A big data processing framework is proposed to provide a better approach for the historical and real-time processing of engagement data from Online Roadshows. The framework enhances the data processing capabilities of big data processing beyond that of traditional programming models to ensure consistency and compatibility while also streamlining processing. The proposed framework not only handles the complexities of semi-structured and unstructured engagement data but it also introduces a pre-processing method to transform the data into a unified semi-structured format that complies with the Complex Event Processing (CEP) paradigm. Moreover, the framework incorporates a dual-mode data processing approach that allows for the simultaneous management of real-time and historical data. This enables a comprehensive analysis of the overall trend and personalized engagement characteristics for each participant. Consequently, this means that the framework could help improve the efficiency, accuracy, and responsiveness of the strategic planning and decision-making processes for companies making use of the Online Roadshow.
2. Online Roadshow
The Online Roadshow is a digital interactive advertising campaign model that was proposed in
[2], developed in response to the COVID-19 (Coronavirus disease 2019) pandemic, which forced individuals to remain socially distanced from one another in an attempt to minimize the spread of the disease
[23]. The pandemic disrupted conventional business engagement, as business owners could no longer interact with their customers directly. The framework leverages the web computing power and ubiquitous internet connectivity to achieve higher levels of business engagement in virtual ways, using the VARK (Visual, Audio, Reading and Writing, and Kinesthetic) Learning Model to overcome the ineffectiveness of non-face-to-face interaction
[24].
The framework allows business owners to integrate their product- or service-specific advertising components dynamically into the roadshow’s activities. The VARK Learning Model is embedded in the interactive games through the use of graphical content, audio content, and interactive content to implement audio visual, reading/writing, or kinesthetic modalities. The interactive games attract participants through various dynamic pieces of content, facilitating the potential exploration of audience preference information, such as audience demographic data and clickstream data. The data analytics module collects and processes the data collected in real-time. The module then generates responsive feedback for business owners through various computing techniques, such as classification and clustering, to provide cues on how to improve user experience
[20].
The main purpose of implementing the big data processing approach in the Online Roadshow is to reduce the data inaccuracy, inconsistency, and noise to provide a quality low-latency clustering outcome for a better user roadshow experience. This is in line with similar works like the D-Impact, a pre-processing data algorithm that achieves higher clustering quality by removing noise and outliers
[25]. In leveraging the real-time big data processing technique on the clustering procedure, low-latency personalization solutions, such as real-time web personalization, are made possible. Instead of recommending general advertising content to the audience, real-time web personalization can provide a more customized web experience to the individual users based on their past web interactions
[20]. Advertising will become more personalized and targeted, meaning that advertisers can iterate highly relevant advertising messages based on the specific behaviors and needs of consumers. This is the future of advertising
[21][22]. Companies are now expected to have a better comprehension of current market trends thanks to the implementation of highly accurate targeted advertising, which allows them to persuasively convince their target audience of the value of their products or services
[17][18].
In an optimal personalized advertising scenario, an audience is expected to receive dynamic advertising content based on their preferences, deduced from their behavioral data. The use of clustering techniques on the data to discover customer groups can improve customer experience through personalization. For instance, the navigational data extracted from the weblog can be processed into useful information that can be sent through newsletters with highly relevant suggestions to increase audience satisfaction
[20]. Research on targeted advertising indicates that it is an effective marketing approach for a multitude of products and services
[26][27]. A successful example of this is Facebook, which leverages targeted advertising techniques to allow business owners to place highly specific targeted advertisements in front of different groups and audiences based on their demographical information, such as hobbies, current living area, age, and gender
[28]. This leads to consumers receiving advertisements relevant to their needs, potentially boosting their desire to purchase the advertised product or service (purchase intention)
[29]. This process can significantly lower marketing costs and is less time-consuming
[30]. Another example of this is the experiment conducted in
[31], which assessed the efficacy of chocolate product advertisements targeted towards children. The study proved the efficacy of the advertising approach by evidencing how in enhanced purchase intention and built a positive brand reputation.
3. Existing Real-Time Big Data Processing Frameworks
With the evolution of rapidly growing information technology, conventional data storage approaches, such as the relational database, are no longer sufficient for the processing of large chunks of data, as they have unacceptably long processing times. Thus, a big data processing framework, as illustrated in
Figure 1, was introduced to eliminate the inefficiency of the conventional data processing framework
[32][33][34]. Data storage modules using the distributed data storage approach on distributed file systems provide more effective data balancing and have fault tolerance capabilities with higher I/O bandwidths. They support higher data loads by improving the structure of the framework, helping to store large amounts of data in a more responsive manner
[35]. For example, the Apache Kafka approach of the message broker module intends to improve the inefficiency of traditional polling-based communication, facilitating enhancements in data persistence, volume, velocity, and fault tolerance capability
[31]. On the other hand, the Apache Spark approach allows for faster data processing compared to the conventional approach, leveraging the MapReducing programming model, which has parallel programming capabilities
[36].
Figure 1. The general framework of the big data processing.
Real-time decision-making capabilities fulfil the requirements of time-critical data processing. For instance, the authors of
[37] leveraged the decision-making capabilities of a real-time big data processing framework to manufacture preventive maintenance systems. Device data are collected and further processed to evaluate the health conditions of the manufactured devices using Apache Storm. Moreover, Apache Spark was implemented by the authors of
[38] to analyze data collected by the second by multiple sensors in an experimental environment to monitor the operating conditions of a turbine syngas compressor, giving the engineers sufficient time to identify the solutions to potential problems.
On the other hand, the authors of
[2] explored the possibility of analyzing environmental monitoring data by using the Apache Spark as middleware to reduce the complexity of the underlying platform, easing the integration of the data processing module and the other devices. Additionally, Apache Spark has been implemented as a stability monitor in power systems to analyze the data generated by sensors during power production
[39]. The stability index is calculated in real-time with an expected minimized latency for monitoring purposes to reduce the possibility of issues such as black out and islanding. A real-time thief identification procedure also helps to locate the crime location by closely monitoring the power grids
[39].
4. Application Controller
In web applications, the controller translates user requests or interactions from the view in the Graphic User Interface (GUI) into the operations that the model will perform. Regarding the handling of user interaction requests from the data source, a request handler is responsible for properly processing and handling the request based on the payload
[40][41]. Regarding Online Roadshows, a cloud-based application controller is necessary as it eases information exchange communication between the client and server. In comparison, the Open Platform Communication (OPC UA) approach used in
[38] requires middleware in the web communication process
[42]. Two commonly used protocols in communicating and exchanging information between digital devices over a network
[43] are taken into consideration for the purpose of message exchange in the cloud-based application controller implementation. They are the SOAP (Simple Object Access Protocol) and REST (Representational State Transfer) protocol.
According to the authors of
[44], SOAP is a stateless and one-way message exchange messaging protocol that facilitates communication by using the Hypertext Transfer Protocol (HTTP) and Extensible Markup Language (XML) between SOAP nodes. On the other hand, REST is a client-server architecture that allows clients to send requests for further processing in the server
[43]. REST does not limit request parameter to XML, supporting various formats such as JSON (JavaScript Object Notation), strings, etc. With its support for RESTful API (Representational state transfer application program interface) and CEP, Spring MVC’s ability to process data without using a proxy service makes it more suitable for use in Online Roadshows. The framework provides better component linking capabilities (e.g., Spark, Kafka, and HDFS) and has a higher-level code usability.
Thus, the REST protocol is more suitable in the case of Online Roadshow data exchange. The requirement of the CEP paradigm allows for information from the event to flow through IT architecture, makes the data available for processing in real-time prior to storage
[45][46][47]. This provides data transformation or data pre-processing to increase the efficiency of message processing.
5. Message Broker
A message broker module provides great help in the asynchronous conversation for in-memory data storage processes such as continuous-site following, information examination, IOT data handling, and data logging
[48]. The message broker involves two parties: the sender (producer)—who produces the data sent to the message channel—and the receiver (consumer)—who listens to the specific “topic” on the message channel.
In a typical message broker scenario, a request will be sent to a specific consumer that is awaiting incoming requests from the producers. It consistently handles the message by storing them into an intermediate storage (e.g., disk or memory cache) rather than following the traditional message-processing scenario of directly disposing the message. This eliminates the inefficiency of traditional polling-based communication and eases the message exchange process, increasing the reliability of the web application’s request handling of incoming messages (e.g., job request).
Apache Kafka could be introduced as the message broker to properly handle the data. It processes data in the Kafka topic sequentially over the distributed nodes and handles incoming data with high fault-tolerance. Research conducted in
[48][49] indicates that Apache Kafka has a higher throughput and lower latency when configured correctly (e.g., appropriate number of topic and replication). Moreover, Apache Kafka keeps messages in the OS cache to offer a message delivery guarantee. Additionally, messages ingested by Apache Kafka will remain in a specific sequence in each topic to guarantee the order of the messages.
On the other hand, RabbitMQ could be introduced as a message-queuing approach for the message broker. It leverages Advanced Message Queuing Protocol (AMQP) to send or receive data from one or more queues, empowering stable and non-concurrent message exchange between applications. RabbitMQ is expected to have medium to high performance in terms of throughput as it relies on acknowledgement (ACK) handshakes and message replication. Message (data) are stored in either memory or disk without steadiness guarantee for message persistence. As RabbitMQ implies optional acknowledge handshakes, it offers delivery guarantee over queue setup
[48][49][50].
NATS is an open-source centralized and lightweight message broker that is designed for message exchange between PC applications and administrations. It offers very high throughput performance as it is an elite local application. Moreover, NATS has a higher latency compared to RabbitMQ due to its high idleness. Regarding message persistence, it offers strong storage ability with configurable settings. NATS supports both message delivery guarantee and message order guarantee.
Last but not least, Redis is a message broker that supports in-memory data storage, implementing the publish/subscribe paradigm. It relies on Redis channel, an intermediate storage space, to store published data from the publisher and to allow consumers to consume data from it. Redis has very high throughput performance and a relatively low latency as it stores data in cache memory for rapid access. Redis also supports the configuration of storage, where data persistence can be achieved through in-memory cache or the order of disks, providing a message order guarantee. However, Redis does not offer a message delivery guarantee
[49].
Thus, Apache Kafka is considered a better option regarding Online Roadshow implementation. It provides high flexibility in fine-tuning for better performance and integration configuration (e.g., intermediate storage space, message delivery, and sequence guarantee) in big data processing.
6. Data Processing Approaches
The batch processing approach is efficient in processing high volumes of data collected from time to time. On the other hand, the stream processing approach performs data processing with a small window of recent data at one time. This approach can be real-time or near-real-time when there are delays between the time of transaction and changes are propagated
[51].
A batch processing approach processes stored data collected from time to time and commonly used Hadoop MapReduce to cluster data into categories, resulting in a longer and more relaxed time interval (e.g., seconds, minutes, or even hours)
[10]. The stream data processing, which is a micro-version of the batch processing approach, processes a small window of data immediately and is expected to perform significantly faster than its batch processing counterpart
[52]. However, the stream data processing approach (e.g., Spark Stream) is computationally constrained (by resource utilization and configurations, etc.) and is clearly characterized by real-time operation. The stream data processing approach can perform statistical analytics on the fly, which is a particularly important characteristic for streaming data such as user-generated content (in the form of routine user interactions) because the data is arriving continuously at high speed.
Apache Hadoop, Apache Spark, and Apache Storm are three popular data processing approaches. Apache Hadoop was introduced by Google and involves the use of a parallel programming framework
[53][54] to perform batch-processing with a Map-Reducing programming model. It provides data storage solutions with distributing capabilities. However, Apache Hadoop can only process stored data and does not support real-time data processing. Therefore, approaches that perform real-time data processing, such as Apache Spark and Apache Storm, have been subsequently introduced.
Apache Spark allows for the implementation of a data processing module in various languages, significantly boosting the flexibility of framework development. It offers a data processing performance that is 10–100 times faster than Apache Hadoop
[55], providing more responsive processing results. Aside from its data processing capabilities, Apache Spark also provides data visualization through Graph X and machine learning capabilities when using the Spark MLib plugin. Thus, it is more functional than Apache Hadoop. Additionally, Apache Spark also supports a variety of data from different file systems, while Apache Hadoop only supports the HDFS. Moreover, Apache Spark is likely to be more suitable than Hadoop in performing iterative tasks due to the latter’s performance limitations (for more details, see Aziz et al.
[56]).
Apache Storm is introduced by the Apache foundation to support real-time computing. It consists of multiple components that allow for the transfer of data from one data stream to another in a distributed and relatively reliable manner using the directed acyclic graph (DAG) that is topologically ordered. The edges are the data flows, and the vertices are the components. The Spout refers to the data stream source that allows the topology to retrieve data from external data publishers. They are transformed into tuples to emit streams along edges of the directed graph. After that, the processing nodes (called the Bolts) will receive the Spout tuples, consuming input streams to perform further data processing, consequently creating new streams
[57][58][59].
For Online Roadshows, Apache Spark is the most suitable data processing approach, as the Online Roadshow deals mainly with past data (historical data) rather than real-time data streams. Although Spark Stream performs micro-batching rather than actual real-time processing, it is convenient for the Online Roadshow as it can perform data visualization and use machine learning through the plugin available in the Apache Spark environment (e.g., GraphX and SparkML) to better support the interpretation of low-level data analysis.
7. Data Storage
Relational databases, such as MySQL and Oracle DB
[60], are being used in traditional data processing frameworks to store data for effective data centralization and efficient storage management
[60]. However, as the huge amount of data goes beyond a certain size, the capabilities of the relational database in collecting, storing, and analyzing the data in the traditional structure become inefficient
[61]. It is no longer sufficient for processing the huge amount of data, and the data integrity in the relational manner is compromised
[60]. Therefore, Google proposed the Apache Hadoop (HBase) to parallelize the data processing capability of big data by distributing the load to accelerate the computation and reduce latency inefficiencies
[62].
A distributed file system with HDFS is a flexible, adaptive, and clustered method of managing the data files in a big data environment with a NoSQL solution. It is a data service that offers the unique set of capabilities required for handling large volumes of data with a high velocity
[59]. In HDFS, files and directories are represented as the NameNodes. It records the metadata attributes, such as access permission, modification details, namespace, access histories, and disk space quota, acting as the first contact for allocating the data blocks containing the file. It will then read the respective blocks from the DataNode closest to the client
[63]. On the other hand, the DataNode that stores the data sends heartbeats to the NameNode to ensure the DataNode is alive, and the replicated data is available over the cluster
[63]. Data Nodes are replicated over multiple nodes and accessed under the control of the NameNode to ensure data integrity over the cluster and prevent file corruption during failure
[62].
On the other hand, Apache Cassandra offers high scalability, availability, and fault tolerance through its replicational characteristics. It is designed to handle various types of unstructured, structured, and semi-structured data. Apache Cassandra provides a relational data storage design to allow key value storage, similar to the SQL relational database with foreign key joins. In a Cassandra cluster, nodes are interconnected, and data are distributed and communicated across each independent node in the cluster regardless of its location. The data model of Cassandra is significantly distinct from other relational database management models due to the fact that it supports key values stored in the storage space
[64].
In the case of Online Roadshow implementation, a distributed file system is more reliable since the data does not require key value storage and is expected to have higher efficiency in data reading latency and data writing capability. Research conducted by Jakkula et al.
[64] indicates that Apache Cassandra can achieve slightly better performance in the operation of updates involving small amounts of data; however, this results in a higher latency when the amount of data increases significantly.
8. Big Data Processing Framework for Online Roadshow
The main purpose of developing the proposed framework is to facilitate personalized participant engagement in the Online Roadshow using dual-mode big data processing. The proposed framework, as illustrated in Figure 2 consists of four mains components: The Application Controller module, the Message Broker module, the Big Data Processing module, and the Data Storage module. These modules are designed to improve the processing of participant engagement data for the Online Roadshow.
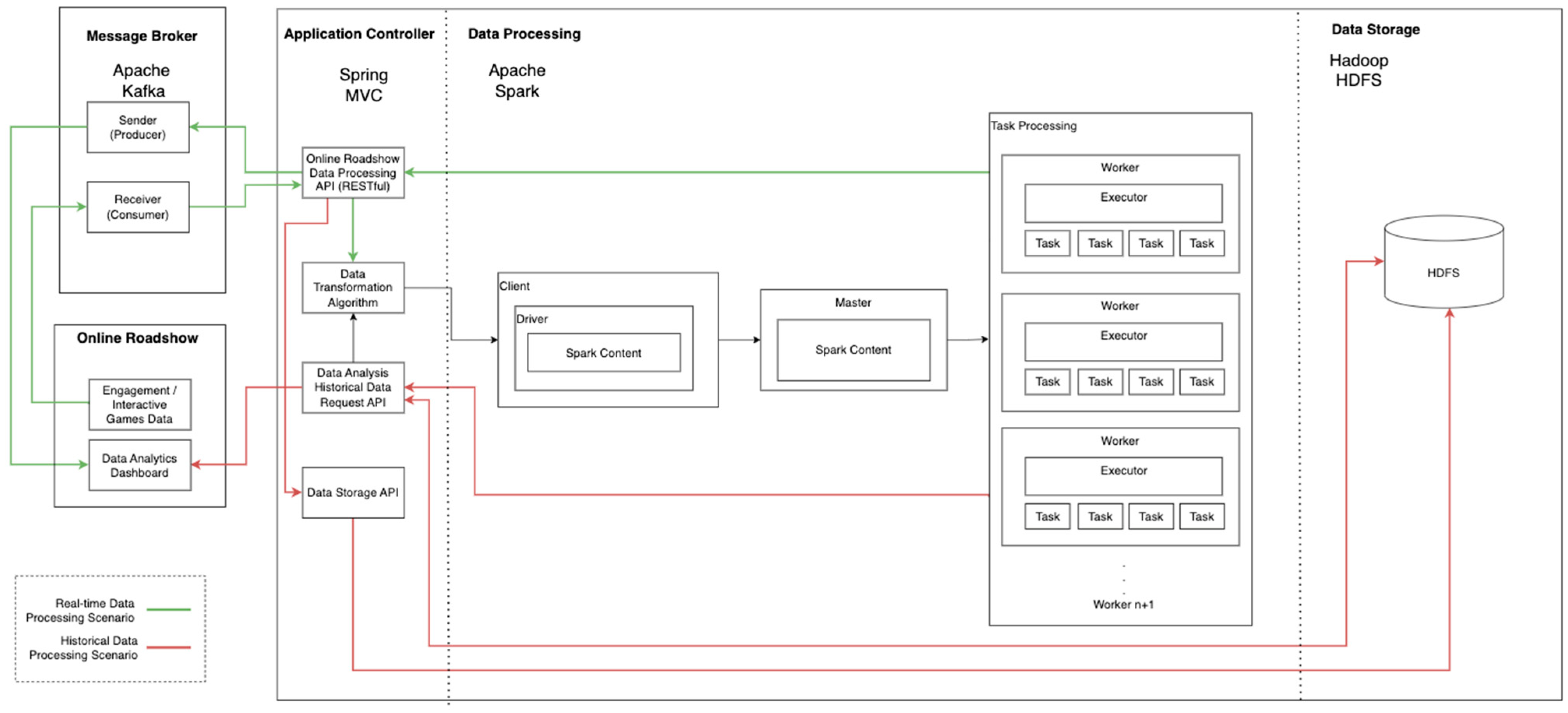
Figure 2. Proposed big data processing framework.
A big data processing framework for the Online Roadshow should be capable of working in dual-mode (red line is the Historical Data Processing scenario and green line is the Real-time Data Processing scenario) to analyze responsive (real-time) and batch (historical) data concurrently. It needs to serve different purposes that require faster and slower responses. For example, real-time big data processing provides a more accurate personalized targeted advertising experience, while historical data processing provides highly efficient trend analyses. For real-time data processing, the proposed framework leverages Apache Kafka as the message broker to handle the large amount of incoming data on the participant’s preference. Apache Spark is used as the data processor.
By implementing the real-time data processing, web personalization can be used to deliver a customized web experience based on the past user behaviors
[20], allowing advertisers to deliver more personalized and targeted advertisements. This practice gives a great opportunity for advertisers to iterate messages and disseminate content that is in alignment with the customer’s tastes
[21][22]. Furthermore, the historical data processing capabilities of the proposed framework provide quantitative feedback for the Online Roadshow event, offering a clearer understanding of the effectiveness of advertisements and the efficiency of the overall marketing strategy. For instance, analyzing the historical data helps businesses to identify strategic advertisement spaces and content that may generate higher traffic flow.
Considering the CEP, the proposed framework leverages Spring MVC as its Application Controller module, which provides high-level big data processing system manipulation. It is highly important to improve its system capabilities to process a variety of data types (e.g., JSON String, files, etc.) and for its data processing manipulation. At the same time, it also provides module integration capabilities (e.g., approach configuration, loggings, and multiple methods of data feeding), making the connection between the models implemented in the proposed framework highly flexible and providing API with REST protocol, which supports a variety of data-over-client-server message communication. In order to ingest, process, store, and retrieve the data produced during the Online Roadshow event, four models, consisting of the Online Roadshow Data Processing API, Data Analysis Historical Data Request API, Data Transformation algorithm, and Data Storage API are incorporated into the Application Controller module.
In the Online Roadshow, web engagement and interactive game data such as page visit, gameplay preferences, and gameplay performance data are collected during participant interaction sessions. Thus, the Online Roadshow Data Processing API provides data feed ingestion from the Online Roadshow to the Message Broker module for real-time data input and further processing. The pseudocode of the Online Roadshow Data Processing API is shown in Figure 3. It consumes the data from the message broker and validates the data to ensure a valid semi-structured JSON data format before processing them via the Data Transformation Algorithm, as shown in Figure 4, to transform the data into a key-value pair for the subsequent data extraction process. Invalid data will be ignored and the next record will be processed instead. Then, the pre-processed data will be processed by the Data Processing module and further broadcast to the message broking channel, which allows subscribers in the message broker to retrieve the real-time data processing result while storing the data in the Data Storage module in the background.
Figure 3. Online Roadshow Data Processing API pseudocode.
Figure 4. Data Transformation Algorithm pseudocode.
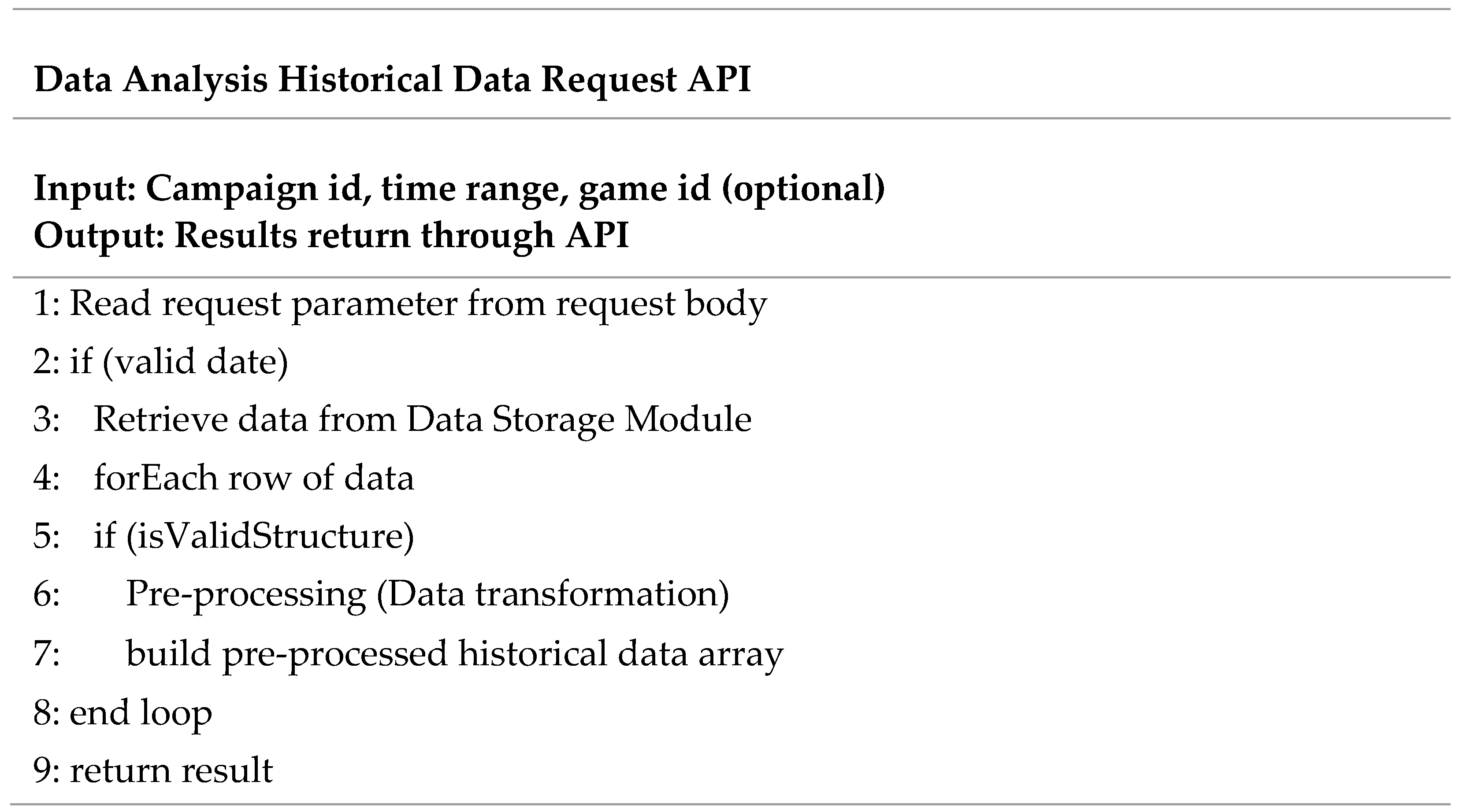
At the same time, historical data ingested from the Message Broker will be stored into the Data Storage module through the Data Storage API, as shown in Figure 5. By analyzing the historical data, advertisers can enhance decision-making efficiency by fine-tuning advertising strategies in the Online Roadshow to facilitate better engagement through providing a personalized web experience. In the case of the historical data retrieval, the Data Analysis Historical Data Request API, as shown in Figure 6, will retrieve the data within the specific requested time frame from the Data Storage module to analyze the overall participant preferences in terms of the sequence of page visit and gameplay behavioral characteristics. After that, the data retrieved will be pre-processed by the Data Transformation Algorithm for further processing by the big data processing module. Finally, the processed data will be returned through the Data Analysis Historical Data Request API to the Data Analytics Dashboard in the Online Roadshow for visualization.
Figure 5. Data Storage API pseudocode.
Figure 6. Data Analysis Historical Data Request API pseudocode.
The Message Broker module in the proposed framework leverages the Apache Kafka as the request handler. Apache Kafka is used to construct the real-time data streaming pipelines that function as a reliable data handling stream of records from the client applications, such as the sequence of page visit and the game play behavioral characteristics.
There will be two models in the Request Handler module that process the real-time data processing requests. The Receiver (Consumer) model is the data entry point and the Sender (Producer) model returns the processed result.
As a result, the proposed framework can process multiple streams of data on the background in the multi-threaded manner without interrupting the user processes, effectively enhancing the user experience.
The Data Processing module intends to analyze the audience preference data in a more responsive manner to allow the system to achieve higher accuracy in the targeted content of the dynamic advertising of the Online Roadshow implementation. For instance, a responsive analysis increases the efficiency of the product/service promotion because it can deliver preferable content to the audience, potentially influencing the consumer’s idea of brand preference and their intention to purchase the product or service. The Data Processing module in the proposed framework implements the Apache Spark with a MapReducing approach. Figure 2 illustrates a Spark Cluster that allows the spark application to run sets of processes independently. For resource optimization, the Spark Cluster can connect to various types of resource managers to optimize the resource allocation process.
During an Online Roadshow event, personal preference data, such as user’s page visits, gameplay behavioral characteristics, and gameplay performance, are collected accordingly for each participant. Thus, the Data Storage module is able to store and retrieve the data of a high volume and velocity while maintaining the data integrity, data persistence, and fault tolerance capability, lowering the risk of losing valuable participant information.
 +1 credit
+1 credit