 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Sirius Huang | -- | 2805 | 2022-11-28 01:33:17 |
Video Upload Options
In compiler design, static single assignment form (often abbreviated as SSA form or simply SSA) is a property of an intermediate representation (IR), which requires that each variable be assigned exactly once, and every variable be defined before it is used. Existing variables in the original IR are split into versions, new variables typically indicated by the original name with a subscript in textbooks, so that every definition gets its own version. In SSA form, use-def chains are explicit and each contains a single element. SSA was proposed by Barry K. Rosen, Mark N. Wegman, and F. Kenneth Zadeck in 1988. Ron Cytron, Jeanne Ferrante and the previous three researchers at IBM developed an algorithm that can compute the SSA form efficiently. One can expect to find SSA in a compiler for Fortran, C or C++, whereas in functional language compilers, such as those for Scheme and ML, continuation-passing style (CPS) is generally used. SSA is formally equivalent to a well-behaved subset of CPS excluding non-local control flow, which does not occur when CPS is used as intermediate representation. So optimizations and transformations formulated in terms of one immediately apply to the other.
1. Benefits
The primary usefulness of SSA comes from how it simultaneously simplifies and improves the results of a variety of compiler optimizations, by simplifying the properties of variables. For example, consider this piece of code:
y := 1 y := 2 x := y
Humans can see that the first assignment is not necessary, and that the value of y being used in the third line comes from the second assignment of y. A program would have to perform reaching definition analysis to determine this. But if the program is in SSA form, both of these are immediate:
y1 := 1 y2 := 2 x1 := y2
Compiler optimization algorithms which are either enabled or strongly enhanced by the use of SSA include:
- Constant propagation – conversion of computations from runtime to compile time, e.g. treat the instruction
a=3*4+5;as if it werea=17; - Value range propagation[1] – precompute the potential ranges a calculation could be, allowing for the creation of branch predictions in advance
- Sparse conditional constant propagation – range-check some values, allowing tests to predict the most likely branch
- Dead code elimination – remove code that will have no effect on the results
- Global value numbering – replace duplicate calculations producing the same result
- Partial redundancy elimination – removing duplicate calculations previously performed in some branches of the program
- Strength reduction – replacing expensive operations by less expensive but equivalent ones, e.g. replace integer multiply or divide by powers of 2 with the potentially less expensive shift left (for multiply) or shift right (for divide).
- Register allocation – optimize how the limited number of machine registers may be used for calculations
2. Converting to SSA
Converting ordinary code into SSA form is primarily a matter of replacing the target of each assignment with a new variable, and replacing each use of a variable with the "version" of the variable reaching that point. For example, consider the following control-flow graph:
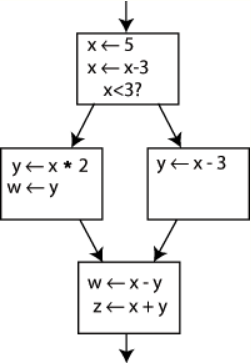
An example control-flow graph, before conversion to SSA. https://handwiki.org/wiki/index.php?curid=1887224
Changing the name on the left hand side of "x [math]\displaystyle{ \leftarrow }[/math] x - 3" and changing the following uses of x to that new name would leave the program unaltered. This can be exploited in SSA by creating two new variables: x1 and x2, each of which is assigned only once. Likewise, giving distinguishing subscripts to all the other variables yields:
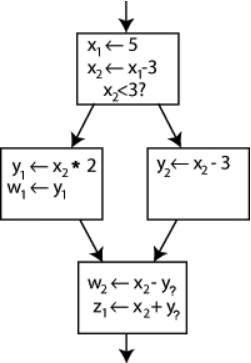
An example control-flow graph, partially converted to SSA. https://handwiki.org/wiki/index.php?curid=1989184
It is clear which definition each use is referring to, except for one case: both uses of y in the bottom block could be referring to either y1 or y2, depending on which path the control flow took.
To resolve this, a special statement is inserted in the last block, called a Φ (Phi) function. This statement will generate a new definition of y called y3 by "choosing" either y1 or y2, depending on the control flow in the past.
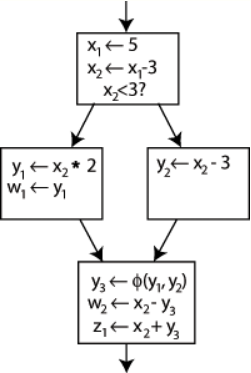
An example control-flow graph, fully converted to SSA. https://handwiki.org/wiki/index.php?curid=1820048
Now, the last block can simply use y3, and the correct value will be obtained either way. A Φ function for x is not needed: only one version of x, namely x2 is reaching this place, so there is no problem (in other words, Φ(x2,x2)=x2).
Given an arbitrary control-flow graph, it can be difficult to tell where to insert Φ functions, and for which variables. This general question has an efficient solution that can be computed using a concept called dominance frontiers (see below).
Φ functions are not implemented as machine operations on most machines. A compiler can implement a Φ function by inserting "move" operations at the end of every predecessor block. In the example above, the compiler might insert a move from y1 to y3 at the end of the middle-left block and a move from y2 to y3 at the end of the middle-right block. These move operations might not end up in the final code based on the compiler's register allocation procedure. However, this approach may not work when simultaneous operations are speculatively producing inputs to a Φ function, as can happen on wide-issue machines. Typically, a wide-issue machine has a selection instruction used in such situations by the compiler to implement the Φ function.
According to Kenny Zadeck,[2] Φ functions were originally known as phony functions while SSA was being developed at IBM Research in the 1980s. The formal name of a Φ function was only adopted when the work was first published in an academic paper.
2.1. Computing Minimal SSA using Dominance Frontiers
First, we need the concept of a dominator: we say that a node A strictly dominates a different node B in the control-flow graph if it is impossible to reach B without passing through A first. This is useful, because if we ever reach B we know that any code in A has run. We say that A dominates B (B is dominated by A) if either A strictly dominates B or A = B.
Now we can define the dominance frontier: a node B is in the dominance frontier of a node A if A does not strictly dominate B, but does dominate some immediate predecessor of B, or if node A is an immediate predecessor of B, and, since any node dominates itself, node A dominates itself, and as a result node B is in the dominance frontier of node A. From A's point of view, these are the nodes at which other control paths, which don't go through A, make their earliest appearance.
Dominance frontiers capture the precise places at which we need Φ functions: if the node A defines a certain variable, then that definition and that definition alone (or redefinitions) will reach every node A dominates. Only when we leave these nodes and enter the dominance frontier must we account for other flows bringing in other definitions of the same variable. Moreover, no other Φ functions are needed in the control-flow graph to deal with A's definitions, and we can do with no less.
There is an efficient algorithm for finding dominance frontiers of each node. This algorithm was originally described in Cytron et al. 1991. Also useful is chapter 19 of the book "Modern compiler implementation in Java" by Andrew Appel (Cambridge University Press, 2002). See the paper for more details.[3]
Keith D. Cooper, Timothy J. Harvey, and Ken Kennedy of Rice University describe an algorithm in their paper titled A Simple, Fast Dominance Algorithm.[4] The algorithm uses well-engineered data structures to improve performance. It is expressed simply as follows:[4]
for each node b
dominance_frontier(b) := {}
for each node b
if the number of immediate predecessors of b ≥ 2
for each p in immediate predecessors of b
runner := p
while runner ≠ idom(b)
dominance_frontier(runner) := dominance_frontier(runner) ∪ { b }
runner := idom(runner)
Note: in the code above, an immediate predecessor of node n is any node from which control is transferred to node n, and idom(b) is the node that immediately dominates node b (a singleton set).
3. Variations That Reduce the Number of Φ Functions
"Minimal" SSA inserts the minimal number of Φ functions required to ensure that each name is assigned a value exactly once and that each reference (use) of a name in the original program can still refer to a unique name. (The latter requirement is needed to ensure that the compiler can write down a name for each operand in each operation.)
However, some of these Φ functions could be dead. For this reason, minimal SSA does not necessarily produce the fewest Φ functions that are needed by a specific procedure. For some types of analysis, these Φ functions are superfluous and can cause the analysis to run less efficiently.
3.1. Pruned SSA
Pruned SSA form is based on a simple observation: Φ functions are only needed for variables that are "live" after the Φ function. (Here, "live" means that the value is used along some path that begins at the Φ function in question.) If a variable is not live, the result of the Φ function cannot be used and the assignment by the Φ function is dead.
Construction of pruned SSA form uses live variable information in the Φ function insertion phase to decide whether a given Φ function is needed. If the original variable name isn't live at the Φ function insertion point, the Φ function isn't inserted.
Another possibility is to treat pruning as a dead code elimination problem. Then, a Φ function is live only if any use in the input program will be rewritten to it, or if it will be used as an argument in another Φ function. When entering SSA form, each use is rewritten to the nearest definition that dominates it. A Φ function will then be considered live as long as it is the nearest definition that dominates at least one use, or at least one argument of a live Φ.
3.2. Semi-Pruned SSA
Semi-pruned SSA form[5] is an attempt to reduce the number of Φ functions without incurring the relatively high cost of computing live variable information. It is based on the following observation: if a variable is never live upon entry into a basic block, it never needs a Φ function. During SSA construction, Φ functions for any "block-local" variables are omitted.
Computing the set of block-local variables is a simpler and faster procedure than full live variable analysis, making semi-pruned SSA form more efficient to compute than pruned SSA form. On the other hand, semi-pruned SSA form will contain more Φ functions.
3.3. Block Arguments
Block arguments are an alternative to Φ functions that is representationally identical but in practice can be more convenient during optimization. Blocks are named and take a list of block arguments, notated as function parameters. When calling a block the block arguments are bound to specified values. Swift and LLVM's MLIR use block arguments.[6]
4. Converting out of SSA Form
SSA form is not normally used for direct execution (although it is possible to interpret SSA[7]), and it is frequently used "on top of" another IR with which it remains in direct correspondence. This can be accomplished by "constructing" SSA as a set of functions which map between parts of the existing IR (basic blocks, instructions, operands, etc.) and its SSA counterpart. When the SSA form is no longer needed, these mapping functions may be discarded, leaving only the now-optimized IR.
Performing optimizations on SSA form usually leads to entangled SSA-Webs, meaning there are Φ instructions whose operands do not all have the same root operand. In such cases color-out algorithms are used to come out of SSA. Naive algorithms introduce a copy along each predecessor path which caused a source of different root symbol to be put in Φ than the destination of Φ. There are multiple algorithms for coming out of SSA with fewer copies, most use interference graphs or some approximation of it to do copy coalescing.[8]
5. Extensions
Extensions to SSA form can be divided into two categories.
Renaming scheme extensions alter the renaming criterion. Recall that SSA form renames each variable when it is assigned a value. Alternative schemes include static single use form (which renames each variable at each statement when it is used) and static single information form (which renames each variable when it is assigned a value, and at the post-dominance frontier).
Feature-specific extensions retain the single assignment property for variables, but incorporate new semantics to model additional features. Some feature-specific extensions model high-level programming language features like arrays, objects and aliased pointers. Other feature-specific extensions model low-level architectural features like speculation and predication.
6. Compilers Using SSA Form
SSA form is a relatively recent development in the compiler community. As such, many older compilers only use SSA form for some part of the compilation or optimization process, but most do not rely on it. Examples of compilers that rely heavily on SSA form include:
- The ETH Oberon-2 compiler was one of the first public projects to incorporate "GSA", a variant of SSA.
- The LLVM Compiler Infrastructure uses SSA form for all scalar register values (everything except memory) in its primary code representation. SSA form is only eliminated once register allocation occurs, late in the compile process (often at link time).
- The Open64 compiler uses SSA form in its global scalar optimizer, though the code is brought into SSA form before and taken out of SSA form afterwards. Open64 uses extensions to SSA form to represent memory in SSA form as well as scalar values.
- As of version 4 (released in April 2005) GCC, the GNU Compiler Collection, makes extensive use of SSA. The frontends generate "GENERIC" code which is then converted into "GIMPLE" code by the "gimplifier". High-level optimizations are then applied on the SSA form of "GIMPLE". The resulting optimized intermediate code is then translated into RTL, on which low-level optimizations are applied. The architecture-specific backends finally turn RTL into assembly language.
- IBM's open source adaptive Java virtual machine, Jikes RVM, uses extended Array SSA, an extension of SSA that allows analysis of scalars, arrays, and object fields in a unified framework. Extended Array SSA analysis is only enabled at the maximum optimization level, which is applied to the most frequently executed portions of code.
- In 2002, researchers modified IBM's JikesRVM (named Jalapeño at the time) to run both standard Java bytecode and a typesafe SSA (SafeTSA) bytecode class files, and demonstrated significant performance benefits to using the SSA bytecode.
- Oracle's HotSpot Java Virtual Machine uses an SSA-based intermediate language in its JIT compiler.[9]
- Microsoft Visual C++ compiler backend available in Microsoft Visual Studio 2015 Update 3 uses SSA[10]
- Mono uses SSA in its JIT compiler called Mini.
- jackcc is an open-source compiler for the academic instruction set Jackal 3.0. It uses a simple 3-operand code with SSA for its intermediate representation. As an interesting variant, it replaces Φ functions with a so-called SAME instruction, which instructs the register allocator to place the two live ranges into the same physical register.
- Although not a compiler, the Boomerang decompiler uses SSA form in its internal representation. SSA is used to simplify expression propagation, identifying parameters and returns, preservation analysis, and more.
- Portable.NET uses SSA in its JIT compiler.
- libFirm a completely graph based SSA intermediate representation for compilers. libFirm uses SSA form for all scalar register values until code generation by use of an SSA-aware register allocator.
- The Illinois Concert Compiler circa 1994[11] used a variant of SSA called SSU (Static Single Use) which renames each variable when it is assigned a value, and in each conditional context in which that variable is used; essentially the static single information form mentioned above. The SSU form is documented in John Plevyak's Ph.D Thesis.
- The COINS compiler uses SSA form optimizations as explained here.
- The Mozilla Firefox SpiderMonkey JavaScript engine uses SSA-based IR.[12]
- The Chromium V8 JavaScript engine implements SSA in its Crankshaft compiler infrastructure as announced in December 2010
- PyPy uses a linear SSA representation for traces in its JIT compiler.
- Android's Dalvik virtual machine uses SSA in its JIT compiler.
- Android's new optimizing compiler for the Android Runtime uses SSA for its IR.
- The Standard ML compiler MLton uses SSA in one of its intermediate languages.
- LuaJIT makes heavy use of SSA-based optimizations.[13]
- The PHP and Hack compiler HHVM uses SSA in its IR.[14]
- Reservoir Labs' R-Stream compiler supports non-SSA (quad list), SSA and SSI (Static Single Information[15]) forms.[16]
- Go (1.7: for x86-64 architecture only; 1.8: for all supported architectures).[17][18]
- SPIR-V, the shading language standard for the Vulkan graphics API and kernel language for OpenCL compute API, is an SSA representation.[19]
- Various Mesa drivers via NIR, an SSA representation for shading languages.[20]
- WebKit uses SSA in its JIT compilers.[21][22]
- Swift defines its own SSA form above LLVM IR, called SIL (Swift Intermediate Language).[23][24]
- Erlang rewrote their compiler in OTP 22.0 to "internally use an intermediate representation based on Static Single Assignment (SSA)." With plans for further optimizations built on top of SSA in future releases.[25]
References
- value range propagation http://llvm.org/devmtg/2007-05/05-Lewycky-Predsimplify.pdf
- see page 43 ["The Origin of Ф-Functions and the Name"] of Zadeck, F. Kenneth, Presentation on the History of SSA at the SSA'09 Seminar, Autrans, France, April 2009 http://citi2.rice.edu/WS07/KennethZadeck.pdf
- Cytron, Ron; Ferrante, Jeanne; Rosen, Barry K.; Wegman, Mark N.; Zadeck, F. Kenneth (1 October 1991). "Efficiently computing static single assignment form and the control dependence graph". ACM Transactions on Programming Languages and Systems 13 (4): 451–490. doi:10.1145/115372.115320. https://dx.doi.org/10.1145%2F115372.115320
- Cooper, Keith D.; Harvey, Timothy J.; Kennedy, Ken (2001). A Simple, Fast Dominance Algorithm. https://web.archive.org/web/20200130142038/http://citi2.rice.edu/WS07/KennethZadeck.pdf.
- Briggs, Preston; Cooper, Keith D.; Harvey, Timothy J.; Simpson, L. Taylor (1998). Practical Improvements to the Construction and Destruction of Static Single Assignment Form. http://www.cs.rice.edu/~harv/my_papers/ssa.pdf.
- "Block Arguments vs PHI nodes - MLIR Rationale". https://mlir.llvm.org/docs/Rationale/Rationale/#block-arguments-vs-phi-nodes.
- von Ronne, Jeffery; Ning Wang; Michael Franz (2004). "Interpreting programs in static single assignment form". Proceedings of the 2004 workshop on Interpreters, virtual machines and emulators - IVME '04. p. 23. doi:10.1145/1059579.1059585. ISBN 1581139098. http://dl.acm.org/citation.cfm?doid=1059579.1059585.
- Boissinot, Benoit; Darte, Alain; Rastello, Fabrice; Dinechin, Benoît Dupont de; Guillon, Christophe (2008). "Revisiting Out-of-SSA Translation for Correctness, Code Quality, and Efficiency" (in en). HAL-Inria Cs.DS: 14. https://hal.inria.fr/inria-00349925.
- "The Java HotSpot Performance Engine Architecture". Oracle Corporation. http://www.oracle.com/technetwork/java/whitepaper-135217.html.
- "Introducing a new, advanced Visual C++ code optimizer". 4 May 2016. https://blogs.msdn.microsoft.com/vcblog/2016/05/04/new-code-optimizer.
- "Illinois Concert Project". http://www-csag.ucsd.edu/projects/concert.html.
- "IonMonkey Overview". https://wiki.mozilla.org/IonMonkey/Overview. ,
- "Bytecode Optimizations". the LuaJIT project. http://wiki.luajit.org/Optimizations.
- "HipHop Intermediate Representation (HHIR)". 30 October 2021. https://github.com/facebook/hhvm/blob/master/hphp/doc/ir.specification.
- Ananian, C. Scott; Rinard, Martin (1999). Static Single Information Form.
- "Encyclopedia of Parallel Computing". https://www.springer.com/us/book/9780387097657.
- "Go 1.7 Release Notes - The Go Programming Language". https://golang.org/doc/go1.7#compiler.
- "Go 1.8 Release Notes - The Go Programming Language". https://golang.org/doc/go1.8#compiler.
- "SPIR-V spec". https://www.khronos.org/registry/spir-v/specs/1.0/SPIRV.pdf.
- Ekstrand, Jason. "Reintroducing NIR, a new IR for mesa". https://lists.freedesktop.org/archives/mesa-dev/2014-December/072761.html.
- "Introducing the WebKit FTL JIT". 13 May 2014. https://webkit.org/blog/3362/introducing-the-webkit-ftl-jit/.
- "Introducing the B3 JIT Compiler". 15 February 2016. https://webkit.org/blog/5852/introducing-the-b3-jit-compiler/.
- "Swift Intermediate Language (GitHub)". 30 October 2021. https://github.com/apple/swift/blob/master/docs/SIL.rst.
- "Swift's High-Level IR: A Case Study of Complementing LLVM IR with Language-Specific Optimization, LLVM Developers Meetup 10/2015". https://www.youtube.com/watch?v=Ntj8ab-5cvE.
- "OTP 22.0 Release Notes". http://www.erlang.org/news/132.


