Data mining (sometimes called knowledge discovery) is the process of analyzing and summarizing data into useful information which can be used to understand common features, the origin of data and to extract hidden predictive information. Data mining is used in science, engineering, modeling and analysis of financial markets.
- data analysis
- object-oriented design
- linear regression
1. Data Mining with DMelt
DataMelt contains many Java packages for data mining. Here we will list some of them:
- Datumbox Machine Learning Framework (WWW). It includes a large number of machine learning algorithms & statistical methods and to be able to handle large sized datasets. It includes classification, clustering analysis, regression, PCA etc.
- Smile Java libraries
- DMelt from the jhplot package that allows visualization of data
- Several neural networks, such as Baysian, Joone, Recun, Neuroph Encog
Data mining in DataMelt are covered many sections of this online manual
- Data classification problems are discussed in DMelt:Statistics/5_Statistical_classification and DMelt:AI/6_Classification_problem.
- Machine learning is discussed in multiple sections
2. Basic Data Mining with DMelt
In this article we will discuss a free data-analysis framework called https://datamelt.org/ DMelt] which can be used to facilitate data analysis and data mining. It is a great program for scientists, engineers and students who need numerical and statistical computations, data and function visualization and even symbolic computation. DMelt is a 100% Java package, which means it is fully object-oriented and runs on any Java Virtual Machine regardless of computer architecture. Another notable feature: it uses the Python language to call Java classes for numerical and statistical computation and for data and math visualization. To be more exact, DMelt fully unitizes the power of Jython which is an implementation of the Python programming language in Java. Such a merge of Java and Jython is not accidental. According to the Tiobe Community Programming Community Index, Java is the world’s most popular programming language. Python is among popular scripting languages widely used in science, engineering and education and it is the fastest growing programming language of 2010 according to the TIOBE index. DMelt uses the Python language due to its short and clear syntax which is handy for calling numerical Java libraries. As the result, data-analysis programs written in such approach are sort and clear, while still utilizing the full strength of Java. This is somewhat different from only-GUI type of programs which typically require walking through various menu and sub-menu to perform certain tasks. In the DMelt approach, one can write short commands using Python to perform computations with arbitrary logic which can be changed at runtime. Such approach is also important for repetitive tasks when analysis code, once saved into a file, can be executed multiple times depending on different inputs (which is a tedious task for only-GUI approach). In some sense, the scripting approach to data mining is similar to the R-programming language The R statistics, but the difference is that DMelt uses Jython for scripting, using the full advantage of its object-oriented design and the full power of Java. Saying this, one should also keep in mind that one can always use a pure Java approach to develop data-mining analysis programs since all numerical and graphical libraries of DMelt are implemented in Java. Or one can use an alternative scripting language, such as BeanShell or the Java scripting API shipped with the javax.script package. Finally, one can enjoy with the powerful Eclipse or Netbeans IDEs while doing scientific programming using the DMelt libraries.
3. Mining tutorial: prediction interval
In this tutorial we will illustrate the full strength of the DMelt for data mining using the Jython language. We show how to analyze multidimensional data, display data on 2D and 3D canvases, plot a function and how to perform a full-scale linear regression analysis.
3.1. Creating Data Sample
Let us assume that we have a matrix of numbers organized as
# this is a multi-dimensional data 1 2 3 4 5 6 7 8 .......
(the numbers of rows and columns can be arbitrary). The goal of this tutorial is to analyze this data and to extract some useful information. The numbers can be stored in a file on a file system or can be located on the Web.
First, make sure that the Java Virtual Machine [1] is installed. Then download DMelt package, unzip it and run "dmelt.sh" (Linux/Mac) or "dmelt.bat" (Windows). If you do this for the first time, Jython will create a cache directory with all available Java packages. Jython needs to build a file-based database documenting all Java classes visible for the Java Virtual Machine which simplify code (no need to specify every Java class in the import statements) and to speed up the code execution.
DMelt comes with a powerful IDE with a code assist based on the Java reflection technology. It also has a Jython shell which helps to develop a data-mining analysis code fully interactively. For this tutorial, we will use the DMelt editor. One can also use the Jython shell which is built inside the DataMelt IDE. In the later case, one can see the program response immediately after entering commands line by line.
A first step is to read the data into a DMelt data container designed to keep such data and do some manipulation. Our preference is to read a data from a prepared file located on the Web. In this tutorial we will use the Jython shell (a window called "JythonShell" locate below the main editor). Make it bigger for continence and type, entering the code line by line and pressing [Enter]:
from jhplot import * pn=PND('data','http://datamelt.org/examples/data/pnd.d') print pn.toString()
Here we create a PND object from the file "pnd.d" stored on the Web and print it for checking. The file has exactly the same structure as shown before, i.e. each row is separated by a new line. From now on, we use the Python syntax to print a string returned by the method "toString()". Alternatively, one can use "pn.toTable()" method to display all numbers in a sortable and searchable table. You will see the numbers printed out in the Jython shell (which is used for output of the print command).
Want to learn about methods of the "pn" object? Just type "pn." and press [Ctrl]-[Space]. You will see a drop-down menu with the methods of this class.
Alternatively, one can look at the complete API of the PND java class as
pn.doc() # to bring up a widows with the class API
3.2. Extracting Features
Let us continue with the analysis of our data. First thing we want to do is to extract the numbers from the 2nd column and display them as a histogram (or a chart-bar density plot) to understand the statistical characteristics of the data. Assuming that the "pn" object is created as shown before, we will extract the second column using the index 1 (the first column has the index 0)
p0=pn.getP0D(1) # extract 2nd column and put to a 1D array print p0.getStat() # print a detailed statistical characteristics c1=HPlot('Plot') # create a canvas to display a histogram c1.visible(); c1.setAutoRange() # set auto-range h1=p0.getH1D(10) # convert 1D array into a histogram with 10 bins c1.draw(h1) # draw the histogram
You will see a long list of statistical characteristics of the array of the first column (object p0) and a pop-up window with the histogram from the first array. The code is self-explanatory and contains the comments to explain each step. For example, the method "p0.getH1D()" fills a one-dimensional histogram (the Java class H1D) using ten bins between a minimum and a maximum value of the array "p0" (the Java class P0D). You will be surprised to find how many methods the H1D class contain. According to the Java API, the histogram class H1D has about 100 methods for data manipulation (excluding the once used for graphical representation).
If you want to make a file with a high-quality vector graphics, use the method c1.export('fig.pdf') (for the PDF format) or c1.export('fig.ps') (for the PostScript format). DMelt supports about 10 image formats for outputs. Figures can be generated in background without bringing up the canvas. In this case, use the method c1.visible(0). Finally, DMelt has a powerful input-output mechanism for each data object (histograms, functions, data arrays) which will allow to store all objects in files using either the Java serialized mechanism or simple text-based files with compression.
The next step in our analysis is to extract the 2 columns and to make a X-Y scatter plot in order find a correlation between the numbers from these columns. In the example below we extract the 2nd and 3rd column, plot them on X-Y canvas and then perform a least-squared linear regression:
from jhplot.stat import * p1=pn.getP1D(1,2) # extract 2nd and 3rd columns c1=HPlot('X-Y plot') c1.visible(); c1.setAutoRange() # set autorange c1.draw(p1) r = LinReg(p1) print "Intercept=",r.getIntercept(), "+/-",r.getInterceptError() print "Slope=",r.getSlope(),"+/-",r.getSlopeError()
This code should follow after the code which creates the object "pn" as discussed before. The execution of this code makes a X-Y graph with the values of the 2nd and 3rd columns, performs a least-squares regression and prints the values of the intercept and the slope (with their statistical uncertainties) of the linear-regression line. But how to visualize such line? We can create a function using the values of the slope and and intercept using the Python approach:
func='%4.2f*x+%4.2f' % (r.getSlope(),r.getIntercept()) # a string representing a function a*x+b f1=F1D( func, p1.getMin(0), p1.getMax(0)) # a function object in the data range c1.draw(f1) # draw the function on the canvas
This part of the code should follow after the code discussed before. In this example, we build a function "a*x+b" using the slope and the intercept values instead of symbols "a" and "b". Note that we reduced the precision of these values during the string formatting (which is not too important in this example). Then we build a function object from the string in the X-axis range given by the data (p1.getMin(0) means the minimum value of our data on the X-axis and p1.getMax(0) is the maximum value).
3.3. Prediction Interval
We can do something more: We can calculate a 95% prediction interval of the regression line [(Confidence and Prediction band. See  Confidence band. The 95% prediction interval is the area in which 95% of all data points are expected to fall. Do not confuse it with a 95% confidence interval, which is the area that has a 95% chance of containing the true regression line. The DMelt can calculate both, but here we only discuss the 95% prediction interval and will try to plot this interval on top of data points.
Confidence band. The 95% prediction interval is the area in which 95% of all data points are expected to fall. Do not confuse it with a 95% confidence interval, which is the area that has a 95% chance of containing the true regression line. The DMelt can calculate both, but here we only discuss the 95% prediction interval and will try to plot this interval on top of data points.
> from java.awt import Color p=r.getPredictionBand(Color.green) # extract 95% prediction band p.setLegend(False) # do not draw the legend for this band p.setErrColor(Color.green) # set green color for error bars c1.draw(p) # show on the canvas
The method getPredictionBand(..) returns a P1D data container containing a 95% prediction interval. We show this band using errors colored in green using the "Color" class from the standard Java "java.awt" package.
Let us continue with this example by displaying the data in three-dimensions (3D) using 3 arbitrary columns. This time we make 2 pads and visualize data for 1,2,3 and 1,3,4 columns using separate interactive 3D pads. As before, we assume this code follows after the previously discussed lines and the object "pn" has been created:
c2=HPlot3D('3D plot',600,400,2,1) # create a 600x400 canvas and make 2 drawing pads c2.visible() c2.cd(1,1); c2.setAutoRange() # navigate to first pad and set autorange p2=pn.getP2D(0,1,2) # extract 3 columns with index 1,2,3 c2.draw(p2) c2.cd(2,1); c2.setAutoRange() # navigate to second pad and set autorange p3=pn.getP2D(0,2,3) # extract 3 columns with index 1,3,4 c2.draw(p3)
This code makes two interactive 3D canvases which can be rotated and zoomed in. Use the methods of the Java class "HPlot3D" to change its style. For example, we can change the color of the drawing box to a gray using the Java Color class as c2.setBoxColor(Color(200,210,210)) which can be inserted after the pad navigation method "cd()".
It should be noted that instead of using the Jython shell, one can use the DMelt editor. Create a file called "example.py" and copy and paster the lines above. To run this file, press [F8] or click on the icon  on the tool-bar menu. There is one essential advantage in using such approach: One can use the built-in code assist which tells about the description of all methods. For example, assuming that the "pn" object is created, just type a dot after "pn" in the editor and press [F4]:
on the tool-bar menu. There is one essential advantage in using such approach: One can use the built-in code assist which tells about the description of all methods. For example, assuming that the "pn" object is created, just type a dot after "pn" in the editor and press [F4]:
> pn. # then press [F4] to display a list of methods
The execution of this script brings up a table showing all methods of this class. You can get a detailed description of each method and insert the selected method into the editor. You can make modifications in the code and rerun the file by using [F8] or clicking on the icon  .
.
Now, let us run all above code snippets of this tutorial in one go. Look at this code:
# Data Mining using DMelt Tutorial. # S.Chekanov. April 2011. Updated for DMelt on Jubne 2016 from jhplot import * from jhplot.stat import LinReg from java.awt import Color # read data from external file pn=PND('data','http://datamelt.org/examples/data/pnd.d') print pn.toString() p0=pn.getP0D(1) # extract 2nd column and put to a 1D array print p0.getStat() # print statistics print p0.variance() h1=p0.getH1D(10) # make a histogram with 10 bins p1=pn.getP1D(1,2) # extract column 2 and 3 c1=HPlot("Plot",600,400,2,1) c1.visible() c1.cd(1,1) # go to the first drawing region c1.setAutoRange() c1.draw(h1) c1.cd(2,1) # go to second drawing region c1.setAutoRange() r = LinReg(p1) print "Intercept=",r.getIntercept(), "+/-",r.getInterceptError() print "Slope=",r.getSlope(),"+/-",r.getSlopeError() # create a string with a*x+b function func='%4.2f*x+%4.2f' % (r.getSlope(),r.getIntercept()) f1=F1D( func, p1.getMin(0), p1.getMax(0)) # define a function in the range of the data p=r.getPredictionBand(Color.green) # calculate the prediction band p.setLegend(False) # do not show the legend p.setErrColor(Color.green) # color for error bars c1.draw(p) c1.draw(p1) # redraw data and the function c1.draw(f1) c1.export("tutorial_dmin1.eps") # make image file (EPS) p2=pn.getP2D(0,1,2) # extract 1,2,3 columns p3=pn.getP2D(0,2,3) # extract 1,3,4 columns c2=HPlot3D("Plot",600,400,2,1) c2.visible() c2.setAutoRange() c2.cd(1,1) c2.setBoxColor(Color.white) c2.draw(p2) c2.cd(2,1) c2.setBoxColor(Color(200,210,210)) c2.setAutoRange() c2.draw(p3) c2.export("tutorial_dmin2.eps")
In the IDE, go to the menu [File] and then [Open from URL]. Copy and paste the URL string with the code (shown in blue in the URL link given above). Then press the button [Open] (to see the code) or [Run] (to run the code). You will see images with our tutorial as shown below:
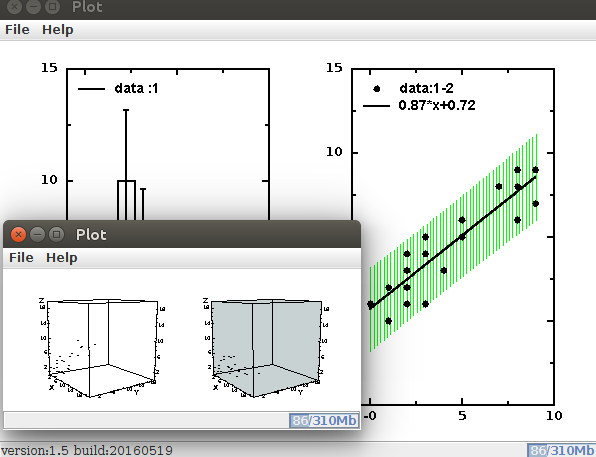
A final word. DMelt comes with more than 400 example scripts, detailed tutorial and even a book describing all aspects of the Java/Jython approach to data analysis. To run examples, simply go to the menubar, select [Tools] and then [DMelt online examples]. Here you can view the available code examples and run them.
More details about the DMelt data-analysis project can be found on the official web page.
4. About the License
The core numerical and graphical Java libraries are licensed under the GNU General Public License v3. Some third-party libraries, documentation, examples, installer, code assist database, language files used by the IDE are licensed under the Creative Commons Attribution-Share Alike License; either version 3.0 and are free only for non-commercial usage (academic research, science and education).
Prepared by Sergei Chekanov and Alejandro D. P. de Astorza (older version on jHepWork available from java.net)
The content is sourced from: https://handwiki.org/wiki/DMelt:DataAnalysis/4_Data_Mining