Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Jiang Du | -- | 168 | 2023-11-23 11:06:13 | | | |
| 2 | Jiang Du | + 1658 word(s) | 1826 | 2023-11-23 11:26:38 | | | | |
| 3 | Wendy Huang | Meta information modification | 1826 | 2023-11-23 12:49:22 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Du, J.; Wei, Q.; Wang, Y.; Sun, X. Basic Process of Binary Code Similarity Analysis. Encyclopedia. Available online: https://encyclopedia.pub/entry/51985 (accessed on 25 June 2026).
Du J, Wei Q, Wang Y, Sun X. Basic Process of Binary Code Similarity Analysis. Encyclopedia. Available at: https://encyclopedia.pub/entry/51985. Accessed June 25, 2026.
Du, Jiang, Qiang Wei, Yisen Wang, Xiangjie Sun. "Basic Process of Binary Code Similarity Analysis" Encyclopedia, https://encyclopedia.pub/entry/51985 (accessed June 25, 2026).
Du, J., Wei, Q., Wang, Y., & Sun, X. (2023, November 23). Basic Process of Binary Code Similarity Analysis. In Encyclopedia. https://encyclopedia.pub/entry/51985
Du, Jiang, et al. "Basic Process of Binary Code Similarity Analysis." Encyclopedia. Web. 23 November, 2023.
Copy Citation
Against the backdrop of highly developed software engineering, code reuse has been widely recognized as an effective strategy to significantly alleviate the burden of development and enhance productivity. However, improper code citation could lead to security risks and license issues. With the source codes of many pieces of software being difficult to obtain, binary code similarity analysis (BCSA) has been extensively implemented in fields such as bug search, code clone detection, and patch analysis.
binary code similarity analysis
source code
pre-compilation
compilation
assembly
linking
feature extraction
feature representation
feature comparison
1. Introduction
With the progression of science and technology, electronic devices, software, and the Internet have become integral components of daily life. The continual improvement of Internet technology, the frequent updates and upgrades of software applications, and the increasingly complex network environment, coupled with the ease of use of software, has brought immense convenience to people. However, it also presents significant challenges to software developers in terms of development and maintenance. The utilization of open source software not only reduces the workload of developers but also transfers the maintenance responsibilities to third-party software developers. Despite the benefits of the extensive use of open source software, including improved efficiency in development, it also entails several risks. For instance, the incorporation of open source software that contains vulnerabilities can lead to the introduction of such vulnerabilities into the engineering code. Additionally, the unauthorized use of open source software in project code may result in license compliance issues.
The “2022 Open Source Security and Analysis Report” [1] released by Synopsys highlights the prevalence of open source code in various industries. Among the 17 industries studied, those related to computer hardware semiconductors, network security, energy and clean technology, and the Internet of Things have code bases that are entirely composed of open source code. The remaining industries, which range from 93% to 99% in terms of open source code usage, still have significant portions of their code bases relying on open source software. The report also indicates that the extensive use of open source code in different industries has brought both benefits and risks. For example, in the Internet of Things sector, 100% of codebases use open source software, with 64% of those codebases being vulnerable. Similarly, in the aerospace, automotive, transportation, and logistics industries, 97% of codebases contain open source code and 60% of those codebases have security vulnerabilities.
In late 2021, a zero-day vulnerability was identified in ApacheLog4j, a commonly used program. This vulnerability, known as Log4Shell (CVE-2021-44228) [2], enables an attacker to execute arbitrary code on an affected server. The first documented attacks using this vulnerability occurred on December 9, initially aimed at the Java Edition 1.18 of the Microsoft’s Minecraft game. According to the attack cases documented in the GitHub repository YfryTchsGD/Log4jAttackSurface, this vulnerability affects a range of popular services and platforms, including Apple iCloud, QQ Mailbox, Steam Store, Twitter, and Baidu search. This highlights the potential far-reaching consequences of vulnerabilities in widely used open source codebases.
In terms of license security, works of innovation (including software) are protected by exclusive copyright as a matter of default. Any use, copying, distribution, or modification of the software without the express permission of the creator/author in the form of an authorized license is legally prohibited. Even the most lenient open source licenses impose obligations on users when utilizing the software. The potential for license risk arises when the license of open source code present in a codebase may be in conflict with the overarching license of that codebase. For instance, the GNU General Public License (GPL) generally regulates the utilization of open source code in commercial software, but commercial software vendors may neglect the mandates of the GPL license, which may result in license conflicts. With respect to industries, the computer hardware and semiconductor industries have the highest percentage of codebases with open source license conflicts at 93%, followed by the Internet of Things industry at 83%. Conversely, healthcare, health tech, and life sciences have the lowest percentage of codebases with open source license conflicts at 41%.
BCSA constitutes a strategic approach to address security vulnerabilities arising from code reuse, under the inhibitive prerequisite of source access denial. By measuring and comparing the similarity between binary and vulnerable functions, a preliminary assessment of the potential vulnerability properties of the target function can be performed. Such comparison framework can be utilized for a singular binary function match, as well as extended to multiple matches, that is, indexing the target function in a global vulnerability database. Analogously, this methodology can also aid in revealing covert acts of code plagiarism as well as potential licensing risks.
The reuse of open source code or licensing security issues can pose threats to both network security and copyright protection and make it more challenging to obtain source code during program analysis. Dynamic analysis tools that are stable and adaptable for use in embedded devices are limited in availability. As a result, researchers have started to investigate the detection of code reuse using BCSA techniques and have achieved significant progress. However, there is a lack of comprehensive literature that presents the recent advancements in BCSA techniques, inspired by technologies such as natural language processing (NLP) and graph neural networks (GNN). A literature review conducted by Haq et al. [3] provides a summary of the development of BCSA technology in the two decades prior to 2019 and a systematic analysis of the technical details of BCSA methods. Kim et al. [4] analyzed 43 BCSA papers from 2014 to 2020, outlined the problems in the current research, and offered solutions. Yu et al. [5] evaluated the content of 34 works, focusing specifically on their performance in searching for vulnerabilities in embedded device firmware.
Research on software similarity analysis comprises both source code similarity analysis and Binary Code Similarity Analysis(BCSA). Source code similarity analysis is often performed whenever the source code is readily available, to discern the reuse of vulnerable code segments or exploit unauthorized utilization of code, particularly in interpretive languages such as Java or Python. However, in a majority of circumstances, the target programs are in binary format, and procuring the source code presents a formidable challenge. Consequently, BCSA plays a pivotal role in code similarity analysis research. The ensuing sectors provide an overview of BCSA from two perspectives: the transformation process from source to binary code, and the foundational procedures implicated in BCSA.
2. Compile Preprocessing
Binary code represents the machine code that results from the compilation of source code and can be executed directly via the central processing unit. This code comprises a series of binary digits (0 s and 1 s) and is not easily readable by humans. To facilitate the analysis of binary code, reverse engineering techniques are employed to translate the machine language code into assembly language, and tools such as debuggers are utilized to simplify the manual examination process.
As shown in Figure 1, the typical process of transforming source code into binary code usually encompasses four stages: pre-compilation, compilation, assembly, and linking. The pre-compilation phase primarily manages operations such as the expansion of header files, substitution of macros, and the elimination of comments. The compilation stage carries out lexical, syntax, and semantic analysis on the code, optimizes it, and transforms it into assembly code. The assembly stage transforms assembly code into machine code. Finally, the linking stage integrates the compiled object files into a binary form to generate the final executable file.
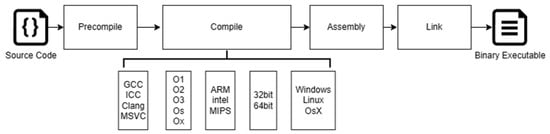
Figure 1. Compilation Process from Source Code to Binary.
The compilation process is responsible for accurately converting the source code into a binary format that the CPU can execute directly. However, the outcome of this process is not fixed, as various factors such as the choice of compiler, optimization options, target CPU architecture, and operating system can all have an impact on the final machine code produced. Consequently, the same source code can result in different binary code outputs through different compilation paths, presenting a challenge for BCSA.
3. Basic Process of BCSA
The central objective of BCSA is to establish the provenance of two binary functions by analyzing their similarities. This analysis forms the foundation for determining the likeness of binary functions. In certain circumstances, the one-to-one comparison of binary functions can be expanded, such as in the case of vulnerability search, where it may be extended to one-to-many function comparison, and in code clone detection, where it may be expanded to many-to-many function comparison.
This research presents a clear depiction of the technical characteristics of BCSA technology by organizing the work into three stages, as depicted in Figure 2. These stages are the feature extraction stage, the feature representation stage, and the feature comparison stage.
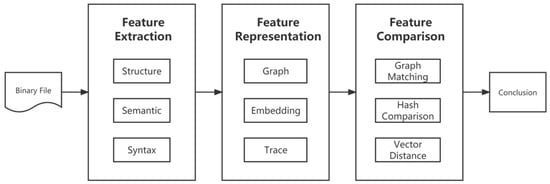
Figure 2. The overall process of the method.
Phase 1: Feature Extraction. The primary task in this stage is to obtain the inherent features of the binary function through the utilization of analysis tools such as IDA Pro [6], BAP [7], Angr [8], Valgrind [9], etc. These inherent features refer to those that are directly obtained from the analysis tools without any additional processing, such as program control flow graphs and call graphs. The input to this stage is a set of raw binary functions, such as binary files, and the output is the raw binary function features. These features are then subjected to further processing in the feature representation stage before being compared in the feature comparison stage. As an illustration, the work performed in the feature extraction stage in Gemini [10] involves the extraction of function control flow graphs (CFGs) and basic block information.
Phase 2: Feature Representation. The main objective of this stage is to process the inherent features of the function obtained in the feature extraction stage in accordance with the author’s requirements and preferences. The input of this stage is the inherent features of the function as produced by the feature extraction stage, and the output is a form of data that can be directly utilized for similarity calculation in the feature comparison stage. As an example, the work performed in the feature representation stage in Gemini [10] encompasses two main tasks: first, the basic block information is transformed into a digital vector representation, serving as nodes in the control flow graph (CFG), resulting in the creation of an ACFG with basic block attribute information. The ACFG is then represented as a vector through the use of an end-to-end neural network, providing a representation of the function that encompasses both its structural and semantic information. This vector representation is used to directly calculate the similarity of the functions in the feature comparison stage.
Phase 3: Feature Comparison. The primary task of this stage is to employ an appropriate method to calculate the similarity between pairs of functional features generated in the feature representation stage. The input of this stage is the representation of the functional features directly produced by the feature representation stage, and the output is the score of similarity between the two functions obtained through the similarity calculation. As an illustration, in the case of Gemini [10], the feature comparison stage employs the cosine distance method to determine the similarity between two feature vectors representing two functions.
References
- 2022 Open Source Security and Analysis Report . analyst-reports. Retrieved 2023-11-23
- CVE-2021-44228 . CVE - Common Vulnerabilities and Exposures. Retrieved 2023-11-23
- Irfan Ul Haq; Juan Caballero; A Survey of Binary Code Similarity. ACM Comput. Surv. 2021, 54, 1-38.
- Dongkwan Kim; Eunsoo Kim; Sang Kil Cha; Sooel Son; Yongdae Kim; Revisiting Binary Code Similarity Analysis Using Interpretable Feature Engineering and Lessons Learned. IEEE Trans. Softw. Eng. 2022, 49, 1661-1682.
- Yu, Y.; Gan, S.; Qiu, J.; et al. Binary Code Similarity Analysis and Its Applications on Embedded Device Firmware Vulnerability Search. Journal of Software 2022, 33, 4137-4172.
- IDA Pro . hex-rays. Retrieved 2023-11-23
- David Brumley; Ivan Jager; Thanassis Avgerinos; Edward J. Schwartz. BAP: A Binary Analysis Platform; Springer Science and Business Media LLC: Dordrecht, GX, Netherlands, 2011; pp. 463-469.
- Fish Wang; Yan Shoshitaishvili. Angr - The Next Generation of Binary Analysis; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, United States, 2017; pp. 8-9.
- Nicholas Nethercote; Julian Seward. Valgrind; Association for Computing Machinery (ACM): New York, NY, United States, 2007; pp. 89-100.
- Xiaojun Xu; Chang Liu; Qian Feng; Heng Yin; Le Song; Dawn Song. Neural Network-based Graph Embedding for Cross-Platform Binary Code Similarity Detection; Association for Computing Machinery (ACM): New York, NY, United States, 2017; pp. 363-376.
More
Information
Subjects:
Computer Science, Software Engineering
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
777
Revisions:
3 times
(View History)
Update Date:
23 Nov 2023
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No