This article discusses computational tools used in artificial intelligence.
- computational tools
1. Search and Optimization
Many problems in AI can be solved theoretically by intelligently searching through many possible solutions:[1] Reasoning can be reduced to performing a search. For example, logical proof can be viewed as searching for a path that leads from premises to conclusions, where each step is the application of an inference rule.[2] Planning algorithms search through trees of goals and subgoals, attempting to find a path to a target goal, a process called means-ends analysis.[3] Robotics algorithms for moving limbs and grasping objects use local searches in configuration space.[4] Many learning algorithms use search algorithms based on optimization.
Simple exhaustive searches[5] are rarely sufficient for most real-world problems: the search space (the number of places to search) quickly grows to astronomical numbers. The result is a search that is too slow or never completes. The solution, for many problems, is to use "heuristics" or "rules of thumb" that prioritize choices in favor of those more likely to reach a goal and to do so in a shorter number of steps. In some search methodologies heuristics can also serve to entirely eliminate some choices unlikely to lead to a goal (called "pruning the search tree"). Heuristics supply the program with a "best guess" for the path on which the solution lies.[6][7] Heuristics limit the search for solutions into a smaller sample size.[8]
A very different kind of search came to prominence in the 1990s, based on the mathematical theory of optimization. For many problems, it is possible to begin the search with some form of a guess and then refine the guess incrementally until no more refinements can be made. These algorithms can be visualized as blind hill climbing: we begin the search at a random point on the landscape, and then, by jumps or steps, we keep moving our guess uphill, until we reach the top. Other optimization algorithms are simulated annealing, beam search and random optimization.[9]
Evolutionary computation uses a form of optimization search. For example, they may begin with a population of organisms (the guesses) and then allow them to mutate and recombine, selecting only the fittest to survive each generation (refining the guesses). Classic evolutionary algorithms include genetic algorithms, gene expression programming, and genetic programming.[10]*[11][12][13] Alternatively, distributed search processes can coordinate via swarm intelligence algorithms. Two popular swarm algorithms used in search are particle swarm optimization (inspired by bird flocking) and ant colony optimization (inspired by ant trails).[14][15]
2. Logic
Logic[16][17] is used for knowledge representation and problem solving, but it can be applied to other problems as well. For example, the satplan algorithm uses logic for planning[18] and inductive logic programming is a method for learning.[19]
Several different forms of logic are used in AI research. Propositional logic[20] involves truth functions such as "or" and "not". First-order logic[17][21] adds quantifiers and predicates, and can express facts about objects, their properties, and their relations with each other. Fuzzy set theory assigns a "degree of truth" (between 0 and 1) to vague statements such as "Alice is old" (or rich, or tall, or hungry) that are too linguistically imprecise to be completely true or false. Fuzzy logic is successfully used in control systems to allow experts to contribute vague rules such as "if you are close to the destination station and moving fast, increase the train's brake pressure"; these vague rules can then be numerically refined within the system. Fuzzy logic fails to scale well in knowledge bases; many AI researchers question the validity of chaining fuzzy-logic inferences.[22][23][24]
Default logics, non-monotonic logics and circumscription[25] are forms of logic designed to help with default reasoning and the qualification problem. Several extensions of logic have been designed to handle specific domains of knowledge, such as: description logics;[26] situation calculus, event calculus and fluent calculus (for representing events and time);[27] causal calculus;[28] belief calculus (belief revision);[29] and modal logics.[30] Logics to model contradictory or inconsistent statements arising in multi-agent systems have also been designed, such as paraconsistent logics.
3. Probabilistic Methods for Uncertain Reasoning
Many problems in AI (in reasoning, planning, learning, perception, and robotics) require the agent to operate with incomplete or uncertain information. AI researchers have devised a number of powerful tools to solve these problems using methods from probability theory and economics.[17][31]
Bayesian networks[32] are a very general tool that can be used for various problems: reasoning (using the Bayesian inference algorithm),[33] learning (using the expectation-maximization algorithm),[34][35] planning (using decision networks)[36] and perception (using dynamic Bayesian networks).[37] Probabilistic algorithms can also be used for filtering, prediction, smoothing and finding explanations for streams of data, helping perception systems to analyze processes that occur over time (e.g., hidden Markov models or Kalman filters).[37]
Compared with symbolic logic, formal Bayesian inference is computationally expensive. For inference to be tractable, most observations must be conditionally independent of one another. Complicated graphs with diamonds or other "loops" (undirected cycles) can require a sophisticated method such as Markov chain Monte Carlo, which spreads an ensemble of random walkers throughout the Bayesian network and attempts to converge to an assessment of the conditional probabilities. Bayesian networks are used on Xbox Live to rate and match players; wins and losses are "evidence" of how good a player is. AdSense uses a Bayesian network with over 300 million edges to learn which ads to serve.[38]:chapter 6
A key concept from the science of economics is "utility": a measure of how valuable something is to an intelligent agent. Precise mathematical tools have been developed that analyze how an agent can make choices and plan, using decision theory, decision analysis,[39] and information value theory.[40] These tools include models such as Markov decision processes,[41] dynamic decision networks,[37] game theory and mechanism design.[42]
4. Classifiers and Statistical Learning Methods
The simplest AI applications can be divided into two types: classifiers ("if shiny then diamond") and controllers ("if shiny then pick up"). Controllers do, however, also classify conditions before inferring actions, and therefore classification forms a central part of many AI systems. Classifiers are functions that use pattern matching to determine a closest match. They can be tuned according to examples, making them very attractive for use in AI. These examples are known as observations or patterns. In supervised learning, each pattern belongs to a certain predefined class. A class is a decision that has to be made. All the observations combined with their class labels are known as a data set. When a new observation is received, that observation is classified based on previous experience.[43]
A classifier can be trained in various ways; there are many statistical and machine learning approaches. The decision tree[44] is perhaps the most widely used machine learning algorithm.[38]:88 Other widely used classifiers are the neural network,[45] k-nearest neighbor algorithm,[46][47] kernel methods such as the support vector machine (SVM),[48][49] Gaussian mixture model,[50] and the extremely popular naive Bayes classifier.[51][52] Classifier performance depends greatly on the characteristics of the data to be classified, such as the dataset size, distribution of samples across classes, the dimensionality, and the level of noise. Model-based classifiers perform well if the assumed model is an extremely good fit for the actual data. Otherwise, if no matching model is available, and if accuracy (rather than speed or scalability) is the sole concern, conventional wisdom is that discriminative classifiers (especially SVM) tend to be more accurate than model-based classifiers such as "naive Bayes" on most practical data sets.[53][54]
5. Artificial Neural Networks
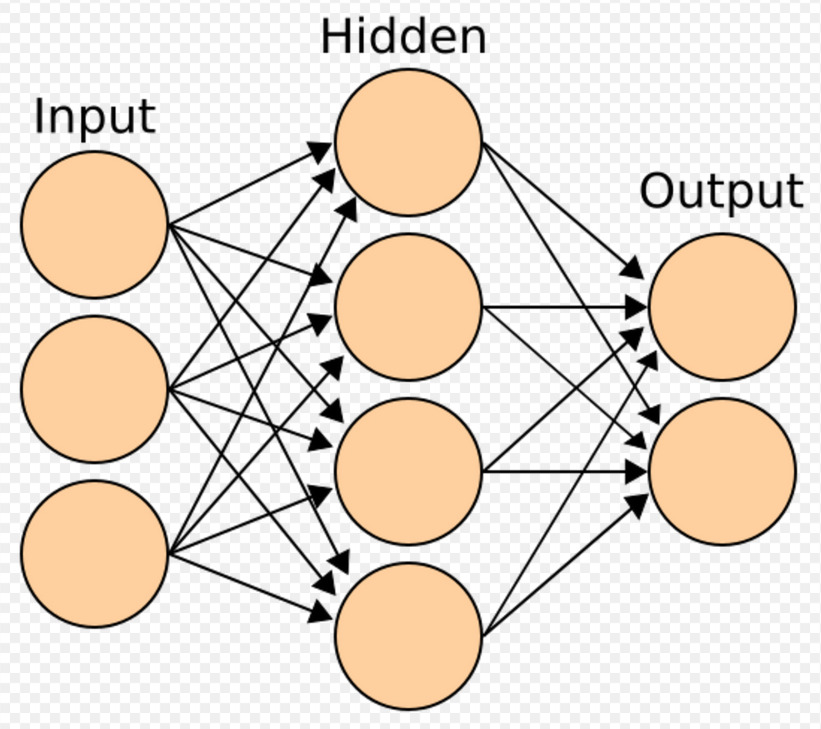
Neural networks were inspired by the architecture of neurons in the human brain. A simple "neuron" N accepts input from other neurons, each of which, when activated (or "fired"), casts a weighted "vote" for or against whether neuron N should itself activate. Learning requires an algorithm to adjust these weights based on the training data; one simple algorithm (dubbed "fire together, wire together") is to increase the weight between two connected neurons when the activation of one triggers the successful activation of another. The neural network forms "concepts" that are distributed among a subnetwork of shared[55] neurons that tend to fire together; a concept meaning "leg" might be coupled with a subnetwork meaning "foot" that includes the sound for "foot". Neurons have a continuous spectrum of activation; in addition, neurons can process inputs in a nonlinear way rather than weighing straightforward votes. Modern neural networks can learn both continuous functions and, surprisingly, digital logical operations. Neural networks' early successes included predicting the stock market and (in 1995) a mostly self-driving car.[38][56]:Chapter 4 In the 2010s, advances in neural networks using deep learning thrust AI into widespread public consciousness and contributed to an enormous upshift in corporate AI spending; for example, AI-related M&A in 2017 was over 25 times as large as in 2015.[57][58]
The study of non-learning artificial neural networks[45] began in the decade before the field of AI research was founded, in the work of Walter Pitts and Warren McCullouch. Frank Rosenblatt invented the perceptron, a learning network with a single layer, similar to the old concept of linear regression. Early pioneers also include Alexey Grigorevich Ivakhnenko, Teuvo Kohonen, Stephen Grossberg, Kunihiko Fukushima, Christoph von der Malsburg, David Willshaw, Shun-Ichi Amari, Bernard Widrow, John Hopfield, Eduardo R. Caianiello, and others.
The main categories of networks are acyclic or feedforward neural networks (where the signal passes in only one direction) and recurrent neural networks (which allow feedback and short-term memories of previous input events). Among the most popular feedforward networks are perceptrons, multi-layer perceptrons and radial basis networks.[59] Neural networks can be applied to the problem of intelligent control (for robotics) or learning, using such techniques as Hebbian learning ("fire together, wire together"), GMDH or competitive learning.[60]
Today, neural networks are often trained by the backpropagation algorithm, which has been around since 1970 as the reverse mode of automatic differentiation published by Seppo Linnainmaa,[61][62] and was introduced to neural networks by Paul Werbos.[63][64][65]
Hierarchical temporal memory is an approach that models some of the structural and algorithmic properties of the neocortex.[66]
To summarize, most neural networks use some form of gradient descent on a hand-created neural topology. However, some research groups, such as Uber, argue that simple neuroevolution to mutate new neural network topologies and weights may be competitive with sophisticated gradient descent approaches. One advantage of neuroevolution is that it may be less prone to get caught in "dead ends".[67]
5.1. Deep Feedforward Neural Networks
Deep learning is the use of artificial neural networks which have several layers of neurons between the network's inputs and outputs. Deep learning has drastically improved the performance of programs in many important subfields of artificial intelligence, including computer vision, speech recognition, natural language processing and others.[68][69][70]
According to one overview,[71] the expression "Deep Learning" was introduced to the machine learning community by Rina Dechter in 1986[72] and gained traction after Igor Aizenberg and colleagues introduced it to artificial neural networks in 2000.[73] The first functional Deep Learning networks were published by Alexey Grigorevich Ivakhnenko and V. G. Lapa in 1965.[74] These networks are trained one layer at a time. Ivakhnenko's 1971 paper[75] describes the learning of a deep feedforward multilayer perceptron with eight layers, already much deeper than many later networks. In 2006, a publication by Geoffrey Hinton and Ruslan Salakhutdinov introduced another way of pre-training many-layered feedforward neural networks (FNNs) one layer at a time, treating each layer in turn as an unsupervised restricted Boltzmann machine, then using supervised backpropagation for fine-tuning.[76] Similar to shallow artificial neural networks, deep neural networks can model complex non-linear relationships.
Deep learning often uses convolutional neural networks (CNNs), whose origins can be traced back to the Neocognitron introduced by Kunihiko Fukushima in 1980.[77] In 1989, Yann LeCun and colleagues applied backpropagation to such an architecture. In the early 2000s, in an industrial application, CNNs already processed an estimated 10% to 20% of all the checks written in the US.[78] Since 2011, fast implementations of CNNs on GPUs have won many visual pattern recognition competitions.[70]
CNNs with 12 convolutional layers were used with reinforcement learning by Deepmind's "AlphaGo Lee", the program that beat a top Go champion in 2016.[79]
5.2. Deep Recurrent Neural Networks
Early on, deep learning was also applied to sequence learning with recurrent neural networks (RNNs)[80] which are theoretically Turing complete[81] and can run arbitrary programs to process arbitrary sequences of inputs. The depth of an RNN is unlimited and depends on the length of its input sequence; thus, an RNN is an example of deep learning.[70] RNNs can be trained by gradient descent[82][83][84] but suffer from the vanishing gradient problem.[68][85] In 1992, it was shown that unsupervised pre-training of a stack of recurrent neural networks can speed up subsequent supervised learning of deep sequential problems.[86]
Numerous researchers now use variants of a deep learning recurrent NN called the long short-term memory (LSTM) network published by Hochreiter & Schmidhuber in 1997.[87] LSTM is often trained by Connectionist Temporal Classification (CTC).[88] At Google, Microsoft and Baidu this approach has revolutionized speech recognition.[89][90][91] For example, in 2015, Google's speech recognition experienced a dramatic performance jump of 49% through CTC-trained LSTM, which is now available through Google Voice to billions of smartphone users.[92] Google also used LSTM to improve machine translation,[93] Language Modeling[94] and Multilingual Language Processing.[95] LSTM combined with CNNs also improved automatic image captioning[96] and a plethora of other applications.
6. Evaluating Progress
Games provide a well-publicized benchmark for assessing rates of progress. AlphaGo around 2016 brought the era of classical board-game benchmarks to a close. Games of imperfect knowledge provide new challenges to AI in game theory.[97][98] E-sports such as StarCraft continue to provide additional public benchmarks.[99][100] Many competitions and prizes, such as the Imagenet Challenge, promote research in artificial intelligence. The most common areas of competition include general machine intelligence, conversational behavior, data-mining, robotic cars, and robot soccer as well as conventional games.[101]
The "imitation game" (an interpretation of the 1950 Turing test that assesses whether a computer can imitate a human) is nowadays considered too exploitable to be a meaningful benchmark.[102] A derivative of the Turing test is the Completely Automated Public Turing test to tell Computers and Humans Apart (CAPTCHA). As the name implies, this helps to determine that a user is an actual person and not a computer posing as a human. Unlike the standard Turing test, CAPTCHA is administered by a machine and targeted to a human as opposed to being administered by a human and targeted to a machine. A computer asks a user to complete a simple test then generates a grade for that test. Computers are unable to solve the problem, so correct solutions are deemed to be the result of a person taking the test. A common type of CAPTCHA is the test that requires the typing of distorted letters, numbers or symbols that appear in an image undecipherable by a computer.[103]
Proposed "universal intelligence" tests aim to compare how well machines, humans, and even non-human animals perform on problem sets that are generic as possible. At an extreme, the test suite can contain every possible problem, weighted by Kolmogorov complexity; unfortunately, these problem sets tend to be dominated by impoverished pattern-matching exercises where a tuned AI can easily exceed human performance levels.[104][105][106][107]
6.1. Hardware Improvements
Since the 2010s, advances in both machine learning algorithms and computer hardware have led to more efficient methods for training deep neural networks that contain many layers of non-linear hidden units and a very large output layer.[108] By 2019, graphic processing units (GPUs), often with AI-specific enhancements, had displaced CPUs as the dominant method of training large-scale commercial cloud AI.[109] OpenAI estimated the hardware compute used in the largest deep learning projects from AlexNet (2012) to AlphaZero (2017), and found a 300,000-fold increase in the amount of compute required, with a doubling-time trendline of 3.4 months.[110][111]
The content is sourced from: https://handwiki.org/wiki/Computational_tools_for_artificial_intelligence
References
- Search algorithms: Russell & Norvig 2003, pp. 59–189 Poole, Mackworth & Goebel 1998, pp. 113–163 Luger & Stubblefield 2004, pp. 79–164, 193–219 Nilsson 1998, chpt. 7–12
- Forward chaining, backward chaining, Horn clauses, and logical deduction as search: Russell & Norvig 2003, pp. 217–225, 280–294 Poole, Mackworth & Goebel 1998, pp. ~46–52 Luger & Stubblefield 2004, pp. 62–73 Nilsson 1998, chpt. 4.2, 7.2
- State space search and planning: Russell & Norvig 2003, pp. 382–387 Poole, Mackworth & Goebel 1998, pp. 298–305 Nilsson 1998, chpt. 10.1–2
- Moving and configuration space: Russell & Norvig 2003, pp. 916–932
- Uninformed searches (breadth first search, depth first search and general state space search): Russell & Norvig 2003, pp. 59–93 Poole, Mackworth & Goebel 1998, pp. 113–132 Luger & Stubblefield 2004, pp. 79–121 Nilsson 1998, chpt. 8
- Heuristic or informed searches (e.g., greedy best first and A*): Russell & Norvig 2003, pp. 94–109, Poole, Mackworth & Goebel 1998, pp. pp. 132–147, Luger & Stubblefield 2004, pp. 133–150, Nilsson 1998, chpt. 9,
- Poole, David; Mackworth, Alan (2017). Artificial Intelligence: Foundations of Computational Agents (2nd ed.). Cambridge University Press. Section 3.6. ISBN 978-1-107-19539-4. http://artint.info/index.html.
- Tecuci, Gheorghe (March–April 2012). "Artificial Intelligence". Wiley Interdisciplinary Reviews: Computational Statistics 4 (2): 168–180. doi:10.1002/wics.200. https://dx.doi.org/10.1002%2Fwics.200
- Optimization searches: Russell & Norvig 2003, pp. 110–116,120–129 Poole, Mackworth & Goebel 1998, pp. 56–163 Luger & Stubblefield 2004, pp. 127–133
- Genetic programming and genetic algorithms: Luger & Stubblefield 2004, pp. 509–530, Nilsson 1998, chpt. 4.2.
- Holland, John H. (1975). Adaptation in Natural and Artificial Systems. University of Michigan Press. ISBN 978-0-262-58111-0. https://archive.org/details/adaptationinnatu00holl.
- Koza, John R. (1992). Genetic Programming (On the Programming of Computers by Means of Natural Selection). MIT Press. ISBN 978-0-262-11170-6. Bibcode: 1992gppc.book.....K. http://adsabs.harvard.edu/abs/1992gppc.book.....K
- Poli, R.; Langdon, W. B.; McPhee, N. F. (2008). A Field Guide to Genetic Programming. Lulu.com. ISBN 978-1-4092-0073-4. http://www.gp-field-guide.org.uk/.
- Artificial life and society based learning: Luger & Stubblefield 2004, pp. 530–541
- Daniel Merkle; Martin Middendorf (2013). "Swarm Intelligence". in Burke, Edmund K.; Kendall, Graham (in en). Search Methodologies: Introductory Tutorials in Optimization and Decision Support Techniques. Springer Science & Business Media. ISBN 978-1-4614-6940-7.
- Logic: Russell & Norvig 2003, pp. 194–310, Luger & Stubblefield 2004, pp. 35–77, Nilsson 1998, chpt. 13–16
- "ACM Computing Classification System: Artificial intelligence". ACM. 1998. ~I.2.3 and ~I.2.4. http://www.acm.org/class/1998/I.2.html.
- Satplan: Russell & Norvig 2003, pp. 402–407, Poole, Mackworth & Goebel 1998, pp. 300–301, Nilsson 1998, chpt. 21
- Explanation based learning, relevance based learning, inductive logic programming, case based reasoning: Russell & Norvig 2003, pp. 678–710, Poole, Mackworth & Goebel 1998, pp. 414–416, Luger & Stubblefield 2004, pp. ~422–442, Nilsson 1998, chpt. 10.3, 17.5
- Propositional logic: Russell & Norvig 2003, pp. 204–233, Luger & Stubblefield 2004, pp. 45–50 Nilsson 1998, chpt. 13
- First-order logic and features such as equality: Russell & Norvig 2003, pp. 240–310, Poole, Mackworth & Goebel 1998, pp. 268–275, Luger & Stubblefield 2004, pp. 50–62, Nilsson 1998, chpt. 15
- "There exist many different types of uncertainty, vagueness, and ignorance... [We] independently confirm the inadequacy of systems for reasoning about uncertainty that propagates numerical factors according to only to which connectives appear in assertions."[22]
- Fuzzy logic: Russell & Norvig 2003, pp. 526–527
- "What is 'fuzzy logic'? Are there computers that are inherently fuzzy and do not apply the usual binary logic?" (in en). Scientific American. https://www.scientificamerican.com/article/what-is-fuzzy-logic-are-t/.
- Default reasoning and default logic, non-monotonic logics, circumscription, closed world assumption, abduction (Poole et al. places abduction under "default reasoning". Luger et al. places this under "uncertain reasoning"): Russell & Norvig 2003, pp. 354–360, Poole, Mackworth & Goebel 1998, pp. 248–256, 323–335, Luger & Stubblefield 2004, pp. 335–363, Nilsson 1998, ~18.3.3
- Representing categories and relations: Semantic networks, description logics, inheritance (including frames and scripts): Russell & Norvig 2003, pp. 349–354, Poole, Mackworth & Goebel 1998, pp. 174–177, Luger & Stubblefield 2004, pp. 248–258, Nilsson 1998, chpt. 18.3
- Representing events and time:Situation calculus, event calculus, fluent calculus (including solving the frame problem): Russell & Norvig 2003, pp. 328–341, Poole, Mackworth & Goebel 1998, pp. 281–298, Nilsson 1998, chpt. 18.2
- Causal calculus: Poole, Mackworth & Goebel 1998, pp. 335–337
- "The Belief Calculus and Uncertain Reasoning", Yen-Teh Hsia
- Representing knowledge about knowledge: Belief calculus, modal logics: Russell & Norvig 2003, pp. 341–344, Poole, Mackworth & Goebel 1998, pp. 275–277
- Stochastic methods for uncertain reasoning: Russell & Norvig 2003, pp. 462–644, Poole, Mackworth & Goebel 1998, pp. 345–395, Luger & Stubblefield 2004, pp. 165–191, 333–381, Nilsson 1998, chpt. 19
- Bayesian networks: Russell & Norvig 2003, pp. 492–523, Poole, Mackworth & Goebel 1998, pp. 361–381, Luger & Stubblefield 2004, pp. ~182–190, ≈363–379, Nilsson 1998, chpt. 19.3–4
- Bayesian inference algorithm: Russell & Norvig 2003, pp. 504–519, Poole, Mackworth & Goebel 1998, pp. 361–381, Luger & Stubblefield 2004, pp. ~363–379, Nilsson 1998, chpt. 19.4 & 7
- Expectation-maximization, one of the most popular algorithms in machine learning, allows clustering in the presence of unknown latent variables[34]:210
- Bayesian learning and the expectation-maximization algorithm: Russell & Norvig 2003, pp. 712–724, Poole, Mackworth & Goebel 1998, pp. 424–433, Nilsson 1998, chpt. 20
- Bayesian decision theory and Bayesian decision networks: Russell & Norvig 2003, pp. 597–600
- Stochastic temporal models: Russell & Norvig 2003, pp. 537–581 Dynamic Bayesian networks: Russell & Norvig 2003, pp. 551–557 Hidden Markov model: (Russell Norvig) Kalman filters: Russell & Norvig 2003, pp. 551–557
- Domingos, Pedro (2015). The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World. Basic Books. ISBN 978-0-465-06192-1.
- decision theory and decision analysis: Russell & Norvig 2003, pp. 584–597, Poole, Mackworth & Goebel 1998, pp. 381–394
- Information value theory: Russell & Norvig 2003, pp. 600–604
- Markov decision processes and dynamic decision networks: Russell & Norvig 2003, pp. 613–631
- Game theory and mechanism design: Russell & Norvig 2003, pp. 631–643
- Statistical learning methods and classifiers: Russell & Norvig 2003, pp. 712–754, Luger & Stubblefield 2004, pp. 453–541
- Decision tree: Russell & Norvig 2003, pp. 653–664, Poole, Mackworth & Goebel 1998, pp. 403–408, Luger & Stubblefield 2004, pp. 408–417
- Neural networks and connectionism: Russell & Norvig 2003, pp. 736–748, Poole, Mackworth & Goebel 1998, pp. 408–414, Luger & Stubblefield 2004, pp. 453–505, Nilsson 1998, chpt. 3
- The most widely used analogical AI until the mid-1990s[34]:187
- K-nearest neighbor algorithm: Russell & Norvig 2003, pp. 733–736
- SVM displaced k-nearest neighbor in the 1990s[34]:188
- kernel methods such as the support vector machine: Russell & Norvig 2003, pp. 749–752
- Gaussian mixture model: Russell & Norvig 2003, pp. 725–727
- Naive Bayes is reportedly the "most widely used learner" at Google, due in part to its scalability.[34]:152
- Naive Bayes classifier: Russell & Norvig 2003, p. 718
- van der Walt, Christiaan; Bernard, Etienne (2006). "Data characteristics that determine classifier performance". http://www.patternrecognition.co.za/publications/cvdwalt_data_characteristics_classifiers.pdf.
- Russell, Stuart J.; Norvig, Peter (2009). Artificial Intelligence: A Modern Approach (3rd ed.). Upper Saddle River, New Jersey: Prentice Hall. 18.12: Learning from Examples: Summary. ISBN 978-0-13-604259-4.
- Each individual neuron is likely to participate in more than one concept.
- Steering for the 1995 "No Hands Across America" required "only a few human assists".
- "Why Deep Learning Is Suddenly Changing Your Life". Fortune. 2016. http://fortune.com/ai-artificial-intelligence-deep-machine-learning/.
- "Google leads in the race to dominate artificial intelligence" (in en). The Economist. 2017. https://www.economist.com/news/business/21732125-tech-giants-are-investing-billions-transformative-technology-google-leads-race.
- Feedforward neural networks, perceptrons and radial basis networks: Russell & Norvig 2003, pp. 739–748, 758 Luger & Stubblefield 2004, pp. 458–467
- Competitive learning, Hebbian coincidence learning, Hopfield networks and attractor networks: Luger & Stubblefield 2004, pp. 474–505
- Seppo Linnainmaa (1970). The representation of the cumulative rounding error of an algorithm as a Taylor expansion of the local rounding errors. Master's Thesis (in Finnish), Univ. Helsinki, 6–7.
- Griewank, Andreas (2012). Who Invented the Reverse Mode of Differentiation?. Optimization Stories, Documenta Matematica, Extra Volume ISMP (2012), 389–400.
- Paul Werbos, "Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences", PhD thesis, Harvard University, 1974.
- Paul Werbos (1982). Applications of advances in nonlinear sensitivity analysis. In System modeling and optimization (pp. 762–770). Springer Berlin Heidelberg. Online http://werbos.com/Neural/SensitivityIFIPSeptember1981.pdf
- Backpropagation: Russell & Norvig 2003, pp. 744–748, Luger & Stubblefield 2004, pp. 467–474, Nilsson 1998, chpt. 3.3
- Hawkins, Jeff; Blakeslee, Sandra (2005). On Intelligence. New York, NY: Owl Books. ISBN 978-0-8050-7853-4.
- "Artificial intelligence can 'evolve' to solve problems" (in en). Science | AAAS. 10 January 2018. http://www.sciencemag.org/news/2018/01/artificial-intelligence-can-evolve-solve-problems.
- Ian Goodfellow, Yoshua Bengio, and Aaron Courville (2016). Deep Learning. MIT Press. Online http://www.deeplearningbook.org
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.; Mohamed, A.; Jaitly, N.; Senior, A.; Vanhoucke, V. et al. (2012). "Deep Neural Networks for Acoustic Modeling in Speech Recognition – The shared views of four research groups". IEEE Signal Processing Magazine 29 (6): 82–97. doi:10.1109/msp.2012.2205597. Bibcode: 2012ISPM...29...82H. https://dx.doi.org/10.1109%2Fmsp.2012.2205597
- Schmidhuber, J. (2015). "Deep Learning in Neural Networks: An Overview". Neural Networks 61: 85–117. doi:10.1016/j.neunet.2014.09.003. PMID 25462637. https://dx.doi.org/10.1016%2Fj.neunet.2014.09.003
- Schmidhuber, Jürgen (2015). "Deep Learning". Scholarpedia 10 (11): 32832. doi:10.4249/scholarpedia.32832. Bibcode: 2015SchpJ..1032832S. https://dx.doi.org/10.4249%2Fscholarpedia.32832
- Rina Dechter (1986). Learning while searching in constraint-satisfaction problems. University of California, Computer Science Department, Cognitive Systems Laboratory.Online https://www.researchgate.net/publication/221605378_Learning_While_Searching_in_Constraint-Satisfaction-Problems
- Igor Aizenberg, Naum N. Aizenberg, Joos P.L. Vandewalle (2000). Multi-Valued and Universal Binary Neurons: Theory, Learning and Applications. Springer Science & Business Media.
- Ivakhnenko, Alexey (1965). Cybernetic Predicting Devices. Kiev: Naukova Dumka.
- Ivakhnenko, A. G. (1971). "Polynomial Theory of Complex Systems". IEEE Transactions on Systems, Man, and Cybernetics (4): 364–378. doi:10.1109/TSMC.1971.4308320. https://dx.doi.org/10.1109%2FTSMC.1971.4308320
- Hinton, G. E. (2007). "Learning multiple layers of representation". Trends in Cognitive Sciences 11 (10): 428–434. doi:10.1016/j.tics.2007.09.004. PMID 17921042. https://dx.doi.org/10.1016%2Fj.tics.2007.09.004
- Fukushima, K. (1980). "Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position". Biological Cybernetics 36 (4): 193–202. doi:10.1007/bf00344251. PMID 7370364. https://dx.doi.org/10.1007%2Fbf00344251
- Yann LeCun (2016). Slides on Deep Learning Online https://indico.cern.ch/event/510372/
- Silver, David; Schrittwieser, Julian; Simonyan, Karen; Antonoglou, Ioannis; Huang, Aja; Guez, Arthur; Hubert, Thomas; Baker, Lucas et al. (19 October 2017). "Mastering the game of Go without human knowledge". Nature 550 (7676): 354–359. doi:10.1038/nature24270. ISSN 0028-0836. PMID 29052630. Bibcode: 2017Natur.550..354S. http://discovery.ucl.ac.uk/10045895/1/agz_unformatted_nature.pdf. "AlphaGo Lee... 12 convolutional layers".
- Recurrent neural networks, Hopfield nets: Russell & Norvig 2003, p. 758 Luger & Stubblefield 2004, pp. 474–505
- Hyötyniemi, Heikki (1996). "Turing machines are recurrent neural networks". Proceedings of STeP '96/Publications of the Finnish Artificial Intelligence Society: 13–24.
- P. J. Werbos. Generalization of backpropagation with application to a recurrent gas market model" Neural Networks 1, 1988.
- A. J. Robinson and F. Fallside. The utility driven dynamic error propagation network. Technical Report CUED/F-INFENG/TR.1, Cambridge University Engineering Department, 1987.
- R. J. Williams and D. Zipser. Gradient-based learning algorithms for recurrent networks and their computational complexity. In Back-propagation: Theory, Architectures and Applications. Hillsdale, NJ: Erlbaum, 1994.
- Sepp Hochreiter (1991), Untersuchungen zu dynamischen neuronalen Netzen , Diploma thesis. Institut f. Informatik, Technische Univ. Munich. Advisor: J. Schmidhuber. http://people.idsia.ch/~juergen/SeppHochreiter1991ThesisAdvisorSchmidhuber.pdf
- Schmidhuber, J. (1992). "Learning complex, extended sequences using the principle of history compression". Neural Computation 4 (2): 234–242. doi:10.1162/neco.1992.4.2.234. https://dx.doi.org/10.1162%2Fneco.1992.4.2.234
- Hochreiter, Sepp; and Schmidhuber, Jürgen; Long Short-Term Memory, Neural Computation, 9(8):1735–1780, 1997
- Alex Graves, Santiago Fernandez, Faustino Gomez, and Jürgen Schmidhuber (2006). Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural nets. Proceedings of ICML'06, pp. 369–376.
- Hannun, Awni; Case, Carl; Casper, Jared; Catanzaro, Bryan; Diamos, Greg; Elsen, Erich; Prenger, Ryan; Satheesh, Sanjeev; Sengupta, Shubho; Coates, Adam; Ng, Andrew Y. (2014). "Deep Speech: Scaling up end-to-end speech recognition". arXiv:1412.5567 [cs.CL]. //arxiv.org/archive/cs.CL
- Hasim Sak and Andrew Senior and Francoise Beaufays (2014). Long Short-Term Memory recurrent neural network architectures for large scale acoustic modeling. Proceedings of Interspeech 2014.
- Li, Xiangang; Wu, Xihong (2015). "Constructing Long Short-Term Memory based Deep Recurrent Neural Networks for Large Vocabulary Speech Recognition". arXiv:1410.4281 [cs.CL]. //arxiv.org/archive/cs.CL
- Haşim Sak, Andrew Senior, Kanishka Rao, Françoise Beaufays and Johan Schalkwyk (September 2015): Google voice search: faster and more accurate. http://googleresearch.blogspot.ch/2015/09/google-voice-search-faster-and-more.html
- Sutskever, Ilya; Vinyals, Oriol; Le, Quoc V. (2014). "Sequence to Sequence Learning with Neural Networks". arXiv:1409.3215 [cs.CL]. //arxiv.org/archive/cs.CL
- Jozefowicz, Rafal; Vinyals, Oriol; Schuster, Mike; Shazeer, Noam; Wu, Yonghui (2016). "Exploring the Limits of Language Modeling". arXiv:1602.02410 [cs.CL]. //arxiv.org/archive/cs.CL
- Gillick, Dan; Brunk, Cliff; Vinyals, Oriol; Subramanya, Amarnag (2015). "Multilingual Language Processing From Bytes". arXiv:1512.00103 [cs.CL]. //arxiv.org/archive/cs.CL
- Vinyals, Oriol; Toshev, Alexander; Bengio, Samy; Erhan, Dumitru (2015). "Show and Tell: A Neural Image Caption Generator". arXiv:1411.4555 [cs.CV]. //arxiv.org/archive/cs.CV
- Borowiec, Tracey Lien, Steven (2016). "AlphaGo beats human Go champ in milestone for artificial intelligence". latimes.com. https://www.latimes.com/world/asia/la-fg-korea-alphago-20160312-story.html.
- Brown, Noam; Sandholm, Tuomas (26 January 2018). "Superhuman AI for heads-up no-limit poker: Libratus beats top professionals" (in en). Science: pp. 418–424. doi:10.1126/science.aao1733. http://science.sciencemag.org/content/359/6374/418.
- Ontanon, Santiago; Synnaeve, Gabriel; Uriarte, Alberto; Richoux, Florian; Churchill, David; Preuss, Mike (December 2013). "A Survey of Real-Time Strategy Game AI Research and Competition in StarCraft". IEEE Transactions on Computational Intelligence and AI in Games 5 (4): 293–311. doi:10.1109/TCIAIG.2013.2286295. https://dx.doi.org/10.1109%2FTCIAIG.2013.2286295
- "Facebook Quietly Enters StarCraft War for AI Bots, and Loses". WIRED. 2017. https://www.wired.com/story/facebook-quietly-enters-starcraft-war-for-ai-bots-and-loses/.
- "ILSVRC2017" (in en). http://image-net.org/challenges/LSVRC/2017/.
- Schoenick, Carissa; Clark, Peter; Tafjord, Oyvind; Turney, Peter; Etzioni, Oren (23 August 2017). "Moving beyond the Turing Test with the Allen AI Science Challenge". Communications of the ACM 60 (9): 60–64. doi:10.1145/3122814. https://dx.doi.org/10.1145%2F3122814
- O'Brien, James; Marakas, George (2011). Management Information Systems (10th ed.). McGraw-Hill/Irwin. ISBN 978-0-07-337681-3.
- Hernandez-Orallo, Jose (2000). "Beyond the Turing Test". Journal of Logic, Language and Information 9 (4): 447–466. doi:10.1023/A:1008367325700. https://dx.doi.org/10.1023%2FA%3A1008367325700
- Dowe, D. L.; Hajek, A. R. (1997). "A computational extension to the Turing Test". Proceedings of the 4th Conference of the Australasian Cognitive Science Society. http://www.csse.monash.edu.au/publications/1997/tr-cs97-322-abs.html.
- Hernandez-Orallo, J.; Dowe, D. L. (2010). "Measuring Universal Intelligence: Towards an Anytime Intelligence Test". Artificial Intelligence 174 (18): 1508–1539. doi:10.1016/j.artint.2010.09.006. https://dx.doi.org/10.1016%2Fj.artint.2010.09.006
- Hernández-Orallo, José; Dowe, David L.; Hernández-Lloreda, M.Victoria (March 2014). "Universal psychometrics: Measuring cognitive abilities in the machine kingdom". Cognitive Systems Research 27: 50–74. doi:10.1016/j.cogsys.2013.06.001. https://dx.doi.org/10.1016%2Fj.cogsys.2013.06.001
- Research, AI (23 October 2015). "Deep Neural Networks for Acoustic Modeling in Speech Recognition". http://airesearch.com/ai-research-papers/deep-neural-networks-for-acoustic-modeling-in-speech-recognition/.
- "GPUs Continue to Dominate the AI Accelerator Market for Now" (in en). InformationWeek. December 2019. https://www.informationweek.com/big-data/ai-machine-learning/gpus-continue-to-dominate-the-ai-accelerator-market-for-now/a/d-id/1336475.
- Ray, Tiernan (2019). "AI is changing the entire nature of compute" (in en). ZDNet. https://www.zdnet.com/article/ai-is-changing-the-entire-nature-of-compute/.
- "AI and Compute" (in en). 16 May 2018. https://openai.com/blog/ai-and-compute/.