Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Optical coherence tomography (OCT) is a noninvasive imaging technique that provides high-resolution cross-sectional retina images, enabling ophthalmologists to gather crucial information for diagnosing various retinal diseases. The images acquired from the patients in raw format might be associated with poor contrast, noise, low light, and other artefacts. Several image enhancement techniques are needed to extract useful information. Several approaches can be used to enhance the quality of the OCT image, such as denoising the images to classify diseases through pathologies segmentation.
- OCT
- fundus
- machine learning
- deep learning
1. Denoising OCT Images
Speckle noise is one of the most common noises generated in OCT imaging. Although imaging technology and equipment are continuously updated, speckle noise has not yet been fully solved. It degrades the performance of the automatic OCT image analysis [24]. Many hardware-based methods, which depend on specially designed acquisition systems, have been proposed for speckle noise suppression during imaging. Iftimia et al. [25] suggested an angular compounding by path length encoding (ACPE) technique that performs B-scan faster to eliminate speckle noise in OCT images. Kennedy et al. [26] presented a speckle reduction technique for OCT based on strain compounding. Based on angular compounding, Cheng et al. [27] proposed a dual-beam angular compounding method to reduce speckle noise and improve the SNR of OCT images. However, all these techniques can be applied to commercial OCT devices, adding an economic burden and increasing scan costs. Many algorithms [28,29,30] have been proposed to obtain a high signal-to-noise ratio (SNR) and high-resolution B-scan images from low-profile retinal OCT images. Bin Qui et al. [31] proposed a semi-supervised learning approach named N2NSR-OCT to generate denoised and super-resolved OCT images simultaneously using up- and down-sampling networks (U-Net (Semi) and DBPN (Semi). Meng-wang et al. [32] used a semi-supervised model to denoise the oct image using a capsule conditional generative adversarial network (Caps-cGAN) with few parameters. Nilesh A. Kande et al. [33] developed a deep generative model, called SiameseGAN, for denoising images with a low signal-to-noise ratio (LSNR) equipped with a Siamese twin network. However, these approaches achieved high efficiency because they were tested over synthesised noisy images created by the generative adversarial network.
Another approach to denoise the OCT images was proposed in [34], which captures repeated B-scans from a unique position. Image registration and averaging are performed to denoise the images. Huazong Liu et al. [35] used dual-tree complex wavelet transform for denoising the OCT images. In this approach, the image is decomposed into wavelet domain using dual-tree complex wavelet transform, and then the signal and noise are separated on the basis of Bayesian posterior probability. An example of OCT image denoising via super-resolution reconstruction is given in Figure 12 [36]. They used a multi-frame fusion mechanism that merges multiple scans for the same scene and utilises sub-pixel movements to recover missing signals in one pixel, significantly improving the image quality.
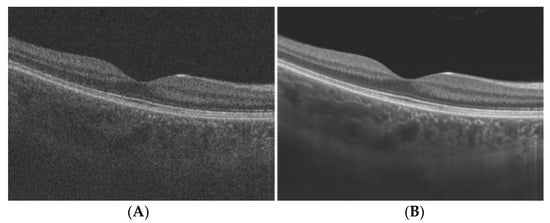
Figure 12. Speckle Noise reduction via super-resolution reconstruction: (A) noisy image; (B) denoised image.
Usually, all OCT image analysis methods proposed in the literature consist of a pre-processing step before performing any main processing steps. Table 2 shows a relatively complete classification of denoising algorithms employed in OCT segmentation. This table shows median and nonlinear anisotropic filters are the most popular methods in OCT image denoising. The fundamental problem associated with most denoising algorithms is their intrinsic consequence in decreasing the image resolution.
Table 2. Pre-processing algorithms used for OCT segmentation.
| Pre-Processing Methods | Researchers | Key Point | Evaluation Parameters |
|---|---|---|---|
| Deep learning (Unet and SRResNet and AC-SRResNet) | Y. Huang et al. [37] | This is the modification of the existing combination of U-Net and Super-Resolution Residual network with the addition of asymmetric convolution. The evaluation parameters used in this paper were signal-to-noise ratio, contrast to noise ratio, and edge preservation index. | SNR (dB) U-Net: 19.36 SRResNet: 20.11 AC-SRResNet: 22.15 |
| SiameseGAN | K. Nilesh et al. [33] | This is the combination of Siamese network module and a generative adversarial network. This model helps generate denoised images closer to the ground-truth image. | Mean PSNR: 28.25 dB |
| Semi-Supervised (N2NSR-OCT) | Q. Bin et al. [31] | This paper utilises up- and down-sampling networks, consisting of modified U-net and DPBN, to obtain a super-resolution image. | PSNR: 20.7491 dB RMSE: 0.0956 dB MS: SSIM 0.8205 |
| Semi-Supervised Capsule cGAN | M. Wang et al. [32] | This paper addresses the issue of speckle noise with a semi-supervised learning-based algorithm. A capsule cognitive generative adversarial network is used to construct the learning system, and the structural information loss is regained by using a semi-supervised loss function. | SNR: 59.01 dB |
| None | Yazdanpanah A. [38], Abramoff M.D. [39], Yang Q. [40] S. Bekalo et al. [41] | These researchers did not use any pre-processing algorithm for the oct image analysis. | DSC: 0.85 Correlation C/D: 0.93 |
| 2D linear smoothing | Huang Y. et al. [42] | This paper uses 3 × 3 pixel boxcar averaging filter to reduce speckle noise. | Avg. mean: 0.51 SD: 0.49 |
| Mean filter | J. Xu et al. [14] | In this paper, the author investigated the possibility of variable-size super pixel analysis for early detection of glaucoma. The ncut algorithm is used to map variable-size superpixels on a 2D feature map by grouping similar neighbouring pixels. | AUC: 0.855 |
| Wavelet shrinkage | Quellec G. et al. [43] | This paper describes an automated method for detection of the footprint of symptomatic exudate-associated derangements (SEADs) in SD-OCT scans from AMD patients. An adaptive wavelet transformation is used to extract a 3D textural feature. | AUC: 0.961 |
| Adaptive vector-valued kernel function | Mishra A. et al. [44] | This paper proposes a two-step kernel-based optimisation scheme to identify the location of layers and then refine them to obtain their segmentation. | NA |
| Two 1D filters: (1) median filtering along the A-scans; (2) Gaussian kernel in the longitudinal direction | Baroni M. et al. [45] | The layer identification is made by smoothing the OCT image with a median filter on the A-scan and a Gaussian field on the B-scan image. | Correlation: 5.13 Entropy: 25.65 |
| SVM approach | Fuller A.R. et al. [46] | This paper uses the SVM approach by considering a voxel’s mean value and variance with various resolution settings to handle the noise and decrease the classification error. | SD: 6.043 |
| Low-pass filtering | Hee M.R. et al. [5] | The peak position of the OCT image was filtered out using a low-pass filter to create similarity in spatial frequency distribution in the axial position. | NA |
The popularity of methods, like nonlinear anisotropic filters and wavelet diffusion, can be attributed to their ability to preserve edge information. It is also essential to mention that many recently developed algorithms that utilise graph-based algorithms are independent of noise and do not use any denoising algorithm.
2. Segmentation of Subretinal Layers of OCT Images
Segmentation is the next step in image processing after image denoising. This procedure gives detailed information about the OCT image ranging from pathologies to the measurement of subretinal layer thickness. While numerous methods [37,40,43,46] for retinal layer segmentation have been proposed in the literature for human OCT images, Sandra Morales et al. [47] used local intensity profiles and fully convolution neural networks to segment rodent OCT images. Rodent OCT images have no macula or fovea, and their lenses are relatively larger. For a single patient, this consists of 80% rodent OCT from a single scan. This approach successfully segmented all the layers of OCT images for healthy patients; however, it could only detect five layers in a diseased image. Yazdanpanah et al. [38] proposed a semi-automated algorithm based on the Chan–Vese active contours without edges to address six-retinal-layer boundary segmentation. They applied their algorithm to 80 retinal OCT images of seven rats and achieved an average Dice similarity coefficient of 0.84 over all segmented retinal layers. Mishra et al. [44] used a two-step kernel-based optimisation to segment retinal layers on a set of OCT images from healthy and diseased rodent retinas. Examples of efficient segmentation and false segmentation of OCT layers are given in Figure 13 and Figure 14. These images were captured with a Heidelberg OCT device at Nepal Eye Hospital.
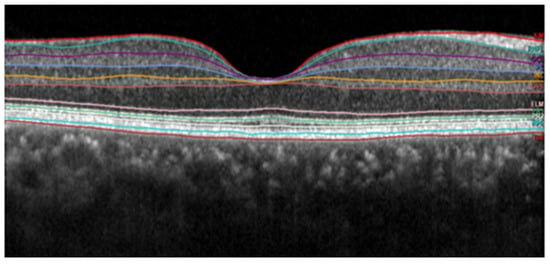
Figure 13. Subretinal layer segmentation of macular OCT.
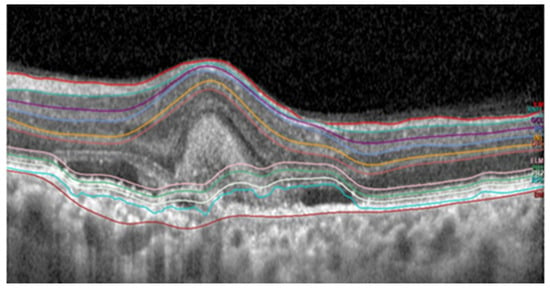
Figure 14. False segmentation of subretinal layers.
3. Detection of Various Pathologies in OCT Images
The detection of various pathologies is the main OCT image analysis objective. A semi-automated 2D method based on active contours was used as the basis for the initial work on fluid segmentation in OCT [48]. In this approach, to segment the IRF and SRF, users need to point out each lesion to get detected by active contour. Later, in [49], a comparable level set method with a quick split Bregman solver was employed to automatically create all candidate fluid areas, which were manually eliminated or selected. These methods are challenging, and few practitioners use them. A multiscale convolutional neural network (CNN) was first proposed for patch-based voxel classification in [50]. It could differentiate between IRF and SRF fluid in both supervised and weakly supervised settings. Although it is the most important aspect in treating eye disease, automated fluid presence detection has received significantly less attention. Table 3 provides a summary of the presented fluid segmentation algorithms, comparing them in terms of many characteristics. An example of fluid segmentation is shown in Figure 15. In this figure, intraretinal fluid (IRF) is represented in red, subretinal fluid (SRF) is depicted in green, and pigment epithelial detachment (PED) is shown in blue.
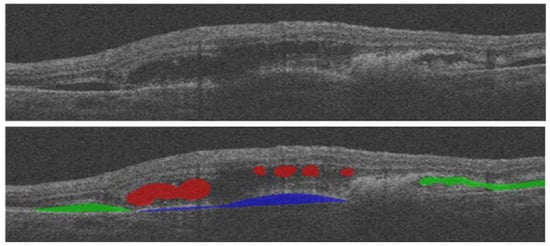
Figure 15. Various types of fluid detection shown in OCT.
Table 3. Overview of related work in fluid segmentation.
| Reference | Fluid Type | Disease | Year | Method | Evaluation Parameter |
|---|---|---|---|---|---|
| Gopinath et al. [51] | IRF | AMD, RVO, DME | 2019 | Selective enhancement of cyst using generalised motion pattern (GMP) and CNN | Mean DC: 0.71 |
| Y. Derradji et al. [52] | Retinal atrophy | AMD | 2021 | CNN and Residual U-shaped Network | Mean Dice score: 0.881 Sensitivity: 0.85 Precision: 0.92 |
| Y. Guo et al. [53] | IRF, SRF, PED | DME | 2020 | ReF-Net | F1 score: 0.892 |
| Marc Wilson et al. [54] | IRF, PED | AMD | 2021 | Various DL Models | DSC: 0.43–0.78 |
| B. Sappa et al. [41] | IRF, SRF, PED | AMD | 2021 | RetFluidNet (based on auto-encoder) | Accuracy IRF: 80.05% PED: 92.74% PED: 95.53% |
| Girish et al. [55] | IRF | AMD, RVO, DME | 2019 | Fully connected neural network (FCNN) | Dice rate: 0.71 |
| Venhuizen et al. [56] | IRF | AMD, RVO, DME | 2018 | Cascade of neural networks to form DL algorithm | DC: 0.75 |
| Schlegl et al. [57] | IRF, SRF | AMD, RVO, DME | 2018 | Auto-encoder | AUC: 0.94 |
| Retouch [1] | IRF, SRF, PED | AMD, RVO | 2019 | Various models proposed by participants | DSC: 0.7–0.8 |
| Xu et al. [50] | Any | AMD | 2015 | Stratified sampling voxel classification for feature extraction and graph method for layer segmentation | TPR: 96% TNR: 0.16% |
| Chiu et al. [58] | Any | DME | 2015 | Kernel regression method to estimate fluid and graph theory and dynamic programming (GTDP) for boundary segmentation | DC: 0.78 |
4. Deep Learning Approach for OCT Image Analysis
Recent developments in AI, including deep learning and machine learning algorithms, have enabled the analysis of OCT images with unprecedented accuracy and speed. These algorithms can segment OCT images, detect pathological features, and identify biomarkers of various ocular diseases. Additionally, the use of AI frameworks such as TensorFlow and Keras has made it easier to develop these algorithms. AI is used for a wide range of applications in OCT, including image segmentation, disease diagnosis, and progression monitoring. One significant application of AI is the detection of age-related macular degeneration (AMD), a leading cause of blindness in older adults. AI algorithms can detect early signs of AMD, which can lead to early intervention and better outcomes for patients. Additionally, AI is used for the diagnosis and monitoring of other ocular diseases, including glaucoma and diabetic retinopathy. The use of AI in OCT has several potential clinical implications. One significant benefit is increased accuracy in diagnosis and treatment. AI algorithms can analyse OCT images with high precision and speed, leading to faster and more accurate diagnosis of ocular diseases. Additionally, AI can help clinicians monitor disease progression and evaluate treatment efficacy. This can lead to better patient outcomes and improved quality of life.
However, there are also potential drawbacks to using AI in OCT. One potential concern is the need for high-quality datasets. To develop accurate and reliable AI algorithms, large datasets of OCT images are required. Additionally, there is a risk of over-reliance on AI, which could lead to a reduction in human expertise and clinical judgment.
Deep learning approaches, particularly convolutional neural networks (CNNs), have been widely used in recent years for the analysis of optical coherence tomography (OCT) images. The success of these methods is attributed to the ability of CNNs to automatically learn features from the data, which can improve the performance of image analysis tasks compared to traditional methods.
One of the most promising deep learning architectures for OCT image analysis is the convolutional neural network (CNN). CNNs are designed to process data with a grid-like topology, such as images, and they are particularly well suited for tasks such as image classification and segmentation.
U-Net architecture is one of the most popular CNN architectures used in OCT image analysis. U-Net is an encoder–decoder type of CNN designed for image segmentation tasks. The encoder portion of the network compresses the input image into a low-dimensional feature space. In contrast, the decoder portion upscales the feature maps to the original image resolution to produce the final segmentation mask. A method using two deep neural networks (U-Net and DexiNed) was proposed in [2] to segment the inner limiting membrane (ILM), retinal pigment epithelium, and Bruch’s membrane in OCT images of healthy and intermediate AMD patients, showing promising results, with an average absolute error of 0.49 pixel for ILM, 0.57 for RPE, and 0.66 for BM.
Another type of architecture that is being used in the analysis of OCT images is Residual Network (ResNet). ResNet is a type of CNN which deals with the problem of vanishing gradients by introducing the idea of “shortcut connections” in the architecture. The shortcut connections bypass the full layers of the network and allow the gradients to be directly propagated to the earlier layers. A study proposed in [59] used a lightweight, explainable convolutional neural network (CNN) architecture called DeepOCT for the identification of ME on optical coherence tomography (OCT) images, achieving high classification performance with 99.20% accuracy, 100% sensitivity, and 98.40% specificity. It visualises the most relevant regions and pathology on feature activation maps and has the advantage of a standardised analysis, lightweight architecture, and high performance for both large- and small-scale datasets.
Subretinal fluid is a common finding in OCT images and can be a sign of various ocular conditions such as age-related macular degeneration, retinal detachment, and choroidal neovascularisation [60]. Accurate and efficient segmentation of subretinal fluid in OCT images is an essential task in ophthalmology, as it can help diagnose and manage these conditions.
However, manual segmentation of subretinal fluid in OCT images is time-consuming, labour-intensive, and prone to observer variability [60]. To address this challenge, there has been growing interest in using automated approaches to segment subretinal fluid in OCT images. In recent years, deep learning models have emerged as a promising solution for this task due to their ability to learn complex features and patterns from large amounts of data [60].
Azade et al. [61] introduced Y-Net, an architecture combining spectral and spatial domain features, to improve retinal optical coherence tomography (OCT) image segmentation. This approach outperformed the U-Net model in terms of fluid segmentation performance. The removal of certain frequency ranges in the spectral domain also demonstrated the impact of these features on the outperformance of fluid segmentation. This study’s results demonstrated that using both spectral and spatial domain features significantly improved fluid segmentation performance and outperformed the well-known U-Net model by 13% on the fluid segmentation Dice score and 1.9% on the average Dice score.
Bilal Hassan et al. [62] proposed using an end-to-end deep learning-based network called RFS-Net for the segmentation and recognition of multiclass retinal fluids (IRF, SRF, and PED) in optical coherence tomography (OCT) images. The RFS-Net architecture was trained and validated using OCT scans from multiple vendors and achieved mean F1 scores of 0.762, 0.796, and 0.805 for the segmentation of IRF, SRF, and PED, respectively. The automated segmentation provided by RFS-Net has the potential to improve the efficiency and inter-observer agreement of anti-VEGF therapy for the treatment of retinal fluid lesions.
Kun Wang et al. [63] proposed the use of an iterative edge attention network (EANet) for medical image segmentation. EANet includes a dynamic scale-aware context module, an edge attention preservation module, and a multilevel pairwise regression module to address the challenges of diversity in scale and complex context in medical images. Experimental results showed that EANet outperformed state-of-the-art methods in four different medical segmentation tasks: lung nodule, COVID-19 infection, lung, and thyroid nodule segmentation.
Jyoti Prakash et al. [64] presented an automated algorithm for detecting macular oedema (ME) and segmenting cysts in optical coherence tomography (OCT) images. The algorithm consists of three steps: removal of speckle noise using edge-preserving modified guided image filtering, identification of the inner limiting membrane and retinal pigment epithelium layer using modified level set spatial fuzzy clustering, and detection of cystoid fluid in positive ME cases using modified Nick’s threshold and modified level set spatial fuzzy clustering applied to green channel OCT images. The algorithm was tested on three databases and showed high accuracy and F1-scores in detecting ME cases and identifying cysts. It was found to be efficient and comparable to current state-of-the-art methodologies.
Menglin Wu et al. [65] proposed a two-stage algorithm for accurately segmenting neurosensory retinal detachment (NRD)-associated subretinal fluid in spectral domain optical coherence tomography (SD-OCT) images. The algorithm is guided by Enface fundus imaging, and it utilises a thickness map to detect fluid abnormalities in the first stage and a fuzzy level set method with a spatial smoothness constraint in the second stage to segment the fluid in the SD-OCT scans. The method was tested on 31 retinal SD-OCT volumes with central serous chorioretinopathy and achieved high true positive volume fractions and positive predictive values for NRD regions and for discriminating NRD-associated subretinal fluid from subretinal pigment epithelium fluid associated with pigment epithelial detachment.
Zhuang Ai et al. [66] proposed a fusion network (FN)-based algorithm for the classification of retinal optical coherence tomography (OCT) images. The FN-OCT algorithm combines the InceptionV3, Inception-ResNet, and Xception deep learning algorithms with a convolutional block attention mechanism and three different fusion strategies to improve the adaptability and accuracy of traditional classification algorithms. The FN-OCT algorithm was tested on a dataset of 108,312 OCT images from 4686 patients and achieved an accuracy of 98.7% and an area under the curve of 99.1%. The algorithm also achieved an accuracy of 92% and an AUC of 94.5% on an external dataset for the classification of retinal OCT diseases.
In addition to these architectures, several other techniques such as Attention U-Net, DenseNet, and SE-Net have also been proposed for OCT image analysis. Attention U-Net is a specific type of U-Net architecture that uses attention mechanisms to enhance the performance of segmentation tasks. A study [67] conducted in 2022 proposed a deep learning method called the wavelet attention network (WATNet) for the segmentation of layered tissue in optical coherence tomography (OCT) images. The proposed method uses the discrete wavelet transform (DWT) to extract multispectral information and improve performance compared to other existing deep learning methods.
DenseNet is another CNN architecture that is widely used for image classification tasks. It is known for its high efficiency and ability to learn features from multiple layers. A 2020 study [68] proposed a method for early detection of glaucoma using densely connected neural networks, specifically a DenseNet with 121 layers pretrained on ImageNet. The results obtained on a dataset of early and advanced glaucoma images achieved high accuracy of 95.6% and an F1-score of 0.97%, indicating that CNNs have the potential to be a cost-effective screening tool for preventing blindness caused by glaucoma; the DenseNet-based approach outperformed traditional methods for glaucoma diagnosis.
SE-Net is another variant of CNN architecture that includes squeeze and excitation blocks to improve the model’s performance by selectively highlighting the important features of the image. Zailiang Chen et al. [69] proposed a deep learning method called SEUNet for segmenting fluid regions in OCT B-scan images, which is crucial for the early diagnosis of AMD. The proposed method is based on U-Net and integrates squeeze and excitation blocks; it is able to effectively segment fluid regions with an average IOU coefficient of 0.9035, Dice coefficient of 0.9421, precision of 0.9446, and recall of 0.9464.
Overall, it can be concluded that deep learning-based methods have shown great potential in the analysis of OCT images and have outperformed traditional methods in various tasks such as image segmentation and diagnosis of retinal diseases. Different CNN architectures, such as U-Net, ResNet, Inception, Attention U-Net, DenseNet, and SE-Net have been proposed and used for these tasks with good performance. However, it should be noted that the success of these models also depends on the quality of the dataset used for training, and the generalisability of these models to new datasets needs further research. Common methods for deep learning-based OCT image processing are shown in Figure 16.
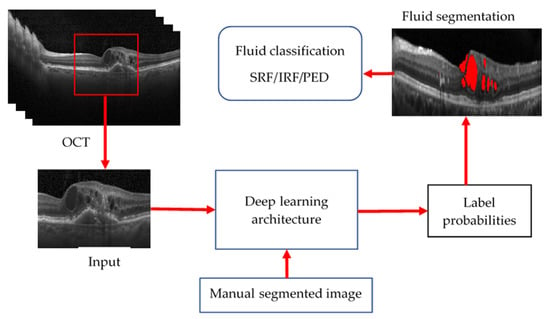
Figure 16. General procedure of AI-based OCT layer segmentation.
This entry is adapted from the peer-reviewed paper 10.3390/bioengineering10040407
This entry is offline, you can click here to edit this entry!