 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Federico Milani | -- | 2119 | 2022-11-02 11:47:27 | | | |
| 2 | Lindsay Dong | Meta information modification | 2119 | 2022-11-24 14:17:37 | | |
Video Upload Options
To account for the lack of fine-grained annotations, such as object bounding boxes, several object detection methods have been developed that leverage only coarse-grain annotations (especially image-level labels indicating only the presence or absence of an object). This approach is called inexact Weak Supervision and introduces a new branch of Object Detection called Weakly Supervised Object Detection. Given an image, Remote Sensing Fully Supervised Object Detection (RSFSOD) aims to locate and classify objects based on Bounding Boxes annotations. Differently from RSFSOD, Remote Sensing Weakly Supervised Object Detection aims to precisely locate and classify object instances in Remote Sensing Images using only image-level labels or other types of coarse-grained labels (e.g., points or scribbles) as ground truth.
1. Coarse-Grained Annotations
2. Main Challenges
-
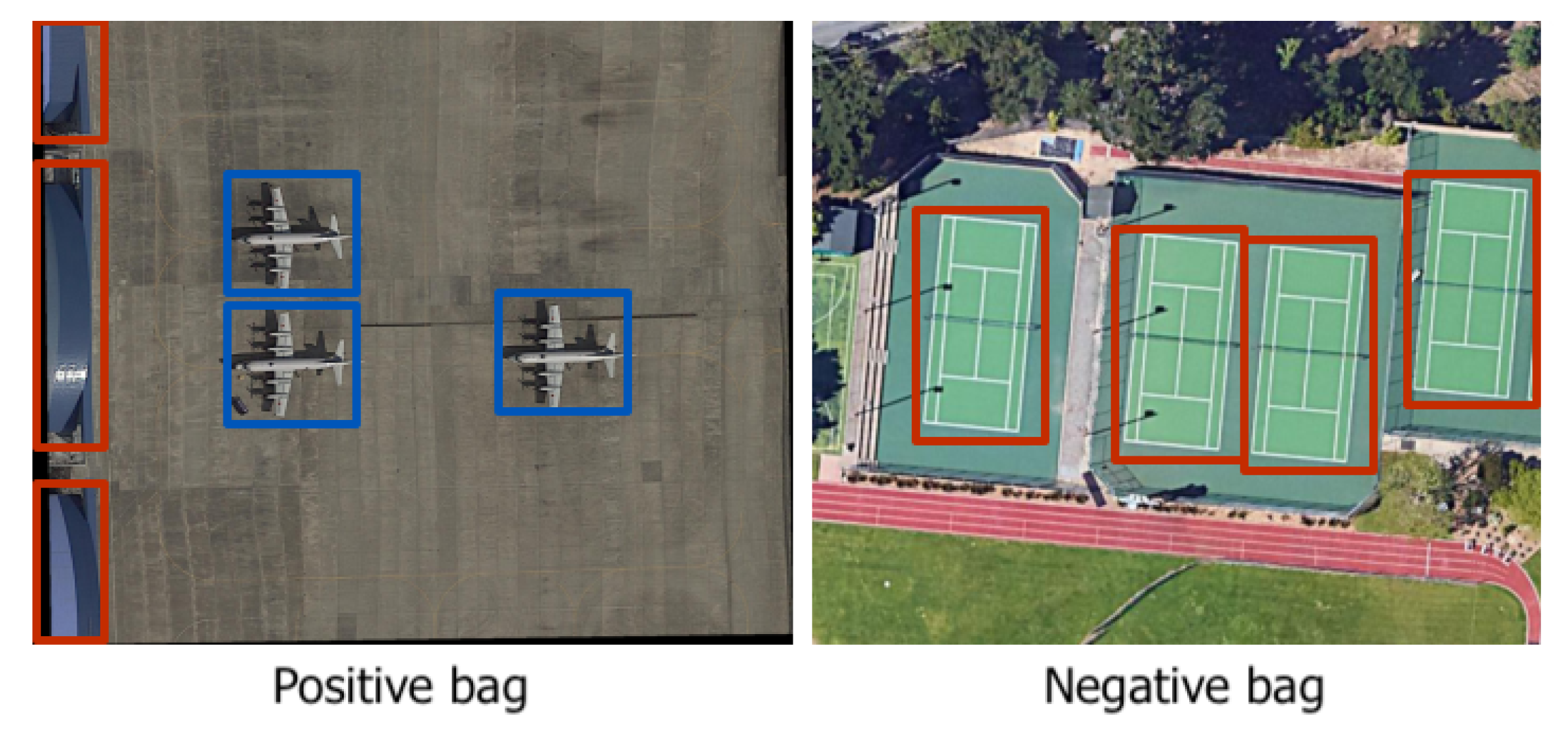
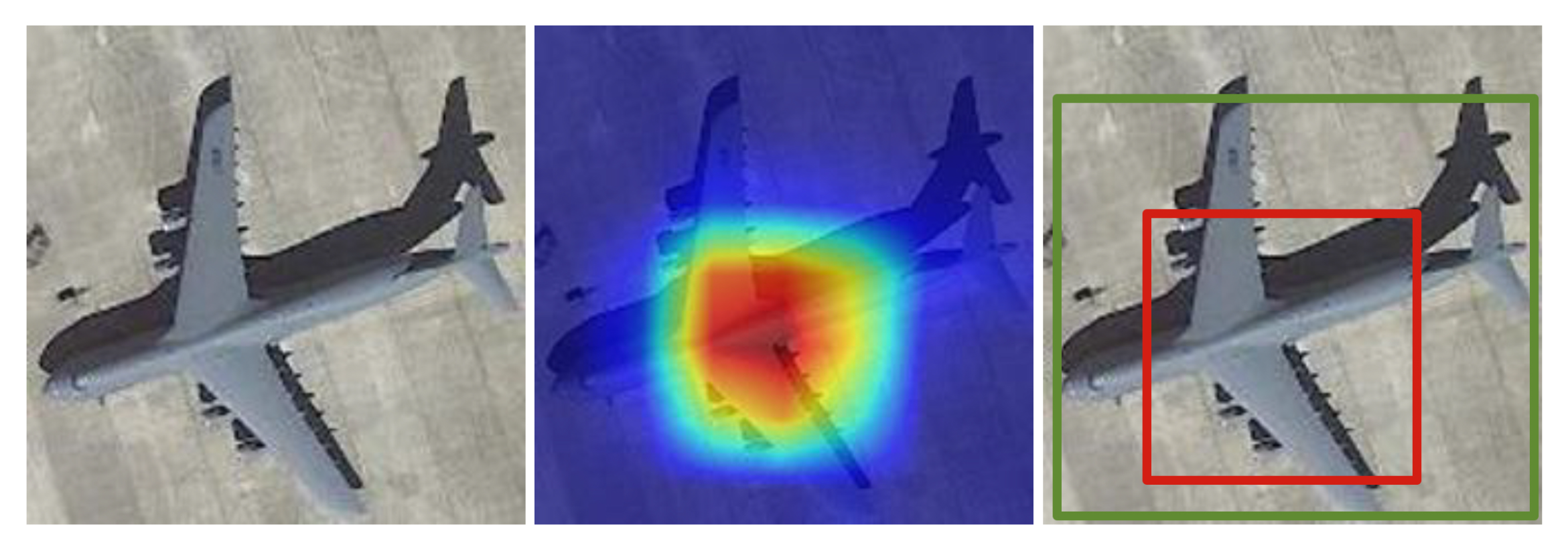
Partial coverage problem: This may arise from the fact that the object detection proposals computed by the WSOD method with the highest confidence score are those that surround the most discriminative part of an instance. If proposals are selected solely based on the highest score, the detector will learn to focus only on the most discriminative parts and not on the entire extent of an object (discriminative region problem). Another problem may derive from proposal generation methods such as Selective Search [3] and Edge Boxes [4], which output proposals that may not cover the entire targets well, reducing the performances of the detector (low-quality proposal problem).
-
Density problem: Images often contain dense groups of instances belonging to the same class. Models usually have difficulties in accurately detecting and distinguishing all the instances in such densely populated regions.
-
Generalization problem: The high intra-class diversity in RSIs induces generalization problems mainly due to three factors:
- -
-
Multi-scale: Objects may have varying sizes, and their representation strongly depends on the image resolution and ground sample distance.
- -
-
Orientation variation: Instances present arbitrary orientations and may require the use of methods generating oriented bounding boxes instead of the classical horizontal bounding boxes.
- -
-
Spatial complexity: In general, RSIs show varying degrees of complexity in the spatial arrangement of the objects.
3. Weakly Supervised Object Detection Approaches
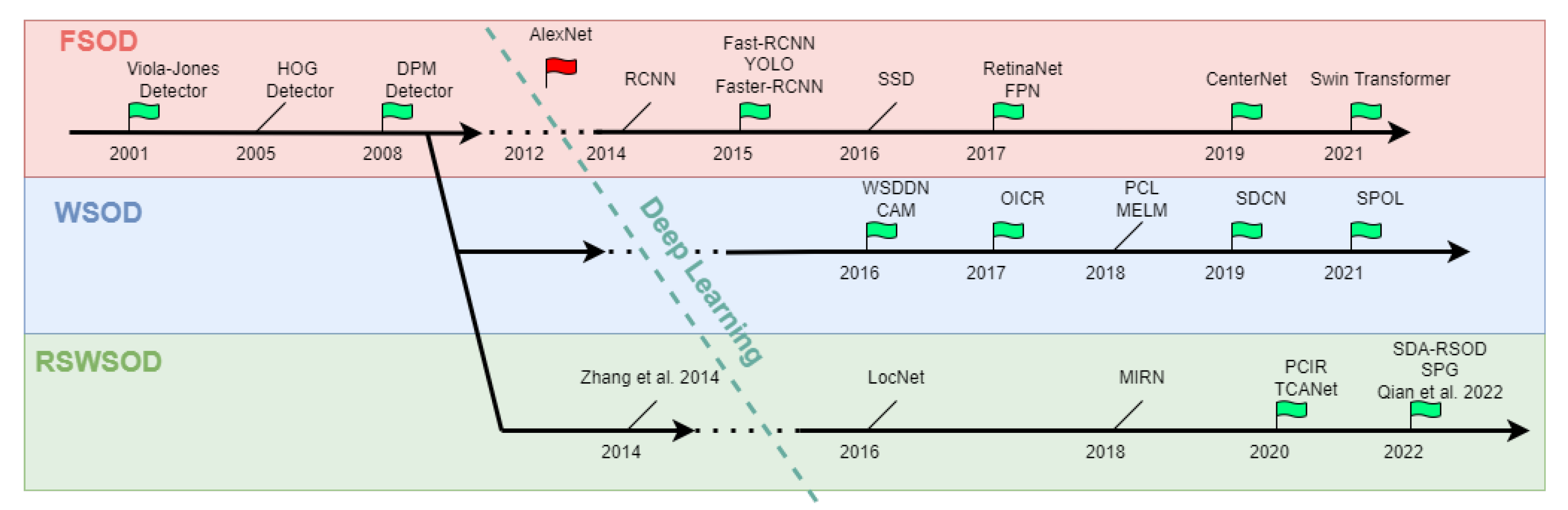
-
TSI + TDL-based: These approaches are based on a simple framework that consists of two stages: training set initialization (TSI) and target detector learning (TDL).
-
MIL-based: These approaches are based on the Multiple Instance Learning (MIL) framework.
-
CAM-based: These approaches are based on Class Activation Maps (CAMs), a well-known explainability technique.
-
Other DL-based: Few methods reformulate the RSWSOD problem starting from the implicit results of other tasks, e.g., Anomaly Detection (AD).
3.1. TSI + TDL-Based
3.2. MIL-Based
3.3. CAM-Based
References
- Li, Y.; He, B.; Melgani, F.; Long, T. Point-based weakly supervised learning for object detection in high spatial resolution remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 5361–5371.
- Shao, F.; Chen, L.; Shao, J.; Ji, W.; Xiao, S.; Ye, L.; Zhuang, Y.; Xiao, J. Deep Learning for Weakly-Supervised Object Detection and Localization: A Survey. Neurocomputing 2022, 496, 192–207.
- Uijlings, J.R.R.; van de Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective Search for Object Recognition. Int. J. Comput. Vis. 2013, 104, 154–171.
- Zitnick, C.L.; Dollár, P. Edge Boxes: Locating Object Proposals from Edges. In Computer Vision—ECCV 2014, Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 391–405.
- Bilen, H.; Vedaldi, A. Weakly Supervised Deep Detection Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2846–2854.
- Tang, P.; Wang, X.; Bai, X.; Liu, W. Multiple Instance Detection Network with Online Instance Classifier Refinement. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3059–3067.
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. arXiv 2019, arXiv:1905.05055.
- Dietterich, T.G.; Lathrop, R.H.; Lozano-Pérez, T. Solving the multiple instance problem with axis-parallel rectangles. Artif. Intell. 1997, 89, 31–71.
- Andrews, S.; Tsochantaridis, I.; Hofmann, T. Support vector machines for multiple-instance learning. Adv. Neural Inf. Process. Syst. 2002, 15, 561–568.
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110.
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893.
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A survey of modern deep learning based object detection models. Digit. Signal Process. 2022, 126, 103514.
- Qian, X.; Huo, Y.; Cheng, G.; Yao, X.; Li, K.; Ren, H.; Wang, W. Incorporating the Completeness and Difficulty of Proposals Into Weakly Supervised Object Detection in Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1902–1911.
- Zhang, D.; Han, J.; Yu, D.; Han, J. Weakly supervised learning for airplane detection in remote sensing images. In Proceedings of the Second International Conference on Communications, Signal Processing, and Systems; Springer: Cham, Switzerland, 2014; pp. 155–163.
- Han, J.; Zhang, D.; Cheng, G.; Guo, L.; Ren, J. Object detection in optical remote sensing images based on weakly supervised learning and high-level feature learning. IEEE Trans. Geosci. Remote Sens. 2014, 53, 3325–3337.
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Scalable multi-class geospatial object detection in high-spatial-resolution remote sensing images. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 2479–2482.
- Cao, L.; Luo, F.; Chen, L.; Sheng, Y.; Wang, H.; Wang, C.; Ji, R. Weakly supervised vehicle detection in satellite images via multi-instance discriminative learning. Pattern Recognit. 2017, 64, 417–424.
- Zhang, D.; Han, J.; Cheng, G.; Liu, Z.; Bu, S.; Guo, L. Weakly supervised learning for target detection in remote sensing images. IEEE Geosci. Remote Sens. Lett. 2014, 12, 701–705.
- Zhou, P.; Zhang, D.; Cheng, G.; Han, J. Negative bootstrapping for weakly supervised target detection in remote sensing images. In Proceedings of the 2015 IEEE International Conference on Multimedia Big Data, Beijing, China, 20–22 April 2015; pp. 318–323.
- Zhou, P.; Cheng, G.; Liu, Z.; Bu, S.; Hu, X. Weakly supervised target detection in remote sensing images based on transferred deep features and negative bootstrapping. Multidimens. Syst. Signal Process. 2016, 27, 925–944.
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90.
- Sheng, Y.; Cao, L.; Wang, C.; Li, J. Weakly Supervised Vehicle Detection in Satellite Images via Multiple Instance Ranking. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2765–2770.
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Object Detectors Emerge in Deep Scene CNNs. arXiv 2014, arXiv:1412.6856.
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Is object localization for free? Weakly-supervised learning with convolutional neural networks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 685–694.
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929.
- Li, Y.; Zhang, Y.; Huang, X.; Yuille, A.L. Deep networks under scene-level supervision for multi-class geospatial object detection from remote sensing images. ISPRS J. Photogramm. Remote Sens. 2018, 146, 182–196.
- Ji, J.; Zhang, T.; Yang, Z.; Jiang, L.; Zhong, W.; Xiong, H. Aircraft detection from remote sensing image based on a weakly supervised attention model. In Proceedings of the IGARSS 2019-2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 322–325.

