Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
The application of emerging technologies, such as Artificial Intelligence (AI), entails risks that need to be addressed to ensure secure and trustworthy socio-technical infrastructures. Machine Learning (ML), the most developed subfield of AI, allows for improved decision-making processes. ML models exhibit specific vulnerabilities that conventional IT systems are not subject to. As systems incorporating ML components become increasingly pervasive, the need to provide security practitioners with threat modeling tailored to the specific AI-ML pipeline is of paramount importance.
- artificial intelligence security
- threat modeling
- vulnerability assessment
- ML life-cycle
1. Introduction
Machine Learning (ML) plays a major role in a wide range of application domains. However, when ML models are deployed in production, their assets can be attacked in ways that are very different from asset attacks in conventional software systems. One example is training data sets, which can be manipulated by attackers well before model deployment time. This attack vector does not exist in conventional software, as the latter does not leverage training data to learn. Indeed, the attack surface of ML systems is the sum of specific attack vectors where an unauthorized user (the “attacker”) can try to inject spurious data into the training process or extract information from a trained model. A substantial part of this attack surface might lie beyond the reach of the organization using the ML system. For example, training data or pre-trained models are routinely acquired from third parties and can be manipulated along the supply chain. Certain ML models rely on sensor input from the physical world, which also makes them vulnerable to manipulation of physical objects. A facial recognition camera can be fooled by people wearing specially crafted glasses or clothes to escape detection. The diffusion of machine learning systems is not only creating more vulnerabilities that are harder to control but can also—if attacked successfully—trigger chain reactions affecting many other systems due to the inherent speed and automation. The call to improve the security of Artificial Intelligence (AI) systems [1] has attracted widespread attention from the ML community, which has given rise to a new vibrant line of research in security and privacy of ML models and related applications. The ML literature is now plentiful with research papers addressing the security of specific ML models, including valuable survey papers discussing individual vulnerabilities and possible defensive techniques. However, existing work mainly focuses on ingenious mechanisms that allow attackers to compromise the ML-based systems at the two core phases of the learning process, that is the training and the inference stages.
2. ML-Based Application Life-Cycle and Related At-Risk Assets
Although there exist many diverse types of learning tasks [2], the development process of ML-based systems has an intrinsic iterative multi-stage nature [3]. Figure 1 shows the reference ML life-cycle, starting from requirements analysis and ending with the ML model’s maintenance in response to changes [4].
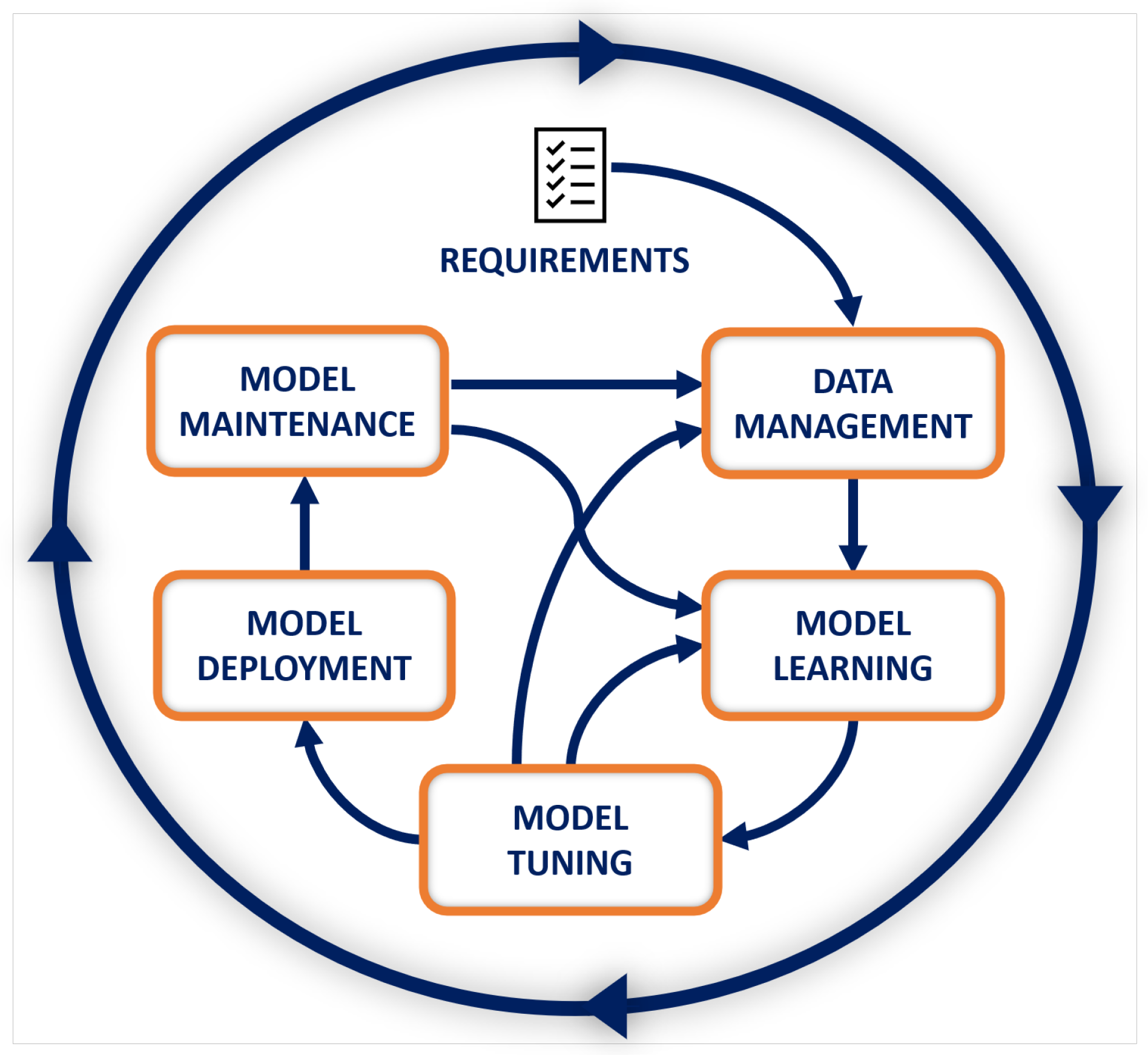
Figure 1. ML life-cycle.
The initial stage of the ML life-cycle, Data Management, includes a number of steps, a major one being the ingestion of the data required for the next stages. Ingestion occurs from multiple sources, and the data collected can either be stored or immediately used. Pre-processing techniques are used to create a consistent data set suitable for training, testing and evaluation. The next step, Model Learning, involves developing or selecting an ML model that can handle the task of interest. Depending on the goals and the amount and nature of the knowledge available to the model, different ML techniques can be used, such as supervised, unsupervised and reinforcement learning. In the training process of a supervised ML-based system, a learning algorithm is provided with predefined inputs and known outputs. The learning algorithm computes some error metrics to determine whether the model is learning well, i.e., it delivers the expected output not only on the inputs it has seen in training, but also on test data it has never seen before. The so-called hyper-parameters, which control how the training is done (e.g., how the error is used to modify the ML model’s internal parameters), are fine-tuned during the Model Tuning stage. While being tuned, the ML model is also validated to determine whether it works properly on inputs collected independently from the original training and test sets. The transition from development to production is handled in the Model Deployment stage. In this stage, the model executes inferences on real inputs, generating the corresponding results. As the production data landscape may change over time, in-production ML models require continuous monitoring. The final ML life-cycle stage, Model Maintenance, monitors the ML model and retrains it when needed.
A number of attack surface and attack vectors can be identified along a typical ML life-cycle. On one hand, some of the potential vulnerabilities are already known to exist in conventional IT systems and still remain part of the ML attack surface, though perhaps they can be seen in a new light when examined through the ML lens. On the other hand, this traditional attack surface expands along new axes when considering the specific, multifaceted and dynamic nature of ML processes. The resulting surface is therefore extremely complex, and mapping it requires going through all the various steps of the ML life-cycle and explaining the different security threats, a task that is inherently challenging due to the large amount of vectors that an adversary can target. Regardless of the ML stage targeted by the adversary, attacks against ML-based systems have negative impacts that generally result in performance decrease, system misbehavior, and/or privacy breach.
At each stage of the ML life-cycle, multiple digital assets are generated and used. Identifying assets in the context of the diverse ML life-cycle stages (including inter-dependencies between them) is a key step in pinpointing what needs to be protected and what could go wrong in terms of security of the AI ecosystem [4]. Based on the generic ML life-cycle reference model described above (see Figure 1), at-risk ML assets can be grouped into six different macro-categories—Data, Models, Actors, Processes, Tools, and Artefacts—as shown in Figure 2. It should be noted that, given the complex and evolving nature of ML-based systems, proper identification of asset that are subject to ML-specific threats must be considered an ongoing task that needs to keep pace with developments in AI/ML solutions.
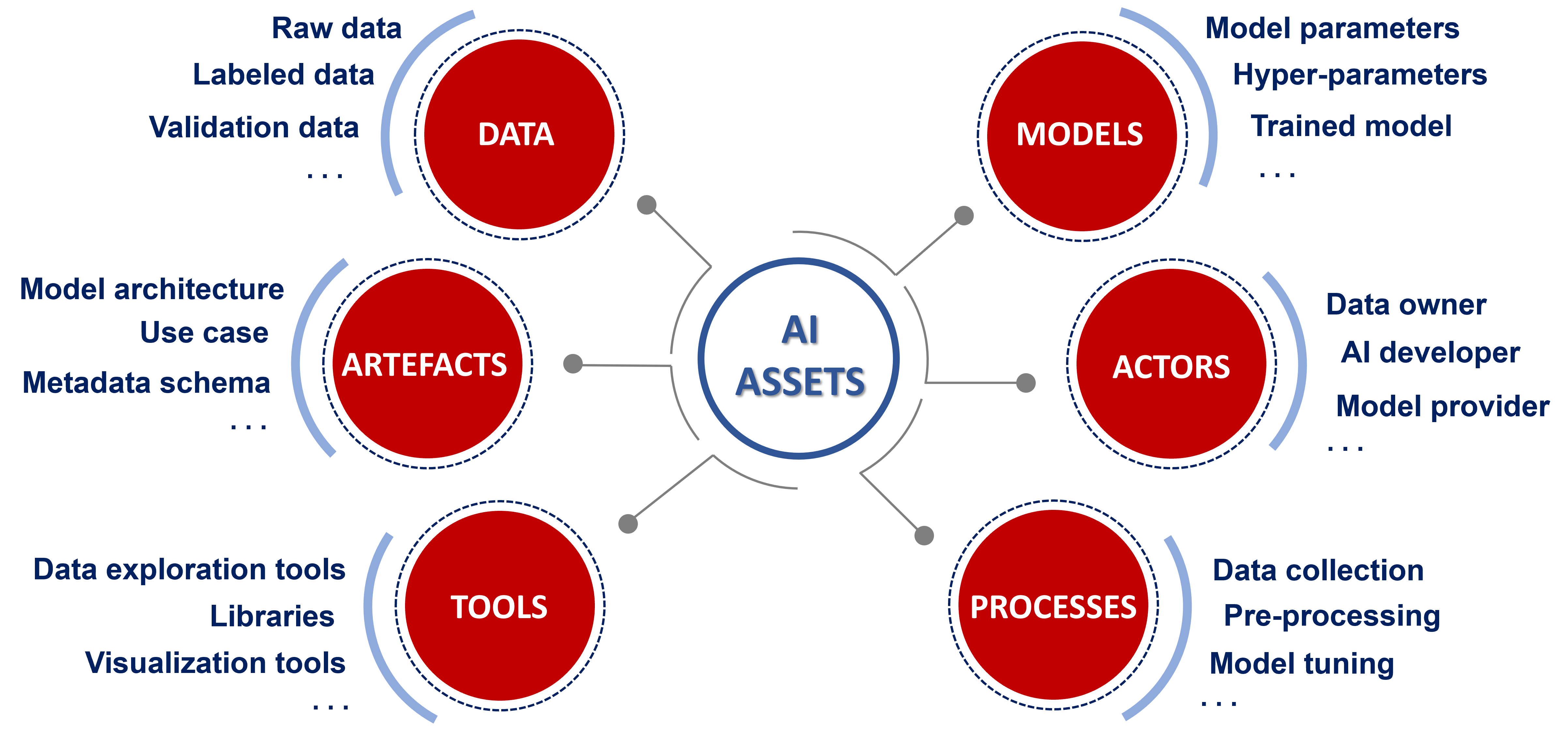
Figure 2. Assets in the AI ecosystem.
3. Failure Mode and Effects Analysis of AI-ML Systems
Failure Mode and Effects Analysis (FMEA) is a well-established, structured approach to discovering potential failures that may exist in the design of a product or process [5][6]. Failure modes are the ways in which an asset (be it a process, system or component) can fail. Effects are the ways that these failures can lead to waste or harmful outcomes for the customer. FMEA techniques are intended to identify, prioritize and limit failure modes of manufacturing or engineering processes, products, designs or services in a systematic way by determining their potential occurrence, root causes, implications and impact [7]. In order to establish the next actions to be made, a quantitative score is calculated to evaluate failures on the basis of their severity.
Guide to FMEA Application in the AI-ML Life-Cycle
FMEA first emerged in the military domain and then spread to the aerospace industry and to other manufacturing domain, with various applications in the nuclear electronics, and automotive fields as well. Recently, researchers have explored how FMEA or other safety engineering tools can be used to assess the design of AI-ML systems [8][9]. Applying FMEA to an AI-ML asset includes the following activities: (i) assigning functions to the asset, (ii) creating structure, function, networks diagrams for the asset, (iii) define defects that can cause the asset’s function/function network to fail, (iv) perform threat modeling actions. Specifically, the above operations can be accomplished by performing the following steps:
-
Step 1: Create one function list per asset. The content of these function lists should be different for each asset in at least a function;
-
Step 2: Specify prerequisites for functions that may refer to functions of other assets. This is the basis used to create function networks;
-
Step 3: Identify one or more asset defects that can impair a function (Failure Mode—FM). Add one or more causes or effects for each defect;
-
Step 4: Use a threat-modeling methodology to map FMs to threats.
The steps of FMEA involve different roles, including the asset category owners (Step 1), the action managers (Steps 2 and 3) and the security analysts (Step 4). A severity score can be assigned to FMs based on the failure effects. This assignment is done independently from the severity assessment of the threats. However, to ensure that the two evaluations are consistent, FM severity should be passed on from the FMs to the threats associated to them, e.g., as a lower bound to DREAD-estimated threat severity.
This entry is adapted from the peer-reviewed paper 10.3390/s22176662
References
- Dietterich, T.G. Steps Toward Robust Artificial Intelligence. AI Mag. 2017, 38, 3–24.
- de Prado, M.; Su, J.; Dahyot, R.; Saeed, R.; Keller, L.; Vállez, N. AI Pipeline—Bringing AI to you. End-to-end integration of data, algorithms and deployment tools. arXiv 2019, arXiv:1901.05049.
- Damiani, E.; Frati, F. Towards Conceptual Models for Machine Learning Computations. In Proceedings of the Conceptual Modeling—37th International Conference, Xi’an, China, 22–25 October 2018; Volume 11157, pp. 3–9.
- Mauri, L.; Damiani, E. STRIDE-AI: An Approach to Identifying Vulnerabilities of Machine Learning Assets. In Proceedings of the International Conference on Cyber Security and Resilience (CSR), Rhodes, Greece, 6–28 July 2021; pp. 147–154.
- Spreafico, C.; Russo, D.; Rizzi, C. A state-of-the-art review of FMEA/FMECA including patents. Comput. Sci. Rev. 2017, 25, 19–28.
- Sankar, N.R.; Prabhu, B.S. Modified approach for prioritization of failures in a system failure mode and effects analysis. Int. J. Qual. Reliab. Manag. 2001, 18, 324–336.
- Kara-Zaitri, C. Disaster prevention and limitation: State of the art; tools and technologies. Disaster Prev. Manag. Int. J. 1996, 5, 30–39.
- Puente, J.; Priore, P.; Fernández, I.; García, N.; de la Fuente, D.; Pino, R. On improving failure mode and effects analysis (FMEA) from different artificial intelligence approaches. In Proceedings of the International Conference on Artificial Intelligence, Reykjavic, Iceland, 22–25 April 2014.
- Li, J.; Chignell, M. FMEA-AI: AI fairness impact assessment using failure mode and effects analysis. In Proceedings of the International Conference on Artificial Intelligence (ICAI), Messe Wien, Austria, 30–31 March 2022; pp. 1–14.
This entry is offline, you can click here to edit this entry!