Computer vision (CV) combined with a deep convolutional neural network (CNN) has emerged as a reliable analytical method to effectively characterize and quantify high-throughput phenotyping of different grain crops, including rice, wheat, corn, and soybean. In addition to the ability to rapidly obtain information on plant organs and abiotic stresses, and the ability to segment crops from weeds, such techniques have been used to detect pests and plant diseases and to identify grain varieties. The development of corresponding imaging systems to assess the phenotypic parameters, yield, and quality of crop plants will increase the confidence of stakeholders in grain crop cultivation, thereby bringing technical and economic benefits to advanced agriculture.
- grain crops
- convolutional neural network
- computer vision
1. Introduction
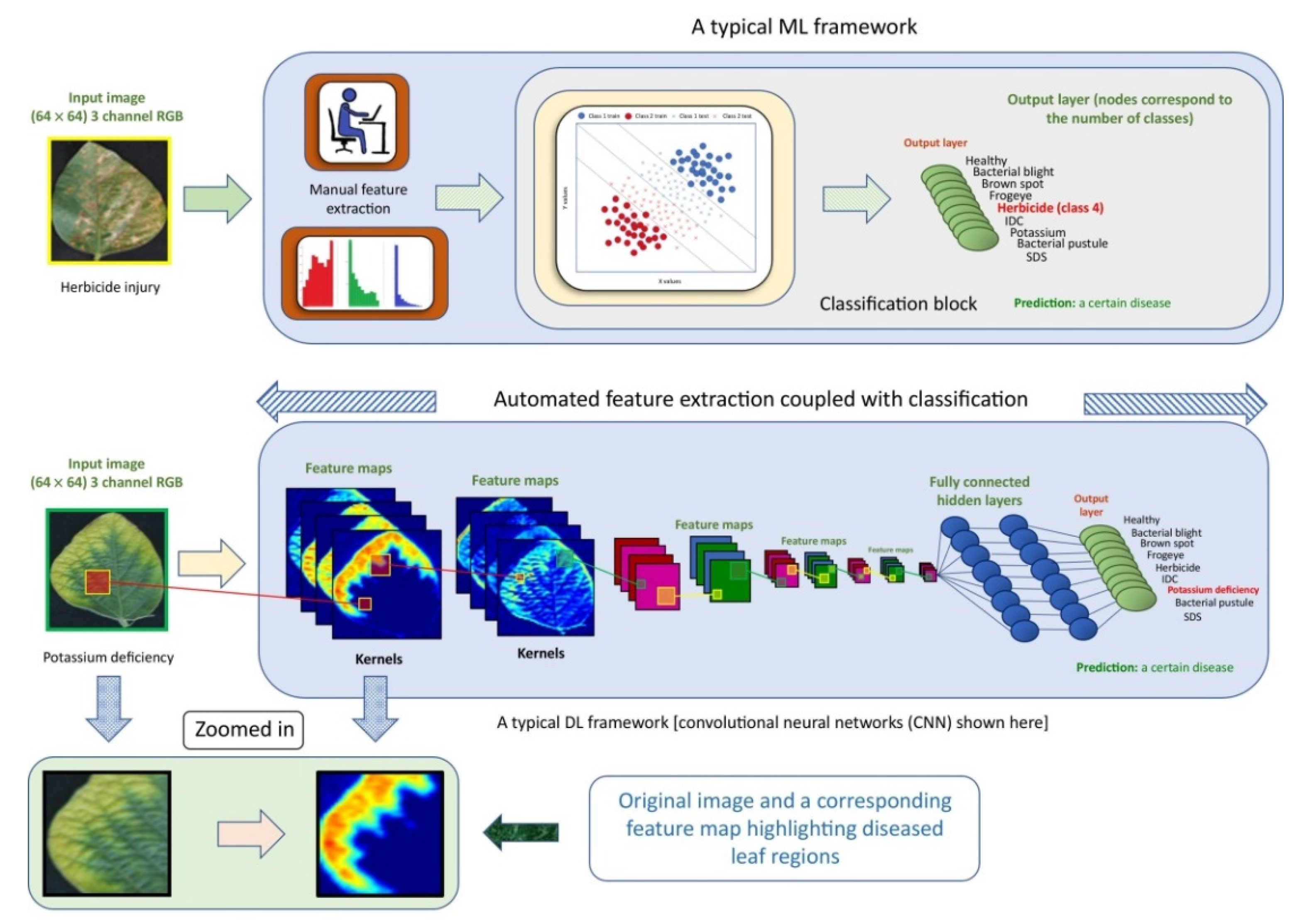
2. Computer Vision (CV) and Convolutional Neural Networks (CNNs)
2.1. CV
2.2. CNN
2.3. CNNs Combined with CV Tasks
2.3.1. Image Classification
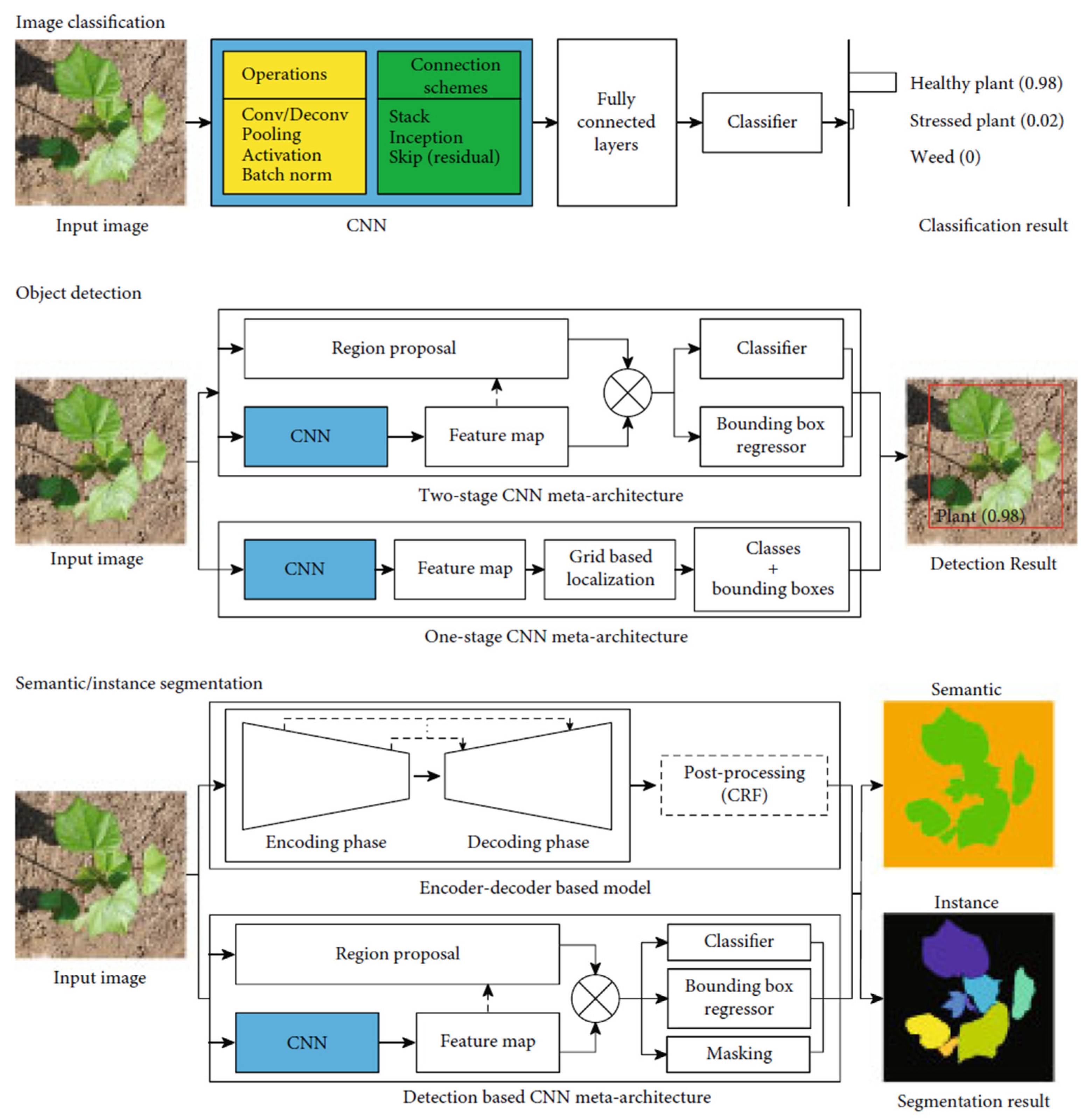
2.3.2. Object Detection
2.3.3. Semantic and Instance Segmentations
This entry is adapted from the peer-reviewed paper 10.3390/agronomy12112659
References
- Tilman, D.; Balzer, C.; Hill, J.; Befort, B.L. Global food demand and the sustainable intensification of agriculture. Proc. Natl. Acad. Sci. USA 2011, 108, 20260–20264.
- Steensland, A.; Thompson, T.L. 2020 Global Agricultural Productivity Report: Productivity in a Time of Pandemics. Global Agricultural Productivity Report: Productivity in a Time of Pandemics; College of Agriculture and Life Sciences: Blacksburg, VA, USA, 2020.
- Yu, Q.Y.; Xiang, M.T.; Wu, W.B.; Tang, H.J. Changes in global cropland area and cereal production: An inter-country comparison. Agric. Ecosyst. Environ. 2019, 269, 140–147.
- Pan, Y.H. Analysis of concepts and categories of plant phenome and phenomics. Acta Agron. Sin. 2015, 41, 175–186.
- Vithu, P.; Moses, J.A. Machine vision system for food grain quality evaluation: A review. Trends Food Sci. Technol. 2016, 56, 13–20.
- Patrício, D.I.; Rieder, R. Computer vision and artificial intelligence in precision agriculture for grain crops: A systematic review. Comput. Electron. Agric. 2018, 153, 69–81.
- Ngugi, L.C.; Abelwahab, M.; Abo-Zahhad, M. Recent advances in image processing techniques for automated leaf pest and disease recognition–A review. Inf. Process. Agric. 2021, 8, 27–51.
- Wang, A.C.; Zhang, W.; Wei, X.H. A review on weed detection using ground-based machine vision and image processing techniques. Comput. Electron. Agric. 2019, 158, 226–240.
- Sun, D.; Robbins, K.; Morales, N.; Shu, Q.; Cen, H. Advances in optical phenotyping of cereal crops. Trends Plant Sci. 2022, 27, 191–208.
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516.
- Dhillon, A.; Verma, G.K. Convolutional neural network: A review of models, methodologies and applications to object detection. Prog. Artif. Intell. 2020, 9, 85–112.
- Mo, Y.; Wu, Y.; Yang, X.; Liu, F.; Liao, Y. Review the state-of-the-art technologies of semantic segmentation based on deep learning. Neurocomputing 2022, 493, 626–646.
- Singh, A.K.; Ganapathysubramanian, B.; Sarkar, S.; Singh, A. Deep Learning for Plant Stress Phenotyping: Trends and Future Perspectives. Trends Plant Sci. 2018, 23, 883–898.
- Diba, A.; Sharma, V.; Pazandeh, A.; Pirsiavash, H.; van Gool, L. Weakly supervised cascaded convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 914–922.
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaria, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53.
- Liu, J.; Wang, X. Plant diseases and pests detection based on deep learning: A review. Plant Methods 2021, 17, 22.
- Jiang, Y.; Li, C. Convolutional Neural Networks for Image-Based High-Throughput Plant Phenotyping: A Review. Plant Phenomics 2020, 2020, 4152816.
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. NIPS 2012, 25, 84–90.
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826.
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556.
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708.
- Zoph, B.; Le, Q.V. Neural architecture search with reinforcement learning. arXiv 2016, arXiv:1611.01578.
- Montavon, G.; Samek, W.; Muller, K.R. Methods for interpreting and understanding deep neural networks. Digit. Signal Process. 2018, 73, 1–15.
- Arrieta, A.B.; Diaz-Rodriguez, N.; del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Garcia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115.
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229.
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2014, Columbus, OH, USA, 23–28 June 2014; pp. 580–587.
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision 2015, Santiago, Chile, 7–13 December 2015; pp. 1440–1448.
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015.
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2015, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440.
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848.
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention 2015, Munich, Germany, 5–9 October 2015; pp. 234–241.
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Simultaneous detection and segmentation. In Proceedings of the European Conference on Computer Vision 2014, Zurich, Switzerland, 6–12 September 2014; pp. 297–312.
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision 2017, Venice, Italy, 22–29 October 2017; pp. 2961–2969.