The Biomolecular Object Network Databank is a bioinformatics databank containing information on small molecule structures and interactions. The databank integrates a number of existing databases to provide a comprehensive overview of the information currently available for a given molecule.
- biomolecular
- small molecule
- bioinformatics
1. Background
The Blueprint Initiative started as a research program in the lab of Dr. Christopher Hogue at the Samuel Lunenfeld Research Institute at Mount Sinai Hospital in Toronto. On December 14, 2005 Unleashed Informatics Limited acquired the commercial rights to The Blueprint Initiative intellectual property. This included rights to the protein interaction database BIND, the small molecule interaction database SMID, as well as the data warehouse SeqHound. Unleashed Informatics is a data management service provider and is overseeing the management and curation of The Blueprint Initiative under the guidance of Dr. Hogue.[1]
2. Construction
BOND integrates the original Blueprint Initiative databases as well as other databases, such as Genbank, combined with many tools required to analyze these data. Annotation links for sequences, including taxon identifiers, redundant sequences, Gene Ontology descriptions, Online Mendelian Inheritance in Man identifiers, conserved domains, data base cross-references, LocusLink Identifiers and complete genomes are also available. BOND facilitates cross-database queries and is an open access resource which integrates interaction and sequence data.[2]
3. Small Molecule Interaction Database (SMID)
The Small Molecule Interaction Database is a database containing protein domain-small molecule interactions. It uses a domain-based approach to identify domain families, found in the Conserved Domain Database (CDD), which interact with a query small molecule. The CDD from NCBI amalgamates data from several different sources; Protein FAMilies (PFAM), Simple Modular Architecture Research Tool (SMART), Cluster of Orthologous Genes (COGs), and NCBI’s own curated sequences. The data in SMID is derived from the Protein Data Bank (PDB), a database of known protein crystal structures. SMID can be queried by entering a protein GI, domain identifier, PDB ID or SMID ID. The results of a search provide small molecule, protein, and domain information for each interaction identified in the database. Interactions with non-biological contacts are normally screened out by default.
SMID-BLAST is a tool developed to annotate known small-molecule binding sites as well as to predict binding sites in proteins whose crystal structures have not yet been determined. The prediction is based on extrapolation of known interactions, found in the PDB, to interactions between an uncrystallized protein with a small molecule of interest. SMID-BLAST was validated against a test set of known small molecule interactions from the PDB. It was shown to be an accurate predictor of protein-small molecule interactions; 60% of predicted interactions identically matched the PDB annotated binding site, and of these 73% had greater than 80% of the binding residues of the protein correctly identified. Hogue, C et al. estimated that 45% of predictions that were not observed in the PDB data do in fact represent true positives.[3]
4. Biomolecular Interaction Network Database (BIND)
4.1. Introduction
The idea of a database to document all known molecular interactions was originally put forth by Tony Pawson in the 1990s and was later developed by scientists at the University of Toronto in collaboration with the University of British Columbia. The development of the Biomolecular Interaction Network Database (BIND) has been supported by grants from the Canadian Institutes of Health Research (CIHR), Genome Canada,[4] the Canadian Foundation for Innovation and the Ontario Research and Development Fund. BIND was originally designed to be a constantly growing depository for information regarding biomolecular interactions, molecular complexes and pathways. As proteomics is a rapidly advancing field, there is a need to have information from scientific journals readily available to researchers. BIND facilitates the understanding of molecular interactions and pathways involved in cellular processes and will eventually give scientists a better understanding of developmental processes and disease pathogenesis
The major goals of the BIND project are: to create a public proteomics resource that is available to all; to create a platform to enable datamining from other sources (PreBIND); to create a platform capable of presenting visualizations of complex molecular interactions. From the beginning, BIND has been open access and software can be freely distributed and modified. Currently, BIND includes a data specification, a database and associated data mining and visualization tools. Eventually, it is hoped that BIND will be a collection of all the interactions occurring in each of the major model organisms.
4.2. Database Structure
BIND contains information on three types of data: interactions, molecular complexes and pathways.
- Interactions are the basic component of BIND and describe how 2 or more objects (A and B) interact with each other. The objects can be a variety of things: DNA, RNA, genes, proteins, ligands, or photons. The interaction entry contains the most information about a molecule; it provides information on its name and synonyms, where it is found (e.g. where in the cell, what species, when it is active, etc.), and its sequence or where its sequence can be found. The interaction entry also outlines the experimental conditions required to observe binding in vitro, chemical dynamics (including thermodynamics and kinetics).
- The second type of BIND entries are the molecular complexes. Molecular complexes are defined as an aggregate of molecules that are stable and have a function when bound to each other. The record may also contain some information on the role of the complex in various interactions and the molecular complex entry links data from 2 or more interaction records.
- The third component of BIND is the pathway record section. A pathway consists of a network of interactions that are involved in the regulation of cellular processes. This section may also contain information on phenotypes and diseases related to the pathway.
The minimum amount of information needed to create an entry in BIND is a PubMed publication reference and an entry in another database (e.g. GenBank). Each entry within the database provides references/authors for the data. As BIND is a constantly growing database, all components of BIND track updates and changes.[5]
BIND is based on a data specification written using Abstract Syntax Notation 1 (ASN.1) language. ASN.1 is used also by NCBI when storing data for their Entrez system and because of this BIND uses the same standards as NCBI for data representation. The ASN.1 language is preferred because it can be easily translated into other data specification languages (e.g. XML), can easily handle complex data and can be applied to all biological interactions – not just proteins.[5] Bader and Hogue (2000) have prepared a detailed manuscript on the ASN.1 data specification used by BIND.[6]
4.3. Data Submission and Curation
User submission to the database is encouraged. To contribute to the database, one must submit: contact info, PubMed identifier and the two molecules that interact. The person who submits a record is the owner of it. All records are validated before being made public and BIND is curated for quality assurance. BIND curation has two tracks: high-throughput (HTP) and low-throughput (LTP). HTP records are from papers which have reported more than 40 interaction results from one experimental methodology. HTP curators typically have a bioinformatics backgrounds. The HTP curators are responsible for the collection of storage of experimental data and they also create scripts to update BIND based on new publications. LTP records are curated by individuals with either an MSc or PhD and laboratory experience in interaction research. LTP curators are given further training through the Canadian Bioinformatics Workshops. Information on small molecule chemistry is curated separately by chemists to ensure the curator is knowledgeable about the subject. The priority for BIND curation is to focus on LTP to collect information as it is published. Although, HTP studies provide more information at once, there are more LTP studies being reported and similar numbers of interactions are being reported by both tracks. In 2004, BIND collected data from 110 journals.[7]
4.4. Database Growth
BIND has grown significantly since its conception; in fact, the database saw a 10 fold increase in entries between 2003 and 2004. By September 2004, there were over 100,000 interaction records by 2004 (including 58,266 protein-protein, 4,225 genetic, 874 protein-small molecule, 25,857 protein-DNA, and 19,348 biopolymer interactions). The database also contains sequence information for 31,972 proteins, 4560 DNA samples and 759 RNA samples. These entries have been collected from 11,649 publications; therefore, the database represents an important amalgamation of data. The organisms with entries in the database include: Saccharomyces cerevisiae, Drosophila melanogaster, Homo sapiens, Mus musculus, Caenorhabditis elegans, Helicobacter pylori, Bos taurus, HIV-1, Gallus gallus, Arabidopsis thaliana, as well as others. In total, 901 taxa were included by September 2004 and BIND has been split up into BIND-Metazoa, BIND-Fungi, and BIND-Taxroot.[7]
Not only is the information contained within the database continually updated, the software itself has gone through several revisions. Version 1.0 of BIND was released in 1999 and based on user feedback it was modified to include additional detail on experimental conditions required for binding and a hierarchical description of cellular location of the interaction. Version 2.0 was released in 2001 and included the capability to link to information available in other databases.[5] Version 3.0 (2002) expanded the database from physical/biochemical interactions to also include genetic interactions.[8] Version 3.5 (2004) included a refined user-interface that aimed to simplify information retrieval.[7] In 2006, BIND was incorporated into the Biomolecular Object Network Database (BOND) where it continues to be updated and improved.
4.5. Special Features
BIND was the first database of its kind to contain info on biomolecular interactions, reactions and pathways in one schema. It is also the first to base its ontology on chemistry which allows 3D representation of molecular interactions. The underlying chemistry allows molecular interactions to be described down to the atomic level of resolution.[7]
PreBIND an associated system for data mining to locate biomolecular interaction information in the scientific literature. The name or accession number of a protein can be entered and PreBIND will scan the literature and return a list of potentially interacting proteins. BIND BLAST is also available to find interactions with proteins that are similar to the one specified in the query.[7]
BIND offers several “features” that many other proteomics databases do not include. The authors of this program have created an extension to traditional IUPAC nomenclature to help describe post-translational modifications that occur to amino acids. These modifications include: acetylation, formylation, methylation, palmitoylation, etc. the extension of the traditional IUPAC codes allows these amino acids to be represented in sequence form as well. BIND also utilizes a unique visualization tool known as OntoGlyphs. The OntoGlyphs were developed based on Gene Ontology (GO) and provide a link back to the original GO information. A number of GO terms have been grouped into categories, each one representing a specific function, binding specificity, or localization in the cell. There are 83 OntoGlyph characters in total. There are 34 functional OntoGlyphs which contain information about the role of the molecule (e.g. cell physiology, ion transport, signaling). There are 25 binding OntoGlyphs which describe what the molecule binds (e.g. ligands, DNA, ions). The other 24 OntoGlyphs provide information about the location of the molecule within a cell (e.g. nucleus, cytoskeleton). The OntoGlyphs can be selected and manipulated to include or exclude certain characteristics from search results. The visual nature of the OntoGlyphs also facilitates pattern recognition when looking at search results.[7] ProteoGlyphs are graphical representations of the structural and binding properties of proteins at the level of conserved domains. The protein is diagrammed as a straight horizontal line and glyphs are inserted to represent conserved domains. Each glyph is displayed to represent the relative position and length of its alignment in the protein sequence.
4.6. Accessing the Database
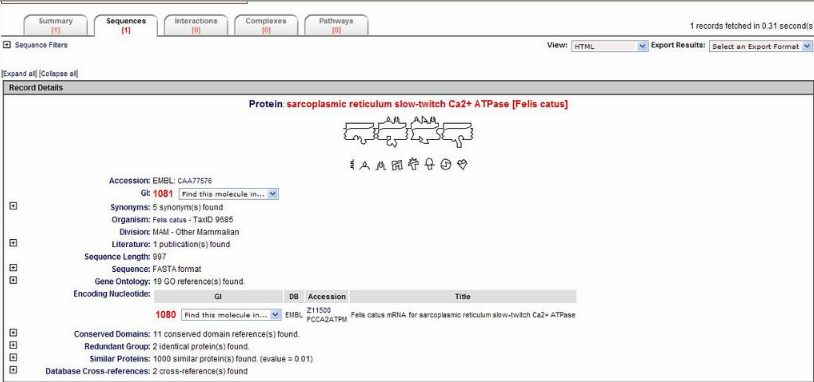
The database user interface is web-based and can be queried using text or accession numbers/identifiers. Since its integration with the other components of BOND, sequences have been added to interactions, molecular complexes and pathways in the results. Records include information on: BIND ID, description of the interaction/complex/pathway, publications, update records, organism, OntoGlyphs, ProteoGlyphs, and links to other databases where additional information can be found. BIND records include various viewing formats (e.g. HTML, ASN.1, XML, FASTA), various formats for exporting results (e.g. ASN.1, XML, GI list, PDF), and visualizations (e.g. Cytoscape). The exact viewing and exporting options vary depending on what type of data has been retrieved.
5. User Statistics
The number of Unleashed Registrants has increased 10 fold since the integration of BIND. As of December 2006 registration fell just short of 10,000. Subscribers to the commercial versions of BOND fall into six general categories; agriculture and food, biotechnology, pharmaceuticals, informatics, materials and other. The biotechnology sector is the largest of these groups, holding 28% of subscriptions. Pharmaceuticals and informatics follow with 22% and 18% respectively. The United States holds the bulk of these subscriptions, 69%. Other countries with access to the commercial versions of BOND include Canada , the United Kingdom , Japan , China , Korea, Germany , France , India and Australia . All of these countries fall below 6% in user share.[2]
The content is sourced from: https://handwiki.org/wiki/Software:Biomolecular_Object_Network_Databank
References
- Blueprint.org http://www.blueprint.org
- BOND at Unleashed Informatics http://bond.unleashedinformatics.com
- Snyder, K, et al.. Domain-based small molecule binding site annotation. BMC Bioinformatics 7: 152 (2006)
- BIND at genomecanada.ca https://www.genomecanada.ca/en/biomolecular-interaction-network-database-bind
- Bader, GD, et al. BIND- The Biomolecular Interaction Network Database. Nucleic Acids Research 29: 242-245 (2001).
- Bader, GD, Hogue, CWV. BIND- a data specification for storing and describing biomolecular interactions, molecular complexes and pathways. Bioinformatics 16(5): 465-477 (2000).
- Alfarano, C, et al. The Biomolecular Interaction Network Database and related tools 2005 update. Nucleic Acids Research 33: D418-D424 (2005).
- Bader, GD, et al.. BIND: the Biomolecular Interaction Network Database. Nucleic Acids Research 31: 248-250 (2003).