Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
In today’s learning environment, e-learning systems are becoming a necessity. A competency-based student portfolio system is also gaining popularity. Due to the variety of e-learning systems and the increasing mobility of students between different learning institutions or e-learning systems, a higher level of automated competency portfolio integration is required.
- e-learning
- competencies
- automation
1. Introduction
To provide an effective learning experience in the learning process, the balance between a student’s already-known material and newly developed skills must be taken into account. Learning programs are oriented to build sequential competencies between different courses. It is designed in a generalized way, assuming all students will achieve the planned level of dedicated competencies. However, different students’ abilities, learning experiences, and other factors affect the variance of competencies. Therefore, personalized competency level tracking and learning path planning are preferred to provide a high user learning experience and effectiveness.
Long-term studies and competency-based e-learning allow the system to collect a student’s competency portfolio and tailor the learning path to meet the student’s needs. For students who lack the required competencies and additional material, consultations may be provided, while students with higher-developed competencies can follow an adapted learning path to skip some topics and avoid repetitively learning already mastered competencies. Additionally, if a student joins only one course or transfers from another learning institution to the study program, his or her competency portfolio must be mapped to the competencies in the learning system. In student mobility programs (such as Erasmus+), this is a problem. The need for administrative and mapping documents led to the “Erasmus without papers” project [1], where student and course data are shared in one linking system between different institutions. It simplified the administration but additional manual work is needed for credit transfer anyway [2]. Therefore, automated credit transfer solutions, based on natural language processing applications that analyse course overlap, were proposed during the last year [3]. Based on topic overlap analysis, this solution ignores competency or outcome mapping. Competency mapping is needed to implement reverse credit transfer [4] and assure that the study process is focused on students’ competencies, not just coverage of students’ knowledge topics. But this task is not easy as no common standard for competencies definition exists and each educational institution’s e-learning system uses its preferred, individually selected competencies. As well, the landscape of the competencies in each area might change over time.
There are two main methods of mapping student competencies: testing the students’ competencies at the time of admission, and mapping each competency between the used competency system and the one shown in students’ past course descriptions or exported from e-learning systems. Both methods are time-consuming. A formative assessment requires effort for preparation (many tasks need to be completed to evaluate all inspected competencies), students are required to take many tests to evaluate different competencies, and the results of the tests must be reviewed by the testing institution because not all competencies can be evaluated by automated testing. Methods to reduce the formative assessment test size for the student by applying adaptive knowledge testing exist [5]. This is helpful in formative testing during the course, however, in the case of long-term study programs where students from other institutions are taking part later in the program, it is still too messy for a full mapping of students and program competencies. Additionally, mapping student and study program or e-learning system competencies based on formal documents and defining students’ already gained competencies eliminates the need for testing but requires document analysis. Multiple persons, representing different study areas, capable of understanding the differences and similarities between study outcomes, which sometimes are expressed in relatively short texts, usually must do the analysis.
Both of these two methods for mapping student competencies to study programs or e-learning system competencies are complicated to apply and time-consuming. Moreover, student mobility, convergence, and retraining are becoming more prevalent, and a simplified solution for integrating student competencies portfolios is needed. Therefore, the objective of the paper is to simplify the mapping of students’ competency portfolio-related course competencies to e-learning system-used competencies by proposing an automated tool for mapping text-written competencies. This requires answering the question of how efficient automated text processing can be for automatic mapping of student-gained and e-learning system-used competencies as well as estimating the possible workload reduction for manual mapping.
2. Automation of Text-Written Competency Mapping
Competencies in e-learning environments, education systems, and student profiles are usually stored in text format. Formal structures for competency descriptions are not popular. Text-based descriptions are more flexible and allow a better presentation of competency for human beings. Linking student-passed courses and descriptions of the courses can be automated with the help of data extraction methods, existing programming technologies or even APIs, designed in the “Erasmus without papers” system [1]. While reading and comparing one competency to another from the analyzed course and the one student passes, gathered from other systems, additional interpretations might be needed. Therefore, to replace human work for competency mapping, automated text analysis solutions are needed.
For competency comparison, we express each competency text as a list of competency levels and competency topics (see Figure 1). The competency level is associated with verb phrases in the sentence and its matching to Bloom’s taxonomy. The Bloom taxonomy defines the key verbs, indicating different levels of proficiency. The use of this metric can also be applied to numerical comparisons. Meanwhile, topic extraction is associated with noun phrases. The list of noun phrases is extracted from the sentence for later text similarity estimation to understand the topic similarity of different competencies. As each sentence can have internal sub-sentences inside of it, the sentence is analyzed recursively for each sub-sentence as part of the initial sentence. For simplification, the verb and noun phrases of the main and sub-sentences are stored in the same lists, regardless of whether they are in the main sentence or not.
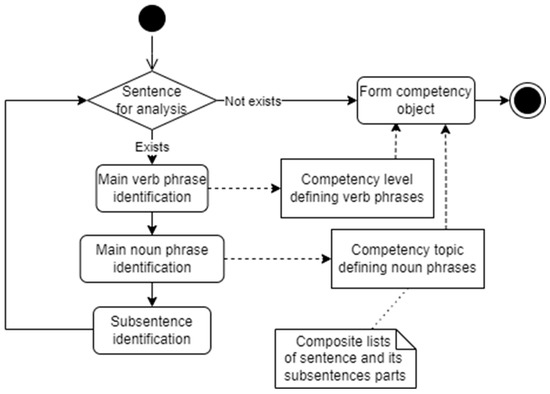
Figure 1. Main schema of competency text expression for structured competency object.
The verb and noun phrases are extracted from the sentence using natural language processing methods. The existing corpus and model are used to label the sentence so that it can be expressed as a tree of parts-of-speech (POS) elements (see Figure 2). The tree structure allows easier identification of related parts of the sentence. The verb phrases are identified in the sentence and marked in multiple labels (all starting with the letter V—VP, VB, VBG, etc.), depending on the form of the verb. However, different verb forms can be taken into account. Any form of the verb will be searched in the sentence, while for further usage it will be converted into the standard form. For noun phrase identification, the highest-level noun phrase element (marked with a label NP) is used, combining multiple words as a composite topic. Sub-sentences are marked with the label S. The text of the sub-sentence is analyzed recursively with the same idea as described above.
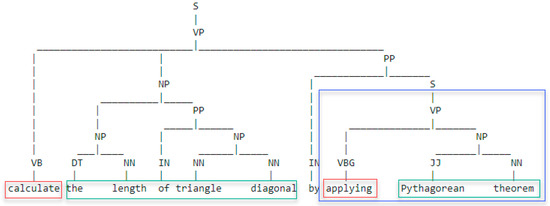
Figure 2. Example of a competency sentence, where red labeled word indicates the verbs, green labeled set of words—noun phrases, and blue labeled block—sub-sentence, which will be recursively analyzed to extract the internal verb and noun phrases.
The same verb and noun phrase identification principle is applied to building a competency tree from a list of competencies [24]. Compared to the existing solution that used data clustering and similarity to estimate competency relationships, in this paper fuzzy logic is employed for mapping competencies.
Fuzzy logic is useful when discrete rules are not easy to express, and ranges between different categories might vary. In the case of competency mapping, one discrete threshold for competency level and topic similarity could cause issues and inconsistency between similar situations. Therefore, after experimenting with Bloom taxonomy level difference and text similarity metrics, experts defined fuzzy, which was applied for fuzzification of those two metrics. The sets for input data are presented in Figure 3 and Figure 4. According to the text similarity method (which involves embedding the noun phrases within one sentence utilizing SentenceTransformer “all-MiniLM-L6-v2“ model and applying a cosine search to measure the similarity between two embedded datasets), a similarity below 50% was considered insufficient to estimate the topic matching. By contrast, an 80% similarity was identified as adequate for topic matching. The range between those two ranges is used for the transition between the sets. The linear transition was used to build trapezoid member functions. Those values were estimated by analyzing a separate dataset, containing a list of topics the computer science study programs should cover (defined by governmental institutions). The dataset for fuzzy function definitions was not the same as the validation data but is partly related since the examples for the validation of the model are mostly from computer science study programs.
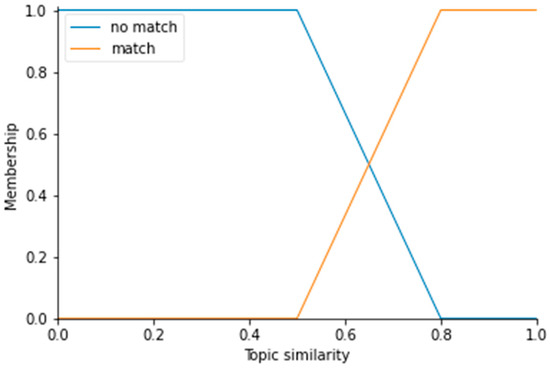
Figure 3. Fuzzy sets for topic similarity definition to matching (labeled as “match”) and not matching (labeled as “not match”).
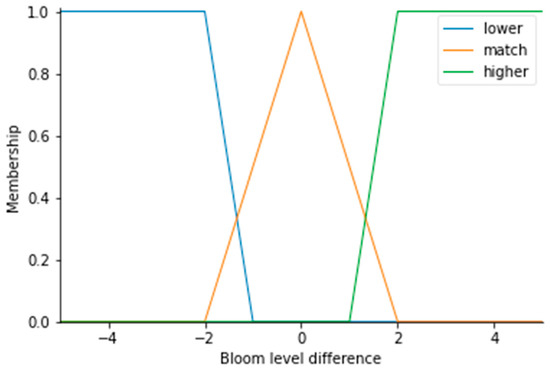
Figure 4. Fuzzy sets for Bloom taxonomy verb level difference definition to matching lower or higher level between the study/course competency and the student competency.
Meanwhile, the Bloom taxonomy verb level difference should be equal to 0 if it is matching, but a variation of 2 levels below and above is possible. Therefore, the fuzzy sets, expressed in Figure 4, were used to define the ranges for three possible sets. Lower and higher competency levels are expressed as trapezoid member functions while matching competency levels are presented as triangle member functions.
The fuzzy variable values can be estimated using Bloom’s taxonomy verb level difference, topic similarity, and fuzzy sets. To get the output, six fuzzy rules were used to define all possible combinations of inputs and present the associated output value. The fuzzy rules and their rationality are presented in Table 1.
Table 1. Fuzzy rule definition.
| Input | Output | Rationale behind the Output Class Assignment 1 |
|
|---|---|---|---|
| Topic Similarity |
Bloom Level Difference | Competency Matching Class | |
| “match” | “higher” | “redundant” | The topic matcher but the student has a higher level of competency; therefore, his or her competencies are even redundant. |
| “match” | “match” | “match” | The topic and competency level match; therefore, the competency fully matches. |
| “match” | “lower” | “partial” | The topic matches, but the student has a lower level of competency; therefore, the competencies match just partially. |
| “no match” | “higher” | “partial” | The competency level is higher; therefore, the topic description can use different terms; therefore, the partial match should be identified. |
| “no match” | “match” | “not related” | The competency level matches, but the topic is different; therefore, the competencies are not related. |
| “no match” | “lower” | “not related” | The student has a lower level of competency and is in a different topic; therefore, the competencies are not related. |
1 Rules were defined by a group of experts in pedagogy.
Accurate mapping of study program/course competencies to students’ competencies can vary. In e-learning systems used for self-study, the accuracy of the mapping may be less critical than the student’s behavior, which may reveal missing competencies and enable the student to demonstrate mastery of unmapped competencies. Meanwhile, for formal education, more accurate mapping might be required, to assure the needed competencies are already achieved. Therefore, for defuzzification, fuzzy output classes are expressed as fuzzy sets, reflecting the need for revision priority (see Figure 5).
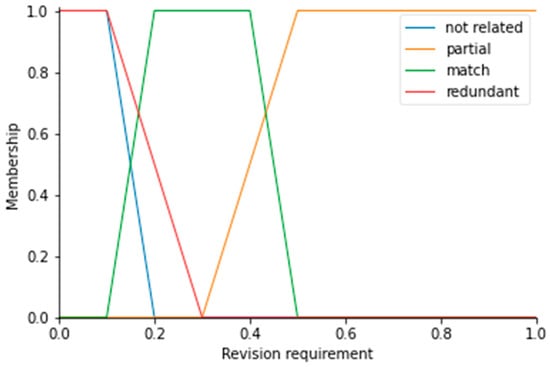
Figure 5. Fuzzy sets for defuzzification to estimate the priority of mapping manual revision.
The received metric (revision requirement) defines a score, illustrating the need for manual revision. Taking into account the need for mapping accuracy, the metric can be ignored, or it can be used to order the automated mapping results for manual revision. Mapping results of partial matches are given the highest priority. The level of matching should be manually determined. The second factor in revision is matching cases. Those are used to make sure some inaccuracies are not present, whereas redundant and not related competencies have the lowest need for manual revision. In the defuzzification phase, all the rules and centroid methods are applied to determine a crisp value. In comparison to other methods (smallest of maximum, mean of maximum, largest of maximum, bisector of area), the Center of Gravity method was selected because it affected the crisp value and proportion of the sets as well.
For example, if we have two competencies, “Use Boolean algebra knowledge and circuit design skills” and “Understand the basics of logical operators”, the Bloom level difference is 0, as “use” and “understand” belong to the same level of Bloom’s taxonomy. Therefore, the Bloom level value falls into the “match” set with a score of 1.0. Meanwhile the similarity score of the topics “boolean algebra knowledge and circuit design skills” and “basics of logical operators” is 0.651. Based on the similarity value, it gains the fuzzy values of 0.504 for “match” and 0.496 for “no match”. Based on the fuzzy logic, the “match” class should be assigned to the mapping of those two competencies. However, it is very close to a “partial” match, as the topic match was not equal to 100%. Fuzzy logic brings more details to the final outcome as opposed to discrete division into classes. At the same time, the revision requirements score for this mapping can be estimated and, in this case, is equal to 0.561 as the center of the fuzzy sets “match” and “partial” is distributed close to this value (black line in Figure 6).
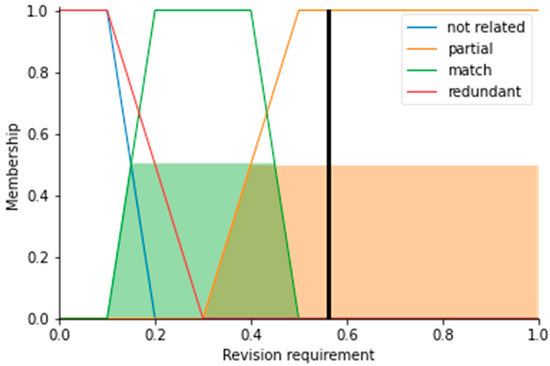
Figure 6. Example of fuzzy logic application for two selected example competencies.
This entry is adapted from the peer-reviewed paper 10.3390/su142416544
This entry is offline, you can click here to edit this entry!