Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Abdullah Mamun | -- | 3064 | 2022-10-26 16:17:47 | | | |
| 2 | Rita Xu | Meta information modification | 3064 | 2022-10-27 04:57:49 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Mamun, A.A.; Ping, E.P.; Hossen, J.; Tahabilder, A.; Jahan, B. Lane Marking Detection Using Deep Neural Networks. Encyclopedia. Available online: https://encyclopedia.pub/entry/31455 (accessed on 24 July 2026).
Mamun AA, Ping EP, Hossen J, Tahabilder A, Jahan B. Lane Marking Detection Using Deep Neural Networks. Encyclopedia. Available at: https://encyclopedia.pub/entry/31455. Accessed July 24, 2026.
Mamun, Abdullah Al, Em Poh Ping, Jakir Hossen, Anik Tahabilder, Busrat Jahan. "Lane Marking Detection Using Deep Neural Networks" Encyclopedia, https://encyclopedia.pub/entry/31455 (accessed July 24, 2026).
Mamun, A.A., Ping, E.P., Hossen, J., Tahabilder, A., & Jahan, B. (2022, October 26). Lane Marking Detection Using Deep Neural Networks. In Encyclopedia. https://encyclopedia.pub/entry/31455
Mamun, Abdullah Al, et al. "Lane Marking Detection Using Deep Neural Networks." Encyclopedia. Web. 26 October, 2022.
Copy Citation
Lane marking recognition is one of the most crucial features for automotive vehicles as it is one of the most fundamental requirements of all the autonomy features of Advanced Driver Assistance Systems (ADAS).
ADAS
deep neural network (DNN)
DBSCAN
object detection
1. Introduction
Autonomous driving has become a hotspot research topic as the intelligent transport system and environmental perception improves daily. LMD is one of the significant parts of the environmental perception system, where many efforts have been made in the previous decade. Nevertheless, developing an efficient lane detection framework under different environmental circumstances is a highly challenging task because it has many dependencies that may influence the framework’s final output.
Various preprocessing techniques have a significant role in lane marking detection systems, mostly dependent on heuristic features. Distinct types of filters such as Finite Impulse Response (FIR) [1], Gaussian [2], and mean and median [3] are used to remove the noise from the input dataset. Duan et al. [4] introduced threshold segmentation to deal with the variation in illumination. Additionally, PLSF [5] and Otsu [6] are also applied for the same region. There are different Regions of Interest (ROI) that are examined to avoid redundancy, such as vanishing point-based ROI [7], adaptive ROI [8], and Fixed-size ROI [9]. An essential preprocessing tool to enhance the quality of lane marks is colour conversion, such as the RGB to HSV colour model.
There are many algorithms applied to extract lane features, especially for straight lanes, for instance, Hough [10], Canny [8], Sobel [9], and FIR filter [11]. Catmull–Rom spline [12], clothoid curve [13], parabolic [14], and cubic B-spline [2] are applied for curved lanes. A few other techniques are used under complex conditions, such as image enhancement [15] and wavelet analysis [16].
DNN (Deep Neural Network) has become one of the most promising computer vision techniques since AlexNet won the ILSVRC challenge in 2012. These deep learning techniques have shown promising performances in various fields of research. Recently, various efficient deep learning approaches have been examined for lane marking detection. From the beginning, Convolution Neuron Network (CNN) [17][18] to the GAN-based method [19] and segmentation process [20] have obtained efficient results on LMD. Additionally, DAGMapper [21] and attention map [22] have been applied to understand the structural features of the lanes. Though these techniques have obtained auspicious results, LMD is still challenging for its lack of generalization capability. For instance, a trained model in a particular scenario, such as daytime, may obtain poor results in other environmental scenarios, such as nighttime.
2. LMD Using DNN
The existing lane marking detection approaches can be classified into two major categories: single-stage and two-stage [23]. The initial segment of the two-stage frameworks extracts the heuristic recognition and deep learning-based lane features. In contrast, the second segment refers to the post-processing steps, which may include fitting, clustering, or interfacing. However, the single-stage lane detection approach provides final results directly from the input stage, including post-processing and cluster results. The LMD using the deep neural network has been discussed from four perspectives: preprocessing, network architecture, network loss functions, and post-processing.
2.1. Pre-Processing
ROI cropping is applied to remove the irrelevant information from the input dataset in the traditional and initial parts of the deep learning approaches. Consequently, it reduces the computational complexity and increases the running speed of the framework. As the lane markings are visualized on the lower part of the image frames, the clipped portion refers to the frames’ upper or sky part. Thus, it reduces the computational complexity by around 30% [23].
Some advanced techniques, such as meta-learning, can be examined to ameliorate the generalization of the CNN method. It can also be improved by diversifying the training dataset. The augmentation technique has a significant role in diversifying and increasing the number of data in the image dataset. In this process, data can be cropped, rotated, brightened, and mirrored to assort the training dataset shown in Figure 1 as a reference.

Figure 1. Different pre-processing technique (a) original, (b) cropped, (c) brighten (d) mirrored, (e) rotating and (f) perspective.
2.2. Network Architecture of LMD
There are many strategies to detect the LMD using a deep learning network, though these strategies can be categorized based on defining the LMD task. Therefore, these techniques can be classified as object detection, classification, and segmentation of lanes. Every feature point on lane segments is labeled, and detects the lanes as an object by the regression coordinates. In comparison, lane position is determined by combining the prior information in the classification techniques. On the contrary, background and lane pixels are labelled as distinct classes and detect the lane through semantic or instant segmentation. However, some LMD techniques are also satisfied with multiple purposes along with detecting lane marks, such as road marking detection, road type classification, and drivable area detection. Initially, architectural information can be managed from the primary convolution network, such as ResNet, VGG, and FCN.
2.2.1. The Initial Network Architecture of LMD
CNN was first introduced to extract the lane feature in LMD by Kim et al. [17]. Additionally, random sample consensus (RANSAC) was used to group the identical architecture of the lane locations. The CNN architecture, shown in Figure 2, consists of three convolution layers, two subsampling layers, and three fully connected layers (FCL). The input dataset was converted into 192 × 28 after the ROI and edge detection. The last FCL provided the predicted output of 100 × 15.
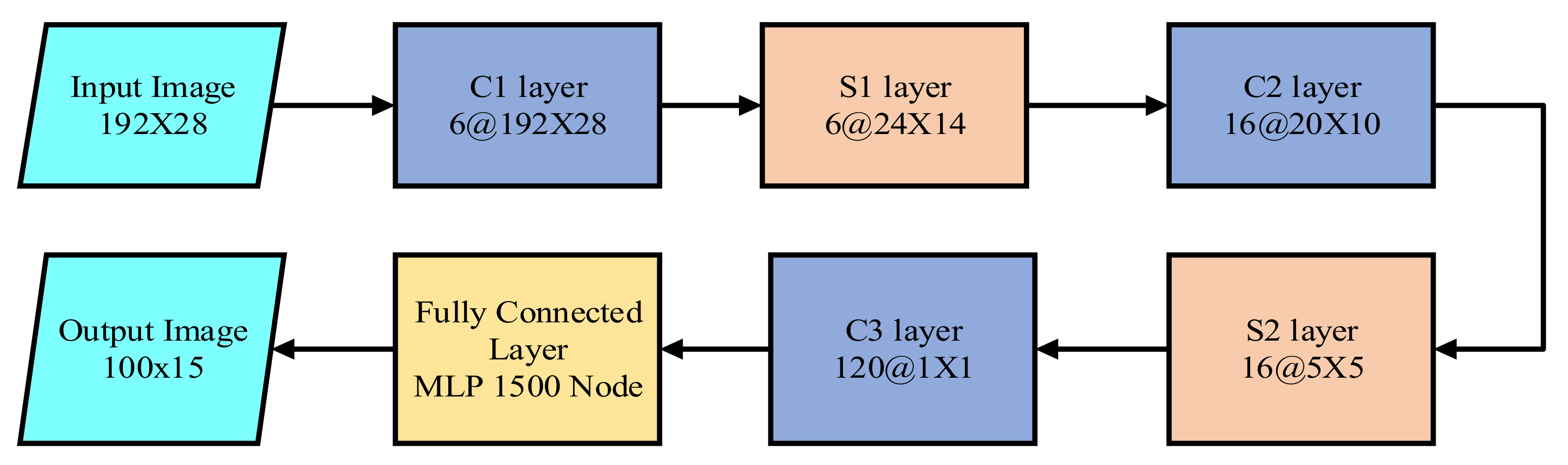
Figure 2. The architecture of CNN based lane marking detection technique.
Though it has improved LMD compared to the traditional methods, it also has some research limitations. The approach requires complex data processing unit and has a complex architecture of eight layers. Therefore, other researchers have developed other improved deep neural networks to overcome the existing limitations.
2.2.2. Lane Detection Based on Object Detection
Various types of visual detection systems are available for the autonomous driving system, such as road marking detection, vehicle detection, and, most importantly, lane marking detection. Sermanet et al. [24] introduced the overfeat technique, emphasizing the importance of a multi-supervised training approach, which simultaneously improved performance due to location, detection, and classification. Two key points typically focus on object detection, such as predicting the object and position of the object on the image.
Huval et al. [25] introduced empirical evaluation of the deep learning (EELane) technique with an overfeat detector to detect the highway’s lane markings. This research aims to apply six regressions to predict the lanes. The initial four regression dimensions indicate the finishing aspects of the line under the segmented lane boundary. The reaming regression dimension conceding the camera suggests the more profound finishing points. The geometrical information from CNN has been applied for many purposes, such as edge detection and inpainting, to assist the main task. The reader can go through it for a detailed understanding [26].
Seokju et al. [27] introduced VPGNet based on VPD, also a geometric estimation method of CNN. It is a modified version of the vanishing point tracking method, composed of four segments. The Vanishing point can guide road marking recognition and lane detection, which was the main contribution of the VPGNet. VPGNet has some post-processing framework for lane regression and clustering, increasing computational complexity. The architecture of the network is shown in Figure 3.
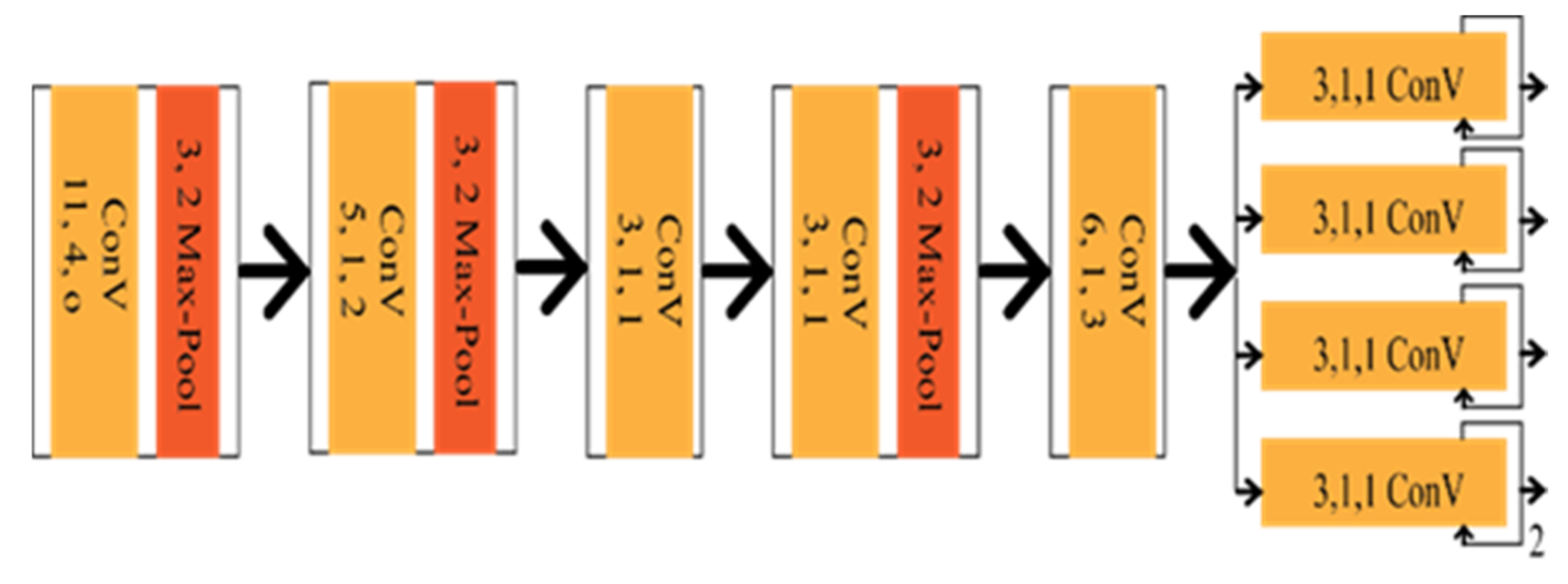
Figure 3. Schematic diagram of VPGNet.
EELane and VPGNet showed the effectiveness of the multi-branch techniques where lane detection can be guided from prior knowledge by sharing different tasks into contiguous representations. Huang et al. [28] combined the spatial and temporal data in the CNN framework to detect the lane markings by selecting the lane boundaries. Therefore, the computational time is reduced, allowing it to be run more effectively in the automated driving car under intricate weather and traffic schemes in real-time. With this aim in mind, lane location estimation is obtained by evaluating Inverse Perspective Transformation (IPM) from the overhead view of the images using spatial and temporal relevancy of lanes. The images are cropped into relevant sub-image, carrying out the local lanes’ boundary information. Sequentially, the CNN framework is applied to detect the actual location and boundary of the lanes. The final structure is optimized to reduce the computational complexity by selecting the adjacent lanes based on the lane change for searching for the lanes’ actual position. The architecture of the network is depicted in Figure 4. The study of spatial and temporal relevancy of lanes made it different from EELane and VPGNet, whereas IM’s implementation created the condition of its robustness. However, this makes up for low illumination conditions, such as at night and rainy conditions [28].
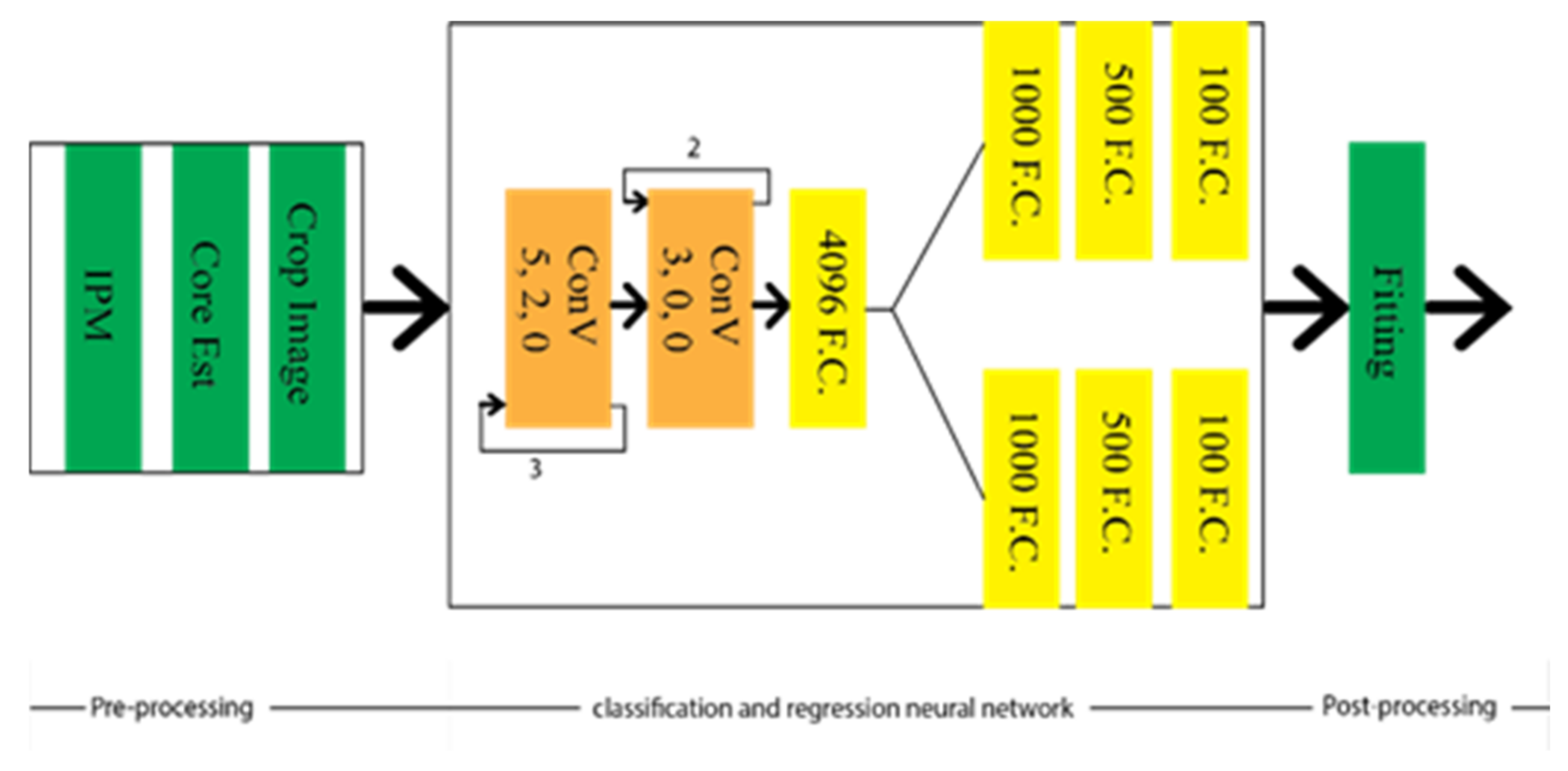
Figure 4. Schematic diagram of spatial and temporal based LMD technique.
2.2.3. Lane Detection Based on the Classification
Image classification refers to the discrimination process of objects available in the input image frame. However, the location of the lane can not be tracked through this process. Therefore, some modification is required in the classification technique to track the lane’s location. Let researchers consider the amendment on the classification is y = f(x,pm(p)), where f(x) is the CNN mapping function, and pm(p) is the prior knowledge depending on the lane location. Gurghian et al. [18] have come up with DeepLane depending on the same idea, which network architecture is shown in Figure 5. DeepLane received the training dataset, which was created from the image frames of the downward camera. It was classified into 317 classes, among which, 316 were for the probable lane position and reaming one was for missing lanes. A softmax function was applied to the last fully connected layer to achieve the probability distribution. The lane position was estimated Ei through the following equation:
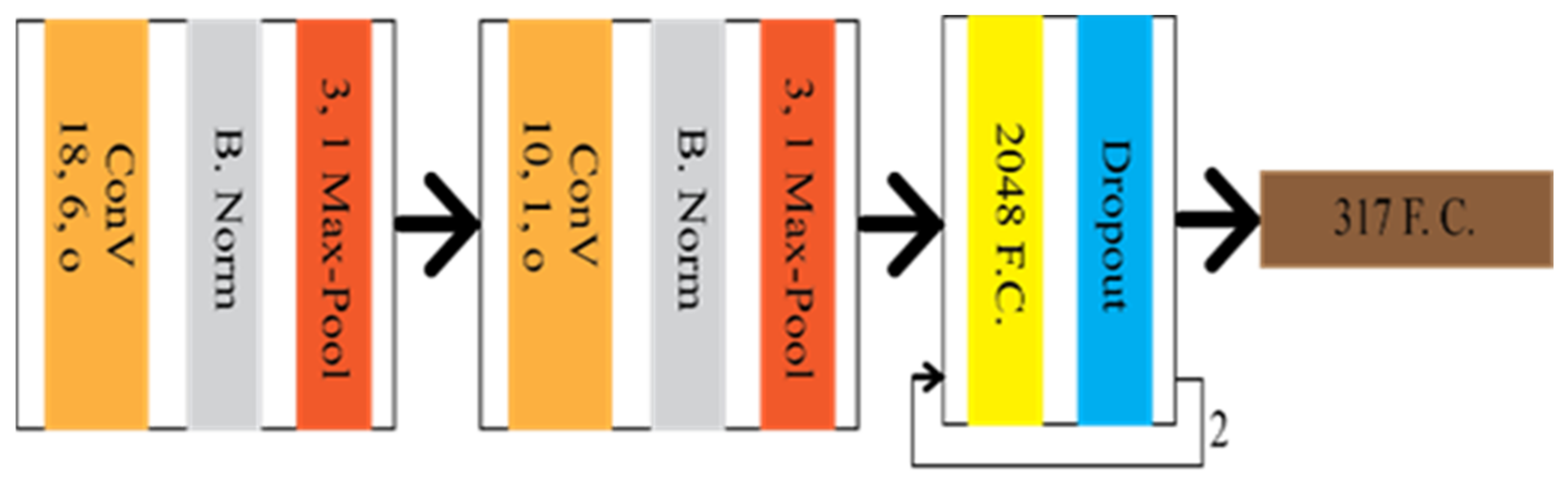
Figure 5. Schematic diagram of DeepLane.
Though DeepLane has achieved a better result than a complex network [17], the prior fixing of the lane position has limited its robustness. In addition, the classification techniques do not fit with lane marking detection, as it is associated with the high-level task. As discussed earlier, the regression of the lane coordinate as an object detection process is also a better possible way to detect lane marking detection.
2.2.4. Lane Detection Based on the Segmentation
Segmentation approaches such as [29][30][31] can be the best option for lane marking detection, as mentioned by Shriyash et al. [32]. These approaches strictly emphasize per-pixel classification rather than focusing on particular shapes. Lane detection based on the segmentation framework achieved more efficient results, except for the concern of the above limitation. This problem is solved by many strategies, such as the strategy proposed by Chiu et al. [33], which referred to the lane marking detection system as an image segmentation problem. However, the conventional segmentation approaches did not last long.
-
End-to-End Segmentation Approach
Due to the previous reason, the researcher started to apply end-to-end segmentation approaches for lane marking detection. The network can carry more features according to the larger size of the convolution kernel. Zhang et al. introduced a GCN [34] algorithm to detect particular lane areas. A lane departure system based on Mask-RCNN [35] is proposed by Riera Luis et al. to detect the lane marks and an additional Kalman filter to track the lanes. Shriyash et al. [36] proposed a CNN architecture that consists of ten neuron layers to detect the lanes in real time. Different types of lanes also have a notable contribution to more comprehensive recognition detection. The modified ERFNet architecture was designed by Fabio et al. [37] to classify the road lanes and identify the drivable area.
Semantic Segmentation through DCNN may have some deficiencies, as it has no learnable pooling parameters. For instance, there is no learnable parameter in max/min pooling or un-sampling layers. Therefore, there is an extreme possibility of losing many features when attempting to recognize a large-perspective field. Kontun et al. [38] introduced dilated convolution to resolve this issue, which can be studied more in [39]. Though this framework had significant advantages, the effective design of CNN architecture emphasizing dilated convolution has become a new issue.
Chen et al. proposed a Deep Convolution Neural Network based on the lane markings detector (LMD), aiming to have the optimal CNN architecture design with dilated convolution [40]. The lane markings detector, similar to ResNet [41] and VGG [42], is used as an encoder to classify, and DeconvNet [43], U-Net [44], and FCN [45] are used as a decoder to create feature maps. Additionally, dilated convolutions were embedded in the encode–decode section of the architecture shown in Figure 6. Lo et al. [40] introduced a CNN architecture based on DDB (Digressive Dilation Block) and FSS (Feature Size Selection), considering the spatial and downsampling operation, which was also embedded with dilation convolution [46].
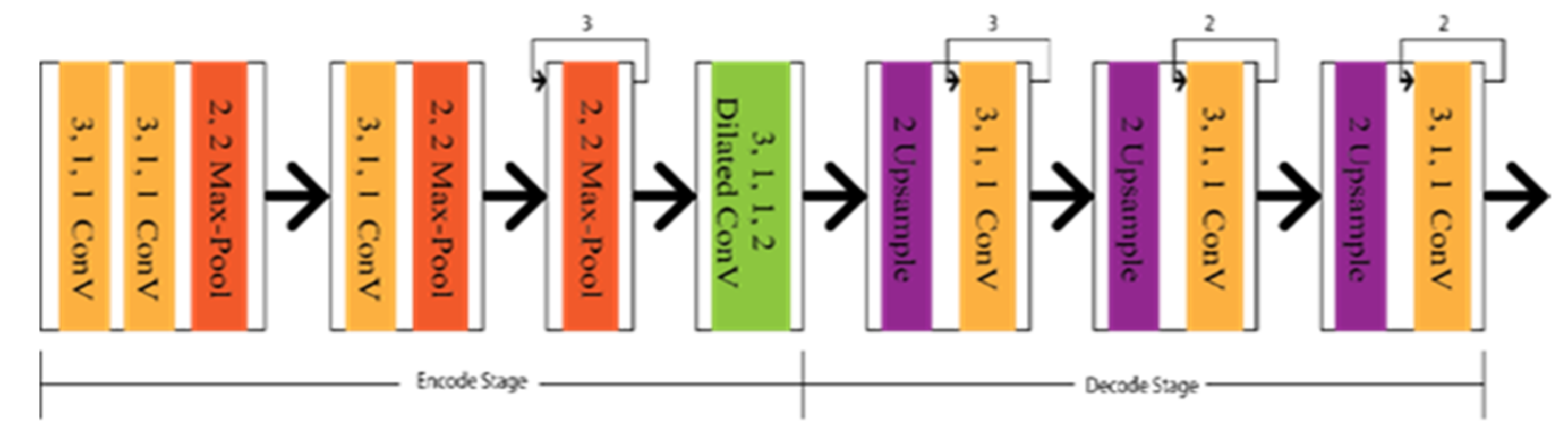
Figure 6. Schematic diagram of Deep Convolution Neural Network based on the lane markings detector (LMD).
Long-range information in lane marking detection is another concern. Wang et al. [47] designed a non-local operation depending on a non-local framework [48]. The model could extract the long-distance or range information, as long-distance information is also one of a lane’s properties. Li et al. [49] proposed Instance batch normalization and Attention Network (IANet) to emphasize the model for considering a particular lane region. It is more appropriate for two-class segmentation scenarios, according to the experimental result.
Considering efficient classification by focusing on pixels rather than shape, Jan et al. [50] came up with an adversarial network known as generative adversarial networks (GAN). It has a generator to create the synthetic data and a discriminator to differentiate the real data from the generator’s output data. The initial concept for the GAN was to predict data closely approximate to the real data. The recent concept tells researchers to differentiate accurately to determine whether the input is generated or real. A reader can go through [51][52][53] for further information about the GAN. Ghafoorian et al. [19] designed Embedding loss GAN (EL-GAN) based on the GNN concept. The framework is divided into two segments, as generator and discriminator. The schematic diagram of the EL-GAN framework is shown in Figure 7. U-Net’s unique algorithm is applied for the generator to train the input, and Tiramisu DenseNet [54] is used for detecting the lane markings. This process is continued up to the level of convergence. In the case of the discriminator, DenseNet [55][56] is used with the fully connected Generative Adversarial Network classification [57].
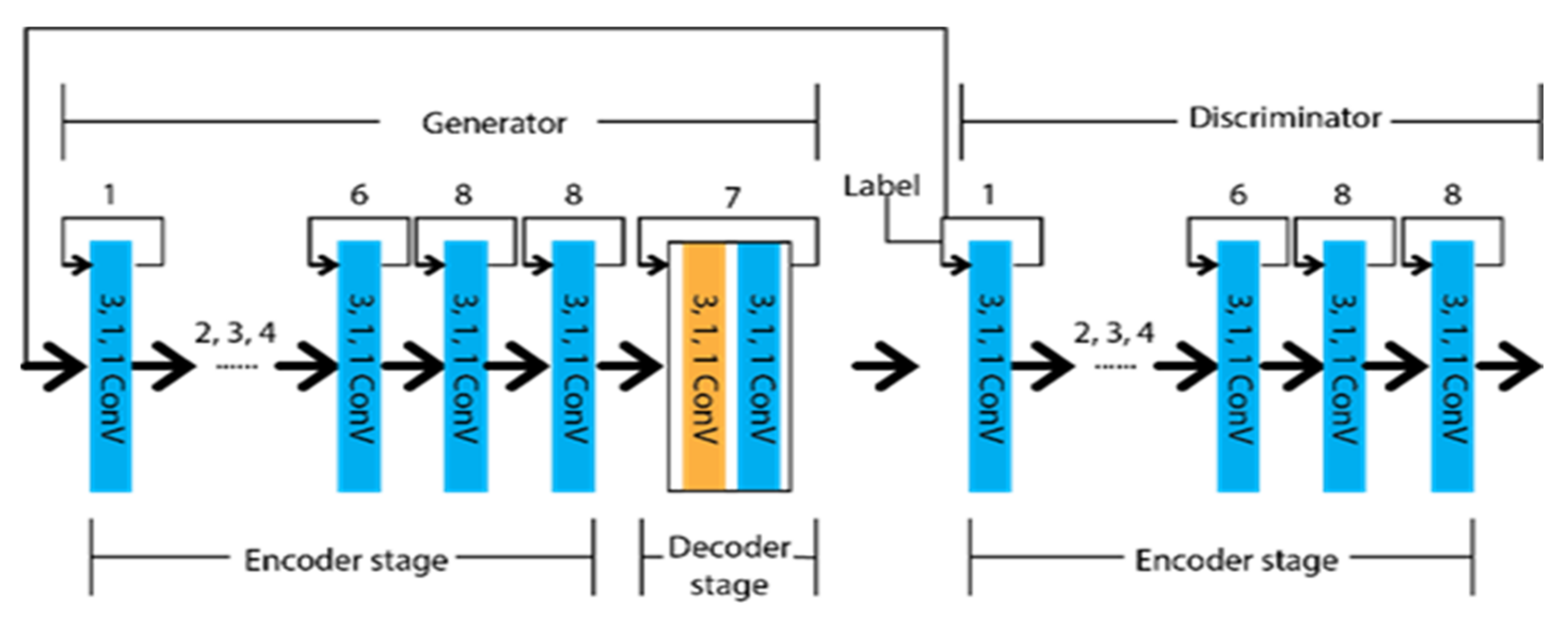
Figure 7. Schematic diagram of EL-GAN.
The framework generator is trained by adversarial embedding and Adam optimizer, whereas the discriminator is trained by stochastic gradient descent and ordinary cross-entropy. Embedding loss can be considered perceptual loss [58], whereas EL-GAN combines perceptual loss and CGAN.
-
Segmentation based on multitask
Geometrical features of roads also have an important role in lane marking detection, which have better performance results than VPGNet. Zhang et al. [59] proposed Geometric Constrained Network (GLCNet), which has multitasked to interlink the lane boundary and lane segmentation sub-structure. The architecture of GLCNet [59] is shown in Figure 8, which indicates that every decode section has a link with the encode section to transfer corresponding features into two distinct tasks. Therefore, the information from the decode sections can be redounded reciprocally. This multitask strategy opened the gate for the researchers to develop a framework for the link between lane boundary and lane area. Considering the same idea as GCLNet, John et al. [60] designed PSINet for multiple detection purposes, such as road scene labels, lane marks, and free space on the road.
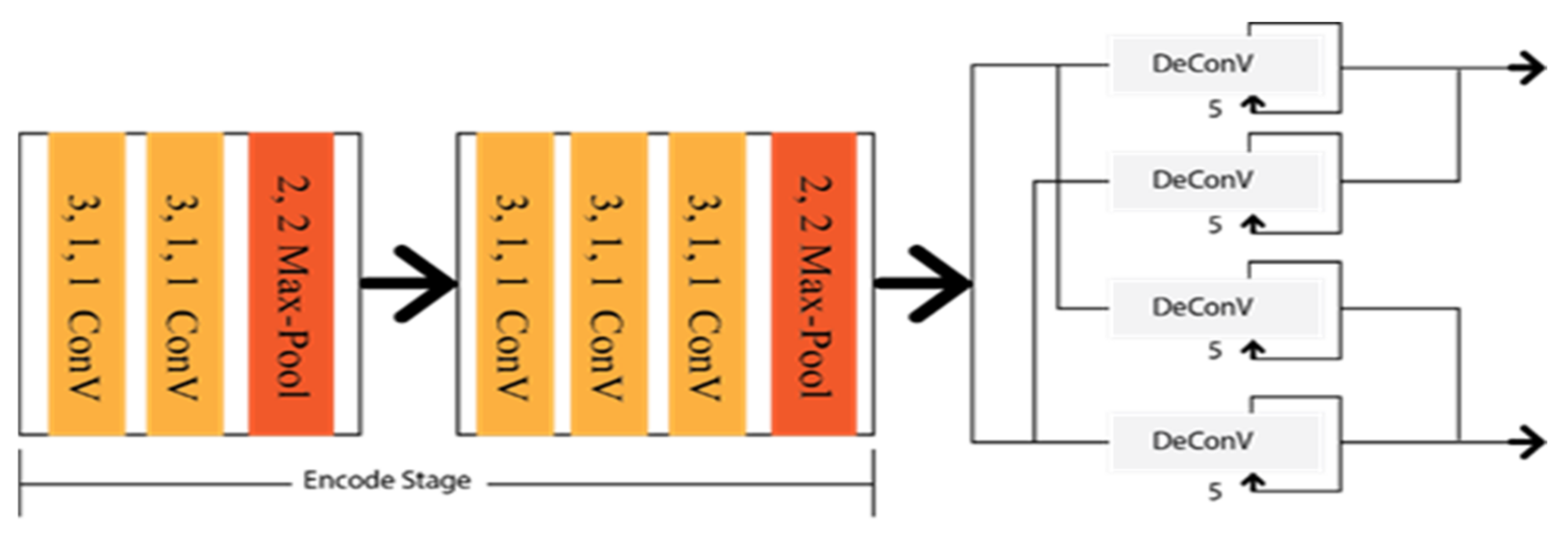
Figure 8. Schematic diagram of GLCNet.
In addition to the geometric or special feature, temporal correlation might have a significant effect where a lane can not be detected due to the linear structure of the captured video. As Long short-term memory (LSTM) has memory capture capability, the lane can be extracted from the previous frame by this LSTM approach. Hence, Qin et al. [61] proposed a CNN-LSTM method that includes two LSTM layers between the encode–decode stage. The major achievement of this method is that it has obtained ameliorate performance results under different occlusion scenarios. The architecture of the CNN-LSTM method is depicted in Figure 9, which indicates the temporal information transfer between the encode–decode stage through LSTM.
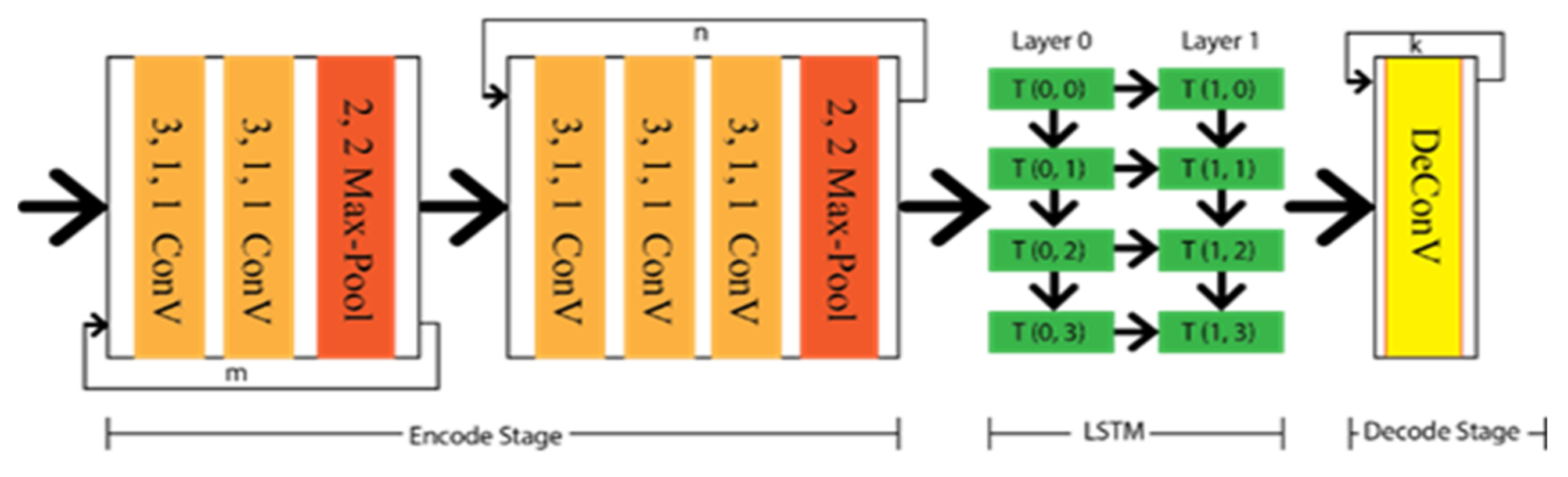
Figure 9. Schematic diagram of CNN-LSTM.
2.2.5. Simplification of the Post-Processing Step
Without considering the optimization by the post-processing step, the described frameworks extracted lane features more efficiently. It is very challenging to differentiate the lane features from the output, excluding the post-processing approach. Effective strategies are more important than particular network architecture to discover the optimal result. This sub-section focuses on these strategies, rather than a deep neural network (DNN) architecture, on lane marking detection.
There are two types of algorithmic output possible for lane marking detection using DNN, such as lane points and lane lines. Hence, the possibilty is raised to utilize different lane features, excluding post-processing steps. There might be three possible solutions to overcome the particular constraint: semantic segmentation by labelling each line as separate classes, instance segmentation by referring to every lane as a different instance, and multi-branch CNN structure by detecting every lane line through the individual branch.
Xingang et al. [20] applied a Spatial Convolution Neural Network (SCNN) to detect the lanes under occlusion scenarios as multi-class semantic segmentation. SCNN framework is based on the LargeFOV layout [62], and the weight of the initial thirteen convolution layers is taken from VGG16 [42]. To predict the lanes precisely, it generates pixel-wise probability maps for training the network. Consequently, it applies a CNN to differentiate the lane markings on its own. Finally, the probability maps are sent to the system to predict the lane markings of different classes. The architecture of the SCCN is shown in Figure 10, where various branches were designed to predict other lane classes.

Figure 10. Schematic diagram of SCCN.
Shriyash et al. [32] proposed Coordinate Network (CooNet) as a lane point regression approach. It is a multi-branch neural network shown in Figure 11, where lanes are predicted in their perspective branches. However, this network has no clustering process as the network directly provides the lane output through the coordinate regression.
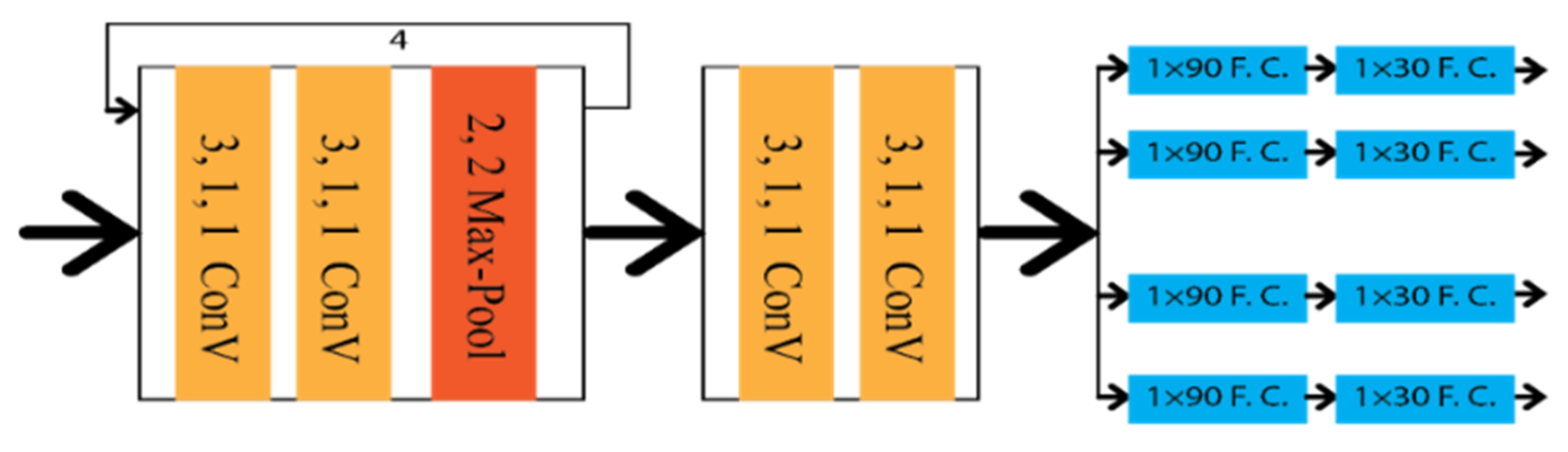
Figure 11. Schematic diagram of CooNet.
To detect multi lanes with changes from the lanes, Davy et al. [63] introduced an end-to-end lane detection approach by applying the LaneNet deep learning method based on the encoding–decoding procedure E-Net [64], as shown in Figure 12. It takes the shared encodes from the input images and finds the embedding binary segmentation for each pixel for creating the cluster together. All pixels can associate with the neighbourhood pixels. It utilized the H-Net to collect the ideal information about the perspective transformation by imposing a relevant condition on the input image. The research aimed to take the challenge on lane changes, unlike the bird’s eye view. Additionally, this approach has no limitation on the number of lanes, whereas CooNet and SCNN can only detect up to four lanes.
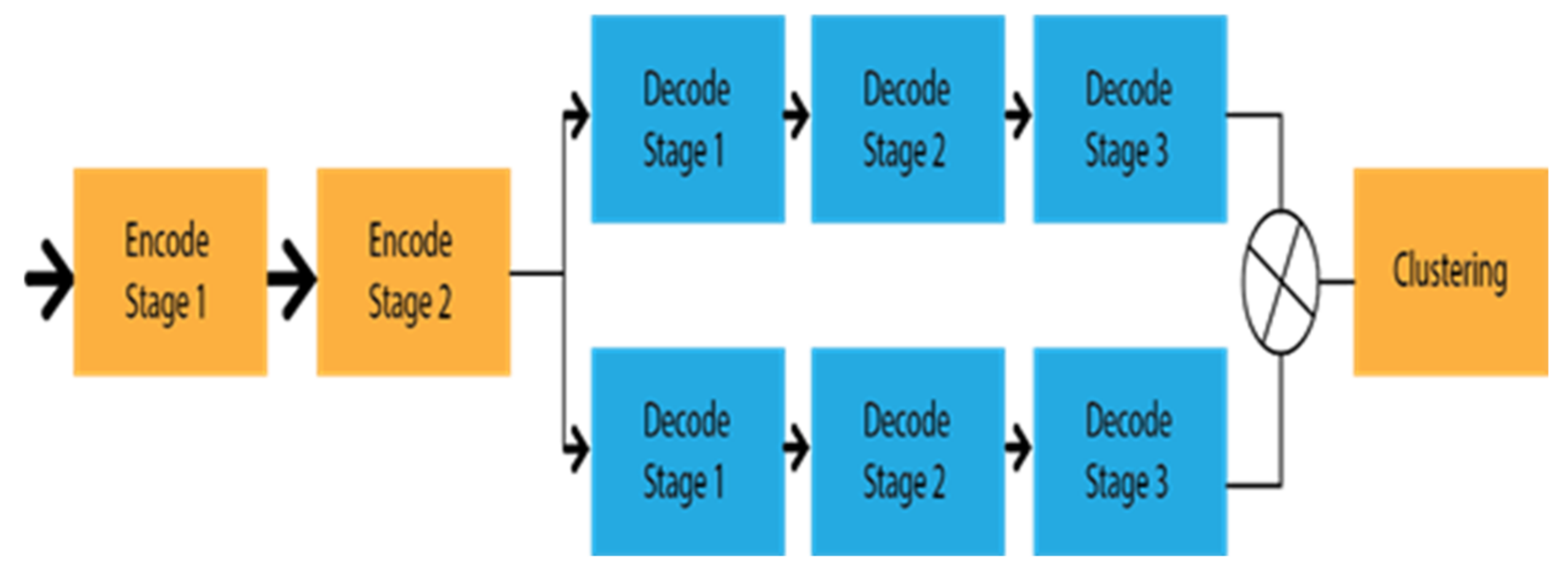
Figure 12. Schematic diagram of Lanenet.
References
- Wang, X.; Wang, Y.; Wen, C. Robust lane detection based on gradient-pairs constraint. In Proceedings of the 30th Chinese Control Conference, Yantai, China, 22–24 July 2011; pp. 3181–3185.
- Hsiao, P.-Y.; Yeh, C.-W.; Huang, S.-S.; Fu, L.-C. A portable vision-based real-time lane departure warning system: Day and night. IEEE Trans. Veh. Technol. 2009, 58, 2089–2094.
- Wang, J.-G.; Lin, C.-J.; Chen, S.-M. Applying fuzzy method to vision-based lane detection and departure warning system. Expert Syst. Appl. 2010, 37, 113–126.
- Duan, J.; Zhang, Y.; Zheng, B. Lane line recognition algorithm based on threshold segmentation and continuity of lane line. In Proceedings of the 2016 2nd IEEE International Conference on Computer and Communications, ICCC 2016, Chengdu, China, 14–17 May 2017; pp. 680–684.
- Gaikwad, V.; Lokhande, S. Lane Departure Identification for Advanced Driver Assistance. IEEE Trans. Intell. Transp. Syst. 2015, 16, 910–918.
- Chai, Y.; Wei, S.J.; Li, X.C. The Multi-scale Hough transform lane detection method based on the algorithm of Otsu and Canny. Adv. Mater. Res. 2014, 1042, 126–130.
- Ding, D.; Lee, C.; Lee, K.-Y. An adaptive road ROI determination algorithm for lane detection. In Proceedings of the 2013 IEEE International Conference of IEEE Region 10 (TENCON 2013), Xi’an, China, 22–25 October 2013.
- Wu, P.-C.; Chang, C.-Y.; Lin, C.H. Lane-mark extraction for automobiles under complex conditions. Pattern Recognit. 2014, 47, 2756–2767.
- Mu, C.; Ma, X. Lane Detection Based on Object Segmentation and Piecewise Fitting. TELKOMNIKA Indones. J. Electr. Eng. 2014, 12, 3491–3500.
- Niu, J.; Lu, J.; Xu, M.; Lv, P.; Zhao, X. Robust Lane Detection using Two-stage Feature Extraction with Curve Fitting. Pattern Recognit. 2016, 59, 225–233.
- Aung, T. Video Based Lane Departure Warning System using Hough Transform. Int. Inst. Eng. 2014.
- Wang, Y.; Shen, D.; Teoh, E.K. Lane detection using spline model. Pattern Recognit. Lett. 2000, 21, 677–689.
- Xiong, H.; Huang, L.; Yu, M.; Liu, L.; Zhu, F.; Shao, L. On the number of linear regions of convolutional neural networks. In Proceedings of the 37th International Conference on Machine Learning (ICML), online, 13–18 July 2020; pp. 10445–10454.
- McCall, J.; Trivedi, M. Video-based lane estimation and tracking for driver assistance: Survey, system, and evaluation. IEEE Trans. Intell. Transp. Syst. 2006, 7, 20–37.
- Li, Y.; Chen, L.; Huang, H.; Li, X.; Xu, W.; Zheng, L.; Huang, J. Nighttime lane markings recognition based on Canny detection and Hough transform. In Proceedings of the 2016 IEEE International Conference on Real-Time Computing and Robotics, RCAR, Angkor Wat, Cambodia, 6–10 June 2016; pp. 411–415.
- Mingfang, D.; Junzheng, W.; Nan, L.; Duoyang, L. Shadow Lane Robust Detection by Image Signal Local Reconstruction. Int. J. Signal Process. Image Process. Pattern Recognit. 2016, 9, 89–102.
- Kim, J.; Lee, M. Robust lane detection based on convolutional neural network and random sample consensus. In Proceedings of the International Conference on Neural Information Processing, Kuching, Malaysia, 3–6 November 2014; Volume 8834, pp. 454–461.
- Gurghian, A.; Koduri, T.; Bailur, S.V.; Carey, K.J.; Murali, V.N. DeepLanes: End-To-End Lane Position Estimation Using Deep Neural Networks. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 38–45.
- Ghafoorian, M.; Nugteren, C.; Baka, N.; Booij, O.; Hofmann, M. EL-GAN: Embedding loss driven generative adversarial networks for lane detection. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2019; Volume 11129, pp. 256–272.
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial as deep: Spatial CNN for traffic scene understanding. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 7276–7283.
- Homayounfar, N.; Liang, J.; Ma, W.-C.; Fan, J.; Wu, X.; Urtasun, R. DAGMapper: Learning to map by discovering lane topology. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 2911–2920.
- Hou, Y.; Ma, Z.; Liu, C.; Loy, C.C. Learning lightweight lane detection CNNS by self attention distillation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; Volume 2019, pp. 1013–1021.
- Tang, J.; Li, S.; Liu, P. A review of lane detection methods based on deep learning. Pattern Recognit. 2021, 111, 107623.
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. In Proceedings of the 2nd International Conference Learning Representations ICLR 2014, Banff, AB, Canada, 14–16 April 2014.
- Huval, B.; Wang, T.; Tandon, S.; Kiske, J.; Song, W.; Pazhayampallil, J.; Andriluka, M.; Rajpurkar, P.; Migimatsu, T.; Chen-Yue, R. An Empirical Evaluation of Deep Learning on Highway Driving. arXiv 2015, arXiv:1504.01716.
- Elharrouss, O.; Almaadeed, N.; Al-Maadeed, S.; Akbari, Y. Image Inpainting: A Review. Neural Process. Lett. 2020, 51, 2007–2028.
- Lee, S.; Kim, J.; Yoon, J.S.; Shin, S.; Bailo, O.; Kim, N.; Lee, T.-H.; Hong, H.S.; Han, S.-H.; Kweon, I.S. VPGNet: Vanishing Point Guided Network for Lane and Road Marking Detection and Recognition. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1965–1973.
- Huang, Y.; Chen, S.; Chen, Y.; Jian, Z.; Zheng, N. Spatial-temproal based lane detection using deep learning. In Artificial Intelligence Applications and Innovations; Springer International Publishing: Cham, Switzerland, 2018; Volume 519.
- Al Mamun, A.; Em, P.P.; Hossen, J. Lane marking detection using simple encode decode deep learning technique: SegNet. Int. J. Electr. Comput. Eng. 2021, 11, 3032–3039.
- Al Mamun, A.; Ping, E.P.; Hossen, J. An efficient encode-decode deep learning network for lane markings instant segmentation. Int. J. Electr. Comput. Eng. 2021, 11, 4982–4990.
- Al Mamun, A.; Em, P.P.; Hossen, M.J.; Tahabilder, A.; Jahan, B. Efficient lane marking detection using deep learning technique with differential and cross-entropy loss. Int. J. Electr. Comput. Eng. 2022, 12, 4206–4216.
- Chougule, S.; Koznek, N.; Ismail, A.; Adam, G.; Narayan, V.; Schulze, M. Reliable multilane detection and classification by utilizing CNN as a regression network. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2019; Volume 11133, pp. 740–752.
- Chiu, K.Y.; Lin, S.F. Lane detection using color-based segmentation. In Proceedings of the IEEE Intelligent Vehicles Symposium, Las Vegas, NV, USA, 6–8 June 2005; Volume 2005, pp. 706–711.
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large kernel matters—Improve semantic segmentation by global convolutional network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1743–1751.
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397.
- Chougule, S.; Ismail, A.; Soni, A.; Kozonek, N.; Narayan, V.; Schulze, M. An efficient encoder-decoder CNN architecture for reliable multilane detection in real time. In Proceedings of the IEEE Intelligent Vehicles Symposium, Changshu, China, 26–30 June 2018; pp. 1444–1451.
- Pizzati, F.; Garcia, F. Enhanced free space detection in multiple lanes based on single CNN with scene identification. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 2536–2541.
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2016, arXiv:1511.07122.
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding Convolution for Semantic Segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460.
- Chen, P.-R.; Lo, S.-Y.; Hang, H.-M.; Chan, S.-W.; Lin, J.-J. Efficient Road Lane Marking Detection with Deep Learning. In Proceedings of the 2018 IEEE 23rd International Conference on Digital Signal Processing (DSP), Shanghai, China, 19–21 November 2018; pp. 1–5.
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778.
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2015, arXiv:1409.1556.
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528.
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015; Volume 9351, pp. 234–241.
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651.
- Lo, S.-Y.; Hang, H.-M.; Chan, S.-W.; Lin, J.-J. Multi-Class Lane Semantic Segmentation using Efficient Convolutional Networks. In Proceedings of the 2019 IEEE 21st International Workshop on Multimedia Signal, Kuala Lumpur, Malaysia, 27–29 September 2019.
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7794–7803.
- Buades, A.; Coll, B.; Morel, J.-M. A non-local algorithm for image denoising. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 60–65.
- Li, W.; Qu, F.; Liu, J.; Sun, F.; Wang, Y. A lane detection network based on IBN and attention. Multimed. Tools Appl. 2020, 79, 16473–16486.
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. arXiv 2014, arXiv:1406.2661.
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved Training of Wasserstein GANs. 2017. Available online: https://github.com/igul222/improved (accessed on 30 November 2020).
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.K.; Wang, Z.; Smolley, S.P. Least Squares Generative Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2813–2821.
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. arXiv 2017, arXiv:1701.07875.
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An Open Urban Driving Simulator. arXiv 2017, arXiv:1711.03938.
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269.
- Jegou, S.; Drozdzal, M.; Vazquez, D.; Romero, A.; Bengio, Y. The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1175–1183.
- Li, C.; Wand, M. Precomputed real-time texture synthesis with markovian generative adversarial networks. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 9907, pp. 702–716.
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Lecture Notes Computer Science; Springer: Cham, Switzerland, 2016; Volume 9906, pp. 694–711.
- Zhang, J.; Xu, Y.; Ni, B.; Duan, Z. Geometric Constrained Joint Lane Segmentation and Lane Boundary Detection. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 11205, pp. 502–518.
- John, V.; Karunakaran, N.M.; Guo, C.; Kidono, K.; Mita, S. Free Space, Visible and Missing Lane Marker Estimation using the PsiNet and Extra Trees Regression. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 189–194.
- Zou, Q.; Jiang, H.; Dai, Q.; Yue, Y.; Chen, L.; Wang, Q. Robust lane detection from continuous driving scenes using deep neural networks. IEEE Trans. Veh. Technol. 2020, 69, 41–54.
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848.
- Neven, D.; De Brabandere, B.; Georgoulis, S.; Proesmans, M.; Van Gool, L. Towards End-to-End Lane Detection: An Instance Segmentation Approach. In Proceedings of the IEEE Intelligent Vehicles Symposium, Rio de Janeiro, Brazil, 8–13 July 2018; Volume 2018, pp. 286–291.
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. azXiv 2016, arXiv:1606.02147.
More
Information
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
1.6K
Revisions:
2 times
(View History)
Update Date:
27 Oct 2022
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No