 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | George A. Papakostas | + 3394 word(s) | 3394 | 2021-09-10 10:05:28 | | | |
| 2 | Lindsay Dong | -14 word(s) | 3380 | 2021-10-26 11:56:27 | | |
Video Upload Options
One of the most important challenges in the computer vision (CV) area is Medical Image Analysis in which DL models process medical images—such as magnetic resonance imaging (MRI), X-ray, computed tomography (CT), etc.—using convolutional neural networks (CNN) for diagnosis or detection of several diseases. The proper function of these models can significantly upgrade the health systems. However, recent studies have shown that CNN models are vulnerable under adversarial attacks with imperceptible perturbations.
1. Introduction
Adversarial attacks have raised concerns in the research community about the safety of deep neural networks and how we can trust our lives on them when they can be fooled easily. Adversarial examples can be created either we know the parameters of the DL model (white box attacks) or not (black box attacks) [1]. Usually, the noise that the attackers add in a clean image is not random but is computed by optimizing the input to maximize the prediction error. However, there are random noises too, which are implemented when the model’s parameters are unknown. Furthermore, there is a phenomenon that is called “adversarial transferability” and this means that adversarial examples which are created from one model can be effective on another model [2]. In addition to this, a study from Kurakin et al. [3] proved that adversarial examples are able to fool a model in the real-world when an adversarial example is printed as is shown in Figure 1.

2. Medical Image Analysis
2.1. Classification—Diagnosis
2.2. Detection
2.3. Segmentation
3. General Adversarial Examples
An adversarial example is an input sample in which it has been added an imperceptible noise so that it can be misclassified. A characteristic example is presented in Figure 2 where an attack has been applied to a deep learning model [5] leading to a wrong classification with high confidence. Szegedy et al. [4] were the first authors who investigated adversarial examples and they concluded that the success of this attack is due to the lack of generalization in the low probability space of data. However, some later works [5][8] have shown that even linear models are vulnerable too and an increase to the model’s capacity improves its robustness to these attacks. According to Hu et al. [13], it is important to study why adversarial examples exist and to better understand deep learning models in order to create more robust models. Attacks can be divided into three categories depending on the knowledge of adversaries. The first category is the white-box attack in which adversaries know everything about the model such as architecture and parameters. The second category is named grey-box attack and the adversaries know the structure of the model but not the parameters. Lastly, in the third category, adversaries know nothing about the model’s structure and parameters. In addition to this, there are targeted and untargeted attacks. In the former, attackers want to misclassify the input sample in a specific class, while in the latter they just want the sample data to be misclassified. There are numerous adversarial attacks and defenses [14] but none of these defenses is a panacea for all types of attacks.

3.1. Adversarial Attacks
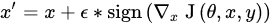
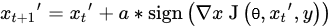
3.2. Adversarial Defenses
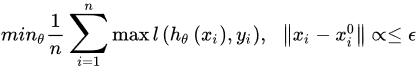
4. Adversarial Medical Image Analysis
4.1. Existing Adversarial Attacks on Medical Images
Paschali et al. [9] studied the effects of adversarial attacks on brain segmentation and skin lesion classification. For the classification task, InceptionV3, InceptionV4 [27], and MobileNet [28] models have been used, while SegNet [29], U-Net and DenseNet [30] were used for segmentation task. Experiments showed that InceptionV3 and DenseNet were the most robust models for classification and segmentation tasks respectively. The authors demonstrated that the robustness of a model is correlated with its depth for classification while for segmentation, dense blocks and skip connections increase its efficacy. The adversarial samples were imperceptibly as the SSIM was 0.97–0.99. Wetstein et al. [31] studied the factors that affect the efficacy of adversarial attacks. Their results show that the value of perturbation is correlated with the efficacy and perceptibility of the attacks. In addition, pre-training models enhance the adversarial transferability and finally, the performance of an attack can be reduced when there is inequality of data/model in target and attacker. Finlayson et al. [32] used PGD white and black box attacks on fundoscopy, dermoscopy, and chest X-ray images, using a pre-trained ResNet50 model. The accuracy of the model was dramatically decreased in both cases.
| Reference | Attacks | Models | Modality | Task | Performance Degradation (%) |
|---|---|---|---|---|---|
| [9] | FGSM, DF, JSMA | Inception, MobileNet, SegNet, U-Net, DenseNet | Dermoscopy, MRI | Classification, Segmentation | 6–24%/19–40% |
| [32] | PGD | ResNet50 | Fundoscopy, Dermoscopy, X-ray | Classification | 50–100% |
| [33] | UAP | U-Net | MRI | Segmentation | Up to 65% |
| [34] | UAP | DNN, Hybrid DNN | MRI | Classification | Not provided |
| [35] | FGSM, PGD | VGG16, MobileNet | Dermoscopy | Classification | Up to 75% |
| [36] | FGSM, PGD | VGG11, U-Net | X-ray, MRI | Classification, Segmentation | Up to 100% |
| [37] | FGSM, One-pixel attack | CNN | CT scans | Classification | 28–36%/2–3% |
| [38] | FGSM, VAT, Noise -based attack | CNN | MRI | Classification | 69%/34%/24% |
| [39] | I-FGSM | CNN, Hybrid lesion-bassed model | Fundoscopy | Classification | 45%/0.6% |
| [40] | PGD | Inception V3 | X-ray, Histology | Classification | Up to 100% |
| [41] | FGSM, I-FGSM | ResDSN Coarse | CT scans | Segmentation | 86% |
| [42] | Image Dependent Perturbation | DenseNet201 | Dermoscopy | Classification | 17% |
| [43] | UAP | VGGNets, InceptionResNetV2, ResNet50, DenseNets | Dermoscopy, Fundoscopy, X-ray | Classification | Up to 72% |
| [44] | UAP | COVIDNet | X-ray | Classification | Up to 45% |
| [45] | FGSM, PGD, C&W, BIM | ResNet50 | X-ray, Dermoscopy, Fundoscopy | Classification | Up to 100% |
| [46] | FGSM | VGG-16, InceptionV3 | CT scans, X-ray | Classification | Up to 90% |
| [47] | PGD | Similar to U-Net | X-ray | Segmentation | Up to 100% |
| [48] | FGSM | Custom CNN | Mammography | Classification | Up to 30% |
4.2. Adversarial Attacks for Medical Images

| Reference | Attack Name | Models | Modality | Task | Performance Degradation (%) |
|---|---|---|---|---|---|
| [49] | Fatty Liver Attack | InceptionResNetV2 | Ultrasound | Classification | 48% |
| [51] | ASMA | U-Net | Fundoscopy, Dermoscopy | Segmentation | 98% success rate on targeted prediction |
| [55] | Multi-organ Segmentation Attack | U-Net | CT scans | Segmentation | Up to 85% |
| [56] | AdvSBF | ResNet50, MobileNet, DensNet121 | X-ray | Classification | Up to 39% |
| [54] | Physical World Attacks | ResNet, InceptionV3, InceptionResNetV2, MobileNet, Xception | Dermoscopy | Classification | Up to 60% |
| [57] | HFC | VGG16, ResNet 50 | Fundoscopy, X-ray | All tasks | Up to 99.5% |
| [58] | MSA | U-Net, R2U-Net, Attention U-Net, Attention R2U-Net | Fundoscopy, Dermoscopy | Segmentation | 98% success rate on targeted prediction |
| [59] | SMIA | ResNet, U-Net, Custom CNNs | Fundoscopy, Endoscopy, CT-scans | Classification Segmentation | Up to 27% |
4.3. Defenses—Attack Detection
| References | Tested Attacks | Models | Modality | Task | Performance |
|---|---|---|---|---|---|
| [45][25][67] | FGSM, BIM, PGD, C&W | ResNet50 | X-ray, Dermoscopy, Fundoscopy | Classification | Detects adversarial example with up to 100% accuracy |
| [68] | FGSM | CNN | MRI | Segmentation | Improves baseline methods up to 1.5% |
| [69] | PGD | 3D ResNets | CT scans | Classification | Improves baseline methods up to 10% and 35% in perturbed data |
| [70] | FGSM, JSMA | CNN | CT scans, MRI | All tasks | Improves baseline methods up to 2% |
| [71] | VAT | UNet | MRI | Segmentation | Improves baseline methods up to 3% |
| [60] | PGD | ResNet32 | Fundoscopy | Classification | Accuracy increased by 40% |
| [61] | I-FGSM | U-Net, InvertNet, SLSDeep, NWCN, DCNN | X-ray | Segmentation | The dice score metric is reduced by only up to 11% |
| [66] | Gradient-based, Score-based, Decision-based | NasnetLarge, InceptionResNetV2 | X-ray | Classification | Accuracy increased by up to 9% |
| [72] | FNAF | U-Net, I-RIM | MRI | Reconstruction | Up to 72% more resilient |
| [73] | FNAF | U-Net, I-RIM | MRI | Reconstruction | Up to 72% more resilient |
| [74] | DAG | SegNet, U-Net, DenseNet | All modalities | Segmentation | Detects adversarial samples with 98% ROC_AUC |
| [75] | FGSM, I-FGSM, PGD, MIM, C&W | U-Net, V-Net, InceptionResNetV2 | Dermoscopy, X-ray | Segmentation, Classification | The accuracy is reduced by only up to 29% |
| [76] | Limited Angle | U-Net | CT scans | Reconstruction | Not provided |
| [77] | FGSM, I-FGSM, C&W | CNN | Fundoscopy, X-ray | Classification | The accuracy is reduced by only up to 24% |
| [78] | FGSM, BIM, PGD, C&W, DF | CNN | X-ray, CT scans | Classification | The accuracy is reduced by only up to 2% |
| [79] | ASMA | ResNet-50, U-Net, DenseNet | Dermoscopy, Fundoscopy | Classification, Segmentation | The accuracy is reduced by only up to 2% |
| [80] | FGSM, BIM, PGD, MIM | DenseNet121 | X-ray | Classification | Detects adversarial samples with up to 97.5% accuracy |
| [81] | FGSM, PGD, C&W | ResNet18 | Fundoscopy | Classification | Prediction accuracy under attack is 86.4% |
| [82] | FGSM | U-Net | CT-Scans | Segmentation | Improves baseline methods up to 9% in terms of IoU |
| [83] | FGSM, BIM, C&W DeepFool | VGG, ResNet | Microscopy | Classification | Detects adversarial samples with up to 99.95% accuracy |
| [84] | APGD-CE, APGD-DLR, FAB-T, Square Attack | ROG | CT-Scans, MRI | Segmentation | Improves baseline methods up to 20% in terms of IoU |
| [85] | PGD, GAP | CheXNet, InceptionV3, Custom CNN | Dermoscopy, X-ray, Fundoscopy | Classification | Improves standard defense method (adversarial training) by up to 9% |
4.4. Benefits of Adversarially Robust Models
5. Implementation Aspects
5.1. Open-Source Libraries
5.2. Source Codes and Datasets
References
- Maliamanis, T.; Papakostas, G. Adversarial computer vision: A current snapshot. In Proceedings of the Twelfth International Conference on Machine Vision (ICMV 2019), Amsterdam, The Netherlands, 31 January 2020; p. 121.
- Papernot, N.; McDaniel, P.; Goodfellow, I. Transferability in Machine Learning: From Phenomena to Black-Box Attacks using Adversarial Samples. arXiv 2016, arXiv:1605.07277. Available online: http://arxiv.org/abs/1605.07277 (accessed on 4 June 2021).
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial Examples in the Physical World. arXiv 2017, arXiv:1607.02533. Available online: http://arxiv.org/abs/1607.02533 (accessed on 4 June 2021).
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing Properties of Neural Networks. arXiv 2014, arXiv:1312.6199. Available online: http://arxiv.org/abs/1312.6199 (accessed on 4 June 2021).
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2015, arXiv:1412.6572. Available online: http://arxiv.org/abs/1412.6572 (accessed on 4 June 2021).
- Xu, W.; Evans, D.; Qi, Y. Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks. In Proceedings of the 2018 Network and Distributed System Security Symposium, San Diego, CA, USA, 18–21 February 2018.
- Meng, D.; Chen, H. MagNet: A Two-Pronged Defense against Adversarial Examples. arXiv 2017, arXiv:1705.09064. Available online: http://arxiv.org/abs/1705.09064 (accessed on 4 June 2021).
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. arXiv 2019, arXiv:1706.06083. Available online: http://arxiv.org/abs/1706.06083 (accessed on 4 June 2021).
- Paschali, M.; Conjeti, S.; Navarro, F.; Navab, N. Generalizability vs. Robustness: Investigating Medical Imaging Networks Using Adversarial Examples. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2018; Frangi, A.F., Schnabel, J.A., Davatzikos, C., Alberola-López, C., Fichtinger, G., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11070, pp. 493–501.
- Chen, Y.-W.; Jain, L.C. (Eds.) Deep Learning in Healthcare: Paradigms and Applications; Springer International Publishing: Cham, Switzerland, 2020; Volume 171.
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.W.M.; van Ginneken, B.; Sánchez, C.I. A Survey on Deep Learning in Medical Image Analysis. Med. Image Anal. 2017, 42, 60–88.
- Finlayson, S.G.; Bowers, J.D.; Ito, J.; Zittrain, J.L.; Beam, A.L.; Kohane, I.S. Adversarial attacks on medical machine learning. Science 2019, 363, 1287–1289.
- Xu, H.; Ma, Y.; Liu, H.-C.; Deb, D.; Liu, H.; Tang, J.-L.; Jain, A.K. Adversarial Attacks and Defenses in Images, Graphs and Text: A Review. Int. J. Autom. Comput. 2020, 17, 151–178.
- Ren, K.; Zheng, T.; Qin, Z.; Liu, X. Adversarial Attacks and Defenses in Deep Learning. Engineering 2020, 6, 346–360.
- Carlini, N.; Wagner, D. Towards Evaluating the Robustness of Neural Networks. arXiv 2017, arXiv:1608.04644. Available online: http://arxiv.org/abs/1608.04644 (accessed on 4 June 2021).
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The Limitations of Deep Learning in Adversarial Settings. arXiv 2015, arXiv:1511.07528. Available online: http://arxiv.org/abs/1511.07528 (accessed on 4 June 2021).
- Moosavi-Dezfooli, S.-M.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal Adversarial Perturbations. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 86–94.
- Xie, C.; Wang, J.; Zhang, Z.; Zhou, Y.; Xie, L.; Yuille, A. Adversarial Examples for Semantic Segmentation and Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1378–1387.
- Tramèr, F.; Kurakin, A.; Papernot, N.; Goodfellow, I.; Boneh, D.; McDaniel, P. Ensemble Adversarial Training: Attacks and Defenses. arXiv 2020, arXiv:1705.07204. Available online: http://arxiv.org/abs/1705.07204 (accessed on 4 June 2021).
- Xie, C.; Wang, J.; Zhang, Z.; Ren, Z.; Yuille, A. Mitigating Adversarial Effects Through Randomization. arXiv 2018, arXiv:1711.01991. Available online: http://arxiv.org/abs/1711.01991 (accessed on 4 June 2021).
- Guo, Y.; Zhang, C.; Zhang, C.; Chen, Y. Sparse DNNs with Improved Adversarial Robustness. arXiv 2019, arXiv:1810.09619. Available online: http://arxiv.org/abs/1810.09619 (accessed on 4 June 2021).
- Wang, Y.; Jha, S.; Chaudhuri, K. Analyzing the Robustness of Nearest Neighbors to Adversarial Examples. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 5133–5142.
- Liu, X.; Li, Y.; Wu, C.; Hsieh, C.-J. Adv-BNN: Improved Adversarial Defense through Robust Bayesian Neural Network. arXiv 2019, arXiv:1810.01279. Available online: http://arxiv.org/abs/1810.01279 (accessed on 4 June 2021).
- Xiao, C.; Deng, R.; Li, B.; Yu, F.; Liu, M.; Song, D. Characterizing Adversarial Examples Based on Spatial Consistency Information for Semantic Segmentation. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11214, pp. 220–237.
- Ma, X.; Li, B.; Wang, Y.; Erfani, S.M.; Wijewickrema, S.; Schoenebeck, G.; Song, D.; Houle, M.E.; Bailey, J. Characterizing Adversarial Subspaces Using Local Intrinsic Dimensionality. arXiv 2018, arXiv:1801.02613. Available online: http://arxiv.org/abs/1801.02613 (accessed on 4 June 2021).
- Metzen, J.H.; Genewein, T.; Fischer, V.; Bischoff, B. On Detecting Adversarial Perturbations. arXiv 2017, arXiv:1702.04267. Available online: http://arxiv.org/abs/1702.04267 (accessed on 4 June 2021).
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826.
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. Available online: http://arxiv.org/abs/1704.04861 (accessed on 4 June 2021).
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495.
- Jegou, S.; Drozdzal, M.; Vazquez, D.; Romero, A.; Bengio, Y. The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1175–1183.
- Wetstein, S.C.; González-Gonzalo, C.; Bortsova, G.; Liefers, B.; Dubost, F.; Katramados, I.; Hogeweg, L.; van Ginneken, B.; Pluim, J.P.W.; de Bruijne, M.; et al. Adversarial Attack Vulnerability of Medical Image Analysis Systems: Unexplored Factors. arXiv 2020, arXiv:2006.06356. Available online: http://arxiv.org/abs/2006.06356 (accessed on 4 June 2021).
- Finlayson, S.G.; Chung, H.W.; Kohane, I.S.; Beam, A.L. Adversarial Attacks Against Medical Deep Learning Systems. arXiv 2019, arXiv:1804.05296. Available online: http://arxiv.org/abs/1804.05296 (accessed on 4 June 2021).
- Cheng, G.; Ji, H. Adversarial Perturbation on MRI Modalities in Brain Tumor Segmentation. IEEE Access 2020, 8, 206009–206015.
- Li, Y.; Zhang, H.; Bermudez, C.; Chen, Y.; Landman, B.A.; Vorobeychik, Y. Anatomical context protects deep learning from adversarial perturbations in medical imaging. Neurocomputing 2020, 379, 370–378.
- Huq, A.; Pervin, M.T. Analysis of Adversarial Attacks on Skin Cancer Recognition. In Proceedings of the 2020 International Conference on Data Science and Its Applications (ICoDSA), Bandung, Indonesia, 5–6 August 2020; pp. 1–4.
- Anand, D.; Tank, D.; Tibrewal, H.; Sethi, A. Self-Supervision vs. Transfer Learning: Robust Biomedical Image Analysis Against Adversarial Attacks. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 1159–1163.
- Paul, R.; Schabath, M.; Gillies, R.; Hall, L.; Goldgof, D. Mitigating Adversarial Attacks on Medical Image Understanding Systems. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 1517–1521.
- Risk Susceptibility of Brain Tumor Classification to Adversarial Attacks|SpringerLink. Available online: https://link.springer.com/chapter/10.1007/978-3-030-31964-9_17 (accessed on 4 June 2021).
- Shah, A.; Lynch, S.; Niemeijer, M.; Amelon, R.; Clarida, W.; Folk, J.; Russell, S.; Wu, X.; Abramoff, M.D. Susceptibility to misdiagnosis of adversarial images by deep learning based retinal image analysis algorithms. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 1454–1457.
- Kovalev, V.; Voynov, D. Influence of Control Parameters and the Size of Biomedical Image Datasets on the Success of Adversarial Attacks. In Pattern Recognition and Information Processing; Ablameyko, S.V., Krasnoproshin, V.V., Lukashevich, M.M., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 1055, pp. 301–311.
- Li, Y.; Zhu, Z.; Zhou, Y.; Xia, Y.; Shen, W.; Fishman, E.K.; Yuille, A.L. Volumetric Medical Image Segmentation: A 3D Deep Coarse-to-fine Framework and Its Adversarial Examples. arXiv 2019, arXiv:2010.16074. Available online: http://arxiv.org/abs/2010.16074 (accessed on 4 June 2021).
- Allyn, J.; Allou, N.; Vidal, C.; Renou, A.; Ferdynus, C. Adversarial attack on deep learning-based dermatoscopic image recognition systems: Risk of misdiagnosis due to undetectable image perturbations. Medicine 2020, 99, e23568.
- Hirano, H.; Minagi, A.; Takemoto, K. Universal adversarial attacks on deep neural networks for medical image classification. BMC Med. Imaging 2021, 21, 9.
- Hirano, H.; Koga, K.; Takemoto, K. Vulnerability of deep neural networks for detecting COVID-19 cases from chest X-ray images to universal adversarial attacks. PLoS ONE 2020, 15, e0243963.
- Ma, X.; Niu, Y.; Gu, L.; Wang, Y.; Zhao, Y.; Bailey, J.; Lu, F. Understanding Adversarial Attacks on Deep Learning Based Medical Image Analysis Systems. arXiv 2020, arXiv:1907.10456. Available online: http://arxiv.org/abs/1907.10456 (accessed on 4 June 2021).
- Pal, B.; Gupta, D.; Rashed-Al-Mahfuz, M.; Alyami, S.A.; Moni, M.A. Vulnerability in Deep Transfer Learning Models to Adversarial Fast Gradient Sign Attack for COVID-19 Prediction from Chest Radiography Images. Appl. Sci. 2021, 11, 4233.
- Bortsova, G.; Dubost, F.; Hogeweg, L.; Katramados, I.; de Bruijne, M. Adversarial Heart Attack: Neural Networks Fooled to Segment Heart Symbols in Chest X-Ray Images. arXiv 2021, arXiv:2104.00139. Available online: http://arxiv.org/abs/2104.00139 (accessed on 10 August 2021).
- On the Assessment of Robustness of Telemedicine Applications against Adversarial Machine Learning Attacks | SpringerLink. Available online: https://link.springer.com/chapter/10.1007/978-3-030-79457-6_44?error=cookies_not_supported&code=3acd5697-d1ba-4ca5-8077-3d1b5d9bae9a (accessed on 10 August 2021).
- Byra, M.; Styczynski, G.; Szmigielski, C.; Kalinowski, P.; Michalowski, L.; Paluszkiewicz, R.; Ziarkiewicz-Wroblewska, B.; Zieniewicz, K.; Nowicki, A. Adversarial Attacks on Deep Learning Models for Fatty Liver Disease Classification by Modification of Ultrasound Image Reconstruction Method. arXiv 2020, arXiv:2009.03364. Available online: http://arxiv.org/abs/2009.03364 (accessed on 4 June 2021).
- Chen, P.-Y.; Zhang, H.; Sharma, Y.; Yi, J.; Hsieh, C.-J. ZOO: Zeroth Order Optimization Based Black-box Attacks to Deep Neural Networks without Training Substitute Models. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 15–26.
- Ozbulak, U.; Van Messem, A.; De Neve, W. Impact of Adversarial Examples on Deep Learning Models for Biomedical Image Segmentation. arXiv 2019, arXiv:1907.13124. Available online: http://arxiv.org/abs/1907.13124 (accessed on 4 June 2021).
- Pena-Betancor, C.; Gonzalez-Hernandez, M.; Fumero-Batista, F.; Sigut, J.; Medina-Mesa, E.; Alayon, S.; Gonzalez de la Rosa, M. Estimation of the Relative Amount of Hemoglobin in the Cup and Neuroretinal Rim Using Stereoscopic Color Fundus Images. Investig. Ophthalmol. Vis. Sci. 2015, 56, 1562–1568.
- Codella, N.C.F.; Gutman, D.; Celebi, M.E.; Helba, B.; Marchetti, M.A.; Dusza, S.W.; Kalloo, A.; Liopyris, K.; Mishra, N.; Kittler, H.; et al. Skin Lesion Analysis Toward Melanoma Detection: A Challenge at the 2017 International Symposium on Biomedical Imaging (ISBI), Hosted by the International Skin Imaging Collaboration (ISIC). arXiv 2018, arXiv:1710.05006. Available online: http://arxiv.org/abs/1710.05006 (accessed on 4 June 2021).
- Kugler, D. Physical Attacks in Dermoscopy: An Evaluation of Robustness for clinical Deep-Learning. J. Mach. Learn. Biomed. Imaging 2021, 7, 1–32.
- Chen, L.; Bentley, P.; Mori, K.; Misawa, K.; Fujiwara, M.; Rueckert, D. Intelligent Image Synthesis to Attack a Segmentation CNN Using Adversarial Learning. arXiv 2019, arXiv:1909.11167. Available online: http://arxiv.org/abs/1909.11167 (accessed on 4 June 2021).
- Tian, B.; Guo, Q.; Juefei-Xu, F.; Chan, W.L.; Cheng, Y.; Li, X.; Xie, X.; Qin, S. Bias Field Poses a Threat to DNN-based X-Ray Recognition. arXiv 2021, arXiv:2009.09247. Available online: http://arxiv.org/abs/2009.09247 (accessed on 4 June 2021).
- Yao, Q.; He, Z.; Lin, Y.; Ma, K.; Zheng, Y.; Zhou, S.K. A Hierarchical Feature Constraint to Camouflage Medical Adversarial Attacks. arXiv 2021, arXiv:2012.09501. Available online: http://arxiv.org/abs/2012.09501 (accessed on 4 June 2021).
- Shao, M.; Zhang, G.; Zuo, W.; Meng, D. Target attack on biomedical image segmentation model based on multi-scale gradients. Inf. Sci. 2021, 554, 33–46.
- Qi, G.; Gong, L.; Song, Y.; Ma, K.; Zheng, Y. Stabilized Medical Image Attacks. arXiv 2021, arXiv:2103.05232. Available online: http://arxiv.org/abs/2103.05232 (accessed on 10 August 2021).
- Wu, D.; Liu, S.; Ban, J. Classification of Diabetic Retinopathy Using Adversarial Training. IOP Conf. Ser. Mater. Sci. Eng. 2020, 806, 012050.
- He, X.; Yang, S.; Li, G.; Li, H.; Chang, H.; Yu, Y. Non-Local Context Encoder: Robust Biomedical Image Segmentation against Adversarial Attacks. AAAI 2019, 33, 8417–8424.
- Novikov, A.A.; Lenis, D.; Major, D.; Hladůvka, J.; Wimmer, M.; Bühler, K. Fully Convolutional Architectures for Multi-Class Segmentation in Chest Radiographs. arXiv 2018, arXiv:1701.08816. Available online: http://arxiv.org/abs/1701.08816 (accessed on 4 June 2021).
- Sarker, M.M.K.; Rashwan, H.A.; Akram, F.; Banu, S.F.; Saleh, A.; Singh, V.K.; Chowdhury, F.U.H.; Abdulwahab, S.; Romani, S.; Radeva, P.; et al. SLSDeep: Skin Lesion Segmentation Based on Dilated Residual and Pyramid Pooling Networks. arXiv 2018, arXiv:1805.10241. Available online: http://arxiv.org/abs/1805.10241 (accessed on 4 June 2021).
- Hwang, S.; Park, S. Accurate Lung Segmentation via Network-Wise Training of Convolutional Networks. arXiv 2017, arXiv:1708.00710. Available online: http://arxiv.org/abs/1708.00710 (accessed on 4 June 2021).
- Yuan, Y. Automatic skin lesion segmentation with fully convolutional-deconvolutional networks. IEEE J. Biomed. Health Inform. 2019, 23, 519–526.
- Taghanaki, S.A.; Das, A.; Hamarneh, G. Vulnerability Analysis of Chest X-Ray Image Classification Against Adversarial Attacks. arXiv 2018, arXiv:1807.02905. Available online: http://arxiv.org/abs/1807.02905 (accessed on 4 June 2021).
- Feinman, R.; Curtin, R.R.; Shintre, S.; Gardner, A.B. Detecting Adversarial Samples from Artifacts. arXiv 2017, arXiv:1703.00410. Available online: http://arxiv.org/abs/1703.00410 (accessed on 4 June 2021).
- Ren, X.; Zhang, L.; Wei, D.; Shen, D.; Wang, Q. Brain MR Image Segmentation in Small Dataset with Adversarial Defense and Task Reorganization. In Machine Learning in Medical Imaging; Suk, H.-I., Liu, M., Yan, P., Lian, C., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 11861, pp. 1–8.
- Liu, S.; Setio, A.A.A.; Ghesu, F.C.; Gibson, E.; Grbic, S.; Georgescu, B.; Comaniciu, D. No Surprises: Training Robust Lung Nodule Detection for Low-Dose CT Scans by Augmenting with Adversarial Attacks. arXiv 2020, arXiv:2003.03824. Available online: http://arxiv.org/abs/2003.03824 (accessed on 4 June 2021).
- Vatian, A.; Gusarova, N.; Dobrenko, N.; Dudorov, S.; Nigmatullin, N.; Shalyto, A.; Lobantsev, A. Impact of Adversarial Examples on the Efficiency of Interpretation and Use of Information from High-Tech Medical Images. In Proceedings of the 2019 24th Conference of Open Innovations Association (FRUCT), Moscow, Russia, 8–12 April 2019; pp. 472–478.
- Chen, C.; Qin, C.; Qiu, H.; Ouyang, C.; Wang, S.; Chen, L.; Tarroni, G.; Bai, W.; Rueckert, D. Realistic Adversarial Data Augmentation for MR Image Segmentation. arXiv 2020, arXiv:2006.13322. Available online: http://arxiv.org/abs/2006.13322 (accessed on 4 June 2021).
- Cheng, K.; Caliva, F.; Shah, R.; Han, M.; Majumdar, S.; Pedoia, V. Addressing the False Negative Problem of Deep Learning MRI Reconstruction Models by Adversarial Attacks and Robust Training. Proc. Mach. Learn. Res. 2020, 121, 121–135.
- Calivá, F.; Cheng, K.; Shah, R.; Pedoia, V. Adversarial Robust Training of Deep Learning MRI Reconstruction Models. arXiv 2021, arXiv:2011.00070. Available online: http://arxiv.org/abs/2011.00070 (accessed on 4 June 2021).
- Park, H.; Bayat, A.; Sabokrou, M.; Kirschke, J.S.; Menze, B.H. Robustification of Segmentation Models Against Adversarial Perturbations in Medical Imaging. arXiv 2020, arXiv:2009.11090. Available online: http://arxiv.org/abs/2009.11090 (accessed on 4 June 2021).
- Taghanaki, S.A.; Abhishek, K.; Azizi, S.; Hamarneh, G. A Kernelized Manifold Mapping to Diminish the Effect of Adversarial Perturbations. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 11332–11341.
- Huang, Y.; Würfl, T.; Breininger, K.; Liu, L.; Lauritsch, G.; Maier, A. Some Investigations on Robustness of Deep Learning in Limited Angle Tomography. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2018; Frangi, A.F., Schnabel, J.A., Davatzikos, C., Alberola-López, C., Fichtinger, G., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11070, pp. 145–153.
- Xue, F.-F.; Peng, J.; Wang, R.; Zhang, Q.; Zheng, W.-S. Improving Robustness of Medical Image Diagnosis with Denoising Convolutional Neural Networks. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2019; Shen, D., Liu, T., Peters, T.M., Staib, L.H., Essert, C., Zhou, S., Yap, P.-T., Khan, A., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 11769, pp. 846–854.
- Tripathi, A.M.; Mishra, A. Fuzzy Unique Image Transformation: Defense Against Adversarial Attacks on Deep COVID-19 Models. arXiv 2020, arXiv:2009.04004. Available online: http://arxiv.org/abs/2009.04004 (accessed on 4 June 2021).
- Defending Deep Learning-Based Biomedical Image Segmentation from Adversarial Attacks: A Low-Cost Frequency Refinement Approach|SpringerLink. Available online: https://link.springer.com/chapter/10.1007/978-3-030-59719-1_34 (accessed on 4 June 2021).
- Li, X.; Zhu, D. Robust Detection of Adversarial Attacks on Medical Images. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 1154–1158.
- Li, X.; Pan, D.; Zhu, D. Defending against Adversarial Attacks on Medical Imaging AI System, Classification or Detection? arXiv 2020, arXiv:2006.13555. Available online: http://arxiv.org/abs/2006.13555 (accessed on 4 June 2021).
- Pervin, M.T.; Tao, L.; Huq, A.; He, Z.; Huo, L. Adversarial Attack Driven Data Augmentation for Accurate and Robust Medical Image Segmentation. arXiv 2021, arXiv:2105.12106. Available online: http://arxiv.org/abs/2105.12106 (accessed on 10 August 2021).
- Uwimana1, A.; Senanayake, R. Out of Distribution Detection and Adversarial Attacks on Deep Neural Networks for Robust Medical Image Analysis. arXiv 2021, arXiv:2107.04882. Available online: http://arxiv.org/abs/2107.04882 (accessed on 10 August 2021).
- Daza, L.; Pérez, J.C.; Arbeláez, P. Towards Robust General Medical Image Segmentation. arXiv 2021, arXiv:2107.04263. Available online: http://arxiv.org/abs/2107.04263 (accessed on 10 August 2021).
- Xu, M.; Zhang, T.; Li, Z.; Liu, M.; Zhang, D. Towards evaluating the robustness of deep diagnostic models by adversarial attack. Med. Image Anal. 2021, 69, 101977.
- Lee, S.; Lee, H.; Yoon, S. Adversarial Vertex Mixup: Toward Better Adversarially Robust Generalization. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 269–278.
- Liu, X.; Xiao, T.; Si, S.; Cao, Q.; Kumar, S.; Hsieh, C.-J. How Does Noise Help Robustness? Explanation and Exploration under the Neural SDE Framework. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 279–287.
- Qin, Y.; Wang, X.; Beutel, A.; Chi, E.H. Improving Uncertainty Estimates through the Relationship with Adversarial Robustness. arXiv 2020, arXiv:2006.16375. Available online: http://arxiv.org/abs/2006.16375 (accessed on 10 August 2021).
- Yi, M.; Hou, L.; Sun, J.; Shang, L.; Jiang, X.; Liu, Q.; Ma, Z.-M. Improved OOD Generalization via Adversarial Training and Pre-training. arXiv 2021, arXiv:2105.11144. Available online: http://arxiv.org/abs/2105.11144 (accessed on 10 August 2021).
- Papernot, N.; Faghri, F.; Carlini, N.; Goodfellow, I.; Feinman, R.; Kurakin, A.; Xie, C.; Sharma, Y.; Brown, T.; Roy, A.; et al. Technical Report on the CleverHans v2.1.0 Adversarial Examples Library. arXiv 2018, arXiv:1610.00768. Available online: http://arxiv.org/abs/1610.00768 (accessed on 4 June 2021).
- Rauber, J.; Zimmermann, R.; Bethge, M.; Brendel, W. Foolbox Native: Fast adversarial attacks to benchmark the robustness of machine learning models in PyTorch, TensorFlow, and JAX. JOSS 2020, 5, 2607.
- Nicolae, M.-I.; Sinn, M.; Tran, M.N.; Buesser, B.; Rawat, A.; Wistuba, M.; Zantedeschi, V.; Baracaldo, N.; Chen, B.; Ludwig, H.; et al. Adversarial Robustness Toolbox v1.0.0. arXiv 2019, arXiv:1807.01069. Available online: http://arxiv.org/abs/1807.01069 (accessed on 4 June 2021).
- Goodman, D.; Xin, H.; Yang, W.; Yuesheng, W.; Junfeng, X.; Huan, Z. Advbox: A Toolbox to Generate Adversarial Examples that Fool Neural Networks. arXiv 2020, arXiv:2001.05574. Available online: http://arxiv.org/abs/2001.05574 (accessed on 4 June 2021).
- Ding, G.W.; Wang, L.; Jin, X. advertorch v0.1: An Adversarial Robustness Toolbox based on PyTorch. arXiv 2019, arXiv:1902.07623. Available online: http://arxiv.org/abs/1902.07623 (accessed on 4 June 2021).
- Ling, X.; Ji, S.; Zou, J.; Wang, J.; Wu, C.; Li, B.; Wang, T. DEEPSEC: A Uniform Platform for Security Analysis of Deep Learning Model. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 673–690.

