Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Deep learning (DL) algorithms were established in 2006 and have been extensively utilized by many researchers and industries in subsequent years. Ever since the impressive breakthrough on the ImageNet classification challenge in 2012, the successes of supervised deep learning have continued to pile up. Many researchers have started utilizing this new and capable family of algorithms to solve a wide range of new tasks, including ways to learn intelligent behaviors in reward–driven complex dynamic problems successfully. The agent––environment interaction expressed through observation, action, and reward channels is the necessary and capable condition of characterizing a problem as an object of reinforcement learning (RL). Learning environments can be characterized as Markov decision problems, as they satisfy the Markov property, allowing RL algorithms to be applied. From this family of environments, games could not be absent. In a game–based environment, inputs (the game world), actions (game controls), and the evaluation criteria (game score) are usually known and simulated. With the rise of DL and extended computational capability, classic RL algorithms from the 1990s could now solve exponentially more complex tasks such as games over time, traversing through huge decision spaces.
- reinforcement learning
- deep learning
- artificial intelligence
- gaming
1. Introduction
Deep learning (DL) algorithms were established in 2006 [1] and have been extensively utilized by many researchers and industries in subsequent years. Ever since the impressive breakthrough on the ImageNet [2] classification challenge in 2012, the successes of supervised deep learning have continued to pile up. Many researchers have started utilizing this new and capable family of algorithms to solve a wide range of new tasks, including ways to learn intelligent behaviors in reward–driven complex dynamic problems successfully. The agent––environment interaction expressed through observation, action, and reward channels is the necessary and capable condition of characterizing a problem as an object of reinforcement learning (RL). Learning environments can be characterized as Markov decision problems [3], as they satisfy the Markov property, allowing RL algorithms to be applied. From this family of environments, games could not be absent. In a game–based environment, inputs (the game world), actions (game controls), and the evaluation criteria (game score) are usually known and simulated. With the rise of DL and extended computational capability, classic RL algorithms from the 1990s [4,5] could now solve exponentially more complex tasks such as games [6] over time, traversing through huge decision spaces. This new generation of algorithms, which exploits graphical processing unit (GPU) batch computations, reward/punishment costs, as well as the immense computational capabilities of today’s machines, is called deep reinforcement learning (DRL) [7]. According to [8,9], neuroevolutionary approaches were demonstrated that directly applied to pixel data. A year after, the development of the Deep–Q–Network (DQN) by Google was the most noticeable breakthrough in the era of DRL. This novel algorithm could recognize and learn behaviors directly from pixels in an unknown environment [10].
However, there were some issues at the early stages of the development due to the instability of neural networks when acting as approximation functions (correlated inputs, oscillating policies, large gradients, etc.) that were solved through the natural development of the wider DL field. For example, the correlation between the inputs to a Machine Learning (ML) model can affect their training process, leading to underfitting/overfitting in many cases. Other issues, such as policy degradation, which can arise from value function overestimation, has been addressed by using multiple value functions [11,12] or large gradients by subtracting a previously learned baseline [13,14]. Other approaches to these instabilities include trust region algorithms, such as trust region policy optimization (TRPO) [15] or proximal policy optimization (PPO) [16], where the policy is updated by applying various constraints.
2. Transition to Deep Reinforcement Learning
Humans can perceive patterns and complete complicated tasks in a very short period. Inside this framework, they successfully interpret optical data, transcribe them into meaningful entities, process them, and eventually make intelligent judgments. Over the last few decades, the scientific community has made significant efforts to accomplish these crucial human capabilities. Even before the turn of the century, studies suggested that intelligent algorithms that could adapt/learn from data may be used to solve this problem [35]. The most widely accepted explanation is that it works similarly to the human brain and central nervous system. These “brain modelling” algorithms can adapt to various problems. They were, however, hampered by the lack of computationally powerful equipment at the time. At its pinnacle, the family of theories, methods, and algorithms based on this principle was known as “neural networks”, and it was considered to be the top choice in most problem–solving domains [36].
3. Deep Q–Network in ATARI
According to [19] that DeepMind published in February 2015, the combination of deep neural networks (DNNs) with classic RL methods was described. The results in games of the ATARI console were excellent (high score in the famous breakout game).
There are several games in which superhuman–level performance has been achieved. DQN can represent states using deep convolutional neural networks (CNNs) to reduce the complexity, which in real–world problems is prohibitive using the classic methods, as analyzed in the previous section. More specifically, the architecture of the DQN was consisted of a 4–dimensional 84 × 84 input image that included the RGB channels of the game’s current frame, along with the luminance channel. The input layer is then followed by three convolutional layers with 32 8 × 8 filters with a stride of 4, 64 4 × 4 filters with stride of 2, and 64 3 × 3 filters with stride of 1, respectively. Moreover, the first and second convolutional layers also applied a rectifier nonlinearity, whereas the third one was followed by a simple rectifier. The final layers consisted of a fully connected dense layer with 512 units, followed by the output layer that consisted of a single output for each of the 4–18 valid actions, considering the “no action” as well.
The expected result is that the agent will be capable of interacting with the rest of the environment with actions, observations, and rewards [39]. Therefore, the agent’s target is to choose which actions will maximize its rewards. In this case, in particular, the deep neural network (DNN) tries to approximate the best energy evaluation function:
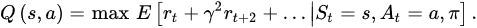
RL is not predictable from the beginning or even deviates when a nonlinear function approximation, such as NNs, is applied to estimate the energy evaluation function. The correlation in sequence observations, as well as the one between energy values and the TD target and the fact that tiny changes in the energy value function would result in many substantial changes in the agent’s policy [40], contribute to the turbulence. DQN, a variation of the Q–learning method that utilizes two core principles, was developed by DeepMind to solve this instability. Initially, an experience replay (experience repetition) mechanism was used, which chose random observations for learning and thereby eliminated the association between a sequence of observations [41].
The second idea was to shift the energy value function in the direction of the TD goal [42,43], but only periodically rather than after each observation, thereby diminishing the relationship between the two. This is performed by regularly replicating the Q network into a second Q network, which is used to estimate the TD target and update the Q–network parameters [44].
The neural network (NN) was used to configure an estimated value function of energy Q(s,a|θi) in the DQN implementation, where θi is the parameter (i.e., the weights) of the Q–network in iteration i. Agent “experience” is then processed in quads et=(St,At,rt,St+1) to enforce experience repetition. At any time t during training, the energy value function’s values are renewed based on samples of experiences randomly selected from the stored data collection. This update is based on the derivative convergence algorithm (gradient descent) and uses the following function error:
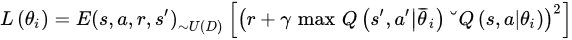
where γ is the discount factor (or rate) that defines the agent’s “visibility”, θi is the Q–network parameters in iteration i, and θ¯i is the parameter of the Q¯¯¯–network used to measure the TD goal in iteration i. The parameters θ¯i are modified every C iterations by copying the parameters, and they remain stable between their renewals [45].
DeepMind used this technique (DQN) to train video data, incentives, terminals, and accessible moves for ATARI games [46]. The network was not given any fundamental knowledge about the game and was trained using video data, rewards, terminals, and accessible movements. This is how a typical user would approach it. Its purpose was to create a single neural network agent that could train (and play) many games. In six of the seven games, the DeepMind Technologies agent defeated every other algorithm with DQN while also beating the world record set by human players in three of them [41].
4. Double Q–Learning
Even though double Q–learning (shown in Algorithm 3) and DQN were watershed moments in the world of RL, they had some flaws. Many researchers suggested improved versions to address these problems [48]. DeepMind also made further improvements regarding the deep Q–learning algorithm and the network, achieving even more excellent high scores in ATARI games such as pinball.
Hado van Hasselt explains that the Q–learning algorithm does not perform well in specific stochastic environments [49]. This occurred due to overestimating the energy values using maxQ(s′,a). The suggested solution was to hold two Q–value functions, QA and QB, which are renewed for the next state by each other. The renewal is carried out by first determining the energy a∗ that maximizes QA in the following state:
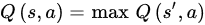
and then calculating the value of QB(s,a) based on a∗ so that the renewal in QA can be carried out as QA(s,a). This particular technique can be combined with DQN, boosting its capabilities, by using the following loss function:
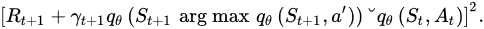
This modification was shown to reduce the overestimation of energy values in the DQN algorithm, resulting in improved algorithm efficiency.
5. Prioritized Experience Replay
According to the replay buffer technique, the DQN algorithm selects samples from memory. However, it would be preferable to use samples from state transitions that are crucial in training. Tom Schaul [50] presented the concept of priority inexperience in 2015. The idea is to choose experience samples with a significant difference between them at the approximate value of Q and the TD target, as this means that these particular experiences “carry” much information. The transitions––experiences are chosen with a probability of p based on the last occurrence of an absolute error:
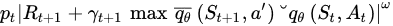
where ω
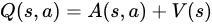
is a hyperparameter that defines the shape of the distribution. Finally, new experiences are added to the memory with the highest priority, giving recent transitions precedence.
6. Dueling Networks
Dueling Network architecture is based on the idea that assessing the value of each possible action is not always essential. Knowing which energy should employ would be critical in certain situations, but the energy choice has the minimum impact on the outcome in many others. However, estimating the relevance of the states is necessary for bootstrapping methods.
To obtain this discovery, Google DeepMind created the Dueling Network [14]. The lowest layers are convolutional, as they were in the DQNs [51] at the time. They employ two sequences (or streams) of ultimately linked layers instead of utilizing coherent layers followed by a single sequence of fully connected layers. The streams are set up to produce independent estimations of value and reward functions. Finally, the two streams are combined to provide only one Q mode output. There are Q values in the network output, one for each service. Because the Dueling Network’s performance is a Q function, it may be trained using several techniques, including DDQN and SARSA [52]. It will also benefit from improvements to these algorithms, such as improved repetition memories and exploration strategies. The module that combines the two streams of completely connected layers to generate a Q rating necessitates meticulous design.
It is worth noting that Q values indicate how profitable it is for the agent to be in state s and take action a (Q(s,a)) as shown in the function below:
where V(s) is the agent’s value for being in state s, and A(s,a) is the advantage of the agent choosing energy a in state s (how much better the outcomes would be if this action were chosen, over all the possible actions).
There is a need to isolate the estimator of these two components using two new streams in conjunction with DQN:
-
One that calculates the state value V(s);
-
One that will estimate the advantage of each action a in state s, A(s,a).
7. Microsoft’s Success
In June 2017, Microsoft reported that it had reached the highest possible score to be accomplished, despite continuous training failures of the Ms. Pacman game, both from Google using neural networks and other companies using different approaches. This phenomenal score of 999,990 was obtained by people cheating at the time. According to Twin Galaxies, a man’s highest score is 933,580, which belongs to Abdner Ashman.
This success came relatively late, as previous years saw substantial performances in other more challenging games, as described in the previous section. Beyond that, DeepMind’s AlphaGo has defeated human Go experts, while Libratus and DeepStack also easily defeated some poker professionals in heads–up no–limit Texas Hold’em. The A team from Maluuba used artificial intelligence (AI) to build tasks, broke them down into roles, and delegated them to over 150 agents. The hybrid reward architecture was used–––a mixture of enhanced learning and a divide and conquer algorithm. Every agent had different responsibilities (for example, finding a particular pill from the Ms. Pacman grid), which they shared with other agents to achieve better results. Another agent was then used that took into account all of the roles presented to each agent and decided which move Ms. Pacman would take.
The best results were obtained when each agent behaved entirely selfishly, and the super–agent concentrated on the best move for the entire club. This was achieved by assigning weights to the various options based on their relevance. For example, fewer agents attempt to stop ghost–enemies than those attempting to make the Pacman gain more points. There are four agents for ghost–enemies (one for each ghost–enemy) and four for chased ghosts. If the super agent’s decision were based on what the majority wanted, it would undoubtedly end up with a ghost enemy and lose. According to Harm Van Seijen, [53], there is significant importance in how agents should collaborate based on their options and how they should behave selfishly based on each agent’s only competence. This relationship benefits the entire process.
8. AlphaGo
AlphaGo is an RL algorithm created by Google DeepMind and implemented to play the Go board game. It was the first algorithm capable of defeating a professional Go player on a full–size 19 × 19 game board [54]. In a series of best–of–five games in March 2016, the AlphaGo algorithm won the title against professional player Lee Sedol. Although Sedol won the fourth game, he resigned in the third game, making the final score 4–1 in favor of AlphaGo.
AlphaGo employs the Monte Carlo tree search algorithm (MCTS), combining branching machine learning approaches with intensive human and computer games training. DL networks are also utilized, getting as input a description of the game board in every state s, passing it through different layers (hidden layers). Subsequently, the policy network chooses the next optimal action (for the computer player), and the value network (or evaluation) estimates the value of the current state s.
AlphaGo Zero is a recent AlphaGo development, which, unlike AlphaGo that learned to play professionally through thousands of games with novice and professional players, is learning by playing against itself. In just a few days, the agent accumulated thousands of years of human experience with the assistance of the best player in the world, none other than AlphaGo itself. AlphaGo Zero succeeded quickly and outperformed all of its previous versions.
There is a single NN during the game that knows nothing about Go at first. Eventually, the algorithm ends up playing with itself, combining the DNN with a robust NN search algorithm regulated and updated to assess movements. The updated network is combined with the same algorithm once more, and a stronger Zero emerges. This process is repeated many times, with each iteration increasing the system’s performance by a small percentage. Furthermore, Zero employs a single NN that combines the logic of the two policies and value networks presented in the initial implementations. As a result of these changes, Zero evolved in terms of algorithmic power and better computing power management.
9. OpenAI Five in DOTA2
Dota 2 is a MOBA game that is known, among other games in the same genre, for being a highly challenging video game, due to the large number of moves the player has in their hands (action space), the various calculations needed, and the multiple goals during a match. The players, such as the units, are only visible in some areas of the world, making the environment partially visible (partial observability). This deep and nuanced style of play necessitates a steep learning curve. In 2019, OpenAI Five [55] succeeded in overcoming this difficulty by winning the OpenAI Five Finals in a five agents vs. the world champions match. Five consisted of five NNs that observe the game environment as a list of 20,000 numbers (input) encoding the observable field of play and function by selecting moves from an 8–number list [56].
The game’s general concept was based on the fact that the player is self–taught, beginning with random parameters and using a modified version of the PPO algorithm [55]. Each of the five team’s NNs is a single long short–term memory (LSTM) network [57] with 1024 units that obtains game status through a Bot API and exports moves with semantic value. For example, this value is counted in the number of ticks (unit of measurement used in game production that expresses how long one step takes) required to postpone the given motion in the X and Y coordinates surrounding the section where the movement will be performed, and so on. Each NN calculates its own movements, which means each agent makes its own decisions based on the current match goal and whether a teammate agent requires assistance. OpenAI Five was able to interpret conditions considered risky, such as the drop of ammunition in the region where the agent was put, using sufficient reward arrangement (reward shaping) and taking into account measurements, such as the fall and its health. The system was able to adapt to advanced gaming practices such as team play pressure on the opponent’s area (5–hero push) and stealing vital items (bounty runes) from the opponent after several days of practicing, with 80% of the time spent playing against himself and 20% against previous models. In a strategy setting such as Dota 2, the idea of exploration is also challenging. During training, properties such as health, speed, and the agent’s initial level were obtained at random values to force the agents to explore the environment strategically.
10. AlphaStar in StarCraft II
StrarCraft II is also an real time strategy game of high complexity and competitiveness, is regarded as one of the games with the most hours of esports competitions, and is a significant challenge for AI research teams. There is no right technique when it comes to being playful. The environment is again partially observable, while the agent must explore it. The amount of space available for movement is determined by two factors. Numerous manageable components result in many combinations [58].
Google’s DeepMind unveiled its 2019 AlphaStar implementation, the first AI to defeat Grzegorz Komincz, one of the best StarCraft II players, in a series of experimental races held on 19 December 2019, under professional classification match conditions, with a score of 5–0 in favor of AlphaStar [13].
This particular AI employs DL, RL techniques, and DNNs and accepts raw game data as input in the StarCraft II setting. These data are interpreted as a list of available sections and properties, and it outputs a collection of commands that comprise the movement performed at each time level. DeepMind called this architecture Transformer, which is based on attention mechanisms distributed using recurrent neural networks (RNNs) and CNNs [55]. The Transformer’s body utilizes one deep core LSTM, a strategy of self–regulating tactics, followed by an indicator network [59] and an approximation of an assessment aggregate value [60].
AlphaStar employs a multidisciplinary algorithm preparation. The network was initially trained using supervised learning by observing people playing games and imitating their short–term and long–term strategies. The training data were then used to power a multi–agent framework. For this technique, they conducted 14 consecutive days of confrontations with competing agents in a competition consisting solely of AI agents, where new entrants, who were branches of existing agents, were dynamically introduced. Each agent was given the goal of defeating either one or a group of opponents. The agents learned from the matches, which enabled them to explore a vast space of strategies related to the way StarCraft II plays while also ensuring that each contestant worked effectively against stronger strategies and did not forget how to face the weakest older strategies.
11. Other Recent Notable Approaches
In paper [61], the authors proposed a deep reinforcement learning architecture for playing text–based adventure games. The game state is represented as a knowledge graph that is learned during exploration and is used to prune the action space, resulting in more efficient decision–making. The authors introduced three key contributions to this field: (1) using a knowledge graph to effectively prune the action space, (2) a knowledge–graph DQN (KG–DQN) architecture that leverages graph embedding and attention techniques to determine which portions of the graph to focus on, and (3) framing the problem as a question–answering task, where pre–training the KG–DQN network with existing question–answering methods improves performance. They demonstrated that incorporating a knowledge graph into a reinforcement learning agent results in faster convergence to the highest reward, compared to strong baselines.
LeDeepChef [62] is a deep reinforcement learning agent aimed at showcasing its generalization abilities in text–based games. The design of the agent involved the use of an actor–critic framework and a novel architecture that evaluates different elements of the context to rank commands. The agent’s structure is recurrent, allowing it to keep track of past context and decisions. The agent was optimized for generalization to new environments through abstraction and a reduction in the action space. The agent also has a module that predicts missing steps in a task, trained on a dataset based on text–based recipes. As a result, LeDeepChef achieved a high score in the validation games and placed second in the overall competition of Microsoft Research’s First TextWorld Problems challenge, which focuses on language and reinforcement learning.
This entry is adapted from the peer-reviewed paper 10.3390/app13042443
This entry is offline, you can click here to edit this entry!