Author(s)
1, *R. Lahoz-Beltra, 1P. Lopez Gonzalez-Nieto, 5M. Gomez Flechoso, 2M.E. Arribas Mocoroa, 3A. Muñoz Martin, 2M.L. Garcia Lorenzo, 4G. Cabrera Gomez, 3J.A. Alvarez Gomez, 2,3A. Caso Fraile, 2,3J. M. Orosco Dagan, 2,3R. Merinero Palomares.
(1) Department of Biodiversity, Ecology and Evolution (Biomathematics), (2) Department of Mineralogy and Petrology, (3) Department of Geodynamics, Stratigraphy and Paleontology, (4) Departmental Section of Analysis and Applied Mathematics, (5) Department of Earth Physics and Astrophysics. Complutense University of Madrid, 28040 Madrid (Spain).
(*) Author for correspondence: lahozraf@bio.ucm.es
Descriptive statistics is a set of statistical techniques that allow a first impression to be obtained of the information contained in the data. Its purpose is to synthesize or summarize the information of the sample (set of data or observations), organize the data in tables and represent them graphically. In this way the researcher, from the data obtained in a first pilot experiment, has statistical tools that will allow him/her the formulation of hypotheses or conjectures about the phenomenon under study.
Descriptive statistics can be applied to the analysis of a random variable X or two random variables X and Y, referring to both cases as univariate descriptive statistics and bivariate descriptive statistics respectively.
- Descriptive statistics
- Centralization, dispersion and shape measures
- Exploratory data analysis
- Random variable
- Sample
1. Statistical terms
First we will organize the experimental data in a data table. This is a 2x2 matrix with the following format: the elements or subjects that are the focus of the study are located in rows, known as the units of analysis (UA1, UA2, ., UAi), whereas the values of the random variables are located in columns (X1, X2, ., Xj). Therefore, a column vector (j) is a random sample, and a row vector (i) is an observation vector.

A random variable is an observable property. If it is quantitative then it can be continuous, that is, it is a measurable property or discrete when the property is countable. Random variables are classified according to the following criterion:
Quantitative: Discrete: 0, 1, 2,.; Continuous: 0.26, 1.81,. etc.
Qualitative: Ordinal or range (order): e.g. colors ordered by wavelength; Nominal (not order) : for example, colors blue, green, red etc.
On some occasions the researcher will use attributes (frequencies) are e.g. percentage of people in blood group A; or percentage of silicates in a given location. We will refer to the values of the variable X as observations, which we will represent as a sequence {x1, x2, . xn}. In order to simplify the notation in this sequence, we refer with x1 to the value of the variable in the first unit of analysis, x2 to the value in the second unit of analysis, etc. The value of n is the sample size, i.e. the number of elements, objects or units of analysis in which the value of the random variable X has been obtained experimentally.
Descriptive statistics summarize the information contained in a sample into three classes of numerical values which are referred to as centralization, dispersion and shape measures.
2. Univariate Descriptive Statistical Methods
In experimental work there are situations where a descriptive statistical analysis of a random variable X is required. The result of this analysis is a series of measures, known as centralization, dispersion and shape measures:
2.1. Centralization measures
Their purpose is to inform about the trend of data.
Sample size (n): This is not in itself a measure of centralization, although it is usually included in this group. It is the number of individuals, elements or objects that make up the sample. A large sample is one with more than 30 individuals (n>30), and a small sample is one with less than 30 (n<30).
Arithmetic mean (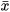 ).- This is the average value of the observations. It is one of the most important measures of centralization:
).- This is the average value of the observations. It is one of the most important measures of centralization:
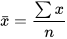
Geometric mean (mg).- It is a mean value that is used with percentages, rates etc:
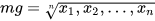
Harmonic mean (ma).- It is a very robust mean value to extreme values with utility in the calculation of the average of speeds, times, performances etc:
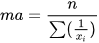
Quadratic mean (mc).- It is a mean value that is used in the calculation of the average of alternate currents, waves, gases, etc. removing the sign effects when some observations take negative values. It is also known as RMS or mean square value:
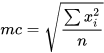
Median (Me).- If we order the values of the observations from lowest to highest the median is that observation that leaves 50% of the observations above and the other 50% below. It is known by other names such as 'quartile two', 'percentile 50'.
Mode (Mo).- It is the most frequent value in the observations.
Quantiles.- This is the application of what is known as elementary range theory, introduced by the statistician Kendall in 1940. If we order the values of the observations from lowest (MIN) to highest (MAX), we will have the following values or quantiles.
If we then divide the sample into four equal parts then Q1 (first quartile) will be the value that leaves 25% and 75% of the observations on the left and right, Q2 (second quartile) is the median (Me), and Q3 (third quartile) is the value that leaves 75% and 25% of the observations on the left and right. Now, if we were to divide the sample into 100 equal parts then we would have percentiles. For example, P25, P50 and P75 correspond to Q1, Q2 and Q3 respectively.
2.2. Dispersion measures
These measures inform us of the variability or dispersion of the data, and therefore of the degree of representativity of the centralization measures. The lower the variability, the more representative the centralization measure obtained will be.
Range (r).- This is defined as the difference between the maximum and minimum values of the observations, i.e. Max(x)-min(x). It is used in quality control experiments.
Interquartile range (IQR).- It is a measure of variability defined from the quartile theory, being equal to Q3-Q1.
Mean Deviation (Dm).- A good indicator of dispersion defined as an average of the differences in absolute value of each observation with respect to the arithmetic mean:
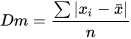
Variance (s2).- It is the most important measure of dispersion in the experimental work, also known as mean square error. It is defined as an average of the squared differences of each observation with respect to the arithmetic mean:
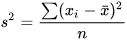
Do not be mistaken with quasi-variance, an unbiased estimator's version of the variance (its mathematical expectation is the population variance, E[ ] =μ):
] =μ):
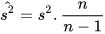
Standard deviation (s).- Is the square root of the variance (s2). In this way units are expressed linearly and not squared as with the variance.
Standard error: Since the sample mean is a random variable, as its value fluctuates from sample to sample, the standard error is the standard deviation of the arithmetic mean. It is used in statistical inference, although sometimes its value is included in descriptive statistics.
Pearson's coefficient of variation (CV): It is defined as the ratio of the standard deviation to the sample mean. It is usually multiplied by 100 allowing a comparison of the variability between any two variables:
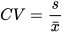
2.3. Shape measurements
Its purpose is to measure the shape of the frequency distribution of the data. The shape of the distribution is quantified with two measurements:
Asymmetry (g1 or 'skewness'): If the distribution is symmetric then g1 will be close to zero. Otherwise, when g1>0 then a considerable number of data are concentrated in the high values of the distribution, being the distribution skewed to the right. If g1<0 then the distribution will be biased towards the low values, i.e. towards the left.

Left-biased (g1<0), unbiased (g1=0) and right-biased (g1>0) distributions
Kurtosis (g2 or 'kurtosis'): This is a measure of the sharpness of the data distribution. If g2 is zero then the distribution is mesocurtic, if g2>0 then it is called leptocurtic, and if g2<0 then the distribution is termed platicurtic. In a leptocurtic distribution the variance s2 is very low, while in a platicurtic distribution the variance s2 is very high. Therefore, the variability has a mean value only when the distribution is mesocurtic.

Platicurtic (g2<0), mesocurtic (g2=0) and leptocurtic (g2>0) distributions
3. Exploratory data analysis
In addition to the measures of centralization, dispersion and shape, the descriptive statistics use graphical methods. The most commonly used graphs in the experimental work are:
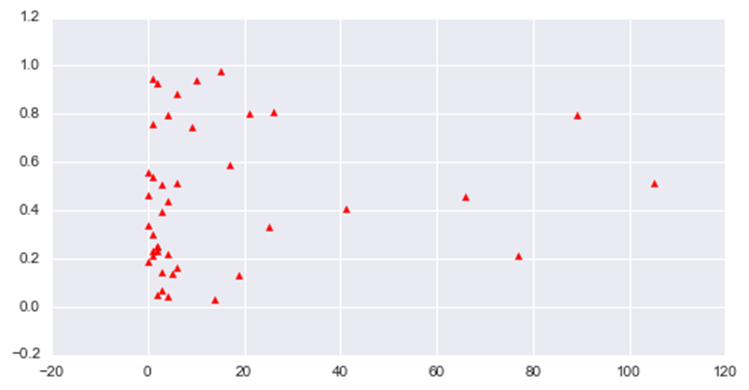
Scatterplot.- Representation of the observations in which the X or x-axis represents the values of the data or observations, and the Y or y-axis is a dummy value obtained by simulating the "shaking" or "jitter" of the X axis, thus allowing a more comfortable visualization of the observations.
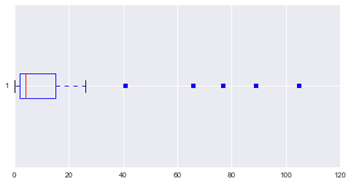
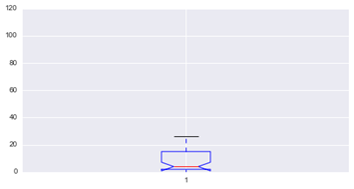
Box and whisker plot.- It is a graph currently widely used in experimental work. It was introduced by the statistician Tukey in 1977 and became popular with the widespread use of computers. It allows for analysis of (a) distribution symmetry, (b) identification of outliers and (c) comparison of batches of data.

Histogram.- One of the most popular graphs in descriptive statistics. It represents the distribution of frequencies in quantitative variables that are continuous. Not to be confused with bar charts used with discrete quantitative variables.
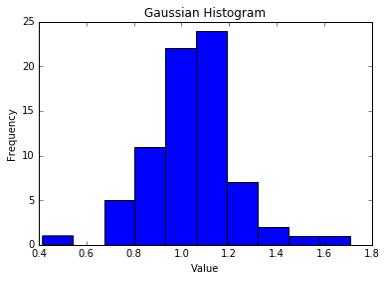
In a histogram the bars are rectangles representing intervals and have a height proportional to the frequency of each interval, once the data are grouped and organized in a table of classes and frequencies.
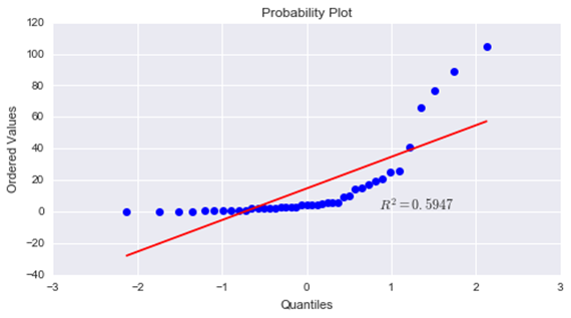
Normal Probability Chart.- Allows the evaluation of the normality of the variable under study by comparing the data with the normal distribution. That is, this graph evaluates whether or not the data come from a normal or Gaussian distribution in an empirical way, by fitting the points representing the experimental data to a straight line that would represent the normal distribution.
4. Python script description
Lines 33-60 calculate the measures of centralization, dispersion and shape. In addition, a test for normality of the data is included. First the script obtains the sample size, minimum, maximum and range values of the variable (lines 36-39). Next, the arithmetic mean (line 40), geometric mean (line 41), harmonic mean (line 42) and quadratic mean (line 43) are calculated. Mode is calculated in line 44, and quartiles Q1, Q2 and Q3 in lines 46-48. Other quartiles can be obtained by specifying the order np.percentile(data,_). The dispersion measures are obtained below. Variance, standard deviation, standard error of the mean, interquartile range and Pearson's deviation coefficient are calculated on lines 49-53. Finally, shape measurements are obtained, both asymmetry (line 55) and kurtosis (line 57). The script performs the D'Agostino and Pearson normality tests (line 59).
The most common graphic methods are performed with the code section displayed in the script between lines 61-93. Lines 63-77 show different versions of the order that allows to represent a box and whiskers plot with the experimental data. Line 65 shows the basic order for a box-and-whiskers plot. If a notch in the box is desired to plot a confidence interval for the median (Me) then the order is as shown on line 68. On line 74 the box-and-whisker plot is shown horizontally. Outliers are detected and plotted using the order on line 71. Finally, line 77 shows an order to obtain a box-and-whisker plot with longer whiskers.
A histogram is represented between lines 79-83. The number of classes and therefore of bars in the histogram can be set or an appropriate value estimated with the Sturges expression (line 82). Other characteristics of the histogram are specified with the order plt.hist(data,numBins,_,.,_). The code section below (lines 85-88) represents a scatter plot simulating with y_data the jitter of data and allowing the user to define some graphic characteristics in plt.scatter(data,y_data,_,.,_). Finally, between lines 90-93 a normal probability graph is displayed.
1 |
############################################################ # # # Virtual Laboratory of Statistics in Python # # # # Univariate descriptive statistics (01.01.2020) # # # # Complutense University of Madrid, Spain # # # # THIS SCRIPT IS PROVIDED BY THE AUTHORS "AS IS" AND # # CAN BE USED BY ANYONE FOR THE PURPOSES OF EDUCATION # # AND RESEARCH. # # # ############################################################ import math import numpy as np # importing numpy import scipy.stats as s # importing scipy.stats import statistics as ss # importing statistics # Embedded graphics import matplotlib.pyplot as plt # importing matplotlib import seaborn as sns # importing seaborn import pylab # Aesthetic parameters of seaborn sns.set_palette("deep", desat=.6) |