The paper is devoted to an overview of multi-agent principles, methods, and technologies intended to adaptive real-time data clustering. The proposed methods provide new principles of self-organization of records and clusters, represented by software agents, making it possible to increase the adaptability of different clustering processes significantly. The paper also presents a comparative review of the methods and results recently developed in this area and their industrial applications. An ability of self-organization of items and clusters suggests a new perspective to form groups in a bottom-up online fashion together with continuous adaption previously obtained decisions. Multi-agent technology allows implementing this methodology in a parallel and asynchronous multi-thread manner, providing highly flexible, scalable, and reliable solutions. Industrial applications of the intended for solving too complex engineering problems are discussed together with several practical examples of data clustering in manufacturing applications, such as the pre-analysis of customer datasets in the sales process, pattern discovery, and ongoing forecasting and consolidation of orders and resources in logistics, clustering semantic networks in insurance document processing. Future research is outlined in the areas such as capturing the semantics of problem domains and guided self-organization on the virtual market.
- multi-agent technology
- adaptive clustering
- resource planning and scheduling
1. Introduction
The known clustering task consists of categorizing a given matters collection according to its inner similarity, such that items belonging to the same group (cluster) are more alike to each other in comparison to ones located in additional sets. Such a problem is typically resolved with a predefined number of groups [1][2][3][4][5][6][7][8].
However, in many practical problems, data are received gradually, e.g., via real-time record-by-record fashion in small batches within unpredictable periods. The most representative example of such an application is customer classification in an internet portal, with a large number of visitors contributing a small but significant amount of data during each visit. User patterning aiming for coherent and up-to-date behavior suggests an adaptive and go-ahead clustering process, taking into account the dynamic nature of the data.
The main limitation of many current data mining methods and algorithms is the need to suggest a hypothesis about data configuration in advance that is frequently impossible in the online mode.
Despite considerable progress in data mining and machine learning technologies, the intended methods and algorithms cannot cope with the enormous amounts of data with critical uncertainty and dynamics. Complexity becomes even more prominent because of the diversity of datasets and growing of application domains. This difficulty also appears since the individual business requirements and computational complexity of the clustering process requires additional resources for the practical applications. An example of such a complexity is given by the authors of [9], where the similarity of user preferences given as a cluster criterion was combined with many other metrics like topology, domain-specific semantics, etc.
Future clustering is comprehended as a collection of if–then rules, providing the most understandable manner of cluster visualization. This technique produces the possibility for smart solutions in business to learn the behavior of orders and resources “on the fly” and to improve the required business capacities in a real-time fashion.
2. Application of Adaptive Clustering for Transport Logistics
2.1. Cargo Transportation Logistics
The problem concerns developing a near-to-optimal schedule to allocate transportation orders to available resources. The objective of a smart solution for real-time scheduling is to analyze customer orders, assign resources, form the plan using the company’s own and third-party fleets, optimize the schedule, and monitoring [10]. In a real-time transport logistics task, the problem of adaptive rescheduling of orders by resources is solved. Generally, the mission is close to the known traveling salesman’s problem. Actually, it includes not only the path minimization, but also many other restrictions, such as the level of service for the customer, the desired windowing time for receiving goods, the order of loading goods, the need to return empty containers, etc.
It is often very difficult to understand which schedules are “good” and which are “bad,” even with the involvement of domain experts complicating the process of forming requirements for intelligent resource management systems. It is possible to approach this task in a completely different way and look at the historical aspect of the records, past trips, and resources. So, a strategy can be evaluated based on this historical data to restore planning knowledge.
However, the problem is complicated for large fleets. It is not trouble-free to ensure that the resulting schedule is feasible, especially from the cost perspective. Other criteria, such as VIP clients, patterns of delivery, preferred carriers, trip shape, cost of plan, total mileage of all trucks, customer satisfaction level for individual clients, satisfaction of drivers, etc., also have to be taken into account. There are even too many human-like heuristics, for example, considering future orders to optimize today’s trips, such as the allocation of constrained orders/resources first, working from the most distant/close points, etc.
Future orders are altogether unknown in advance. Thus, scheduling is carried out in real time while focusing on many specific properties, such as source and destination points, time windows, weight, volume, type, clients’ reputation, and other specific requirements for cargo delivery conditions. Information about orders and resources are usually accumulated in a table, where each row represents a unique entity, for example, a transportation order, including information on the source and destination locations, and other cargo-related information. Thus, a clustering problem deals with items in a heterogeneous multi-dimensional space composed of the records having different types of coordinates.
2.2. Adaptive Clustering for Discovering Rules and Validating Logic of Logistics Scheduling
The developed adaptive clustering solution for rules extracting in the logistics domain intends to monitor the flow of orders, scheduling results, constructing rules applied to improve the quality of the planning and the forecasting. The primary problem is to learn the rules of a suitable schedule for a customer being, for instance, an immense transportation company [10]. The customer is not able to establish the formal model components like metric criteria to estimate the proximity and similarity of schedules generated. In the considered example, the customer provides a dataset made of 920 orders planned manually by operators. An adaptive clustering procedure runs for extracting hidden rules from the dataset.
A table with information on orders was created such that each row represents an order:
-
From—the source location of cargo transportation;
-
To—the destination location of cargo transportation;
-
Pallets—number of units to be transported;
-
CarrierType—the name of the carrier company;
-
Depot—location of the vehicle executing the transportation;
-
VehicleType—the type of the vehicle;
-
Orders—the total amount of orders transported in parallel on a vehicle.
As can be seen, the From, To, and Pallets axes belonged to the second category (we cannot control these fields), while the CarrierType, Depot, VehicleType, and Orders axes were situated in the first category. The developed solution of adaptive clustering found 218 rules. The spreading of their confidence level is presented in Figure 1.
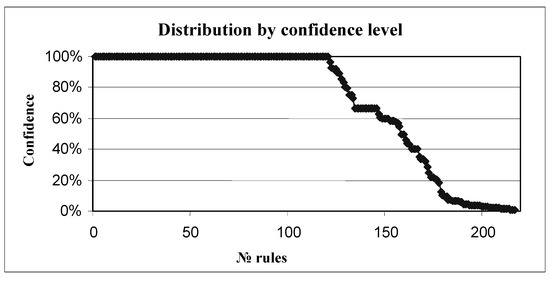
Figure 1. Association of system-detected rules with the confidence level.
Thus, more than 50% of rules had a confidence level of 100%, providing the value for decision making. Examples of system-found rules are shown in Figure 2, linking to the companies and geographical locations.

Figure 2. Examples of the discovered rules.
The company experts confirmed most of the rules and agreed that the revealed dependencies are persuasive for the problem domain. More interesting is the fact that the experts found that 8–12% of the rules had substantial business value. The discovered rules were incorporated into the knowledge base of the system for automatic scheduling, and innovative schedules were developed, such that the resulting schedules turned out very similar to ones created by experienced human dispatchers.
As a result of such a “learning from experience,” the developed solution became much faster and provided several benefits for the customer:
-
Manual rework needed is decreased by 32%;
-
Trip quality is increased by 17%;
-
Gaps presence in trips is decreased by 11%;
-
Errors in product distribution plans decreased by 11%;
-
Fleet mileage is decreased by 16%;
-
Fleet usage is decreased by 8%.
Overall, the system brought approximately 20% of the increase in schedule quality. The time required to learn and customize domain-specific logic of operational scheduling in a new custom domain decreased from 1–2 months to 10–15 days.
2.3. Adaptive Clustering for Consolidation of Orders in Transport Logistics
The second problem is to find possible options for order consolidation aiming to improve efficiency [11]. The clustering method was applied here to find groups of orders similar in the geographical location and time windows. It can be supplied simultaneously by one truck with a specific capacity. The consolidation of orders requires the use of journey time metrics (JTM) and analysis of nearness of source locations by geography and by distance/time (JTM), as well as destination locations in combination with the overlap of time intervals if one truck takes all consolidated orders.
Such orders can be delivered in different ways: All orders in the cluster could be shipped by one truck, or by several trucks similar or not to each other. Particular heuristics were developed to expose the options for decision-makers. The resulting clusters discovered some interesting hidden rules:
-
90% of orders found consolidations with at least one order;
-
423 consolidations (21–27 pallets), improving the efficiency of transportation, were found.
The obtained results are given in Figure 3.
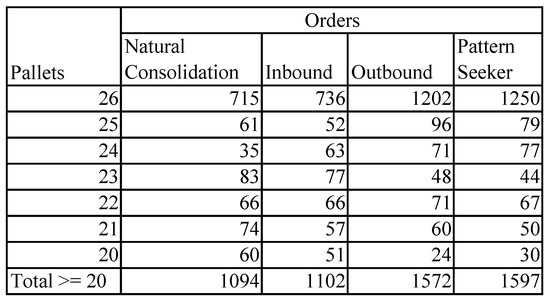
Figure 3. Results of cargo consolidations.
In general, the solution is 1.5-times more consolidations, improving the schedule quality by 15%.
3. Future Steps
Multi-agent technology provides various recently developed methods for adaptive clustering by data their self-organization to expand the current technologies, which can be considered as a new generic methodology. The stated results designate the following research directions for future research in the efficiency of adaptive clustering using multi-agent technology:
1. Application of ontologies for capturing the semantics of the problem domain
Developing a virtual marketAt the moment, agents use real money in decision-making. However, virtual money can be introduced as a way to regulate the abilities of clusters and records to make decisions and solve conflicts. For example, in transportation logistics, the sum of money available for a record can be set as a price for the order, which the customer is due to pay. Then, the history of VIP order is “richer” than a record of a single order from a regular customer. It makes it possible to form clusters with distant records, taking into account a growing context, and generating more groups as a result.
2. Guided self-organization on the virtual market of clusters and records
The self-organization process can be stopped by local attractors, which is hard for agents to avoid. One of the solutions consists of the appointment of an agent of the “whole” system. Its mission is to monitor the situation in clustering, recover the potential local optimums, and to cascade changes during different types of interventions, for example, investing virtual money into some promising clusters or records.
3. Self-learning
Agents of records and clusters may use different self-learning tools, including neuro-networks or deep learning ones, to alter their decision-making rules and analyze the results.
4. Multi-object optimization for the best possible use of virtual money
As the next step in method development, we consider a situation when one record (cluster) can locate in a few groups simultaneously, paying for a membership or some virtual taxes, etc. In this case, the collected virtual money of each agent needs to be assigned by other agents of clusters and records in the best possible way on the virtual market, aiming to decide which candidates to choose.
The results of the research could be useful for designing a new generation of smart software products based on multi-agent technology that is able to adapt, learn, and evolve over their life cycle.
This entry is adapted from the peer-reviewed paper 10.3390/math8101664
References
- Pattern Recognition, 3rd ed.; Theodoridis, S.; Koutroumbas, K. (Eds.) Academic Press: Cambridge, MA, USA, 2010; p. 984.
- Everit, B. Cluster Analysis, 5th ed.; Wiley: Chichester, UK, 2011; p. 346.
- Larose, D.T.; Larose, C.D. Discovering Knowledge in Data, 2nd ed.; Wiley: Hoboken, NJ, USA, 2014; p. 336.
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; The MIT Press: London, UK, 2018; p. 525.
- Contemporary Experimental Design, Multivariate Analysis and Data Mining, 1st ed.; Fan, J.; Pan, J. (Eds.) Springer: Basel, Switzerland, 2020; p. 386.
- Shirkhorshidi, A.S.; Aghabozorgi, S.; Ying, T.; Herawan, W. Big Data Clustering: A Review. In ICCSA 2014: Computational Science and Its Applications—ICCSA 2014; Springer: Basel, Switzerland, 2014; pp. 707–720.
- Mirkin, B. Clustering for Data Mining a Data Recovery Approach, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2016; p. 350.
- Volkovich, Z.; Toledano-Kitai, D.; Weber, G.-W. Self-Learning k-eans Clustering: A Global Optimization Approach. J. Glob. Optim. 2013, 56, 219–232.
- Taha, K. Static and Dynamic Community Detection Methods That Optimize a Specific Objective Function: A Survey and Experimental Evaluation. IEEE Access 2020, 8, 98330–98358.
- Himoff, J.; Rzevski, G.; Skobelev, P. Multi-Agent Logistics i-Scheduler for Road Transportation. In Proceedings of the AAMAS’06, Hakodate, Hokkaido, Japan, 8–12 May 2006; pp. 1514–1521.
- Minakov, I.; Rzevski, G.; Skobelev, P.; Volman, S. Automatic extraction of business rules to improve quality in planning and consolidation in transport logistics based on multi-agent clustering. In Proceedings of the Autonomous Intelligent Systems: Multi-Agents and Data Mining 2007, LNAI 4476, St. Petersburg, Russia, 3–5 June 2007; pp. 124–137.