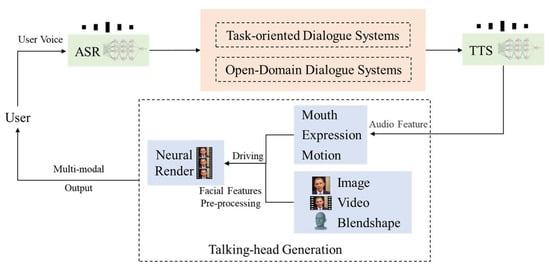
With the rapid development of artificial intelligence technology, virtual humans have been continuously applied in various scenarios, including virtual anchors, virtual customer service, and online education. In human–computer interaction, there is an anthropomorphic digital human who can quickly establish contact with users and improve user experience. Simultaneously, multimodal human–computer interaction is one of the application directions of virtual humans. The system aims to generate interactive objects with natural characteristics using deep learning models, including speech recognition, dialogue system, text-to-speech, and virtual human video synthesis. Among them, virtual human video generation is mainly divided into 2D/3D facial reconstruction, talking-head generation, body movements, and human movements. Meanwhile, in the talking-head generation task, we need to consider the audition consistency of lip shapes and facial attributes, such as facial expressions and eye movements.
In the research of talking-head generation, audio-driven lip synthesis is a popular research direction by inputting the corresponding audio and any mesh vertex, facial image, or video to synthesize the lip-synced talking-head video. In other words, the model dynamically maps the lower-dimensional speech or text signal to the higher-dimensional video signal. Note that text-driven lip synthesis is a natural extension of the task.
2. Human–Computer Interaction System Architecture
Based on artificial intelligence technologies, such as natural language processing, voice, and image processing, the system pursues multimodal interaction with low-latency and high-fidelity anthropomorphic virtual humans. As shown in Figure 1, the system is mainly composed of four modules: (1) the system converts the voice information input by the user into text information through the automatic speech recognition (ASR) module; (2) the dialogue system (DS) takes the text information output by the ASR module as input; (3) the text-to-speech (TTS) module converts the text output by the DS into realistic speech information; (4) the talking-head generation module preprocesses the picture, video, or blendshape as the model input to extract its facial features. Then, the model maps the lower-dimensional voice signal by the TTS module to the higher-dimensional video signals, including the mouth, expression, motion, etc. Finally, the model uses the rendering system to fuse the features and multimodal output video and displays it on the user side.
Figure 1. The system architecture of multimodal human–computer interaction.
2.1. Speech Module
The ASR and TTS of the speech module correspond to the human hearing and language function, respectively. After decades of research, speech recognition and text-to-speech synthesis have been widely used in various commercial products. We use the PaddleSpeech [
32], a code, open-sourced by Baidu. One model can complete both ASR and TTS tasks, which greatly reduces the complexity of model deployment and enables better collaboration with other modules. In addition, we can also choose API services provided by commercial companies, such as Baidu, Sogou, iFLYTEK, etc.
2.2. Dialogue System Module
Our dialogue system module needs to have the ability to have multiple rounds of dialogue. The system needs to answer domain-specific questions and meet users’ needs to chat. As shown in Figure 1, the question is passed to the dialogue module after the user’s voice passes through the ASR. The dialogue module must retrieve or generate matching answers from the knowledge base according to the user’s question. However, it is impossible to rely entirely on the model to generate answers in a specific domain multi-turn dialogue. In some scenarios, to better consider the context information, the above information will be aggregated to identify the user’s intent and return the answer in the way of QA.
2.3. Talking-Head Generation
The facial appearance data of the talking-head generation module mainly comes from real-person photos, videos, or blendshape character model coefficients. Taking video as an example, we first perform video preprocessing on these facial appearance data and then map the audio signal of TTS in Figure 1 to higher-dimensional signals such as human face lip shape, facial expression, and facial action, and finally, use a neural network. The model performs video rendering and outputs multimodal video data.
In human–computer interaction, a timely response can improve user experience. However, the time delay of the whole system is equal to the sum of the time consumed by each data processing module. Among them, the voice module and the dialogue module have been commercialized by a wide range of users, which can meet the real-time requirements of human–computer interaction. At present, it takes a long time for the talking-head generation model to render and output multimodal video. Therefore, we need to improve the data processing efficiency of the talking-head generation model, reduce the rendering time of the multimodal video, and reduce the response time of the human–computer interaction system extension. Although the virtual human has achieved low-latency response in some commercial products such as JD’s ViDA-MAN [
33], etc., the long production cycle, high cost, and poor portability are also problems that cannot be ignored.
3. Talking-Head Generation
Talking-head video generation, i.e., lip motion sequence generation, aims to synthesize lip motion sequences corresponding to the driving source (a segment of audio or text). Based on synthesizing the lip motion, the video synthesis of the talking head also needs to consider its facial attributes, such as facial expressions and head movements.
In the early talking-head video generation methods, researchers mainly used cross-modal retrieval [
3] and HMM-based methods [
34] to realize the dynamic mapping of driving sources to lip motion data. However, these methods have relatively high requirements on the application environment of the model, visual phoneme annotation, etc. Thies et al. [
3] introduced an image-based lip-motion synthesis method, which generates the real oral cavity by retrieving and selecting the optimal lip shape from offline samples. However, the method is based on text–morpheme–morpheme. The retrieval of the map does not truly take into account the contextual information of the speech. Zhang et al. [
30] introduced key pose interpolation and smoothing modules to synthesize pose sequences based on cross-modal retrieval and used a GAN model to generate videos.
Recently, the rapid development of deep learning technology has provided technical support for talking-head video generation and promoted the vigorous development of talking-head video generation methods. Table 1 summarizes the representative works on talking-head video generation.
- (1)
-
2D-based methods.
In 2D-based methods, talking-head generation mainly used landmarks, semantic maps, or other image-like representations to solve the problem, which dates back to Bregler et al. 1997 [
4]. In talking-head video generation, Chen et al. [
17] used landmarks as an intermediate layer for mapping from low-dimensional audio to high-dimensional video and divided the whole method into two stages. Chung et al. [
9] used two decoders to decouple the voice and the speaker identity to generate the video without the influence of the speaker identity. Lip synthesis can also use image-to-image translation to generate [
35] an extension of this method. Zhou et al. [
16] and Song et al. [
15] use a combination of separate audio-visual representations and neural networks to optimize the synthesis.
- (2)
-
3D-based methods.
Early 3D-based approaches pre-built 3D models of specific people and then rendered the models. Compared to 2D methods, this method can have better control over motion. However, the construction cost of such a 3D model is relatively high, and the effect of changing a new identity cannot be guaranteed. In synthesizing Barack Obama’s videos, these works [
8,
11] synthesize realistic speaking facial videos by pre-constructing 3D facial models and learning to map audio sequences to video sequences to drive the model. In addition, there are many generative talking-head models based on 3DMM parameters [
10,
19,
20,
23], and models, such as blendshape [
19], flame [
36], and 3D mesh [
37], are used with the audio as model input. Among them, VOCA [
16] uses the blendshape of the character’s head to create the model. Meshtalk [
37] uses the neutral face template mesh as the basis to generate the talking-head video. However, the model with intermediate parameter 3DMM brings a certain loss of information. Moreover, VOCA is an independent 3D talking-head synthesis model that can capture different speech styles, while Meshtalk can parse out the absolute latent space of audio-related and audio-independent facial movements.
Table 1. The main model of talking-head generation in recent years. ID: The model can be divided into three types: identity-dependent (D), identity-independent(I), and hybrid(H). Driving Data: Audio(A), Text(T), and Video(V).
Most current methods reconstruct 3D models from training videos directly. NVP (neural voice puppetry) has since designed the Audio2ExpressionNet and the 3D model of the independent identity. NeRF (Neural Radiance Fields) [
38,
39,
40,
41], which simulates implicit representation with MLP, can store 3D spatial coordinates and appearance information and be used for large-resolution scenes. To reduce information loss, AD-NeRF [
25] trains two NeRFs for head and drive rendering of talking-head synthesis and obtains good visual effects. Many models require unrestricted universal identity and speech as input in practical application scenarios. Prajwal et al. [
22,
42] take any unidentified video and arbitrary speech as input to synthesize unrestricted talking-head video.
4. Datasets and Evaluation Metrics
4.1. Datasets
In the era of artificial intelligence, the dataset is an important part of the deep learning model. At the same time, data sets also promote the solution of complex problems in the field of virtual human synthesis. However, in practical applications, there are few high-quality annotation data sets that cannot meet the training needs of the speech synthesis model. Moreover, many institutions/researchers are affected by the deepfake technical ethics issues, which increase the difficulty of obtaining some data sets. For example, only researchers, teachers, and engineers from universities, research institutions, and enterprises are allowed to apply, and students are prohibited from applying. In Table 2, we briefly highlighted the data sets commonly used by most researchers, including statistics and download links.
Table 2. Summary of talking-head video datasets.
The GRID [
68] dataset was recorded in a laboratory setting with 34 volunteers, which is relatively small in a large dataset, but each volunteer spoke 1000 phrases for a total of 34,000 utterance instances. The phrase composition of the dataset conforms to certain rules. Each phrase contains six words, randomly selected from each of the six types of words to form a random phrase. The six categories of words are “command”, “color”, “preposition”, “letter”, “number”, and “adverb”. Dataset is available at
https://spandh.dcs.shef.ac.uk//gridcorpus/, accessed on 30 December 2022.
LRW [
69], known for various speaking styles and head poses, is an English-speaking video dataset collected from the BBC program with over 1000 speakers. The vocabulary size is 500 words, and each video is 1.16 s long (29 frames), involving the target word and a context. Dataset is available at
https://www.robots.ox.ac.uk/~vgg/data/lip_reading/lrw1.html, accessed on 30 December 2022.
LRW-1000 [
70] is a Mandarin video dataset collected from over 2000 vocabulary subjects. The purpose of the dataset is to cover the natural variation of different speech modalities and imaging conditions to incorporate the challenges encountered in real-world applications. There are large variations in the number of samples in each category, video resolution, lighting conditions, and attributes such as speaker pose, age, gender, and makeup. Note: the official URL (
http://vipl.ict.ac.cn/en/view_database.php?id=13, accessed on 30 December 2022.) is no longer available, you can go to the paper page for details about the data and download the agreement file here (
https://github.com/VIPL-Audio-Visual-Speech-Understanding/AVSU-VIPL, accessed on 30 December 2022.) if you plan to use this dataset for your research.
ObamaSet [
8] is a specific audio-visual dataset that focuses on analyzing the visual speech of former US President Barack Obama. All video samples are collected from his weekly address footage. Unlike previous datasets, it only focuses on Barack Obama and does not provide any human annotations. Dataset is available at
https://github.com/supasorn/synthesizing_obama_network_training, accessed on 30 December 2022.
VoxCeleb2 [
71] is extracted from YouTube videos, including the video URL and discourse timestamp. At the same time, it is currently the largest public audio-visual data set. Although this dataset is used for speaker recognition tasks, it can also be used to train a talking-head generation model. However, the dataset needs to apply to obtain the download permission to prevent misuse of the dataset. The URL for the permit application is
https://www.robots.ox.ac.uk/~vgg/data/voxceleb/, accessed on 30 December 2022. Because the dataset is huge, it requires 300 G+ storage space and supporting download tools. The download method is available at
https://github.com/walkoncross/voxceleb2-download, accessed on 30 December 2022.
VOCASET [
19] is a 4D-face dataset with approximately 29 min of 4D face scans, synchronized audio from 12-bit speakers (six women and six men), and recorded 4D-face scans at 60 fps. As a representative high-quality 4D face-to-face audio-visual dataset, Vocaset greatly facilitates the research of 3D VSG. Dataset is available at
https://voca.is.tue.mpg.de/, accessed on 30 December 2022.
MEAD [
44], the Multi-View Emotional Audio-Visual Dataset, is a large-scale, high-quality emotional audio-video dataset. Unlike previous datasets, it focuses on facial generation for natural emotional speech and takes into account multiple emotional states (eight different emotions on three intensity levels). Dataset is available at
https://wywu.github.io/projects/MEAD/MEAD.html, accessed on 30 December 2022.
HDTF [
51], a large in-the-wild high-resolution audio-visual dataset, stands for the High-definition Talking-Face Dataset. The HDTF dataset consists of approximately 362 different videos of 15.8 h. The resolution of the original video is 720 P or 1080 P. Each cropped video is resized to 512 × 512. Dataset is available at
https://github.com/MRzzm/HDTF, accessed on 30 December 2022.
4.2. Evaluation Metrics
The evaluation task of talking-head video generation is an open problem that requires the evaluation of generation results from both objective and subjective aspects. Chen et al. [
72] reviewed several state-of-the-art talking-head generation methods. They designed a unified benchmark based on their properties. Subjective evaluation is often used to compare the generated content’s visual quality and sensory effects, such as whether lip-sync audio is in sync with the picture. Due to the high cost of subjective factors in the evaluation process, many researchers have attempted to quantitatively evaluate generated content using objective metrics [
22,
28,
29,
52]. These metrics can be classified into three types: visual quality, audio-visual semantic consistency, and real time based on quantitative model performance evaluations.
Visual Quality. Reconstruction error measures (e.g., mean squared error) are a natural way to evaluate the quality of generated video frames. However, the reconstruction error only focuses on the pixel alignment, ignoring the global visual quality. Therefore, existing works typically employ the peak signal-to-noise ratio (PSNR), structural similarity index metric (SSIM) [
29,
73], and learned perceptual image patch similarity (LPIPS) [
74] to evaluate the global vision of generated image quality. Since metrics, such as PSNR and SSIM, cannot explain human perception well, and LPIPS is closer to human perception in visual similarity judgment, it is recommended to use LPIPS to evaluate the visual quality of generated content quantitatively. More recently, Prajwal et al. [
22] introduced the Fréchet inception distance (FID) [
75] to measure the distance between synthetic and real data distributions, as FID is more consistent with human perception assessments.
Audio-visual semantic consistency. The semantic consistency of the generated video and the driving source mainly includes audio-visual synchronization and speech consistency. For audio-visual synchronization, the landmark distance (LMD) [
12] computes the Euclidean distance of lip region landmarks between the synthetic video frame and the ground truth frame. Another synchronization evaluation metric uses SyncNet [
7] to predict the offset of generated frames and ground truth. For phonetic coherence, Chen et al. [
74] proposed a synchronization evaluation metric, the Lip-Reading Similarity Distance (LRSD), which can evaluate semantically synchronized lip movements.
Real-time performance. The length of time to generate the talking-head video is an important indicator for existing models. In the practical application of human–computer interaction, people are very sensitive to factors such as waiting time and video quality. Therefore, the model should generate the video as quickly as possible without sacrificing visual quality or the coherence of audio-visual semantics. NVIDIA [
10] uses a deep neural network to map low-dimensional speech waveform data to high-dimensional facial 3D vertex coordinates and uses traditional motion capture technology to obtain high-quality video animation data to train the model.
Delayed Talking-Head Synthesis Model. Ye et al. [
6] presented a novel, fully convolutional network with DCKs for the multimodal task of audio-driven talking-face video generation. Due to the simple yet effective network architecture and the video pre-processing, there is a significant improvement in the real-time performance of talking-head generation. Lu et al. [
76] present a live system that generates personalized photorealistic talking-head animation only driven by audio signals at over 30 fps. However, many studies ignore real-time performance, and we should consider it as a critical evaluation metric in the future.
Human–computer interaction is a method for the future development of virtual humans. Unlike one-way information output, digital human needs to have multimodal information such as natural language, facial expression, and natural human-like gestures. Meanwhile, it also needs to be able to feedback on high-quality video in a short time after a given voice request [
33,
77].
However, in generating high-quality and low-latency digital human video, many researchers do not take real time as the evaluation index of the model. Hence, many models generate videos too slowly to cover the application requirements. For example, to generate 256 × 256 resolution facial video without background, ATVGnet [
17] takes 1.07 s, You Said That [
35] takes 14.13 s, X2Face [
78] takes 15.10 s, DAVS [
16] takes 17.05 s, and 1280 × 720 resolution video with background takes longer. Although it only takes 3.83 s for Wav2lip [
22] to synthesize a video with a background, the definition of the lower part of the face is lower than that of other areas [
6].
Many studies have attempted to establish a new evaluation benchmark and proposed more than a dozen evaluation metrics for virtual human video generation. Therefore, the existing evaluation metrics for virtual human video generation are not uniform. In addition to objective indicators, there are also subjective indicators, such as user research.