data and twin owners’ sovereignty.
Concerning the first challenge, the metrology stage of the physical-to-virtual link faces an enormous heterogeneity of data sources (sensor data streams, legacy machinery, ERP systems, tracks of human–machine interaction), which already in itself poses a major challenge to meaningful and secure data sharing [18]. Equally, the digital shadow production offers an increasing method richness of data- and model-driven analytics and machine learning [19][20]. This complex m:n relationship between multiple data sources and multiple analytics methods requires at least a quadratic number of different individual mapping efforts between the metrology and analytics parts, which has to be repeated whenever sources or analytics methods are added, changed, or deleted.
To reduce this effort, an intense discussion about standardized formats for the interchange between both subtasks emerged. Industrie 4.0 has standardized the OPC/Unified Architecture [21], with successful application examples such as [22]. OPC is also investigating additional service-oriented language options such as XML/JSON. However, though language standardization obviously helps, it does not reduce the number of m × n necessary semantic mappings. Proposed highly sophisticated information supply networks lining up the workflow of processing and storing the digital shadow steps along the physical-to-virtual link [21][23][24] offer important technical infrastructure, but they do not solve the basic complexity issue either.
The formal goal here is to reduce the basic complexity from quadratic to quasi-linear, i.e., from m × n to d × (m + n). Here, d represents a small number of bridging data models with the property that each language allows (a) for representing sensor fusion results for a large class of widely used sensor application domains, which (b) can be directly used with a very class of analytics “at the press of a button”. Encouragingly, there does exist a first highly successful example of such a “data model in the middle”: the Object-Centric Event Log (OCEL) formalism. It offers a simple relational model of activities, objects, and events on which all kinds of process mining or robotic process automation tools can directly operate without any further effort [25]. Any sensor results that can be represented as networks of discrete events on defined objects (e.g., ERP data, discrete transport operations, etc.) can be mapped to this data model. Market-leading process mining start-ups such as Celonis demonstrate the value of such a purpose-oriented data model, which they also support by high-performance special-purpose DBMS. Research for further such data models, e.g., in production engineering, is actively underway.
Concerning the second challenge (data sharing), the introductory discussion around Figure 1 showed that the MAS interaction protocols of digital twins imply massive flows of heterogeneous data. Typical data management goals mentioned in the scientific and practitioner literature include producing added value by sharing data within and across company boundaries, enabling more variety (data heterogeneity) while ensuring veracity (data quality and provenance), and reducing the costs of managing large volumes (“big data”) with near real-time velocity.
To address these goals, several architecture patterns evolved from traditional DBMS, as depicted in Figure 3. Since the late 1990s, data warehouses radically separated operational transaction processing (OLTP) from online analytic processing (OLAP) to facilitate historical data analytics and reduce interference between short transactions and broad analytics [26]. In Extract-Transform-Load (ETL) processes, the Transform part ensured meaningful integration and data cleaning for OLAP but required manual schema integration for linking new data sources, even if OLAP analytics might only require these data later or never. Moreover, OLAP data were far away from representing the current OLTP state. Even this latter point could be partially addressed by main memory databases. Last but not least, dramatically failed IT mergers, e.g., in banking, demonstrated that data warehouses did not work well in today’s volatile corporate environment with frequent mergers, acquisitions, and re-organizations. This also makes them problematic for supporting large societies of interacting digital twins.
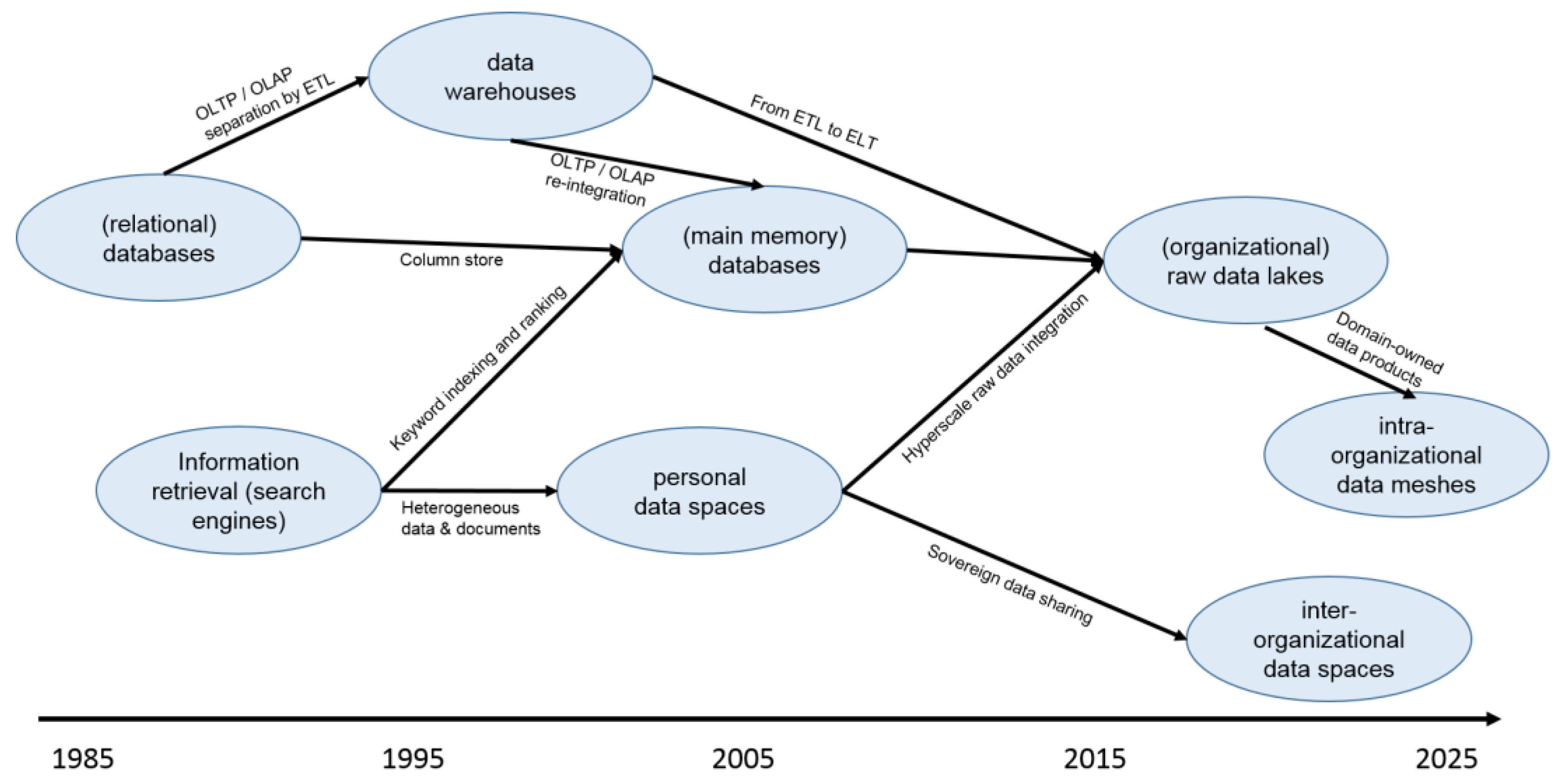
Figure 3. Evolution of data management and analytics paradigms over four decades.
By loading raw data and delaying the Transform action until its results are actually needed, data lakes [27] turn ETL into ELT, enabling “pay-as-you-go” instead of requiring full upfront Transform investment. Following Microsoft research on (personal) data spaces [28], they also adopt a “schema-on-read” approach, which helps users manage the growing wilderness of structured, semi-structured, and unstructured media data from different perspectives. Corporate strategists appreciate that loading and storing un-interpreted raw data with flexible schema-on-read facilitates corporate change: in a merger, you simply throw the raw data of the new partners into your data lake, and then have time to gradually understand and re-organize the semantic relationships among the data. Due to their flexibility, data lakes are popular as shared data stores for digital twins, especially in large organizations, including “hyper-scalers” such as Google or Amazon.
For many highly specialized SMEs, this hyper-scaler dominance caused concern about possible loss of “hidden champion” corporate knowledge. Such organizations want data sovereignty: to take advantage of the added value of sharing data but retain full freedom to decide and monitor who uses the data, and how.
Observing these concerns, [29] proposed an extension of the personal data space or data lake idea by a concept of sovereign data sharing, called industrial data spaces. This was quickly adopted by government and developed in large-scale projects on architectural standards, models, algorithms, and real-world applications [30]. On the political level, the ideas found their way into national and European data strategies, including, e.g., GAIA-X [31].
Technically, sovereign data sharing in data spaces is enabled by encapsulating data export and import facilities in so-called connectors [32], coordinated by auxiliary components in a data space infrastructure:
-
Brokers help to match offers suitable for a data request
-
Optionally supported by vocabulary services for supporting semantic matching, and by
-
Federated data integration and machine learning from heterogeneous sources.
-
Contract management and monitoring services (e.g., Clearing House).
-
Identification services ensure that only members of a data space can operate in it.
In the original IDSA Architecture, such services are offered by a central organization. In contrast, GAIA-X requires decentralized federation services. For example, a data space application in industrial benchmarking [33] shows how both secret input data of the benchmark participants and the confidential algorithms of the benchmarking company can be protected despite the sharing.
The data space philosophy also caused rethinking of the central data lake IT strategy of large companies and public organizations (e.g., city governments). The new data mesh strategies [34] transfer the ownership of, and responsibility for, domain-specific data and digital twins to individual business domains, while de-emphasizing central corporate data lakes and IT departments. Data meshes thus aim to improve responsiveness to customers and promote business domain-driven digital twins. Simplistically, they can be seen as a top-down approach to reach the initially bottom-up concept of data spaces. This is but one striking example of the relevance of the next topic, strategy modeling in digital twin and human organizational agent networks.
2.3. Strategy Perspective: Analysis of Cooperation and Competition in Agent Networks
Data lake, data space, and data mesh approaches are not just technical concepts. They represent different philosophies of socio-technical data and service ecosystems, in which digital twins help human organizations pursue their goals, strategies, and (inter-)actions [35][36].
In the data space literature as well as in MAS languages, this is documented in multi-level information models [37]. Based on such models, MAS developers can be supported by visual agent modeling languages. However, due to their wide range of applications, such languages still require the generality of imperative programming languages. This puts application domain experts at a disadvantage, since they have to work through a lot of implementation complexity to contribute to large multi-agent digital twin models.
To empower a broader range of stakeholders to contribute to the design of multi-agent ecosystems, the social requirements modeling language i* [38] mimics the way domain experts and other humans naturally talk about such ecosystems—in terms of intentions, dependencies, and actions or tasks. Due to its concise graphical notation, which closely resembles the common-sense way of talking about social actors, i* has been shown in hundreds of cases to greatly reduce the effort required for discussing model details between developers and domain experts [39].
Specifically, i* combines two core aspects of goal- and actor-oriented requirements engineering. Researchers illustrate its graphical notation in Figure 4 with a small real-world i* documentation of a strategy debate on urban water management in a low-income megacity quarter (cf. [39]):
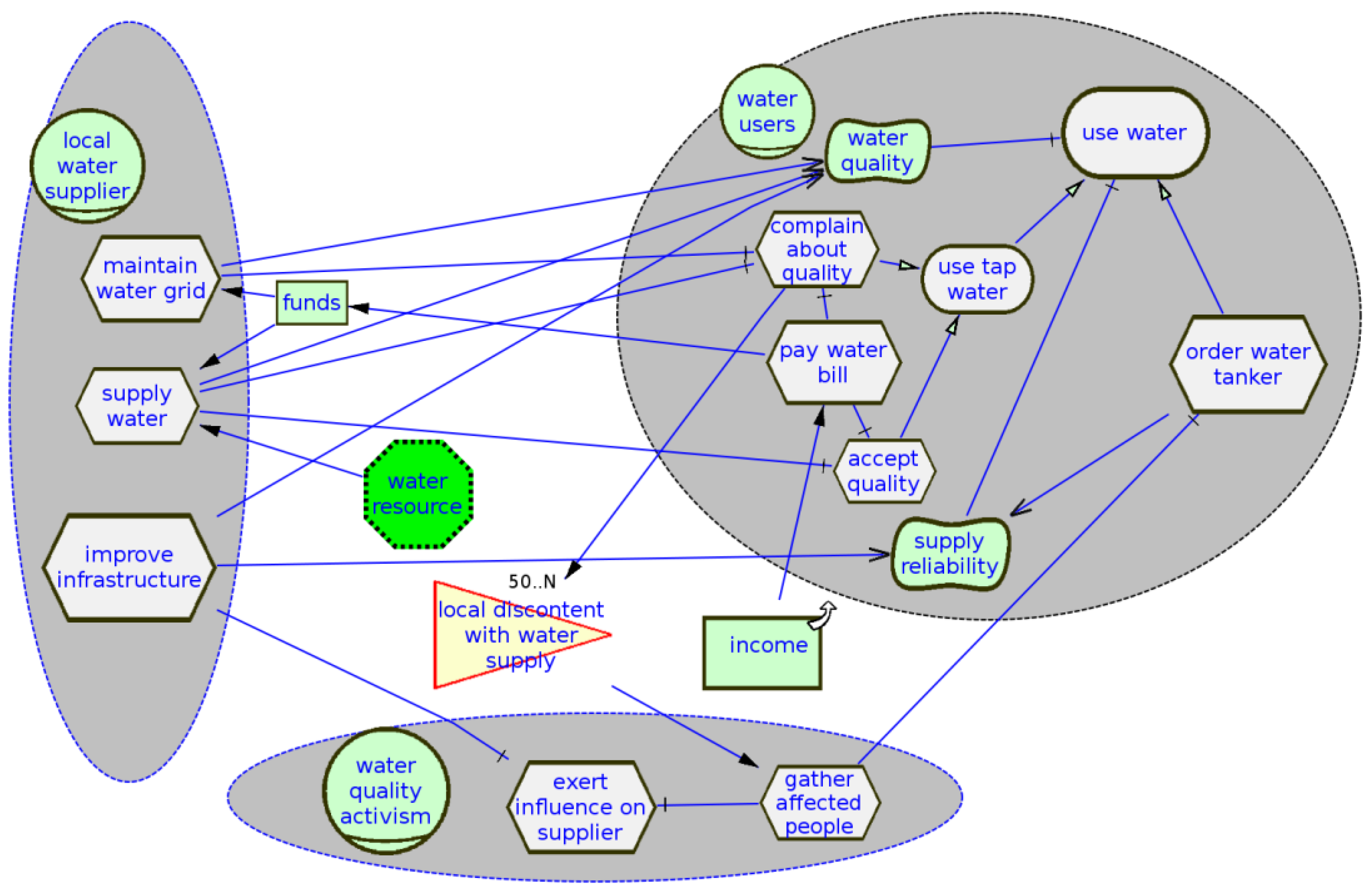
Figure 4. Initial water user-centered i* model of urban water management.
-
In the graphical i* notation, actors (agent roles) are represented by grey background shapes, water user and local water supplier. A goal-task hierarchy for each actor describes its goals and possible task combinations (actions) for their achievement. The goals thus serve as the strategic rationale for subgoals and tasks. Specific (must-have) goals such as use water are represented as ovals, whereas soft goals (also called non-functional requirements), such as water quality or supply reliability, look a bit like toppled 8′s. A goal such as use water can be pursued by two alternatives: by the direct task/action order water tanker or by pursuing a subgoal use tap water with associated subtasks.
-
Many goals or tasks cannot be achieved by the actor alone but need to be delegated to others, creating a network of strategic dependencies, represented as directed links between the various kinds of nodes. For example, achievement of the water quality soft goal by water users depends on fulfillment of the tasks maintain water grid and supply water by a local water supplier. Satisfiability of the latter task, however, depends on a sufficient water resource.
References
- Wahlster, W. (Ed.) SemProM: Foundations of Product Memories for the Internet of Production; Springer: Berlin/Heidelberg, Germany, 2013.
- Li, J.; Tao, F.; Cheng, Y.; Zhao, L. Big data in product lifecycle management. Int. J. Adv. Manuf. Technol. 2015, 81, 667–684.
- Bergsjö, D. Product Lifecycle Management: Architectural and Organizational Perspectives; Chalmers University of Technology: Gothenburg, Sweden, 2013; ISBN 9789173852579.
- Grieves, M. Digital Twin—Maintaining Excellence through Virtual Factory Replication; White Paper, Florida Institute of Technology: Melbourne, FL, USA, 2014.
- van Dyck, M. Emergence, Evolution, and Management of Innovation Ecosystems. Ph.D. Thesis, RWTH Aachen, Aachen, Germany, 2022.
- Botín-Sanabria, D.M.; Mihaita, A.-S.; Peimbert-García, R.E.; Ramírez-Moreno, M.A.; Ramírez-Mendoza, R.A.; Lozoya-Santos, J.d.J. Digital Twin Technology Challenges and Applications: A Comprehensive Review. Remote Sens. 2022, 14, 1335.
- Mourtzis, D. (Ed.) Design and Operation of Production Networks for Mass Customization in the Area of Cloud Technology; Elsevier: Amsterdam, The Netherlands, 2022.
- Wooldridge, M. Agent-based software engineering. IEE Proc.-Softw. 1997, 144, 26–37.
- Russell, S.J.; Norvig, P. Artificial Intelligence: A Modern Approach, 4th ed.; Pearson Education: Hoboken, NJ, USA, 2021.
- FIPA. IEEE Foundation for Intelligent Physical Agents. 2022. Available online: http://fipa.org/ (accessed on 5 May 2023).
- Wikipedia. Comparison of Platforms for Software Agents. Wikipedia 2023. Available online: https://en.wikipedia.org/wiki/Comparison_of_platforms_for_software_agents (accessed on 5 May 2023).
- JADE. The Java Agent Development Framework. Available online: https://jade-project.gitlab.io/ (accessed on 5 May 2023).
- Smith, R.G. The Contract Net Protocol: High-level communication and control in a distributed problem solver. IEEE Trans. Comput. 1980, 29, 1104–1113.
- Schillo, M.; Kray, C.; Fischer, K. The eager bidder problem: A fundamental problem of DAI and selected solutions. In Proceedings of the 1st International Joint Conference on Autonomous Agents Multiagent Systems, Bologna, Italy, 15–19 July 2002; ACM: New York, NY, USA, 2002; pp. 599–606.
- Gath, M. Optimizing Transport Logistics Processes with Multiagent Planning and Control. Ph.D. Thesis, University of Bremen, Bremen, Germany, 2016.
- Icarte Ahumada, G.A. Negotiations for Agent-Based Concurrent Process Scheduling of Resources in Highly Dynamic Environments. Ph.D. Thesis, University of Bremen, Bremen, Germany, 2021.
- Merino, J.; Xie, X.; Moretti, N.; Chang, J.; Parlikad, A. Data integration for digital twins in the built environment based on federated data models. Proceedings of the Institution for Civil Engineers—Smart Infrastructure and Construction, 2023. Available online: https://www.icevirtuallibrary.com/doi/10.1680/jsmic.23.00002 (accessed on 13 November 2023).
- Volz, F.; Sutschet, G.; Stojanovic, L.; Usländer, T. On the role of digital twins in data spaces. Sensors 2023, 23, 7601.
- Jones, D.; Snider, C.; Nassehi, A.; Yon, J.; Hicks, B. Characterizing the digital twin—A systematic literature review. CIRP J. Manuf. Sci. Technol. 2020, 29, 36–52.
- von Rueden, L.; Mayer, S.; Beckh, K.; Georgiev, B.; Giesselbach, S.; Heese, R.; Kirsch, B.; Walczak, M.; Pfrommer, J.; Pick, A.; et al. Informed machine learning—A taxonomy of integrating prior knowledge into learning systems. IEEE Trans. Knowl. Data Eng. 2023, 35, 614–633.
- OPC Foundation. The Industrial Interoperability Standard. Available online: https://opcfoundation.org/developer-tools/documents/?type=Specification (accessed on 27 July 2023).
- Lipp, J.; Rath, M.; Vroomen, U.; Bührig-Polaczek, A. Flexible OPC UA data load optimizations on the edge of production. In Proceedings of the International Conference Enterprise Information Systems, Selected Papers; Springer: Berlin/Heidelberg, Germany, 2020; pp. 43–61.
- Bauernhansl, T.; Hartleif, S.; Felix, T. The digital shadow of production—A concept for the effective and efficient information supply in dynamic industrial environments. Procedia CIRP 2018, 72, 69–74.
- Liebenberg, M.; Jarke, M. Information systems engineering with Digital Shadows—Concepts and use cases in the Internet of Production. Inf. Syst. 2023, 114, 102182.
- Van der Aalst, W. Concurrency and objects matter! Disentangling the fabric of real operational processes to create digital twins. In Theoretical Aspects of Computing—ICTAC 2021, Proceedings of the ICTAC 2021, Virtual, 8–10 September 2021; Springer: Heidelberg, Germany, 2021; pp. 3–17.
- Gans, G.; Jarke, M.; Kethers, S.; Lakemeyer, G. Continuous requirements engineering for organization networks: A (dis)trustful approach. Requir. Eng. J. 2003, 8, 4–22.
- Hai, R.; Koutras, C.; Quix, C.; Jarke, M. Data lakes: A survey of functions and systems. IEEE Trans. Knowl. Data Eng. 2023, 35, 1–20.
- Halevy, A.; Franklin, M.; Maier, D. Principles of data space systems. In Proceedings of the 25 ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, Chicago, IL, USA, 26 June 2006; pp. 1–9.
- Jarke, M.; Quix, C. On warehouses, lakes, and spaces—The changing role of conceptual modeling for data integration. In Conceptual Modeling Perspectives; Cabot, J., Gomez, C., Pastor, O., Sancho, M., Teniente, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2017; pp. 231–245.
- Otto, B.; ten Hompel, M.; Wrobel, S. (Eds.) Designing Data Spaces: The Ecosystem Approach to Competitive Advantage; Springer Nature: Berlin/Heidelberg, Germany, 2022; p. 580.
- GAIA-X. GAIA-X Framework. 2023. Available online: https://gaia-x.eu/framework (accessed on 5 August 2023).
- Giess, A.; Hupperz, M.; Schoormann, T.; Moeller, F. What does it take to connect? Unveiling characteristics of data space connectors. In Proceedings of the Hawaii International Conference on System Sciences (HICSS), Honolulu, HI, USA, 3–6 January 2024.
- Pennekamp, J.; Lohmüller, J.; Vlad, E.; Loos, J.; Rodermann, N.; Sapel, P.; Fink, I.; Schmitz, S.; Hopmann, C.; Jarke, M.; et al. Designing Secure and Privacy-Preserving Information Systems for Industry Benchmarking. In Proceedings of the CAiSE 2023, Zaragoza, Spain, 12–16 June 2023; Springer LNCS 13901. 2023; pp. 1–17.
- Deghani, Z. How to Move beyond a Monolithic Data Lake to a Distributed Data Mesh. Available online: https://martinfowler.com/articles/data-monolith-to-mesh.html (accessed on 25 October 2023).
- van Dyck, M.; Lüttgens, D.; Piller, F.; Brenk, S. Interconnected digital twins and the future of digital manufacturing: Insights from a Delphi study. J. Prod. Innov. Manag. 2023, 40, 475–505.
- Scheider, S.; Lauf, F.; Möller, F.; Otto, B. A reference system architecture with data sovereignty for human-centric data ecosystems. Bus. Inf. Syst. Eng. 2023, 65, 577–595.
- Gleim, L.; Pennekamp, J.; Liebenberg, M.; Buchsbaum, M.; Niemietz, P.; Knape, S.; Epple, A.; Storms, S.; Trauth, D.; Bergs, T.; et al. FactDAG: Formalizing data interoperability in an Internet of Production. IEEE Internet Things J. 2020, 7, 3243–3253.
- Yu, E. Modeling Strategic Relationships for Process Engineering. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 1996.
- Baier, K.; Mataré, V.; Liebenberg, M.; Lakemeyer, G. Towards integrated intentional agent simulation and semantic geodata management in complex urban systems modeling. Comput. Environ. Urban Syst. 2015, 51, 47–58.
More
Information
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
502
Revisions:
2 times
(View History)
Update Date:
13 Dec 2023
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No