Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Eui Chul Lee | -- | 1324 | 2023-08-15 10:44:26 | | | |
| 2 | Rita Xu | -3 word(s) | 1321 | 2023-08-15 10:59:34 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Lee, K.; Kim, S.; Lee, E.C. Facial Expression Image Classification. Encyclopedia. Available online: https://encyclopedia.pub/entry/48072 (accessed on 26 July 2026).
Lee K, Kim S, Lee EC. Facial Expression Image Classification. Encyclopedia. Available at: https://encyclopedia.pub/entry/48072. Accessed July 26, 2026.
Lee, Kunyoung, Seunghyun Kim, Eui Chul Lee. "Facial Expression Image Classification" Encyclopedia, https://encyclopedia.pub/entry/48072 (accessed July 26, 2026).
Lee, K., Kim, S., & Lee, E.C. (2023, August 15). Facial Expression Image Classification. In Encyclopedia. https://encyclopedia.pub/entry/48072
Lee, Kunyoung, et al. "Facial Expression Image Classification." Encyclopedia. Web. 15 August, 2023.
Copy Citation
As emotional states are diverse, simply classifying them through discrete facial expressions has its limitations. Therefore, to create a facial expression recognition system for practical applications, not only must facial expressions be classified, emotional changes must be measured as continuous values.
facial expression classification
facial expression regression
arousal
valence
1. Introduction
Facial expression recognition (FER), an indicator for emotion recognition, is the most widely used nonverbal means by which humans express emotions [1]. In the field of computer vision, FER involves using algorithms or deep learning operations to discriminate the facial expression from a face image. With the recent development of deep learning networks such as convolutional neural networks (CNNs) [2][3][4] and transformers [5][6] that take images as input, most algorithms displaying state-of-the-art (SOTA)-level accuracy are deep learning-based approaches. In particular, deep learning methods tends to show much better performance than handcrafted feature-based methods when subjects are wearing glasses or hats that cause facial occlusion. Because FER is applied to emotion recognition and human computer interaction-based services rather than simple facial expression classification, the importance of FER in practical environments outside the lab has increased [7]. Consequently, deep learning-based approaches have become the main research direction. FER has reached a level of commercialization on edge devices such as mobile or embedded environments, and lightweight facial expression recognition models that minimize degradation of accuracy are being actively pursued as a major research topic. Fortunately, deep learning-based FER has progressed to the extent of being lightweight and producing fast inference on edge device based on hardware optimization and acceleration.
Interactive systems that include multi-modal approaches for emotion recognition using camera and microphone sensors are being researched for driver monitoring and human–computer interaction systems for more advanced affective computing [8]. Therefore, the necessity of fast and accurate facial expression recognition is becoming an increasingly important research topic.
Researchers introduce a knowledge distillation (KD) approach for training a student model based on a state-of-the-art (SOTA)-level teacher model of more than 4 G (×109) multiply-accumulate operations (MAC) of computation, thereby reducing the computation to 0.3 G (×109) MAC. MAC is a metric used to assess the amount of computation required for model inference, and represents the number of multiplication and accumulation operations. According to this metric, the proposed method uses more than 50 times less computation than the existing models. This means that it can be applied to different types of on-device programs, making it universally applicable. Furthermore, because it can predict facial expressions in real time, it can observe instantaneous facial expressions such as micro-expressions. Researchers propose a facial expression recognition learning method using a teacher bound that can improve both classification and regression performance by learning both loss of classification and regression problems, not only simple KD. The proposed method shows more than 10% performance improvement compared to SOTA methods, with improved performance in both valence and arousal measurements.
Multi-task EfficientNet-B2 is known to display SOTA performance with an accuracy of 63.03% [9], according to the literature [10]. The proposed method has been confirmed to provide the best results considering model size and processing speed, and is an approach that can be executed in real-time on mobile and embedded systems with a computation time only 10% that of other SOTA-level approaches. Therefore, researchers conducted research to improve model performance and render the model lightweight enough that it can be used on mobile devices in real-time.
2. Emonet
Emonet proposed a fast and accurate FER model on the challenged dataset without any constraints on face angle or the presence of glasses, hats, etc. Emonet is suitable for real-time applications, as it incorporates face alignment and jointly estimates categorical and continuous emotions in a single pass. Emonet was tested on three challenging datasets collected under naturalistic conditions, thereby demonstrating that it outperforms all previous methods [11].
Emonet’s representation vectors and soft labels are used as the teacher model’s output for knowledge distillation. Emonet infers facial landmarks from a network designed for face alignment, and uses emotional layers with an attention mechanism based on landmark inference results to achieve better classification accuracy, valence, and arousal regression than previous works. In the case of the proposed student model, researchers do not design a network responsible for landmark inference, showing that it is possible to achieve a similar level of accuracy faster than that of the teacher model using only the existing CNN method. Regarding the KD results, the multiply-accumulate (MAC) of the teacher model is 15.3 G, whereas the MAC of the student model is 0.3 G, which is 50 times faster; this makes it possible to operate in mobile and embedded environments.
3. Knowledge Distillation
KD is a lightweight model development technique that transfers the knowledge of a model with good performance and a large amount of computation to a smaller model with a lighter amount of association and faster processing speed. This technique was proposed by Hinton et al., and can be applied to various classification problems [12]. During classification, the value of the ground truth and the value predicted by the teacher are used by the student model during learning. In the case of the ground truth, the correct answer class is hard-labeled as 1 and other classes are hard-labeled as 0. However, most of the results of the predicted teacher model are soft-labeled in the form of the largest correct value using softmax [13]. This is a lightweight technique first introduced in [12], with an easier-to-understand equation introduced in [14]. Equation (1) is the formula used to calculate the total loss in KD. Here, is the cross-entropy loss, σ() is the softmax loss, refers to the output logits of the student model, refers to the output logits of the teacher model, y is the ground truth, α is a balancing parameter, and T is the temperature hyperparameter.
where denotes the cross-entropy loss [15] and σ denotes the softmax loss. Therefore, the first term on the right refers to the cross-entropy loss between the correct answer and the student model, whereas the second term refers to the cross-entropy loss between the predictions of the teacher and student models. The degree to which the student mimics the teacher can be controlled by adjusting α. This method is outlined in Figure 1.
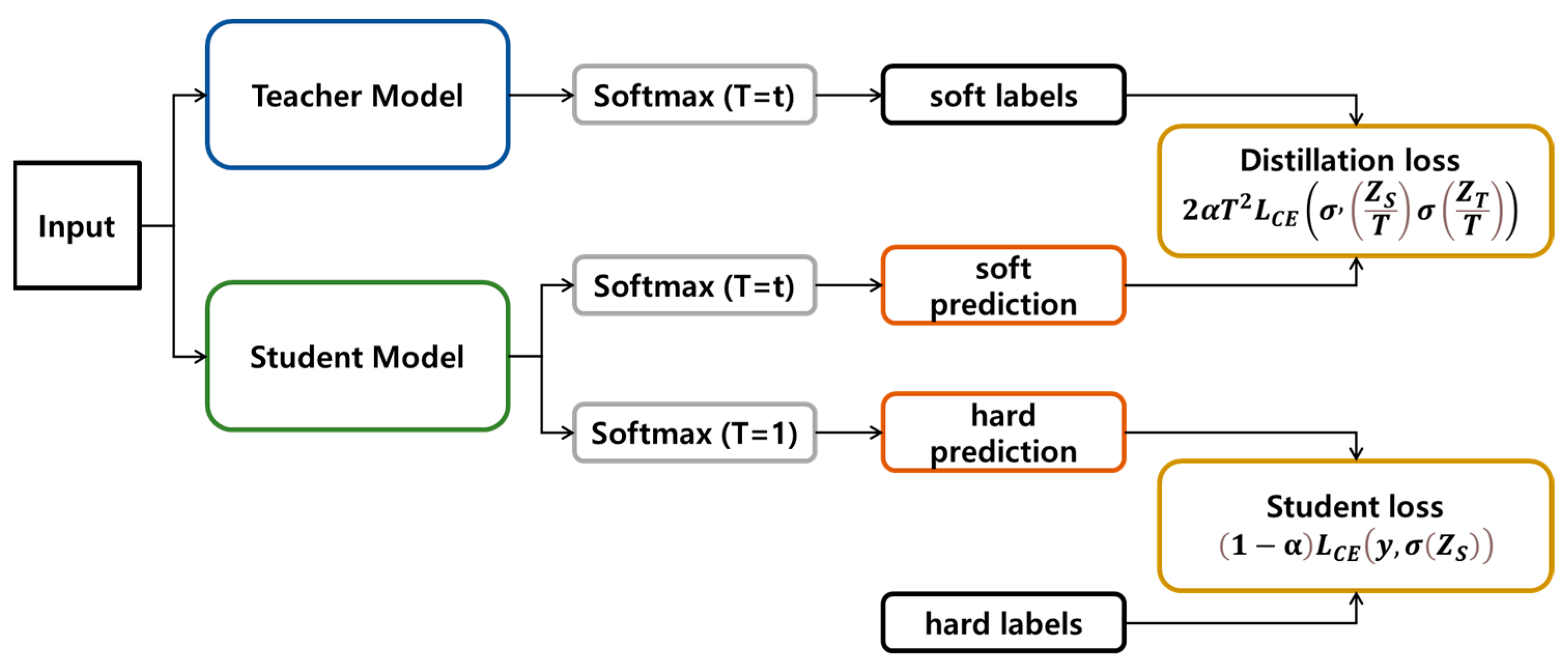
Figure 1. Overall explanation of knowledge distillation.
KD is applied during learning, specifically, the part corresponding to the expression that can be classified by the facial expression label values. A total of eight facial expressions (neutral, happiness, sadness, anger, contempt, disgust, surprise, fear) [16] expressed in Emonet were learned.
4. Teacher Bound
Knowledge distillation is a method used in classification. However, many deep learning models have various outputs, and there is a regression problem among the outputs. Therefore, the method proposed by Chen at al. uses a teacher bound to learn the value of the teacher model for the regression problem [17]. This method applies a large loss, similar to a penalty, only when the performance of the student model is lower than that of the teacher model by a certain extent, and uses the student model’s own loss when performance improves. The formula for this method is expressed in Equation (2), where denotes the regression value predicted by the student model, y denotes the correct answer value, and Rt denotes the value predicted by the teacher model. In Equation (2), if the loss of the student model is greater than the loss of the teacher model by m or more, is applied to ; if it is smaller, is 0. Finally, as shown in Equation (3), the final loss uses with applied.
References
- Papers with Code—Facial Expression Recognition (FER). Available online: https://paperswithcode.com/task/facial-expression-recognition (accessed on 20 April 2023).
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015.
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016.
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015.
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017.
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is W orth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Online, 3–7 May 2021.
- Farzaneh, A.H.; Qi, X. Facial Expression Recognition in the Wild via Deep Attentive Center Loss. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 5–9 January 2021; pp. 2401–2410.
- Busso, C.; Bulut, M.; Lee, C.-C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive Emotional Dyadic Motion Capture Database. Lang Resour. Eval. 2008, 42, 335–359.
- Savchenko, A.V.; Savchenko, L.V.; Makarov, I. Classifying Emotions and Engagement in Online Learning Based on a Single Facial Expression Recognition Neural Network. IEEE Trans. Affect. Comput. 2022, 13, 2132–2143.
- The Latest in Machine Learning | Papers with Code. Available online: https://paperswithcode.com/ (accessed on 11 April 2023).
- Gerczuk, M.; Amiriparian, S.; Ottl, S.; Schuller, B. EmoNet: A Transfer Learning Framework for Multi-Corpus Speech Emotion Recognition. IEEE Trans. Affect. Comput. 2021. early access.
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531.
- Bridle, J. Training Stochastic Model Recognition Algorithms as Networks Can Lead to Maximum Mutual Information Estimation of Parameters. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 27–30 November 1989; Morgan-Kaufmann: Burlington, MA, USA, 1989; Volume 2.
- Tung, F.; Mori, G. Similarity-Preserving Knowledge Distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019.
- Zhang, Z.; Sabuncu, M.R. Generalized Cross Entropy Loss for Training Deep Neural Networks with Noisy Labels. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 2–8 December 2018.
- Ekman, P. Universal Facial Expressions of Emotion. Calif. Ment. Health Res. Dig. 1970, 8, 151–158.
- Takamoto, M.; Morshita, Y.; Imaoka, H. An Efficient Method of Training Small Models for Regression Problems with Knowledge Distillation. In Proceedings of the IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Shenzhen, China, 6–8 August 2020.
More
Information
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
533
Revisions:
2 times
(View History)
Update Date:
15 Aug 2023
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No