Molecular Inversion Probe (MIP) belongs to the class of Capture by Circularization molecular techniques for performing genomic partitioning, a process through which one captures and enriches specific regions of the genome. Probes used in this technique are single stranded DNA molecules and, similar to other genomic partitioning techniques, contain sequences that are complementary to the target in the genome; these probes hybridize to and capture the genomic target. MIP stands unique from other genomic partitioning strategies in that MIP probes share the common design of two genomic target complementary segments separated by a linker region. With this design, when the probe hybridizes to the target, it undergoes an inversion in configuration (as suggested by the name of the technique) and circularizes. Specifically, the two target complementary regions at the 5’ and 3’ ends of the probe become adjacent to one another while the internal linker region forms a free hanging loop. The technology has been used extensively in the HapMap project for large-scale SNP genotyping as well as for studying gene copy alterations and characteristics of specific genomic loci to identify biomarkers for different diseases such as cancer. Key strengths of the MIP technology include its high specificity to the target and its scalability for high-throughput, multiplexed analyses where tens of thousands of genomic loci are assayed simultaneously.
- scalability
- circularization
- molecular techniques
1. Technique Procedure
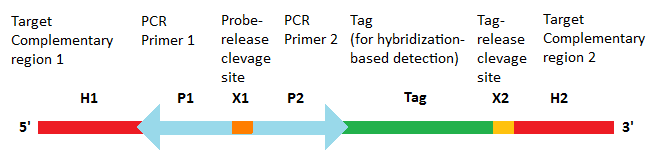
1.1. Molecular Inversion Probe Structure
The probes are designed with sequences that are complementary to the genomic target at its 5’ and 3’ ends .[1][2][3] The internal region contains two universal PCR primer sites that are common to all MIPs as well as a probe-release site, which is usually a restriction site.[2] If the identification of the captured genomic target is performed using array-based hybridization approaches, the internal region may optionally contain a probe-specific tag sequence that uniquely identifies the given probe as well as a tag-release site, which, similar to the probe-release site, is also a restriction site.
1.2. Protocol
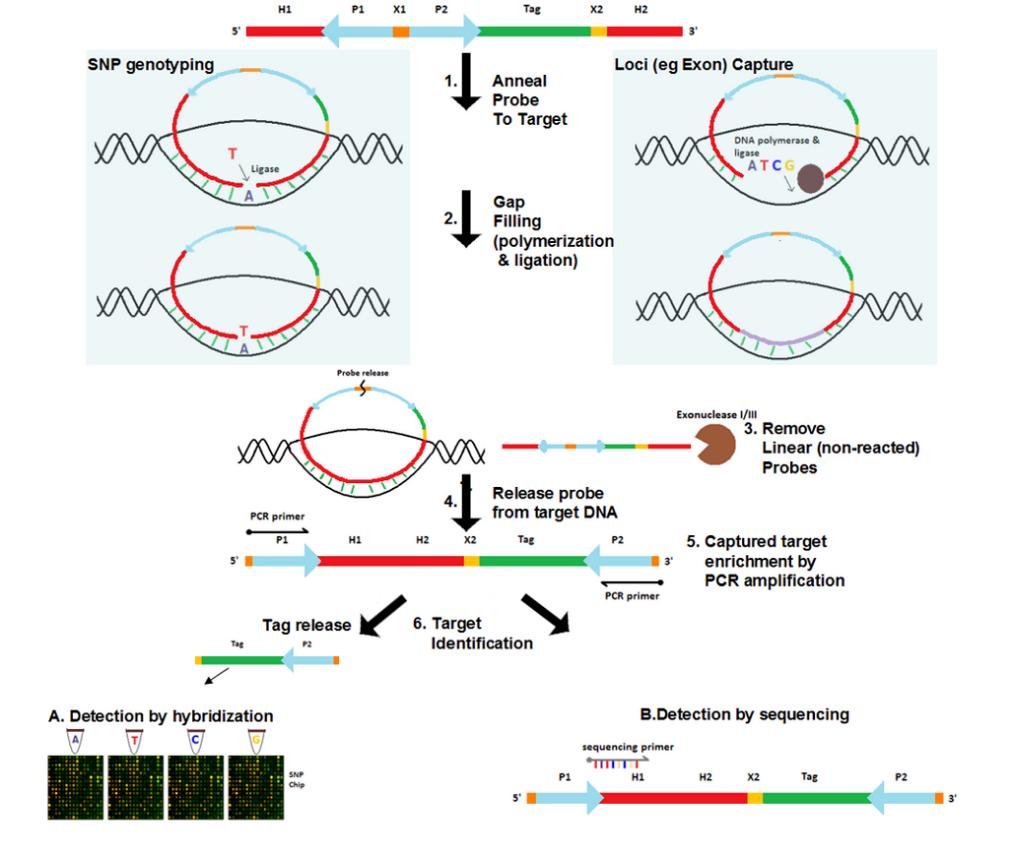
- Anneal probe to genomic target DNA
Probes are added to the genomic DNA sample. After a denaturation followed by an annealing step, the target-complementary ends of the probe are hybridized to the target DNA. The probes then undergo circularization in this process. These probes, however, are designed such that a gap delimited by the hybridized ends of the probes remains over the target region. The size of the gap ranges from a single nucleotide for SNP genotyping [2] to several hundred nucleotides for loci capture (e.g. exome capture).[4]
- Gap filling
The gap is filled by DNA polymerase using free nucleotides and the ends of the probe are ligated by ligase, resulting in a fully circularized probe.
- Remove non-reacted probes
Since gap filling is not performed for non-reacted probes, they remain linear. Exonuclease treatment removes these non-reacted probes as well as any remaining linear DNA in the reaction.
- Probe release
In some versions of the protocol, the probe-release site (commonly a restriction site) is cleaved by restriction enzymes such that the probe becomes linearized. In this linearized probe the universal PCR primer sequences are located at the 5’ and 3’ ends and the captured genomic target becomes part of the internal segment of the probe. Other protocols leave the probe as a circularized molecule.
- Captured target enrichment
If the probe is linearized, traditional PCR amplification is performed to enrich the captured target using the universal primers of the probe. Otherwise, rolling circle amplification is performed for the circular probe.
- Captured target identification
The captured target can be identified either via array-based hybridization approaches [2] or by sequencing of the target.[4] If array-based approach is used, the probe may optionally contain a probe-specific tag that uniquely identifies the probe as well as the genomic region targeted by it. The tags from each probe are released by cleaving the tag release site with restriction enzymes. These tags are then hybridized to the sequences that are placed on the array and are complementary to them. The captured target can also be identified by sequencing the probe, now also containing the target. Traditional Sanger sequencing or cheaper, more high-throughput technologies such as SOLiD, Illumina or Roche 454 can be used for this purpose.
Multiplex analysis
Although each probe examines one specific genomic locus, multiple probes can be combined into a single tube for multiplexed assay that simultaneously examines multiple loci. Currently, multiplexed MIP analysis can examine more than 55,000 loci in a single assay.[1]
2. Technique Development History
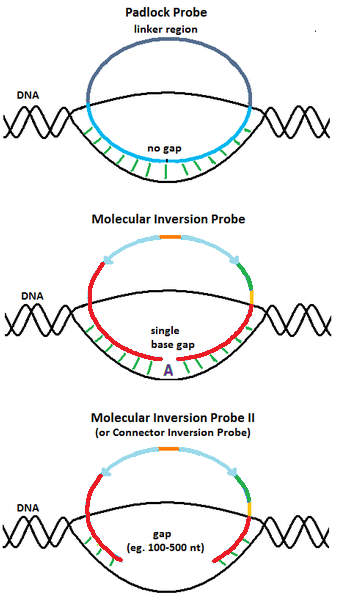
2.1. Padlock Probe
The design of the molecular inversion probes (MIP) originated from padlock probes, a molecular biology technique first reported by Nilsson et al. in 1994 .[5] Similar to MIP, padlock probes are single stranded DNA molecules with two 20-nucleotide long segments complementary to the target connected by a 40-nucleotide long linker sequence. When the target complementary regions are hybridized to the DNA target, the padlock probes also become circularized. However, unlike MIP, padlock probes are designed such that the target complementary regions span the entire target region upon hybridization, leaving no gaps. Thus, padlock probes are only useful for detecting DNA molecules with known sequences.
Nilsson et al.[5] demonstrated the use of padlock probes to detect numerous DNA targets, including a synthetic oligonucleotide and a circular genomic clone. Padlock probes have high specificity towards their target and can distinguish target molecules that closely resemble one another. Nilsson et al.[5] also demonstrated the use of padlock probes to differentiate between a normal and a mutant cystic fibrosis conductance receptor (CFCR) where the CFCR mutant had a 3bp deletion corresponding to one of the ends of the probe. Since ligation requires the ends of the probe to be immediately adjacent to one another when hybridized to the target, the 3bp deletion in the mutant prevented successful ligation. Padlock probes were also successfully used for in situ hybridization to detect alphoid repeats specific to chromosome 12 in a sample of chromosomes in metastasis state. Here, traditional, linear oligonucleotide probes failed to yield results.[5] Thus, padlock probes possess sufficient specificity to detect single copy elements in the genome.[5]
2.2. Molecular Inversion Probe
In order to perform SNP genotyping, Hardenbol et al.[2] modified padlock probes such that when the probe is hybridized to the genomic target, there is a gap at the SNP position. Gap filling using a nucleotide that is complementary to the nucleotide at the SNP location determines the identity of the polymorphism. This design brings numerous benefits over the more traditional padlock probe technique. Using multiple padlock probes specific to a plausible SNP requires careful balancing of the concentration of these allele specific probes to ensure SNP counts at a given locus are properly normalized.[2] In addition, with this design, bad probes affect all genotypes at a given locus equally.[2] For instance, since MIP probes can assay multiple genotypes at a particular genomic locus, if the probe for a given locus does not work (e.g. fails to properly hybridize to the genomic target), none of the genotypes at this locus will be detected. In contrast, for padlock probes, one needs to design a distinct padlock probe to detect each plausible genotype a given locus (e.g. one padlock probe is needed for detecting "A" at a given SNP locus and another padlock probe is needed for detecting "T" at the locus). Thus, a bad padlock probe will only affect the detection of the specific genotype that the probe is designed to detect whereas a bad MIP probe will affect all genotypes at the locus. Using MIP, one avoids potential incorrect SNP calling since if the probe designed to assay a given locus does not work, no data is generated for this locus and no SNP calling is performed.
In their procedure, Hardenbol et al.[2] assayed more than 1000 SNP loci simultaneously in a single tube where the tube contained more than 1000 probes with distinct designs. The pool of probes was aliquoted into four tubes for four different reactions. In each reaction, a distinct nucleotide (A, T, C or G) was used for gap filling. Only when the nucleotide at the SNP locus was complementary to the applied nucleotide would the gap be closed by ligation and the probe be circularized. Identification of the captured SNPs was performed on genotyping arrays where each spot on the array contained sequences complementary to the locus-specific tags in the probes. Since the DNA array costs is a major contributor to the cost of this technique, the performance of four-chip-one-color detection was compared to two-chip-two color detection. The results were found to be similar in terms of SNP call rate and signal-to-noise ratio.[2]
In a recent report,[3] this group successfully increased the level of multiplexing to simultaneously assay more than 10,000 SNP loci, using 12,000 distinct probes. The study examined SNP polymorphisms in 30 trio samples (each trio consisted of a mother, father and their child). Knowing the genotypes of the parents, the accuracy of the SNP genotypes predicted in the child was determined by examining whether a concordance existed between the expected Mendelian inheritance patterns and the predicted genotypes. Trio concordance rate has been found to be > 99.6%.[6] In addition, a set of MIP-specific performance metrics was developed. This work set the framework for high-throughput SNP genotyping in the HapMap project.[3]
2.3. Connector Inversion Probe
To capture longer genomic regions than a single nucleotide, Akhras et al.[4] modified the design of MIP by extending the gap delimited by the hybridized probe ends and named the design Connector Inversion Probe (CIP). The gap corresponds to the genomic region of interest to be captured (e.g. exons). Gap filling reaction is achieved with DNA polymerase, using all four nucleotides. Identification of the captured regions can then be done by sequencing them using locus-specific primers that map to one of the target complementary ends of the probes.
Akhras et al.[4] also developed the multiplexing multiplex padlocks (MMP) barcode system in order to lower the costs of reagents. A single assay might involve DNA samples from multiple individuals and examine multiple genomic loci in each individual. A DNA barcode system that uniquely identifies each plausible combination of individual and genomic locus is represented as DNA tags that were inserted into the linker region of the probes. Thus, sequences from the captured regions would include the barcode, allowing the non-ambiguous determination of the individual and the genomic locus that the captured region belongs to.
This group has also developed a software for designing locus-specific CIPs (CIP creator 1.0.1).
3. Application
Molecular Inversion Probe (MIP) is one of the techniques widely used to capture a small region of the genome for further examination. With the invention of the next generation sequencing technologies, the cost of sequencing whole genomes has decreased dramatically, however the cost is still too high for these sequencing machines to be used in practice in every laboratory. Instead, different genome partitioning techniques can be used to isolate smaller but highly specific regions of the genome for further analysis. MIP, for instance, can be used to capture targets for SNPgenotyping, copy number variation or allelic imbalance studies, to name a few.
3.1. SNP Genotyping
In SNP genotyping, the probes are separated into four reactions and a different type of nucleotide is added to each reaction. If the SNP at the target region is complementary to the added nucleotide, the ligation is successful and the probe becomes fully circularized. Since each probe hybridizes to exactly one SNP target in the genome, successfully circularized probes provide the nucleotide identities of the SNPs. The tag sequences from the four nucleotide-specific reactions are then hybridized to either four genotyping arrays or two, dual-colour arrays (one channel for each reaction). Analyzing which spots on the array are bound by the tags allows the determination of the SNP identities at the genomic loci represented by those tags.
The SNPs targeted by MIP can then be used in areas of research such as quantitative trait loci (QTL) analysis or genome-wide association studies (GWAS) where the SNPs are used in either indirect linkage disequilibrium studies or directly screened for causative mutations.
3.2. Copy Number Variation Detection
Molecular inversion probe technique can also be used for copy number variation (CNV) detection. This dual role in SNP genotyping as well as CNV analysis of MIP is similar to the high-density SNP genotyping arrays which have recently been used for CNV detection and analysis as well. These techniques extract the allele-specific signal intensities from genotyping data and use that to generate CNV results. These techniques have higher precision and resolution than traditional techniques such as G-banded karyotypic analyses, fluorescence in situ hybridization (FISH) or array comparative genomic hybridization (aCGH).
4. Current Research
MIP has been used extensively in many areas of research; some of the examples of the use of this technique in recent literature are outlined below:
- Molecular inversion probe technique has been used in studying childhood brain tumors, the most common solid pediatric cancer and the leading cause of pediatric cancer mortality. Despite their high prevalence, little is known about the genetic events that contribute to the development and progression of pediatric gliomas. MIP has identified novel areas of copy number events in this cancer using minimal DNA. Identification of these events can in return lead to the understanding of the underlying mechanism of this disease.[7]
- 45 pediatric leukemia samples were analyzed for gene copy aberrations using molecular inversion probe technology. The MIP analysis identified 69 regions of recurring copy number changes, of which 41 have not been identified with other DNA microarray platforms. Copy number gains and losses were validated in 98% of clinical karyotypes and 100% of fluorescence in situ hybridization studies available.[8]
- In another study, the MIP was used to identify the association between the polymorphisms and haplotypes in the caspase-3, caspase-7, and caspase-8 genes and the risk for endometrial cancer.[9]
- A recent study has demonstrated the success of MIP for copy number variation and genotyping studies in formalin-fixed paraffin embedded samples. These banked samples, usually with extensive follow-up information, underperform or suffer high failure rates compared to fresh frozen samples because of DNA degradation and cross-linking during the fixation and processing. The study, however, successfully applied MIP to obtain high quality copy number and genotyping data from formalin-fixed paraffin embedded samples.[10]
- Molecular inversion probe technique has also been used in the field of pharmacogenomics. Genotyping of genes important in drug metabolism, excretion and transport using MIP has paved the way in understanding the patient-to-patient variability in responses to drugs.[11]
5. MIP Design and Optimization
5.1. Probe Design Optimization Strategies
To optimize the degree of multiplexing and the lengths of the captured regions, a number of factors should be considered when designing probes:[1]
- The sequences of the probe that are complementary to the DNA target must be specific and map only to unique regions with reasonable sequence complexity in the genome . Genomic regions containing repeats should be treated with caution.
- For all probes used in a single assay, the annealing temperatures of the two target complementary ends of the probes should be similar such that hybridization of the two ends to their targets can be achieved at the same temperature.[2]
- The GC content of the genomic targets should be similar and the targets lengths variability should be restricted such that all gaps can be filled under similar elongation timeframes.[1]
- The lengths of the genomic targets cannot be too long (current successful applications worked with 100 to 200bp target lengths[1]), otherwise steric effects may interfere with successful hybridization of the probes to their targets.[1]
- The tags from each probe used for microarray-based captured region identification should have similar melting temperatures as well as maximal orthogonal base complexities. These ensure that all tags can be hybridized to the array under similar conditions and that cross-hybridizations are minimized, respectively.
5.2. MIP Protocol Optimization Strategies
A number of experimental conditions can be modified for optimization,[1] these include:
- Hybridization and gap-fill time
- Probes, Ligase and DNA polymerase concentrations
- Enrichment of the captured target by either rolling circle amplification or linearizing the probes to perform multi-template PCR using the universal primers, common for all probes
- Captured target identification via either array-based hybridization approaches or direct sequencing of the target
These factors are critical since in one study, proper optimization strategies increased target capture efficiency from 18 to 91 percent.[12]
6. Performance Metrics
Turner et al. 2009[1] summarized two metrics that are commonly reported in MIP-based genomic capture experiments that identify the target by sequencing.
- Capture Uniformity: analogous to recall – the fraction of genomic targets that are captured with confidence. Specifically, the relative abundance of sequence reads that are mapped to each genomic target.
- Capture Specificity: analogous to precision – the fraction of sequence reads that actually map to the genomic targets of interest.
These two metrics are directly affected by the quality of the batch of probes. To improve the results for low quality probes, higher levels of sequencing depths can be performed. The amount of sequencing scales needed nearly exponentially with decreases in uniformity and specificity.
Hardenbol et al. 2005[3] proposed a set of metrics that concern SNP genotyping using MIPs.
- Single/noise ratio: Ratio of true genotype counts over background counts
- Probe conversion rate: Number of genomic SNP loci for which probes can be designed and successfully assayed. In other words, this metric concerns the fraction of probes that produce genotyping results.
- Call rate: For a given SNP locus, the number of DNA samples whose genotypes at this locus can be measured. In other words, the number of supporting evidence for the genotype(s) assigned to the given SNP locus.
- Completeness: For the set of SNPs assayed, the total fraction of genotypes that are successfully obtained.
- Accuracy: For the set of SNPs assayed, the fraction detected genotypes that are correct. This is commonly measured by the repeatability of the results.
An inherent trade-off exists between probe conversion rate and accuracy. Removing probes that yielded incorrect genotypes increases the accuracy but decreases the probe conversion rate. In contrast, using a lenient probe acceptance threshold increases probe conversion rate but decreases the accuracy.[3]
7. Other Genomic Partitioning Techniques
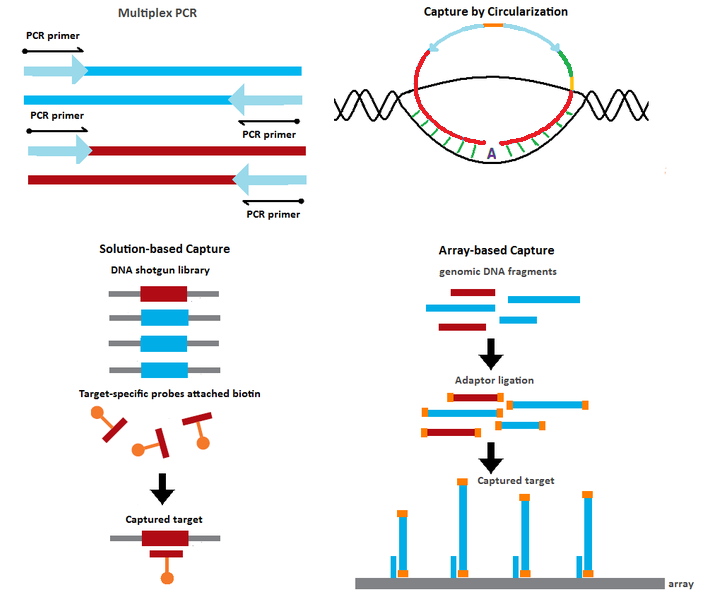
To reduce the costs from sequencing whole genomes, many methods that enrich specific genomic regions of interest have been proposed.
| Technique | Details | Multiplex Levela |
|---|---|---|
| Multiplex PCR[13] | Target enrichment by PCR amplification of the genomic targets using multiple target-specific primer sets | 102 - 103 |
| Capture by Circularization[2][3][4][14][15] | Target capture using probes containing sequences complementary to the target Hybridization of the probes to their targets results in circularized products Target enrichment via rolling circle amplification or PCR using universal primers |
104 - 105 |
| Solution-based Capture[16] | Genomic DNA shotgun fragments in solution captured by biotinylated probes with sequences complementary to the desired targets |
104 - 105 |
| Array-based Capture[17] | Genomic DNA shotgun fragments captured on microarray containing spots with sequences complementary to the desired targets | 105 - 106 |
| aThe number of genomic loci that can be assayed in a single run | ||
7.1. Other Capture by Circularization Methods
Gene selector method:[14] An initial multiplex PCR step is performed to enrich the targets of interest. The PCR products are circularized upon hybridization to target-specific probes with sequences complementary to the two primers used in the PCR step.
Capture by selective circularization method:[15] The genomic DNA is digested into fragments with restriction enzymes. Using selector probes with flanking regions that are complementary to the target of interest, the digested DNA fragments are circularized upon hybridization to the selector probes.
7.2. Performance Comparisons between Genomic Partitioning Techniques
Each method demonstrates trade offs between uniformity, capture specificity, cost, scalability and availability.
- In terms of capture specificity, Capture by Circularization methods demonstrate the best results. This is due to the fact that all methods in this class require two ends of the same DNA molecule (e.g. two ends of MIP probes) to simultaneously bind to a single cognate partner molecule (e.g. genomic target region) in the proper configuration for successful ligation.
- In contrast, Capture by Circularization methods demonstrate less uniformity compared to other methods. This is because the probe design for each distinct genomic target is unique and thus the performance between individual probes may vary.
- Regarding scalability, high specificity of Capture by Circularization and Solution-based Capture methods make them the most appropriate for studies which involve large number of genomic targets and many samples. Array-based Capture techniques are appropriate for studying many genomic targets but with fewer samples due to limited resolution and specificity of microarrays. Multiplex PCR methods are most appropriate for small-scale studies due to it ease of use and availability of reagents.
- The costs associated with each technique are difficult to compare given the vast choices of designs and experimental conditions. However, for every technique, attaining a high multiplexing level where many loci are assayed simultaneously amortizes the costs.
8. Advantages of MIP
- Unlike some of the other genotyping techniques, the need to PCR amplify the DNA sample prior to MIP application is eliminated. This is beneficial when examining a large number of target sequences simultaneously when cross-talk between primer pairs is likely to happen[2]
- High specificity: High specificity is achieved by that
i) Unlike other highly multiplexed genotyping techniques, MIP utilizes enzymatic steps (DNA polymerization and ligation) in solution to capture specific loci, which is then followed by an amplification step. Such a combination of enzymatic steps confers a high degree of specificity on the MIP assay[18]
ii) Exonuclease treatment removes non-reacted, linear probes
iii) The tag sequences are selected in a way to increase specificity at hybridization and thus prevent cross-talk at the detection step[2]
iv) Target complementary sequences at both ends of the probe are physically limited to interact locally[2] - Built-in quality control of the signal to noise ratio: the MIP technique examines the possibility of all four bases for each SNP position. A homozygous SNP is expected to have a single signal and a heterozygous SNP to have two signals. Thus, the signal to noise ratio can be monitored using the background alleles and if a call has a suspicious signal, it can be discarded from the downstream analysis[2]
- High levels of multiplexing (on the order of 104-105 probes in one assay) can be achieved[1]
- Low amount of sample DNA (e.g. 0.2 ng/SNP [2]) is needed since the MIP probes can be applied directly to genomic DNA instead of shotgun libraries
- High concordance: trio concordance rate is found to be > 99.6%[6]
- Reproducibility: genotyping the same individual several times showed that the genotyped SNPs were concordant (99.9%)[2]
- High dynamic range: in CNV detection studies, up to 60 copies of amplified regions can be detected in the genome[18]
- Since MIP requires only 40 base-pairs of intact genomic DNA, its use in degraded samples, such as formaldehyde fixed paraffin embedded samples, may offer distinct advantages[18]
- Simple infrastructure (only common bench-top reagents and tools are required) and simple design make this technique broadly applicable in many laboratories
- The choices of the platform for identifying the captured target are very flexible such that cost-efficiency may be improved. For instance, the captured targets can be directly sequenced, bypassing the need for sequencing library construction.
9. Limitations of MIP
- Sensitivity and uniformity are relatively low compared to other genomic capture techniques since not all targets can be captured under the same experimental conditions for high-throughput runs that involve multiple probes. However, a recent study that used probes with longer linker regions improved uniformity.[19]
- The plausible sizes of the target that can be captured are limited since
i) Large gap region leads to steric constraints[1] for the intramolecular circularization of the probe and
ii) Large gap requires longer probes be synthesized, increasing the costs. - The degree of multiplexing is constrained by the multiplexing capability of the method chosen for target identification. If array-based detection methods are used, the number of targets that can be assayed is limited by the available spots on the array.
- Since a distinct probe is needed to capture each region, it is costly to assay many regions. However, with multiplexity, the costs are amortized. For instance, at a multiplexity level of 1000, the costs become $0.01 per probe for each assay.[2]
- MIP reaction conditions may require optimization, which is particularly important for assaying heterozygotic sites.[12]
The content is sourced from: https://handwiki.org/wiki/Biology:Molecular_Inversion_Probe
References
- "Methods for genomic partitioning". Annu Rev Genom Hum Genet 10: 263–284. 2009. doi:10.1146/annurev-genom-082908-150112. PMID 19630561. https://semanticscholar.org/paper/c59da5528210c8756e6830a3c1a4543f7323b9cf.
- "Multiplexed genotyping with sequence-tagged molecular inversion probes". Nat Biotechnol 21 (6): 673–678. 2003. doi:10.1038/nbt821. PMID 12730666. https://dx.doi.org/10.1038%2Fnbt821
- "Highly multiplexed molecular inversion probe genotyping: over 10,000 targeted SNPs genotyped in a single tube assay". Genome Res 15 (2): 269–275. 2005. doi:10.1101/gr.3185605. PMID 15687290. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=546528
- Hall, Neil, ed (2007). "Connector inversion probe technology: a powerful one-primer multiplex DNA amplification system for numerous scientific applications". PLoS ONE 2 (9): e195. doi:10.1371/journal.pone.0000915. PMID 17878950. Bibcode: 2007PLoSO...2..915A. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=1976392
- "Padlock probes: circularizing oligonucleotides for localized DNA detection". Science 265 (5181): 2085–2088. 1994. doi:10.1126/science.7522346. PMID 7522346. Bibcode: 1994Sci...265.2085N. https://dx.doi.org/10.1126%2Fscience.7522346
- Absalan, Farnaz; Mostafa Ronaghi (2008). Molecular Inversion Probe Assay. Methods in Molecular Biology. 396. Humana Press. pp. 315–330. doi:10.1007/978-1-59745-515-2. ISBN 978-1-934115-37-4. https://dx.doi.org/10.1007%2F978-1-59745-515-2
- J. D. Schiffman; Y. Wang; S. R. Vandenberg; P. G. Fisher; J. M. Ford; H. Ji; J. G. Hodgson (2008). "Molecular inversion probes (MIPs) identify novel copy number changes in pediatric gliomas". Journal of Clinical Oncology 26 (15_suppl): 13006. doi:10.1200/jco.2008.26.15_suppl.13006. https://dx.doi.org/10.1200%2Fjco.2008.26.15_suppl.13006
- Joshua D. Schiffman; Yuker Wang; Lisa A. McPherson; Katrina Welch; Nancy Zhang; Ronald Davis; Norman J. Lacayo; Gary V. Dahl et al. (2009). "Molecular inversion probes reveal patterns of 9p21 deletion and copy number aberrations in childhood leukemia". Cancer Genet Cytogenet 193 (1): 9–18. doi:10.1016/j.cancergencyto.2009.03.005. PMID 19602459. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2776674
- "Polymorphisms and haplotypes in the caspase-3, caspase-7, and caspase-8 genes and risk for endometrial cancer: a population-based, case-control study in a Chinese population". Cancer Epidemiol Biomarkers Prev 18 (7): 2114–22. 2009. doi:10.1158/1055-9965.EPI-09-0152. PMID 19531679. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2764360
- "High quality copy number and genotype data from FFPE samples using Molecular Inversion Probe (MIP) microarrays". BMC Med. Genom. 2: 2–8. 2009. doi:10.1186/1755-8794-2-8. PMID 19228381. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2649948
- "Multiplex assay for comprehensive genotyping of genes involved in drug metabolism, excretion, and transport". Clin Chem 53 (7): 1222–30. 2007. doi:10.1373/clinchem.2007.086348. PMID 17510302. https://dx.doi.org/10.1373%2Fclinchem.2007.086348
- "Multiplex amplification of large sets of human exons". Nat Methods 4 (11): 931–936. 2007. doi:10.1038/nmeth1110. PMID 17934468. https://dx.doi.org/10.1038%2Fnmeth1110
- "MegaPlex PCR: a strategy for multiplex amplification". Nat Methods 4 (10): 835–837. 2007. doi:10.1038/nmeth1091. PMID 17873887. https://dx.doi.org/10.1038%2Fnmeth1091
- "Multiplex amplification of all coding sequences within 10 cancer genes by Gene-Collector". Nucleic Acids Res 35 (7): e47. 2007. doi:10.1093/nar/gkm078. PMID 17317684. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=1874629
- "Multiplex amplification enabled by selective circularization of large sets of genomic DNA fragments". Nucleic Acids Res 33 (8): e71. 2005. doi:10.1093/nar/gni070. PMID 15860768. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=1087789
- "Direct genomic selection". Nat Methods 2 (1): 63–69. 2005. doi:10.1038/nmeth0105-63. PMID 16152676. https://dx.doi.org/10.1038%2Fnmeth0105-63
- "Direct selection of human genomic loci by microarray hybridization". Nat Methods 4 (11): 903–905. 2007. doi:10.1038/nmeth1111. PMID 17934467. https://dx.doi.org/10.1038%2Fnmeth1111
- "Analysis of molecular inversion probe performance for allele copy number determination". Genome Biol 8 (11): R246. 2007. doi:10.1186/gb-2007-8-11-r246. PMID 18028543. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2258201
- "A comprehensive assay for targeted multiplex amplification of human DNA sequences". Proc Natl Acad Sci U S A 105 (27): 9296–9301. 2008. doi:10.1073/pnas.0803240105. PMID 18599465. Bibcode: 2008PNAS..105.9296K. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2442818