Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Francesco Beritelli | -- | 1230 | 2023-07-11 22:10:28 | | | |
| 2 | Wendy Huang | Meta information modification | 1230 | 2023-07-12 04:20:37 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Avanzato, R.; Beritelli, F.; Lombardo, A.; Ricci, C. Heart Digital Twin. Encyclopedia. Available online: https://encyclopedia.pub/entry/46660 (accessed on 25 June 2026).
Avanzato R, Beritelli F, Lombardo A, Ricci C. Heart Digital Twin. Encyclopedia. Available at: https://encyclopedia.pub/entry/46660. Accessed June 25, 2026.
Avanzato, Roberta, Francesco Beritelli, Alfio Lombardo, Carmelo Ricci. "Heart Digital Twin" Encyclopedia, https://encyclopedia.pub/entry/46660 (accessed June 25, 2026).
Avanzato, R., Beritelli, F., Lombardo, A., & Ricci, C. (2023, July 11). Heart Digital Twin. In Encyclopedia. https://encyclopedia.pub/entry/46660
Avanzato, Roberta, et al. "Heart Digital Twin." Encyclopedia. Web. 11 July, 2023.
Copy Citation
Today’s healthcare facilities require new digital tools to cope with the rapidly increasing demand for technology that can support healthcare operators. The advancement of technology is leading to the pervasive use of IoT devices in daily life, capable of acquiring biomedical and biometric parameters, and providing an opportunity to activate new tools for the medical community. Digital twins (DTs) are a form of technology that are gaining more prominence in these scenarios. The heart DT is proposed for the evaluation of electrocardiogram (ECG) signals by means of an artificial intelligence component.
digital twin
microservices
heart DT
smart healthcare
IoT Sensors
deep learning
1. Heart DT Architecture and Implementation
The creation of a heart DT involves the presence of various functional components both in the digital and real world. The implementation of such a system requires the use of technologies capable of making the entire system scalable, dynamic, and resilient. For this reason, a modular approach was chosen, dividing the workflow into functional blocks.
The enabling technology combines microservices, which natively possess characteristics that perfectly fit with the requirements of the heart DT architecture, such as scalability, robustness, and isolation.
The following technologies were used for the development of the architecture: Docker [1] as the execution environment for microservices, while Kubernetes [2] was chosen for their orchestration.
The functional blocks for the implementation of the proposed architecture with the corresponding software applications are described below.
Figure 1 provides a block representation of the proposed system.
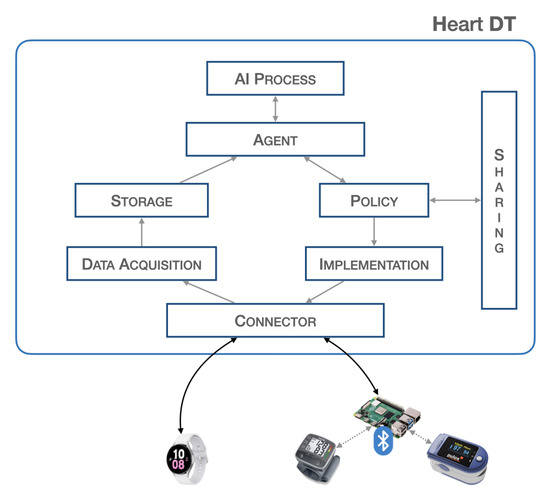
Figure 1. Heart DT architecture.
The blocks described are, furthermore, all independent of each other and are activated when an underlying block sends and schedules possible actions. Such a structure allows for the creation of a dynamic and scalable heart DT that can host a large volume of data and can interact with other elements.
-
Connector:The connector block is responsible for establishing connections with the physical world, allowing bidirectional data transfer. It is necessary to ensure connectivity with various communication protocols such as HTTP, MQTT, etc., and guarantee the safety of communications so as not to invalidate data and adapt the data format to the platform. The platform is designed to have a single endpoint, i.e., a single IP address that all sensors point to. There are proxy policies in place that allow for discrimination of the respective connector based on the path. If communication requires higher level of security, such as control of actuators, VPN tunnels will be established within the connector block to ensure the highest level of security. This architecture respects all principles of GDPR. This block consists of two PODs (PODs are the smallest deployable units of computing that you can create and manage in Kubernetes, https://kubernetes.io/docs/concepts/workloads/pods/, accessed on 19 April 2023) that establish the connection with the outside world. In particular, there may be a POD that implements a REST API server for the acquisition of biomedical data from the physical world, and a second POD that passes this information to the higher-level blocks. In this scenario, since the implementation in the physical world is not expected, any POD that schedules commands to any actuators can not be found. SERVICES are configured to expose services outside the Kubernetes cluster via NodePort.
-
Data Acquisition:The data acquisition block is responsible for acquiring the data, it filters and preprocesses the data before storage. At the implementation level, there is a need to manage various PODs for filtering and preprocessing raw data. In particular, the first POD is set up to communicate with the connector block, the second POD performs data resampling, and the third POD extracts a specific time window. At the end of these processes, the data is sent to the database in a specific previously defined format.
-
Storage:The storage block contains a database that stores the acquired data. This is useful because many applications need to have a significant amount of historical data for better analysis. This block contains three PODs: the first POD runs a database instance (such as mysql), the second POD performs queries such as inserting and extracting data from it, whereas the third POD communicates with the other blocks. Implementing this block requires configuring a Volumemounts to ensure data consistency in the event of an abnormal system shutdown.
-
Agent:The agent block is the main element responsible for starting (according to specific policies) the inference process to validate the data extracted from the database. Furthermore, once the output from the validation is obtained, it is used to send commands to the physical world or share the information with other elements. The implementation of this block requires the development of various PODs: a POD that manages the time and schedule of all operations, a POD that extracts data from the database, a POD that passes this information to the AI process block, and a POD that interacts with the policy and implementation blocks.
-
AI process:The AI process block is responsible for validating the real-time data previously captured through the inference process. At the implementation level, this block consists of a POD that receives data from the agent and another POD that performs inference and returns the result. The latter POD contains the trained neural network model.
-
Policy:The policy block is responsible for defining the boundaries that the processed data and information must have, specifying the limits within which it is or is not possible to pass certain information, thus avoiding modifying certain parameters beyond certain thresholds.This block consists of a POD containing a descriptor, listing all the information-sharing policies and thresholds for implementing actions, through actuators, in the real world.
-
Implementation:The implementation block is responsible for executing, with the authorization of the policy block, the corrective actions suggested by the agent or other DTs to the actuators. The implementation block also manages connections with actuation devices operating in the physical world, and adapts the information from higher-level components to the physical devices. The implementation takes place through a POD that defines specific operations and commands to be scheduled in real devices; for this reason, its implementation depends on specific cases.
-
Sharing:The sharing block allows the sending and receiving of information from other elements, particularly by exposing a REST API server. This provides an endpoint through which it is possible to contact and be contacted for data and information exchange. This block consists of a POD that implements a REST API server to expose communication interfaces to other objects.
2. Heart DT Workflow
The architecture introduced above, illustrated in Figure 2, describes the following workflow.
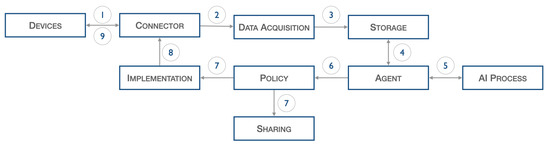
Figure 2. Heart DT workflow.
Data from IoT sensors, such as ECG, pressure, and pulse, are acquired and sent to the connector (1), which forwards them to the data acquisition stage (2). The latter, after performing normalization operations, inserts the filtered data into the database (3). The agent block, at certain fixed periods set during the configuration phase, start the validation process: specifically, the previously input data are extracted from the database (4) and passed to the AI process block (5), which perform inference on it.
As a result of this last process, certain actions are decided upon, but these are first screened by the policy block (6). Once consent is obtained from the policy block, information can be shared with other elements through the sharing block (7) or commands can be scheduled to the physical world through the Implementation block (7). The latter interacts with the Connector block (8) to forward the command to the actual device (9).
References
- Docker. Docker Overview. Available online: https://docs.docker.com/get-started/overview/ (accessed on 5 May 2023).
- Kubernetes. Kubernetes Documentation. Available online: https://kubernetes.io/docs/home/ (accessed on 5 May 2023).
More
Information
Subjects:
Telecommunications
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
751
Revisions:
2 times
(View History)
Update Date:
12 Jul 2023
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No