Blue Gene is an IBM project aimed at designing supercomputers that can reach operating speeds in the PFLOPS (petaFLOPS) range, with low power consumption. The project created three generations of supercomputers, Blue Gene/L, Blue Gene/P, and Blue Gene/Q. Blue Gene systems have often led the TOP500 and Green500 rankings of the most powerful and most power efficient supercomputers, respectively. Blue Gene systems have also consistently scored top positions in the Graph500 list. The project was awarded the 2009 National Medal of Technology and Innovation. As of 2015, IBM seems to have ended the development of the Blue Gene family though no public announcement has been made. IBM's continuing efforts of the supercomputer scene seems to be concentrated around OpenPower, using accelerators such as FPGAs and GPUs to battle the end of Moore's law.
- petaflops
- pflops
- supercomputer
1. History
In December 1999, IBM announced a US$100 million research initiative for a five-year effort to build a massively parallel computer, to be applied to the study of biomolecular phenomena such as protein folding.[1] The project had two main goals: to advance our understanding of the mechanisms behind protein folding via large-scale simulation, and to explore novel ideas in massively parallel machine architecture and software. Major areas of investigation included: how to use this novel platform to effectively meet its scientific goals, how to make such massively parallel machines more usable, and how to achieve performance targets at a reasonable cost, through novel machine architectures. The initial design for Blue Gene was based on an early version of the Cyclops64 architecture, designed by Monty Denneau. The initial research and development work was pursued at IBM T.J. Watson Research Center and led by William R. Pulleyblank.[2]
At IBM, Alan Gara started working on an extension of the QCDOC architecture into a more general-purpose supercomputer: The 4D nearest-neighbor interconnection network was replaced by a network supporting routing of messages from any node to any other; and a parallel I/O subsystem was added. DOE started funding the development of this system and it became known as Blue Gene/L (L for Light); development of the original Blue Gene system continued under the name Blue Gene/C (C for Cyclops) and, later, Cyclops64.
In November 2004 a 16-rack system, with each rack holding 1,024 compute nodes, achieved first place in the TOP500 list, with a Linpack performance of 70.72 TFLOPS.[3] It thereby overtook NEC's Earth Simulator, which had held the title of the fastest computer in the world since 2002. From 2004 through 2007 the Blue Gene/L installation at LLNL[4] gradually expanded to 104 racks, achieving 478 TFLOPS Linpack and 596 TFLOPS peak. The LLNL BlueGene/L installation held the first position in the TOP500 list for 3.5 years, until in June 2008 it was overtaken by IBM's Cell-based Roadrunner system at Los Alamos National Laboratory, which was the first system to surpass the 1 PetaFLOPS mark. The system was built in Rochester, MN IBM plant.
While the LLNL installation was the largest Blue Gene/L installation, many smaller installations followed. In November 2006, there were 27 computers on the TOP500 list using the Blue Gene/L architecture. All these computers were listed as having an architecture of eServer Blue Gene Solution. For example, three racks of Blue Gene/L were housed at the San Diego Supercomputer Center.
While the TOP500 measures performance on a single benchmark application, Linpack, Blue Gene/L also set records for performance on a wider set of applications. Blue Gene/L was the first supercomputer ever to run over 100 TFLOPS sustained on a real world application, namely a three-dimensional molecular dynamics code (ddcMD), simulating solidification (nucleation and growth processes) of molten metal under high pressure and temperature conditions. This achievement won the 2005 Gordon Bell Prize.
In June 2006, NNSA and IBM announced that Blue Gene/L achieved 207.3 TFLOPS on a quantum chemical application (Qbox).[5] At Supercomputing 2006,[6] Blue Gene/L was awarded the winning prize in all HPC Challenge Classes of awards.[7] In 2007, a team from the IBM Almaden Research Center and the University of Nevada ran an artificial neural network almost half as complex as the brain of a mouse for the equivalent of a second (the network was run at 1/10 of normal speed for 10 seconds).[8]
1.1. Name
The name Blue Gene comes from that it was originally designed to do, help biologists understand the processes of protein folding and gene development.[9] "Blue" is a traditional moniker that IBM uses for many of its products and the company itself. The original Blue Gene design was renamed "Blue Gene/C" and eventually Cyclops64. The "L" in Blue Gene/L comes from "Light" as that design's original name was "Blue Light". The "P" version was designed to be a petascale design. "Q" is just the letter after "P". There is no Blue Gene/R.[10]
1.2. Major Features
The Blue Gene/L supercomputer was unique in the following aspects:[11]
- Trading the speed of processors for lower power consumption. Blue Gene/L used low frequency and low power embedded PowerPC cores with floating point accelerators. While the performance of each chip was relatively low, the system could achieve better performance to energy ratio, for applications that could use larger numbers of nodes.
- Dual processors per node with two working modes: co-processor mode where one processor handles computation and the other handles communication; and virtual-node mode, where both processors are available to run user code, but the processors share both the computation and the communication load.
- System-on-a-chip design. All node components were embedded on one chip, with the exception of 512 MB external DRAM.
- A large number of nodes (scalable in increments of 1024 up to at least 65,536)
- Three-dimensional torus interconnect with auxiliary networks for global communications (broadcast and reductions), I/O, and management
- Lightweight OS per node for minimum system overhead (system noise).
1.3. Architecture
The Blue Gene/L architecture was an evolution of the QCDSP and QCDOC architectures. Each Blue Gene/L Compute or I/O node was a single ASIC with associated DRAM memory chips. The ASIC integrated two 700 MHz PowerPC 440 embedded processors, each with a double-pipeline-double-precision Floating Point Unit (FPU), a cache sub-system with built-in DRAM controller and the logic to support multiple communication sub-systems. The dual FPUs gave each Blue Gene/L node a theoretical peak performance of 5.6 GFLOPS (gigaFLOPS). The two CPUs were not cache coherent with one another.
Compute nodes were packaged two per compute card, with 16 compute cards plus up to 2 I/O nodes per node board. There were 32 node boards per cabinet/rack.[12] By the integration of all essential sub-systems on a single chip, and the use of low-power logic, each Compute or I/O node dissipated low power (about 17 watts, including DRAMs). This allowed aggressive packaging of up to 1024 compute nodes, plus additional I/O nodes, in a standard 19-inch rack, within reasonable limits of electrical power supply and air cooling. The performance metrics, in terms of FLOPS per watt, FLOPS per m2 of floorspace and FLOPS per unit cost, allowed scaling up to very high performance. With so many nodes, component failures were inevitable. The system was able to electrically isolate faulty components, down to a granularity of half a rack (512 compute nodes), to allow the machine to continue to run.
Each Blue Gene/L node was attached to three parallel communications networks: a 3D toroidal network for peer-to-peer communication between compute nodes, a collective network for collective communication (broadcasts and reduce operations), and a global interrupt network for fast barriers. The I/O nodes, which run the Linux operating system, provided communication to storage and external hosts via an Ethernet network. The I/O nodes handled filesystem operations on behalf of the compute nodes. Finally, a separate and private Ethernet network provided access to any node for configuration, booting and diagnostics. To allow multiple programs to run concurrently, a Blue Gene/L system could be partitioned into electronically isolated sets of nodes. The number of nodes in a partition had to be a positive integer power of 2, with at least 25 = 32 nodes. To run a program on Blue Gene/L, a partition of the computer was first to be reserved. The program was then loaded and run on all the nodes within the partition, and no other program could access nodes within the partition while it was in use. Upon completion, the partition nodes were released for future programs to use.
Blue Gene/L compute nodes used a minimal operating system supporting a single user program. Only a subset of POSIX calls was supported, and only one process could run at a time on node in co-processor mode—or one process per CPU in virtual mode. Programmers needed to implement green threads in order to simulate local concurrency. Application development was usually performed in C, C++, or Fortran using MPI for communication. However, some scripting languages such as Ruby[13] and Python[14] have been ported to the compute nodes.
2. Blue Gene/P

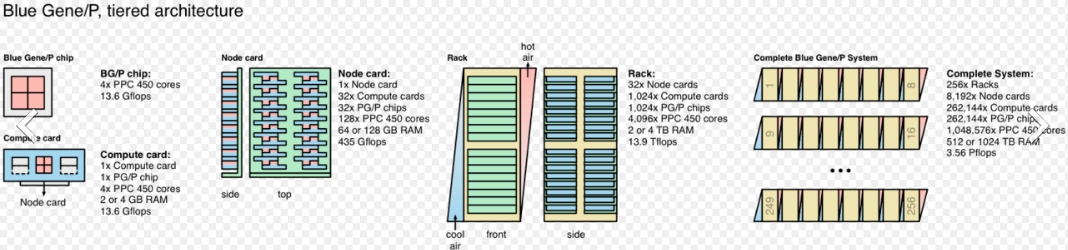
In June 2007, IBM unveiled Blue Gene/P, the second generation of the Blue Gene series of supercomputers and designed through a collaboration that included IBM, LLNL, and Argonne National Laboratory's Leadership Computing Facility.[15]
2.1. Design
The design of Blue Gene/P is a technology evolution from Blue Gene/L. Each Blue Gene/P Compute chip contains four PowerPC 450 processor cores, running at 850 MHz. The cores are cache coherent and the chip can operate as a 4-way symmetric multiprocessor (SMP). The memory subsystem on the chip consists of small private L2 caches, a central shared 8 MB L3 cache, and dual DDR2 memory controllers. The chip also integrates the logic for node-to-node communication, using the same network topologies as Blue Gene/L, but at more than twice the bandwidth. A compute card contains a Blue Gene/P chip with 2 or 4 GB DRAM, comprising a "compute node". A single compute node has a peak performance of 13.6 GFLOPS. 32 Compute cards are plugged into an air-cooled node board. A rack contains 32 node boards (thus 1024 nodes, 4096 processor cores).[16] By using many small, low-power, densely packaged chips, Blue Gene/P exceeded the power efficiency of other supercomputers of its generation, and at 371 MFLOPS/W Blue Gene/P installations ranked at or near the top of the Green500 lists in 2007-2008.[17]
2.2. Installations
The following is an incomplete list of Blue Gene/P installations. Per November 2009, the TOP500 list contained 15 Blue Gene/P installations of 2-racks (2048 nodes, 8192 processor cores, 23.86 TFLOPS Linpack) and larger.[3]
- On November 12, 2007, the first Blue Gene/P installation, JUGENE, with 16 racks (16,384 nodes, 65,536 processors) was running at Forschungszentrum Jülich in Germany with a performance of 167 TFLOPS.[18] When inaugurated it was the fastest supercomputer in Europe and the sixth fastest in the world. In 2009, JUGENE was upgraded to 72 racks (73,728 nodes, 294,912 processor cores) with 144 terabytes of memory and 6 petabytes of storage, and achieved a peak performance of 1 PetaFLOPS. This configuration incorporated new air-to-water heat exchangers between the racks, reducing the cooling cost substantially.[19] JUGENE was shut down in July 2012 and replaced by the Blue Gene/Q system JUQUEEN.
- The 40-rack (40960 nodes, 163840 processor cores) "Intrepid" system at Argonne National Laboratory was ranked #3 on the June 2008 Top 500 list.[20] The Intrepid system is one of the major resources of the INCITE program, in which processor hours are awarded to "grand challenge" science and engineering projects in a peer-reviewed competition.
- Lawrence Livermore National Laboratory installed a 36-rack Blue Gene/P installation, "Dawn", in 2009.
- The King Abdullah University of Science and Technology (KAUST) installed a 16-rack Blue Gene/P installation, "Shaheen", in 2009.
- In 2012, a 6-rack Blue Gene/P was installed at Rice University and will be jointly administered with the University of Sao Paulo.[21]
- A 2.5 rack Blue Gene/P system is the central processor for the Low Frequency Array for Radio astronomy (LOFAR) project in the Netherlands and surrounding European countries. This application uses the streaming data capabilities of the machine.
- A 2-rack Blue Gene/P was installed in September 2008 in Sofia, Bulgaria, and is operated by the Bulgarian Academy of Sciences and Sofia University.[22]
- In 2010, a 2-rack (8192-core) Blue Gene/P was installed at the University of Melbourne for the Victorian Life Sciences Computation Initiative.[23]
- In 2011, a 2-rack Blue Gene/P was installed at University of Canterbury in Christchurch, New Zealand.
- In 2012, a 2-rack Blue Gene/P was installed at Rutgers University in Piscataway, New Jersey. It was dubbed "Excalibur" as an homage to the Rutgers mascot, the Scarlet Knight.[24]
- In 2008, a 1-rack (1024 nodes) Blue Gene/P with 180 TB of storage was installed at the University of Rochester in Rochester, New York.[25]
- The first Blue Gene/P in the ASEAN region was installed in 2010 at the Universiti of Brunei Darussalam’s research centre, the UBD-IBM Centre. The installation has prompted research collaboration between the university and IBM research on climate modeling that will investigate the impact of climate change on flood forecasting, crop yields, renewable energy and the health of rainforests in the region among others.[26]
- In 2013, a 1-rack Blue Gene/P was donated to the Department of Science and Technology for weather forecasts, disaster management, precision agriculture, and health it is housed in the National Computer Center, Diliman, Quezon City, under the auspices of Philippine Genome Center (PGC) Core Facility for Bioinformatics (CFB) at UP Diliman, Quezon City.[27]
2.3. Applications
- Veselin Topalov, the challenger to the World Chess Champion title in 2010, confirmed in an interview that he had used a Blue Gene/P supercomputer during his preparation for the match.[28]
- The Blue Gene/P computer has been used to simulate approximately one percent of a human cerebral cortex, containing 1.6 billion neurons with approximately 9 trillion connections.[29]
- The IBM Kittyhawk project team has ported Linux to the compute nodes and demonstrated generic Web 2.0 workloads running at scale on a Blue Gene/P. Their paper, published in the ACM Operating Systems Review, describes a kernel driver that tunnels Ethernet over the tree network, which results in all-to-all TCP/IP connectivity.[30][31] Running standard Linux software like MySQL, their performance results on SpecJBB rank among the highest on record.
- In 2011, a Rutgers University / IBM / University of Texas team linked the KAUST Shaheen installation together with a Blue Gene/P installation at the IBM Watson Research Center into a "federated high performance computing cloud", winning the IEEE SCALE 2011 challenge with an oil reservoir optimization application.[32]
3. Blue Gene/Q

The third supercomputer design in the Blue Gene series, Blue Gene/Q has a peak performance of 20 Petaflops,[33] reaching LINPACK benchmarks performance of 17 Petaflops. Blue Gene/Q continues to expand and enhance the Blue Gene/L and /P architectures.
3.1. Design
The Blue Gene/Q Compute chip is an 18 core chip. The 64-bit A2 processor cores are 4-way simultaneously multithreaded, and run at 1.6 GHz. Each processor core has a SIMD Quad-vector double precision floating point unit (IBM QPX). 16 Processor cores are used for computing, and a 17th core for operating system assist functions such as interrupts, asynchronous I/O, MPI pacing and RAS. The 18th core is used as a redundant spare, used to increase manufacturing yield. The spared-out core is shut down in functional operation. The processor cores are linked by a crossbar switch to a 32 MB eDRAM L2 cache, operating at half core speed. The L2 cache is multi-versioned, supporting transactional memory and speculative execution, and has hardware support for atomic operations.[34] L2 cache misses are handled by two built-in DDR3 memory controllers running at 1.33 GHz. The chip also integrates logic for chip-to-chip communications in a 5D torus configuration, with 2GB/s chip-to-chip links. The Blue Gene/Q chip is manufactured on IBM's copper SOI process at 45 nm. It delivers a peak performance of 204.8 GFLOPS at 1.6 GHz, drawing about 55 watts. The chip measures 19×19 mm (359.5 mm²) and comprises 1.47 billion transistors. The chip is mounted on a compute card along with 16 GB DDR3 DRAM (i.e., 1 GB for each user processor core).[35]
A Q32[36] compute drawer contains 32 compute cards, each water cooled.[37] A "midplane" (crate) contains 16 Q32 compute drawers for a total of 512 compute nodes, electrically interconnected in a 5D torus configuration (4x4x4x4x2). Beyond the midplane level, all connections are optical. Racks have two midplanes, thus 32 compute drawers, for a total of 1024 compute nodes, 16,384 user cores and 16 TB RAM.[37]
Separate I/O drawers, placed at the top of a rack or in a separate rack, are air cooled and contain 8 compute cards and 8 PCIe expansion slots for Infiniband or 10 Gigabit Ethernet networking.[37]
3.2. Performance
At the time of the Blue Gene/Q system announcement in November 2011, an initial 4-rack Blue Gene/Q system (4096 nodes, 65536 user processor cores) achieved #17 in the TOP500 list[3] with 677.1 TeraFLOPS Linpack, outperforming the original 2007 104-rack BlueGene/L installation described above. The same 4-rack system achieved the top position in the Graph500 list[38] with over 250 GTEPS (giga traversed edges per second). Blue Gene/Q systems also topped the Green500 list of most energy efficient supercomputers with up to 2.1 GFLOPS/W.[17]
In June 2012, Blue Gene/Q installations took the top positions in all three lists: TOP500,[3] Graph500 [38] and Green500.[17]
3.3. Installations
The following is an incomplete list of Blue Gene/Q installations. Per June 2012, the TOP500 list contained 20 Blue Gene/Q installations of 1/2-rack (512 nodes, 8192 processor cores, 86.35 TFLOPS Linpack) and larger.[3] At a (size-independent) power efficiency of about 2.1 GFLOPS/W, all these systems also populated the top of the June 2012 Green 500 list.[17]
- A Blue Gene/Q system called Sequoia was delivered to the Lawrence Livermore National Laboratory (LLNL) beginning in 2011 and was fully deployed in June 2012. It is part of the Advanced Simulation and Computing Program running nuclear simulations and advanced scientific research. It consists of 96 racks (comprising 98,304 compute nodes with 1.6 million processor cores and 1.6 PB of memory) covering an area of about 3,000 square feet (280 m2).[39] In June 2012, the system was ranked as the world's fastest supercomputer.[40][41] at 20.1 PFLOPS peak, 16.32 PFLOPS sustained (Linpack), drawing up to 7.9 megawatts of power.[3] In June 2013, its performance is listed at 17.17 PFLOPS sustained (Linpack).[3]
- A 10 PFLOPS (peak) Blue Gene/Q system called Mira was installed at Argonne National Laboratory in the Argonne Leadership Computing Facility in 2012. It consist of 48 racks (49,152 compute nodes), with 70 PB of disk storage (470 GB/s I/O bandwidth).[42][43]
- JUQUEEN at the Forschungzentrum Jülich is a 28-rack Blue Gene/Q system, and was from June 2013 to November 2015 the highest ranked machine in Europe in the Top500.[3]
- Vulcan at Lawrence Livermore National Laboratory (LLNL) is a 24-rack, 5 PFLOPS (peak), Blue Gene/Q system that became available in 2013. Vulcan will serve Lab-industry projects through Livermore's High Performance Computing (HPC) Innovation Center[44] as well as academic collaborations in support of DOE/National Nuclear Security Administration (NNSA) missions.[45]
- Fermi at the CINECA Supercomputing facility, Bologna, Italy,[46] is a 10-rack, 2 PFLOPS (peak), Blue Gene/Q system.
- A five rack Blue Gene/Q system with additional compute hardware called AMOS was installed at Rensselaer Polytechnic Institute in 2013.[47] The system was rated at 1048.6 teraflops, the most powerful supercomputer at any private university, and third most powerful supercomputer among all universities in 2014.[48]
- An 838 TFLOPS (peak) Blue Gene/Q system called Avoca was installed at the Victorian Life Sciences Computation Initiative in June, 2012.[49] This system is part of a collaboration between IBM and VLSCI, with the aims of improving diagnostics, finding new drug targets, refining treatments and furthering our understanding of diseases.[50] The system consists of 4 racks, with 350 TB of storage, 65,536 cores, 64 TB RAM.[51]
- A 209 TFLOPS (peak) Blue Gene/Q system was installed at the University of Rochester in July, 2012.[52] This system is part of the Health Sciences Center for Computational Innovation, which is dedicated to the application of high-performance computing to research programs in the health sciences. The system consists of a single rack (1,024 compute nodes) with 400 TB of high-performance storage.[53]
- A 209 TFLOPS peak (172 TFLOPS LINPACK) Blue Gene/Q system called Lemanicus was installed at the EPFL in March 2013.[54] This system belongs to the Center for Advanced Modeling Science CADMOS ([55]) which is a collaboration between the three main research institutions on the shore of the Geneva Lake in the French speaking part of Switzerland : Université de Lausanne, Université de Genève and EPFL. The system consists of a single rack (1,024 compute nodes) with 2.1 PB of IBM GPFS-GSS storage.
- A half-rack Blue Gene/Q system, with about 100 TFLOPS (peak), called Cumulus was installed at A*STAR Computational Resource Centre, Singapore, at early 2011.[56]
- As part of DiRAC, the EPCC hosts a 6144-node Blue Gene/Q system at the University of Edinburgh[57]
3.4. Applications
Record-breaking science applications have been run on the BG/Q, the first to cross 10 petaflops of sustained performance. The cosmology simulation framework HACC achieved almost 14 petaflops with a 3.6 trillion particle benchmark run,[58] while the Cardioid code,[59][60] which models the electrophysiology of the human heart, achieved nearly 12 petaflops with a near real-time simulation, both on Sequoia. A fully compressible flow solver has also achieved 14.4 PFLOP/s (originally 11 PFLOP/s) on Sequoia, 72% of the machine's nominal peak performance.[61]
The content is sourced from: https://handwiki.org/wiki/Blue_Gene
References
- "Blue Gene: A Vision for Protein Science using a Petaflop Supercomputer". IBM Systems Journal, Special Issue on Deep Computing for the Life Sciences 40 (2). http://www.research.ibm.com/journal/sj/402/allen.pdf.
- "A Talk with the Brain behind Blue Gene", BusinessWeek, November 6, 2001, http://www.businessweek.com/stories/2001-11-06/a-talk-with-the-brain-behind-blue-gene .
- "Home - TOP500 Supercomputer Sites". http://www.top500.org. Retrieved 13 October 2017.
- "Archived copy". Archived from the original on 2011-07-18. https://web.archive.org/web/20110718034455/https://asc.llnl.gov/computing_resources/bluegenel/. Retrieved 2007-10-05.
- hpcwire.com http://www.hpcwire.com/hpc/701665.html
- "SC06". http://sc06.supercomputing.org. Retrieved 13 October 2017.
- "Archived copy". Archived from the original on 2006-12-11. https://web.archive.org/web/20061211183441/http://www.hpcchallenge.org/custom/index.html?lid=103&slid=212. Retrieved 2006-12-03.
- "Mouse brain simulated on computer". BBC News. April 27, 2007. Archived from the original on 2007-05-25. https://web.archive.org/web/20070525081051/http://news.bbc.co.uk/2/hi/technology/6600965.stm.
- "IBM100 - Blue Gene". 7 March 2012. http://www-03.ibm.com/ibm/history/ibm100/us/en/icons/bluegene/. Retrieved 13 October 2017.
- Kunkel, Julian M.; Ludwig, Thomas; Meuer, Hans (12 June 2013). "Supercomputing: 28th International Supercomputing Conference, ISC 2013, Leipzig, Germany, June 16-20, 2013. Proceedings". Springer. https://books.google.com/books?id=TTC7BQAAQBAJ&pg=PA318&lpg=PA318&dq=%22Blue+Gene/L%22+%22light%22&source=bl&ots=KhsDwF0OrL&sig=gBcC1rdX4415tw-AH371aPEiixs&hl=sv&sa=X&ved=0ahUKEwjEuJTG4PjSAhWJFiwKHenuDcsQ6AEIUTAJ#v=onepage&q=%22Blue+Gene/L%22+%22light%22&f=false. Retrieved 13 October 2017.
- "Blue Gene". IBM Journal of Research and Development 49 (2/3). 2005. http://www.research.ibm.com/journal/rd49-23.html.
- Kissel, Lynn. "BlueGene/L Configuration". https://asc.llnl.gov/computing_resources/bluegenel/configuration.html. Retrieved 13 October 2017.
- ece.iastate.edu http://www.ece.iastate.edu/~crb002/cnr.html
- William Scullin (March 12, 2011). "Python for High Performance Computing". Atlanta, GA. http://us.pycon.org/2011/home/.
- "IBM Triples Performance of World's Fastest, Most Energy-Efficient Supercomputer". 2007-06-27. http://www-03.ibm.com/press/us/en/pressrelease/21791.wss. Retrieved 2011-12-24.
- "Overview of the IBM Blue Gene/P project". IBM Journal of Research and Development 52: 199–220. Jan 2008. doi:10.1147/rd.521.0199. https://dx.doi.org/10.1147%2Frd.521.0199
- "Green500 - TOP500 Supercomputer Sites". http://www.green500.org. Retrieved 13 October 2017.
- "Supercomputing: Jülich Amongst World Leaders Again". IDG News Service. 2007-11-12. http://www.pressebox.de/pressemeldungen/ibm-deutschland-gmbh-4/boxid-136200.html.
- "IBM Press room - 2009-02-10 New IBM Petaflop Supercomputer at German Forschungszentrum Juelich to Be Europe's Most Powerful". 03.ibm.com. 2009-02-10. http://www-03.ibm.com/press/us/en/pressrelease/26657.wss. Retrieved 2011-03-11.
- ""Argonne's Supercomputer Named World’s Fastest for Open Science, Third Overall"". http://www.mcs.anl.gov/news/detail.php?id=147. Retrieved 13 October 2017.
- "Rice University, IBM partner to bring the first Blue Gene supercomputer to Texas, March 2012". http://news.rice.edu/2012/03/30/rice-university-ibm-partner-to-bring-first-blue-gene-supercomputer-to-texas/.
- Вече си имаме и суперкомпютър, Dir.bg, 9 September 2008 http://dnes.dir.bg/2008/09/09/news3363693.html#sepultura
- "IBM Press room - 2010-02-11 IBM to Collaborate with Leading Australian Institutions to Push the Boundaries of Medical Research - Australia". 03.ibm.com. 2010-02-11. http://www-03.ibm.com/press/au/en/pressrelease/29383.wss. Retrieved 2011-03-11.
- "Archived copy". Archived from the original on 2013-03-06. https://web.archive.org/web/20130306182855/http://www.informationweek.com/hardware/supercomputers/rutgers-gets-big-data-weapon-in-ibm-supe/232700313. Retrieved 2013-09-07.
- "University of Rochester and IBM Expand Partnership in Pursuit of New Frontiers in Health". University of Rochester Medical Center. May 11, 2012. Archived from the original on 2012-05-11. https://web.archive.org/web/20120511152144/http://www.urmc.rochester.edu/news/story/index.cfm?id=3498.
- "IBM and Universiti Brunei Darussalam to Collaborate on Climate Modeling Research". IBM News Room. http://www-03.ibm.com/press/us/en/pressrelease/32755.wss. Retrieved 18 October 2012.
- Ronda, Rainier Allan. "DOST’s supercomputer for scientists now operational". http://www.philstar.com/headlines/2014/04/15/1312838/dosts-supercomputer-scientists-now-operational. Retrieved 13 October 2017.
- "Topalov training with super computer Blue Gene P". http://players.chessdom.com/veselin-topalov/topalov-blue-gene-p. Retrieved 13 October 2017.
- Kaku, Michio. Physics of the Future (New York: Doubleday, 2011), 91.
- "Project Kittyhawk: A Global-Scale Computer". http://www.research.ibm.com/kittyhawk/. Retrieved 13 October 2017.
- [1]
- "Rutgers-led Experts Assemble Globe-Spanning Supercomputer Cloud". 2011-07-06. Archived from the original on 2011-11-10. https://web.archive.org/web/20111110044858/http://news.rutgers.edu/medrel/special-content/summer-2011/rutgers-led-experts-20110706. Retrieved 2011-12-24.
- "IBM announces 20-petaflops supercomputer". Kurzweil. 18 November 2011. http://www.kurzweilai.net/ibm-announces-20-petaflops-supercomputer. Retrieved 13 November 2012. "IBM has announced the Blue Gene/Q supercomputer, with peak performance of 20 petaflops"
- "Memory Speculation of the Blue Gene/Q Compute Chip". http://wands.cse.lehigh.edu/IBM_BQC_PACT2011.ppt. Retrieved 2011-12-23.
- "The Blue Gene/Q Compute chip". http://www.hotchips.org/wp-content/uploads/hc_archives/hc23/HC23.18.1-manycore/HC23.18.121.BlueGene-IBM_BQC_HC23_20110818.pdf. Retrieved 2011-12-23.
- "IBM Blue Gene/Q supercomputer delivers petascale computing for high-performance computing applications". http://www-01.ibm.com/common/ssi/rep_ca/8/897/ENUS112-028/ENUS112-028.PDF. Retrieved 13 October 2017.
- "IBM uncloaks 20 petaflops BlueGene/Q super". The Register. 2010-11-22. https://www.theregister.co.uk/2010/11/22/ibm_blue_gene_q_super/. Retrieved 2010-11-25.
- "The Graph500 List". Archived from the original on 2011-12-27. https://web.archive.org/web/20111227021230/http://www.graph500.org/.
- Feldman, Michael (2009-02-03). "Lawrence Livermore Prepares for 20 Petaflop Blue Gene/Q". HPCwire. Archived from the original on 2009-02-12. https://web.archive.org/web/20090212034132/http://www.hpcwire.com/features/Lawrence-Livermore-Prepares-for-20-Petaflop-Blue-GeneQ-38948594.html. Retrieved 2011-03-11.
- B Johnston, Donald (2012-06-18). "NNSA's Sequoia supercomputer ranked as world's fastest". https://www.llnl.gov/news/newsreleases/2012/Jun/NR-12-06-07.html. Retrieved 2012-06-23.
- TOP500 Press Release http://www.top500.org/lists/2012/06/press-release
- "MIRA: World's fastest supercomputer - Argonne Leadership Computing Facility". http://www.alcf.anl.gov/articles/mira-worlds-fastest-supercomputer. Retrieved 13 October 2017.
- "Mira - Argonne Leadership Computing Facility". http://www.alcf.anl.gov/mira. Retrieved 13 October 2017.
- "HPC Innovation Center". http://hpcinnovationcenter.llnl.gov/. Retrieved 13 October 2017.
- "Lawrence Livermore's Vulcan brings 5 petaflops computing power to collaborations with industry and academia to advance science and technology". 11 June 2013. https://www.llnl.gov/news/newsreleases/2013/Jun/NR-13-06-05.html. Retrieved 13 October 2017.
- "Archived copy". Archived from the original on 2013-10-30. https://web.archive.org/web/20131030045547/http://www.hpc.cineca.it/content/ibm-fermi. Retrieved 2013-05-13.
- "Rensselaer at Petascale: AMOS Among the World’s Fastest and Most Powerful Supercomputers". http://news.rpi.edu/content/2013/10/03/amos-among-world%E2%80%99s-fastest-and-most-powerful-supercomputers. Retrieved 13 October 2017.
- Michael Mullaneyvar. "AMOS Ranks 1st Among Supercomputers at Private American Universities". http://news.rpi.edu/content/2014/08/04/amos-ranks-43rd-list-world%E2%80%99s-top-500-supercomputers. Retrieved 13 October 2017.
- "World's greenest supercomputer comes to Melbourne - The Melbourne Engineer". 16 February 2012. http://themelbourneengineer.eng.unimelb.edu.au/2012/02/worlds-greenest-computer-comes-to-melbourne/. Retrieved 13 October 2017.
- "Melbourne Bioinformatics - For all researchers and students based in Melbourne's biomedical and bioscience research precinct". http://www.vlsci.org.au/. Retrieved 13 October 2017.
- "Access to High-end Systems - Melbourne Bioinformatics". http://www.vlsci.org.au/page/computer-software-configuration. Retrieved 13 October 2017.
- "University of Rochester Inaugurates New Era of Health Care Research". http://www.rochester.edu/news/show.php?id=4192. Retrieved 13 October 2017.
- "Resources - Center for Integrated Research Computing". http://www.circ.rochester.edu/resources.html. Retrieved 13 October 2017.
- [2]
- Utilisateur, Super. "À propos". http://www.cadmos.org. Retrieved 13 October 2017.
- "A*STAR Computational Resource Centre". https://www.acrc.a-star.edu.sg/21/hardware.html.
- "DiRAC BlueGene/Q". https://www.epcc.ed.ac.uk/facilities/dirac.
- S. Habib; V. Morozov; H. Finkel; A. Pope; K. Heitmann; K. Kumaran; T. Peterka; J. Insley; D. Daniel; P. Fasel; N. Frontiere & Z. Lukic. "The Universe at Extreme Scale: Multi-Petaflop Sky Simulation on the BG/Q". arXiv:1211.4864. Cite uses deprecated parameter |last-author-amp= (help) //arxiv.org/abs/1211.4864
- "Cardioid Cardiac Modeling Project". http://researcher.watson.ibm.com/researcher/view_project.php?id=2992. Retrieved 13 October 2017.
- "Venturing into the Heart of High-Performance Computing Simulations". https://str.llnl.gov/Sep12/streitz.html. Retrieved 13 October 2017.
- "Cloud cavitation collapse". Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis on - SC '13. doi:10.1145/2503210.2504565. http://dl.acm.org/citation.cfm?doid=2503210.2504565.