Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Iulia Știrb | -- | 1582 | 2023-10-10 21:49:51 | | | |
| 2 | Jessie Wu | + 15 word(s) | 1597 | 2023-10-11 04:33:23 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Știrb, I.; Gillich, G. Mapping of the NUMA-BTDM Algorithm. Encyclopedia. Available online: https://encyclopedia.pub/entry/50082 (accessed on 25 June 2026).
Știrb I, Gillich G. Mapping of the NUMA-BTDM Algorithm. Encyclopedia. Available at: https://encyclopedia.pub/entry/50082. Accessed June 25, 2026.
Știrb, Iulia, Gilbert-Rainer Gillich. "Mapping of the NUMA-BTDM Algorithm" Encyclopedia, https://encyclopedia.pub/entry/50082 (accessed June 25, 2026).
Știrb, I., & Gillich, G. (2023, October 10). Mapping of the NUMA-BTDM Algorithm. In Encyclopedia. https://encyclopedia.pub/entry/50082
Știrb, Iulia and Gilbert-Rainer Gillich. "Mapping of the NUMA-BTDM Algorithm." Encyclopedia. Web. 10 October, 2023.
Copy Citation
Through Low-Level Virtual Machine (LLVM)-compiling infrastructure, one can build just-in-time (JIT) compilers which are used to interpret the LLVM IR (Intermediate Representation) corresponding to new syntactic rules as part of a new programming language invented by the developer. In this case, the LLVM JIT is used to compile the code which is not part of the language definitions of clang (LLVM front end). LLVM JIT can also trigger LLVM optimizations on the LLVM IR.
LLVM
JIT compiler
number of cores
number of logical cores
NUMA systems
1. Introduction
The NUMA-Balanced Thread and Data Mapping (NUMA-BTDM) algorithm [1] maps the threads to the cores depending on their type and on the hardware details of the underlying machine. Mapping is performed by traversing the communication tree and assigning a core to each thread in the tree [2]. The NUMA-BTDM algorithm [1] performs logical mapping [2] by inserting a pthread_setaffinity_np call [3] in the Low-Level Virtual Machine (LLVM) IR (Intermediate Representation) of the input code after each pthread_create call [3]. The pthread_setaffinity_np call [3] maps the thread to one or several cores. However, the real mapping is completed at runtime by calling the pthread_setaffinity_np call [3].
2. Obtaining the Hardware Architecture Details of the Underlying Architecture
To obtain the hardware architecture detail to customize the mapping, the NUMA-BTDM algorithm [1] executes the system call twice from inside the LLVM IR code. The first system call gives the number of cores of the underlying architecture and the second system call gives the total number of logical cores. Dividing the number of logical cores by the number of cores gives the number of logical cores per CPU used by the custom mapping in the NUMA-BTDM algorithm [1], assuming the architecture is homogeneous.
The physical number of cores is obtained by executing, from the code of the NUMA-BTLP algorithms [4], the system calls with the following parameter: system(“cat/proc/cpuinfo | awk ‘/^processor/{print $3}’ | wc -l; grep -c ^processor/proc/cpuinfo”). The logical number of cores is obtained by executing the system with the following parameter: system(“grep ^cpu\\scores/proc/cpuinfo | uniq | awk ‘{print $4}’”). The/proc/cpuinfo file in Linux is written at every system start-up and contains relevant hardware information about the machine. By dividing the result of the second system call by the result of the first, the logical number of cores per processing unit is obtained. The number of cores and the number of logical cores per processing unit are used in the mapping of the NUMA-BTDM algorithm [1].
3. Mapping Autonomous Threads
To obtain the autonomous threads, the communication tree is traversed and the autonomous threads are stored in a list. Then, the thread is mapped, uniformly processing units in the following manner:
coreIDForThreadi = floor((k × (i − 1)) modulo j)
where i = 1→threadNo, threadNo = total number of autonomous threads
and k = (threadNo (total number of autonomous threads))/(coreNo (total number of cores))
where i = 1→threadNo, threadNo = total number of autonomous threads
and k = (threadNo (total number of autonomous threads))/(coreNo (total number of cores))
Given the thread ID for an autonomous thread, the information is stored in an unordered_map defined by (key, value) pairs, in which the thread ID is the key and the ID of the core to which the thread is mapped is the value. Then, the LLVM IR input code is parsed and found on every pthread_create call [3], which creates an autonomous thread; a pthread_setaffinity_np call [3] is inserted after it, mapping the autonomous thread to its core by using the information in the unordered_map. The corresponding core of the autonomous thread is quickly accessed due to the hash-based implementation of the unordered_map that stores the pairs (threads ID, core ID).
4. Mapping Side-By-Side Threads
The communication tree is traversed searching for side-by-side threads. Once a side-by-side thread is found, it is added to an unordered_map similar to autonomous threads. Once all side-by-side threads are added to the unordered_map, the code is parsed to reach the pthread_create calls [3] corresponding to each side-by-side thread. The call is reached uniquely by the thread ID using the containing function, i.e., the called parent function, and by the executing function, i.e., the called function attached to the thread, to reach the information that has been stored inside the tree node.
Every node in the communication tree corresponds to a pthread_create call [3] that creates a thread. Moreover, multiple nodes in the communication tree can define the same thread. A shared flag between multiple nodes in the tree that represent the same thread is set to “mapped” in the tree node once the first side-by-side thread, e.g., that is created enclosed in a loop structure, is mapped. Therefore, the static analysis of the NUMA-BTLP algorithm [4] considers all the threads created in a loop to all have the same mapping [2]. Moreover, the static analysis considers that the pthread_create call [3] in a loop maps a single thread because the compiler only parses a pthread_create call [3] from the static point of view [2]. So, the relation between the affinity of the mapped thread(s) and the pthread_create call [3] is one-to-one.
Another way of having multiple nodes in the communication tree defining the same thread is when the same pthread_create call [3] is called from another code path. In the static analysis of the NUMA-BTLP algorithm [4], two or many nodes in the communication tree can each describe the same thread, meaning the thread has the same ID, the same parent function and function attached in multiple nodes, when the parent function is called from different paths in the LLVM IR code. In this case, the static analysis [4] considers that the pthread_create call [3] creates the same thread from whichever path is called.
There is also another way of having multiple nodes in the communication tree pointing to the same thread. The same pthread_create call [3] can be represented by multiple nodes in the tree, showing that the thread created by the Pthreads call [3] has different data dependencies with different nodes from the communication tree. For instance, a thread that is side-by-side related to two threads will be the son of each of the two threads in the communication tree. Let us discuss this situation. The pthread_create calls [3] corresponding to the son thread and to the two parent threads in the generation tree are reached by parsing the LLVM IR code, and data dependencies are found between the son thread and the two other so-called parent threads. Finally, the two parent threads will determine the son threads to be added to the communication tree in two different places, as a son of the first parent thread and as a son of the second parent thread. Having reached the pthread_create call [3] of the son thread, the pthread_setaffinity_np calls [3] for the son thread and for the parent threads to be inserted in the LLVM IR in the following way. The son thread is added to the communication tree as a son of the first parent thread. The son thread reunites its affinity with the affinity of the first parent thread, resulting in its new affinity. The son thread is added to the second parent thread in the communication tree. It reunites its newly computed affinity (computed as a son of the first thread) with the affinity of the second parent, resulting a new affinity for the son threads which is updated automatically in the son node from the first and the second parent threads. A good example for such a case is a data dependency between two threads created earlier in the parent function and another thread created afterwards in the same parent function which depends on the data used by the two threads.
In Figure 1, there is a thread with ID 0 which is the main thread executing the main function and the threads with IDs 1 and 2 are created using pthread_create calls [3] from inside the main function. The figure shows the communication tree for the threads described earlier. Given that thread 0 has data dependencies with thread 1, and thread 1 has data dependencies with thread 0 and thread 2, all threads in the figure are of the side-by-side type. According to the mentions in the paragraph below, thread 1 appears in two places in the communication tree because it is in side-by-side relation with two threads, namely 0 and 2. Thread with ID 0 is mapped on core 0 and the thread with ID 2 is mapped on core 1, so the son thread with ID 1 of both threads with ID 0 and 2 will be mapped on cores 0 and 1, therefore taking the affinity of both parent threads.
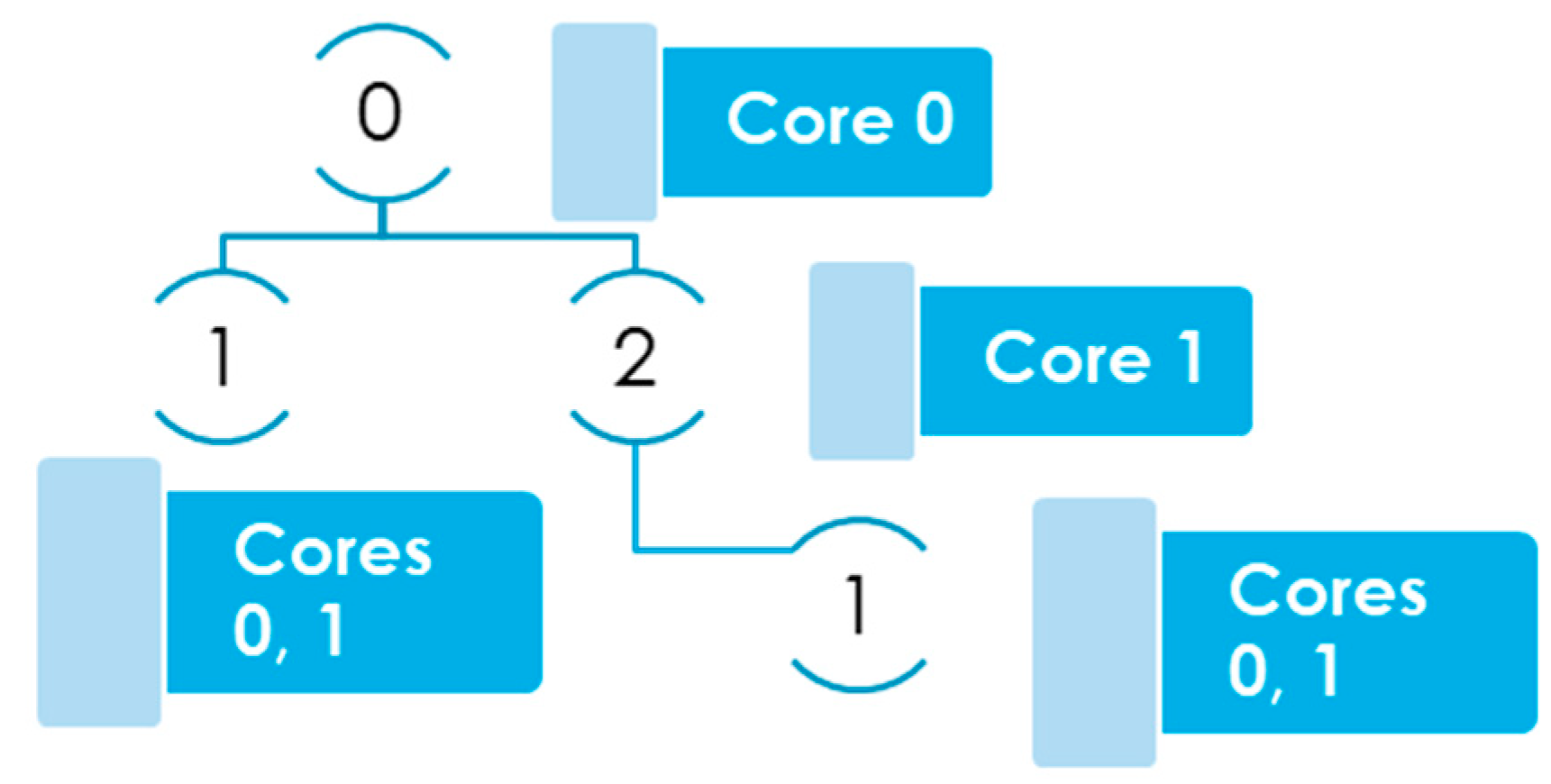
Figure 1. Mapping of a side-by-side thread with ID 1 having multiple parents in the communication tree.
5. Mapping Postponed Threads
Postponed threads are each mapped to the less loaded core [2] after mapping the autonomous and the side-by-side-threads. The less loaded core is considered the one that has the lowest number of threads assigned to it at a specific moment. To find the less loaded core, the unordered_map is traversed and the (key, value) pairs are reversed and added to a map. Therefore, the (key, value) pairs in the unordered_map will become (new_key, new_value) in the map, where the new_key is a value in the unordered_map (i.e., the value becomes the thread ID) and the new_value is the key from the unordered_map (i.e., the key becomes the list of core IDs where the thread is mapped). The map container is sorted, ascending by the number of threads assigned to each core. The postponed threads will always be mapped, one by one, to the first core in the map. However, if the first core changes, the postponed threads will be mapped to the new first core in the map.
References
- Știrb, I. NUMA-BTDM: A thread mapping algorithm for balanced data locality on NUMA systems. In Proceedings of the 2016 17th International Conference on Parallel and Distributed Computing, Applications and Technologies (PDCAT), Guangzhou, China, 16–18 December 2016; pp. 317–320.
- Știrb, I. Extending NUMA-BTLP Algorithm with Thread Mapping Based on a Communication Tree. Computers 2018, 7, 66.
- Pthreads(7)-Linux Manual Page. Available online: https://man7.org/linux/man-pages/man7/pthreads.7.html (accessed on 4 February 2021).
- Știrb, I. NUMA-BTLP: A static algorithm for thread classification. In Proceedings of the 2018 5th International Conference on Control, Decision and Information Technologies (CoDIT), Thessaloniki, Greece, 10–13 April 2018; pp. 882–887.
More
Information
Subjects:
Computer Science, Software Engineering
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
644
Revisions:
2 times
(View History)
Update Date:
11 Oct 2023
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No