Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Offline handwritten Chinese recognition is an important research area of pattern recognition, including offline handwritten Chinese character recognition (offline HCCR) and offline handwritten Chinese text recognition (offline HCTR), which are closely related to daily life. HCTR is more complex and relatively less accurate due to the unconstrained nature of text lines and the adhesion between characters. It can be further divided into line-level HCTR and page-level HCTR depending on whether the recognition object is a cropped image of a text line or an entire page.
- handwritten Chinese recognition
- deep learning
- convolutional neural network
1. Line-Level Text Recognition
Line-level text recognition methods are mainly divided into two categories: one is to perform pre-segmentation, use a single-character classifier for recognition, and combine it with the context to generate text lines. The other is to recognize the text directly without character segmentation. Segmentation-based approaches mostly use over-segmentation and depth detection networks. Since HCCs tend to form overlapping and consecutive strokes between characters in the unrestrained writing process, it will significantly impact the cutting results, thus limiting the final recognition accuracy. The over-segmentation-based methods also face the problem of data sparsity. Therefore, there has been more research on segmentation-free based methods in the past few years. Clearly, the segmentation-free approach loses the detection information of individual characters, so some scholars combine segmentation and segmentation-free approaches and use deep detection networks to achieve end-to-end recognition of text while preserving the location information of characters. The researchers will present both types of approaches in the following.
1.1. Segmentation-Based Recognition
The segmentation-based text recognition approach is based on individual Chinese character recognition. Both character shape modeling and linguistic context modeling play a significant role. Most of the previous segmentation-based approaches are based on over-segmentation strategies. This approach usually involves building several modules, including character over-segmentation, character classification, language modeling, and geometric modeling. Then, they are integrated to find the optimal path.
In 2016, Wang et al. [1] used deep knowledge containing character or non-character labels, class labels, and the heterogeneous CNN that can be trained by deep knowledge to recognize HCT. The text will be over-segmented, so the HCT deep knowledge contains two parts: segmentation labels and classification labels for each segmented character. They proposed two types of heterogeneous CNN models, the cascading CNN containing 2-class CNN and all-class CNN, and the negative-awareness CNN. The proposed method has the advantage of incorporating the language model deeper into the path search when combined with language models compared to Long Short-Term Memory (LSTM) and Hidden Markov Model (HMM) frameworks that are good at handling time sequence tasks. Subsequently, during the period of back-off N-gram language models (BLMs) as the standard language model for the HCTR task, Wu et al. [2] first tried to recognize HCT using the neural network language model (NNLM) based on over-segmented text. They use CNN-based neural networks as a shape model for text recognition, which is used to accomplish over-segmentation of characters, classification, and as a geometric context model, and combined with hybrid NNLMs to improve the performance of the recognition system. Their approach achieved the best recognition result then and is often used as a comparison for the recognition results of other research methods on HCTR afterward. The research approaches since then have been focused on segmentation-free text recognition. In 2020, Wang et al. [3] proposed an HCTR method based on weakly supervised learning, as shown in Figure 1. Firstly, the text image is segmented by a CNN-based segmentation algorithm to generate a series of original text segments. Then, it is combined into one or more consecutive text segments to form a corresponding candidate character pattern and form a character candidate region. Finally, the wave beam search method is used to search the optimal path in the candidate region. The language and character classification models are combined to obtain the final recognition result. Their final experimental results show the competitive recognition performance of the method compared with other state-of-the-art methods. There is also room to further improve the performance by combining more powerful language models.
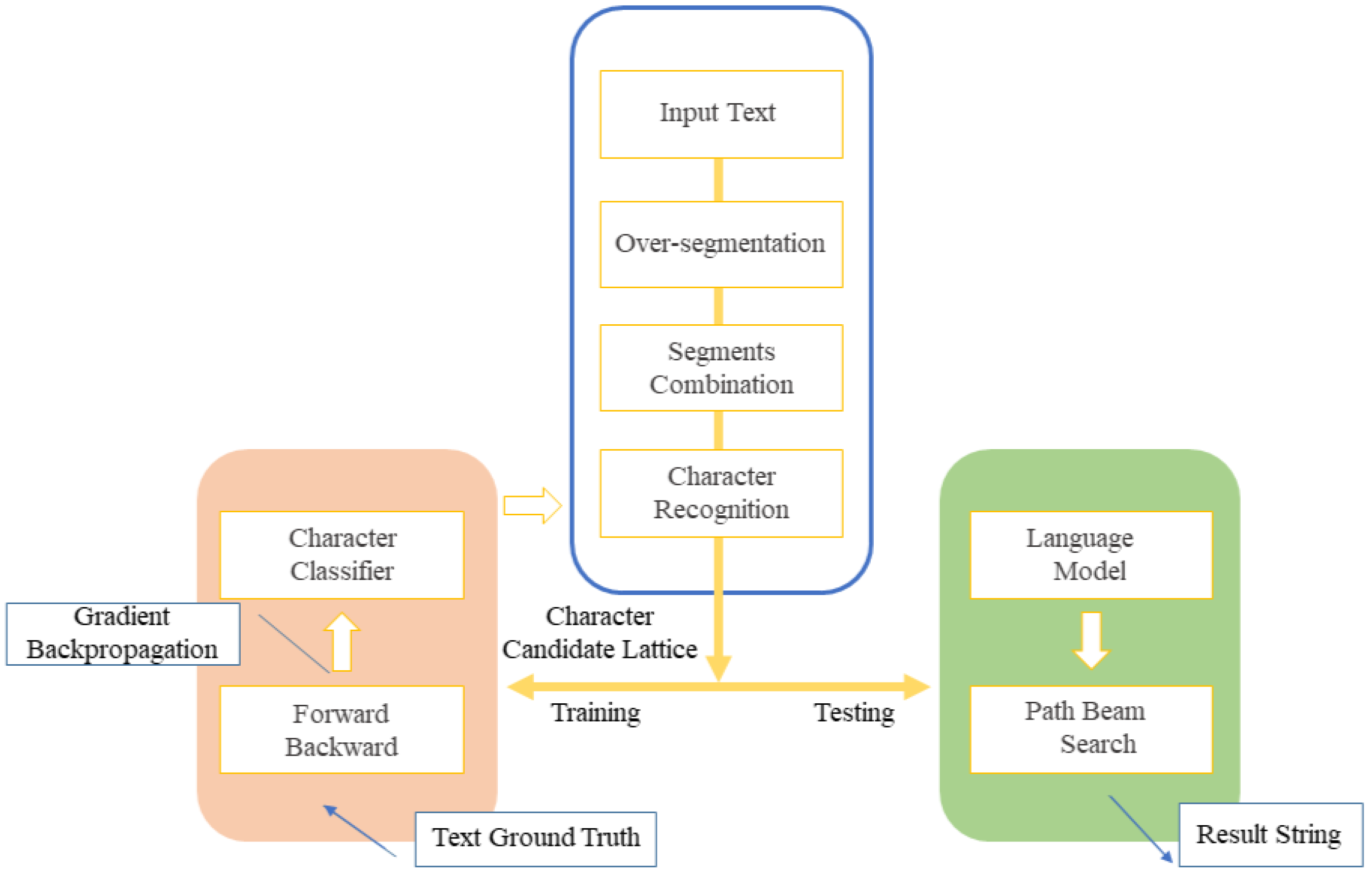
Figure 1. HCTR algorithm based on weakly-supervised learning [3].
Unlike over-segmentation-based methods, Peng et al. [4][5] used the full convolutional network-based approach for character detection as character segmentation, providing a new idea for segmentation-based HCTR. They proposed a fully convolutional network (FCN) that enables fast and accurate implementation of HCTR [4]. The structure extends three modules for detecting, localization, and classifying characters in text after a backbone network generates feature maps. Their proposed network model not only produces recognition results compared to the mainstream approach Recurrent Neural Network (RNN)/LSTM but also contains segmentation results that can be used for other subsequent applications, such as removing certain information. Compared with over-segmentation-based methods such as [1], this method can somewhat solve the problem of difficulty in segmenting characters due to overlapping characters, etc. Still, the recognition efficiency is not very satisfactory compared to other methods. In 2022, they further proposed a segmentation-annotation-free approach to segment and recognize text [5]. Compared with [4], they proposed a weakly supervised learning method that trains the network with only transcript annotations, which greatly reduces the cost of manual annotation while ensuring the output of segmented characters. In addition, they devised a contextual regularization method that incorporates integrated contextual information in the training of the FCN, thus significantly improving the recognition performance. The latest research is Hu et al. [6], who proposed a new retrieval-based approach that dynamically retrieves relevant content of the recognized text from the Internet to train an adaptive language model (LM) that can be integrated into the whole recognition process. Their strategy goes through a two-pass recognition process. After the initial recognition result is obtained by completing the first pass using the baseline system, the second pass recognition builds on this by retrieving relevant content on the Internet and building a domain-related language model integrated into the path search. Eventually, the method does not use much synthetic data compared to [5]. It achieves recognition results that can compete with [2], which has a large amount of character-level annotation and uses NNLM.
1.2. Segmentation-Free Recognition
The segmentation-free recognition method focuses on continuous feature extraction of the input text images. The possible sequences of characters represented in the sequential features are then matched with those of single characters. The best-matched text sequence is derived as the output of the whole recognition according to the evaluation criteria of the objective function. The HMM based on the Gaussian Mixture Model (GMM) proposed by Su et al. [7] became the representative algorithm in handwritten text recognition. As the length of recognized characters increases, the HMM-based approach generates too many parameters that limit the recognition performance. Subsequently, offline handwritten text recognition based on or combined with neural networks has evolved more significantly. In recent years, some approaches using the Multi-dimensional LSTM (MDLSTM) Model [8], Convolutional Recurrent Neural Network (CRNN) [9], Connectionist Temporal Classification (CTC) algorithm [10], and attention mechanism [11], etc., have improved the model recognition accuracy to different degrees.
To apply MDLSTM-RNN to HCTR with an accuracy of 83.5% was first proposed by Messina et al. [12]. Shen et al. [13] pointed out that the current data augmentation method can significantly improve the accuracy of the recognition task of printed documents. However, it is not suitable for the task of handwriting recognition. Therefore, the team utilizes the baseline model MDLSTM-RNN [14] for generating synthetic line images. By training and testing on the CASIA dataset, the character error rate of the model trained with synthetic images and real images is reduced by 10.4%. Bluche et al. [15] proposed using character decomposition techniques to speed up HCTR for the slow system of [12]. Their system consists of an optical model based on MDLSTM-RNN and a language model. They use Cangjie [16], Wubi [17], and an arbitrary encoding to decompose characters for experiments without significant modification to the baseline MDLSTM-RNN. Wu et al. [18] improved the MDLSTM-RNN network. In addition, the network based on SMDLSTM-RNN applies fewer MDLSTM layers than the network based on MDLSTM-RNN [12], consumes much fewer resources and computation, and improves the accuracy by 3.14% without adding a corpus.
Du et al. conducted a series of studies combining neural networks with HMM. In 2016, they proposed a deep neural network (DNN-HMM) based on the Bayesian decision for handwritten text recognition [19]. The model extracts the gradient features based on the classifier of DNN, and then the HMM models the text lines sequentially. Finally, the feature language model is integrated with the DNN-HMM feature model, and the final recognition result can be obtained by Bayesian decision. Later, they extended their work in [20] to investigate the key issues of feature extraction, character modeling, and language modeling when using GMM-HMM, DNN-HMM, and DCNN-HMM to implement HCTR. They proposed a hybrid neural network Hidden Markov Model (NN-HMM) and proved its effectiveness for offline HCTR [21]. In 2020, they proposed a Chinese text recognition method (CNN-PHMM) that combines a writer-aware CNN network and parsimonious HMM [22]. First, the state binding algorithm is used by PHMM to reduce the total amount of HMM states. Second, WCNN integrates each convolutional layer with an adaptive layer composed of writer-dependent vectors and optimizes it by combining it with other network parameters to obtain the final recognition result. Though the method segments characters, their approach reduces the CER for recognition of the ICDAR 2013 dataset to the best result at that time based on the compact design of the output layers and the writer-aware convolutional layers. Due to the high dependence of this approach on a large amount of writer-specific data and it needing multiple-pass decoding, which is time consuming, they proposed another generalized writer adaptation scheme in 2022 that can achieve fast sentence-level unsupervised adaptation [23]. Trained by identification loss (IDL), they proposed a style extractor network (SEN) consisting of a convolutional layer, a recurrent neural network with gated recurrent units (GRU), where the writing style is represented by a one-dimensional vector integrated by the output of the GRU. The style information extracted by the SEN is fed into the writer-independent recognizer to achieve adaptation. Thus, the performance of the recognizer using SEN is improved. Notably, in 2021, Wang et al. [24] also proposed an intelligent residual attention gate module combining residual and attention frameworks based on fully convolutional neural networks. The module enhances the ability to extract meaningful features from text images by weighting to increase the importance of representative features and reduce the influence of background or noise, significantly improving the performance of the current HCTR.
Different neural networks have different advantages and can be integrated by model merging. In recent years, RNNs and their modified networks have been used more often in combination with convolutional networks to recognize handwritten text. In 2019, Xiu et al. [25] proposed a neural network structure combining a Multi-level Multimodal Fusion module and an Attention-based LSTM module to fully use visual feature information and linguistic semantic information. Zhang et al. [26] proposed a Bidirectional Recurrent Neural Network (BiRNN) for text recognition. The network first obtains the semantic feature map by the convolution layer and then converts the semantic information into time series information through the conversion module and processes it through Bidirectional-LSTM. The results prove that the algorithm can analyze and predict characters by linking forward and backward contexts and effectively solve the problem of sample imbalance. In 2020, Xie et al. [27] proposed a data enhancement method for HCTR and constructed a recognition network model combining CNN and LSTM (CNN-ResLSTM). The experiment proved that data preprocessing and data augmentation methods can effectively improve the model performance.
In addition to the character encoding method discussed in [15], Hoang et al. [28] developed a new encoding technique called LOgographic DEComposition Encoding (LODEC). It can perform one-to-one mapping of Chinese. Instead of splitting characters into scattered stroke elements, the proposed encoding limits the decomposition to predefined radical components to encode many Chinese characters with a small number of basic elements. They also proposed a deep learning architecture called LODENet that extracts radical-based features from the input data, which is then decoded by a transformation network for radical-based features. In 2021, Ngo et al. [29] first proposed to use the RNN-Transducer model for offline HCTR. The network mainly comprises a visual feature encoder, language context encoder, and joint decoder. Specifically, CNN is used to obtain relevant visual features, and then the visual features are encoded according to the BLSTM module. On the other hand, relevant language context information is obtained through the Embedding layer and the LSTM module. Finally, the visual and language features are coupled and decoded into the final recognition result through the fully connected and softmax layers. In addition to the above approaches, the visual characteristics of glyphs and the semantics of Chinese characters are also exploited by [30]. In 2022, Zhan et al. proposed the Glyph-Semanteme fusion embedding (GSE) module according to the correlation between glyphs and semantics. Specifically, the decoder prediction obtains the recognition result by extracting the glyph and semantic embedding of Chinese characters and automatically calculating the symbol speech fusion embedding of characters according to the parametric gating fusion strategy. Furthermore, two kinds of generalized systems engineering, character-level generalized systems engineering (CGSE) and text-level generalized systems engineering (TGSE), are applied in the decoder stage to generate predictions. On the standard benchmark ICDAR-2013 HCTR competition dataset, the method achieves a character-level recognition accuracy of 96.65%, which demonstrates the effectiveness of the proposed glyph-semantic fusion embedding.
Figure 2 counts the number of papers on line-level HCTR research by segmentation and segmentation-free based approaches from 2016 to 2022, as well as the highest AR achieved on the ICDAR 2013 dataset with and without LM per year. In general, segmentation-free approaches have become more mainstream in recent years due to their avoidance of expensive character segmentation annotations and character segmentation errors, combined with writer-aware, language models, etc., to improve recognition performance. Current research on segmentation-based approaches aims to achieve high-performance end-to-end recognition while providing character location information. In addition to using a single strategy, Zhu et al. [31] proposed an attention combination model that can combine the advantages of segmentation and segmentation-free recognition methods. Both provide character position information for more accurate recognition of characters, avoid segmentation errors, and enable end-to-end recognition. They first obtained recognition results for multiple recognition methods. Then, a combined model of one-dimensional gated convolutional neural networks containing multiple encoders and a decoder could infer the final recognition results. Their experimental results show the effectiveness of combining explicit and implicit segmentation methods. Table 1 summarizes the recognition accuracy of different methods on the ICDAR 2013 dataset for line-level text.
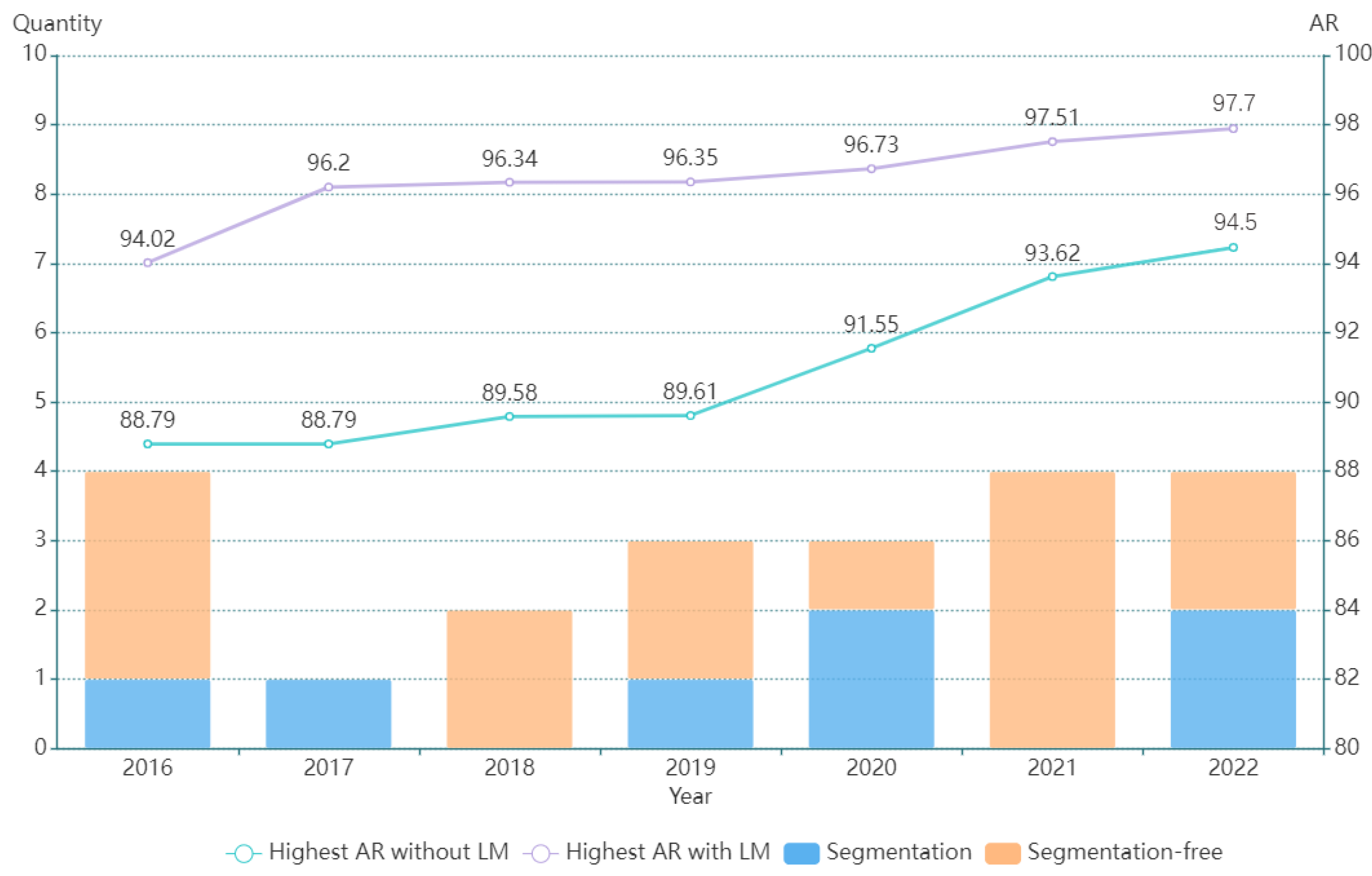
Figure 2. The number of papers per year from 2016 to 2022 on line-level HCTR with different methods and the highest AR (100%-CER) achieved on the ICDAR 2013 dataset with and without LM. The references corresponding to the highest AR (without LM) per year are [1][4][5][21][27][32]. The references corresponding to the highest AR (with LM) per year are [1][2][5][21][22][25][32].
Table 1. AR (100%-CER) of line-level text recognition by different methods on the ICDAR 2013 dataset. “n/a” indicates not mentioned, “×” indicates used, “√” indicates not used.
| Method | Year | Experimental Platform |
Framework | Method Type |
Without LM |
LM | Data Synthesis |
|---|---|---|---|---|---|---|---|
| Negative- awareness CNN (trigram) [1] |
2016 | n/a | n/a | over- segmentation |
88.79 | 94.02 | × |
| DNN- HMM [19] |
2016 | n/a | n/a | segmentation- free |
83.89 | 93.5 | × |
| DCNN- HMM [20] |
2017 | n/a | Caffe | segmentation- free |
n/a | 95.93 | × |
| HRMELM [2] | 2017 | Intel Core i7- 4790 3.60 GHz CPU, NVIDIA Titan X GPUs |
Caffe | over- segmentation |
n/a | 96.2 | × |
| NN- HMM [21] |
2018 | n/a | Caffe | segmentation- free |
89.58 | 96.34 | × |
| FCN (with SRM) [4] |
2019 | GTX 1080Ti GPU |
n/a | segmentation | 89.61 | 95.51 | √ |
| Attention- Based LSTM [25] |
2019 | n/a | Tensorflow | segmentation- free |
88.74 | 96.35 | × |
| Attention combination of sequence models [31] |
2020 | two TITAN Xp GPUs |
Pytorch | combination of segmentation and segmentation- free |
90.86 | 94 | √ |
| CNN- ResLSTM [27] |
2020 | i7-8700K CPU, single Titan X GPU |
Caffe | segmentation- free |
91.55 | 96.72 | √ |
| Weakly supervised learning [3] |
2020 | NVIDIA GeForce GTX 1080Ti GPUs |
Pytorch | over- segmentation |
n/a | 95.11 | × |
| WCNN- PHMM [22] |
2020 | NVIDIA GeForce GTX 1080Ti GPUs |
Kaldi, Pytorch |
segmentation | 91.36 | 96.73 | × |
| Residual- attention [24] |
2021 | Intel Core i9-9900K 3.60 GHz CPU, NVIDIA RTX 2080Ti GPUs |
Tensorflow | segmentation- free |
91.30 | 96.51 | × |
| CNN-CTC- CBS [32] |
2021 | two NVIDIA Titan V GPUs |
Pytorch | segmentation- free |
93.62 | 97.51 | √ |
| Attention- based model + GSE [30] |
2022 | Intel XEON E5-1650 with 3.5 GHz, one NVIDIA GTX 2080Ti GPU |
Tensorflow | segmentation- free |
89.87 | 96.65 | × |
| Common + Retrieval LM + Improvements [6] |
2022 | n/a | n/a | over- segmentation |
n/a | 95.48 | × |
| Segment- annotation- free [5] |
2022 | NVIDIA GTX 1080Ti GPU with 11 GB of memory |
Pytorch | segmentation | 94.50 | 97.70 | √ |
2. Page-Level Text Recognition
In addition to recognizing line-level text, driven by the critical value of text recognition for fields such as industry and education, scholars have recently conducted several studies on recognizing page-level handwritten text. Refs. [33][34][35][36] recognize traditional ancient texts read from top to bottom, and Ref. [37] recognizes texts under standard test paper formatting specifications, which are restricted to a specific layout. Faced with unconstrained text, Kundu et al. [38] extracted text lines from unconstrained handwritten documents using Generative Adversarial Networks (GAN). Yan et al. [39] identified the failure of existing methods to correctly identify Chinese text when adding keywords and word replacement as a two-dimensional problem. Therefore, the team proposed a Structural Attention Network (SAN) model to learn irregular structures to recognize text correctly with insertions and swaps. A critical attempt and advancement of unconstrained page-level HCTR was in 2022; Peng et al. [40] proposed a new end-to-end weakly supervised page-level HCTR method, PageNet. The method consists of three modules, a module for detecting and recognizing characters, a reading order module for determining intercharacter relationships and determining head and tail characters, and a graph-based decoding module for outputting the detection and recognition results, trained in a weakly supervised learning framework. This method achieves solving for the HCTR page-level reading order problem under weak supervision and can handle unconstrained text. It also provides new ideas and inspirations to other researchers to solve the page-level text recognition problem.
This entry is adapted from the peer-reviewed paper 10.3390/app13063500
References
- Wang, S.; Chen, L.; Xu, L.; Fan, W.; Sun, J.; Naoi, S. Deep knowledge training and heterogeneous CNN for handwritten Chinese text recognition. In Proceedings of the 2016 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), Shenzhen, China, 23–26 October 2016; pp. 84–89.
- Wu, Y.C.; Yin, F.; Liu, C.L. Improving handwritten Chinese text recognition using neural network language models and convolutional neural network shape models. Pattern Recognit. 2017, 65, 251–264.
- Wang, Z.X.; Wang, Q.F.; Yin, F.; Liu, C.L. Weakly supervised learning for over-segmentation based handwritten Chinese text recognition. In Proceedings of the 2020 17th International Conference on Frontiers in Handwriting Recognition (ICFHR), Dortmund, Germany, 8–10 September 2020; pp. 157–162.
- Peng, D.; Jin, L.; Wu, Y.; Wang, Z.; Cai, M. A fast and accurate fully convolutional network for end-to-end handwritten Chinese text segmentation and recognition. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 25–30.
- Peng, D.; Jin, L.; Ma, W.; Xie, C.; Zhang, H.; Zhu, S.; Li, J. Recognition of Handwritten Chinese Text by Segmentation: A Segment-annotation-free Approach. IEEE Trans. Multimed. 2022.
- Hu, S.; Wang, Q.; Huang, K.; Wen, M.; Coenen, F. Retrieval-based language model adaptation for handwritten Chinese text recognition. Int. J. Doc. Anal. Recognit. (IJDAR) 2022, 1–11.
- Su, T.H.; Zhang, T.W.; Guan, D.J.; Huang, H.J. Off-line recognition of realistic Chinese handwriting using segmentation-free strategy. Pattern Recognit. 2009, 42, 167–182.
- Thireou, T.; Reczko, M. Bidirectional long short-term memory networks for predicting the subcellular localization of eukaryotic proteins. IEEE/ACM Trans. Comput. Biol. Bioinform. 2007, 4, 441–446.
- Shi, B.; Bai, X.; Yao, C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2298–2304.
- Graves, A. Connectionist temporal classification. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 61–93.
- Chorowski, J.K.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-based models for speech recognition. Adv. Neural Inf. Process. Syst. 2015, 28, 577–585.
- Messina, R.; Louradour, J. Segmentation-free handwritten Chinese text recognition with LSTM-RNN. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; pp. 171–175.
- Shen, X.; Messina, R. A method of synthesizing handwritten chinese images for data augmentation. In Proceedings of the 2016 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), Shenzhen, China, 23–26 October 2016; pp. 114–119.
- Graves, A.; Schmidhuber, J. Offline handwriting recognition with multidimensional recurrent neural networks. Adv. Neural Inf. Process. Syst. 2008, 21, 545–552.
- Bluche, T.; Messina, R. Faster segmentation-free handwritten Chinese text recognition with character decompositions. In Proceedings of the 2016 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), Shenzhen, China, 23–26 October 2016; pp. 530–535.
- Liu, C.L.; Lin, J.H. Using structural information for identifying similar Chinese characters. In Proceedings of the ACL-08: HLT, Short Papers, Columbus, OH, USA, 15–20 June 2008; pp. 93–96.
- Sacher, H. Interactions in Chinese: Designing interfaces for Asian languages. Interactions 1998, 5, 28–38.
- Wu, Y.C.; Yin, F.; Chen, Z.; Liu, C.L. Handwritten Chinese Text Recognition Using Separable Multi-Dimensional Recurrent Neural Network. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 79–84.
- Du, J.; Wang, Z.R.; Zhai, J.F.; Hu, J.S. Deep neural network based hidden Markov model for offline handwritten Chinese text recognition. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 3428–3433.
- Wang, Z.R.; Du, J.; Hu, J.S.; Hu, Y.L. Deep convolutional neural network based hidden markov model for offline handwritten Chinese text recognition. In Proceedings of the 2017 4th IAPR Asian Conference on Pattern Recognition (ACPR), Nanjing, China, 26–29 November 2017; pp. 816–821.
- Wang, Z.R.; Du, J.; Wang, W.C.; Zhai, J.F.; Hu, J.S. A comprehensive study of hybrid neural network hidden Markov model for offline handwritten Chinese text recognition. Int. J. Doc. Anal. Recognit. (IJDAR) 2018, 21, 241–251.
- Wang, Z.R.; Du, J.; Wang, J.M. Writer-aware CNN for parsimonious HMM-based offline handwritten Chinese text recognition. Pattern Recognit. 2020, 100, 107102.
- Wang, Z.R.; Du, J. Fast writer adaptation with style extractor network for handwritten text recognition. Neural Netw. 2022, 147, 42–52.
- Wang, Y.; Yang, Y.; Ding, W.; Li, S. A Residual-Attention Offline Handwritten Chinese Text Recognition Based on Fully Convolutional Neural Networks. IEEE Access 2021, 9, 132301–132310.
- Xiu, Y.; Wang, Q.; Zhan, H.; Lan, M.; Lu, Y. A Handwritten Chinese Text Recognizer Applying Multi-level Multimodal Fusion Network. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 1464–1469.
- Zhang, X.; Yan, K. An Algorithm of Bidirectional RNN for Offline Handwritten Chinese Text Recognition. In Proceedings of the Intelligent Computing Methodologies, Nanchang, China, 3–6 August 2019; Lecture Notes in Computer Science. Huang, D.S., Huang, Z.K., Hussain, A., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 423–431.
- Xie, C.; Lai, S.; Liao, Q.; Jin, L. High Performance Offline Handwritten Chinese Text Recognition with a New Data Preprocessing and Augmentation Pipeline. In Proceedings of the Document Analysis Systems, Wuhan, China, 26–29 July 2020; Lecture Notes in Computer Science. Bai, X., Karatzas, D., Lopresti, D., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 45–59.
- Hoang, H.T.; Peng, C.J.; Tran, H.V.; Le, H.; Nguyen, H.H. LODENet: A Holistic Approach to Offline Handwritten Chinese and Japanese Text Line Recognition. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 4813–4820.
- Ngo, T.T.; Nguyen, H.T.; Ly, N.T.; Nakagawa, M. Recurrent neural network transducer for Japanese and Chinese offline handwritten text recognition. In Proceedings of the International Conference on Document Analysis and Recognition, Lausanne, Switzerland, 5–10 September 2021; pp. 364–376.
- Zhan, H.; Lyu, S.; Lu, Y. Improving offline handwritten Chinese text recognition with glyph-semanteme fusion embedding. Int. J. Mach. Learn. Cybern. 2022, 13, 485–496.
- Zhu, Z.Y.; Yin, F.; Wang, D.H. Attention Combination of Sequence Models for Handwritten Chinese Text Recognition. In Proceedings of the 2020 17th International Conference on Frontiers in Handwriting Recognition (ICFHR), Dortmund, Germany, 8–10 September 2020; pp. 288–294.
- Liu, B.; Sun, W.; Kang, W.; Xu, X. Searching from the Prediction of Visual and Language Model for Handwritten Chinese Text Recognition. In Proceedings of the International Conference on Document Analysis and Recognition, Lausanne, Switzerland, 5–10 September 2021; pp. 274–288.
- Yang, H.; Jin, L.; Sun, J. Recognition of chinese text in historical documents with page-level annotations. In Proceedings of the 2018 16th International Conference on Frontiers in Handwriting Recognition (ICFHR), Niagara Falls, NY, USA, 5–8 August 2018; pp. 199–204.
- Yang, H.; Jin, L.; Huang, W.; Yang, Z.; Lai, S.; Sun, J. Dense and tight detection of chinese characters in historical documents: Datasets and a recognition guided detector. IEEE Access 2018, 6, 30174–30183.
- Xie, Z.; Huang, Y.; Jin, L.; Liu, Y.; Zhu, Y.; Gao, L.; Zhang, X. Weakly supervised precise segmentation for historical document images. Neurocomputing 2019, 350, 271–281.
- Ma, W.; Zhang, H.; Jin, L.; Wu, S.; Wang, J.; Wang, Y. Joint layout analysis, character detection and recognition for historical document digitization. In Proceedings of the 2020 17th International Conference on Frontiers in Handwriting Recognition (ICFHR), Dortmund, Germany, 8–10 September 2020; pp. 31–36.
- Su, T.; You, H.; Liu, S.; Wang, Z. FPRNet: End-to-End Full-Page Recognition Model for Handwritten Chinese Essay. In Proceedings of the International Conference on Frontiers in Handwriting Recognition, Hyderabad, India, 4–7 December 2022; pp. 231–244.
- Kundu, S.; Paul, S.; Bera, S.K.; Abraham, A.; Sarkar, R. Text-line extraction from handwritten document images using GAN. Expert Syst. Appl. 2020, 140, 112916.
- Yan, S.; Wu, J.W.; Yin, F.; Liu, C.L. Recognizing Handwritten Chinese Texts with Insertion and Swapping Using a Structural Attention Network. In Proceedings of the International Conference on Document Analysis and Recognition, Lausanne, Switzerland, 5–10 September 2021; pp. 557–571.
- Peng, D.; Jin, L.; Liu, Y.; Luo, C.; Lai, S. PageNet: Towards End-to-End Weakly Supervised Page-Level Handwritten Chinese Text Recognition. Int. J. Comput. Vis. 2022, 130, 2623–2645.
This entry is offline, you can click here to edit this entry!