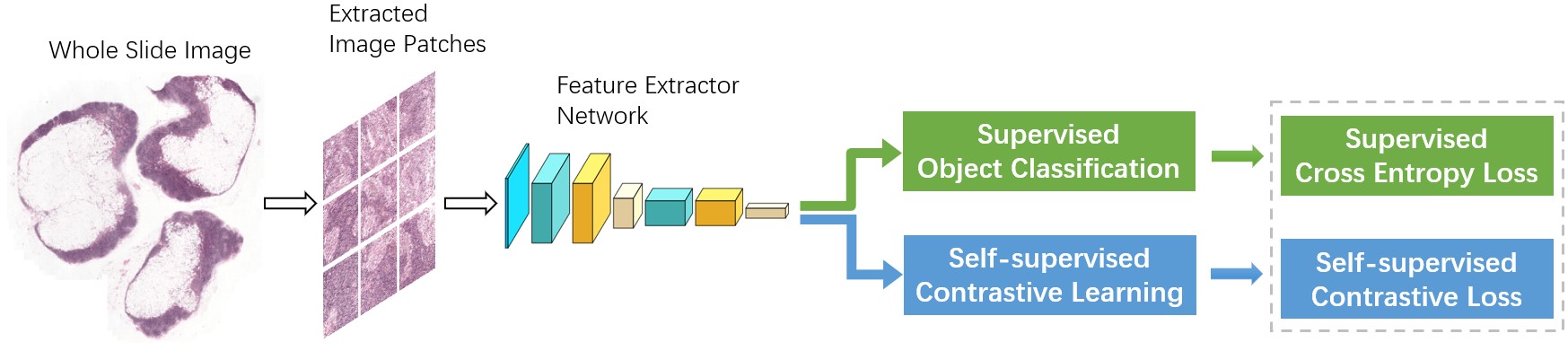
The metastasis detection in lymph nodes via microscopic examination of H&E stained histopathological images is one of the most crucial diagnostic procedures for breast cancer staging. The manual analysis is extremely labor-intensive and time-consuming because of complexities and diversities of histopathological images. Deep learning has been utilized in automatic cancer metastasis detection in recent years. The success of supervised deep learning is credited to a large labeled dataset, which is hard to obtain in medical image analysis. Contrastive learning, a branch of self-supervised learning, can help in this aspect through introducing an advanced strategy to learn discriminative feature representations from unlabeled images. In this paper, we propose to improve breast cancer metastasis detection through self-supervised contrastive learning, which is used as an accessional task in the detection pipeline, allowing a feature extractor to learn more valuable representations, even if there are fewer annotation images. Furthermore, we extend the proposed approach to exploit unlabeled images in a semi-supervised manner, as self-supervision does not need labeled data at all. Extensive experiments on the benchmark Camelyon2016 Grand Challenge dataset demonstrate that self-supervision can improve cancer metastasis detection performance leading to state-of-the-art results.
1. Introduction
Cancer is currently one of the major causes of death for people all over the world. It is estimated that 14.5 million people have died of cancer, and by 2030 this figure is expected to exceed 28 million. The most common cancer for women is breast cancer. Every year, 2.1 million people around the world are diagnosed with breast cancer, according to World Health Organization (WHO) [
1]. Due to the high rate of mortality, considerable efforts were made in the past decade to detect breast cancer from histological images so as to improve survival through early breast tissue diagnosis.
Since lymph node is the first position of breast cancer metastasis, metastasis identification of lymph node is one of the most essential criteria for early detection. In order to analyze the characteristics of tissues, pathologists examine tissue slices under the microscope [
2]. The tissue slices are traditionally directly observed with a histopathologist's naked eyes and visual data are assessed manually based on prior medical knowledge. The manual analysis is highly time consuming and labor expensive due to the intricacies and diversities of histopathological images. At the same time, highly depending on histopathologist's expertise, workload, and current mood, the manual diagnostic procedure is subjective and limited repeatability. In addition, in the face of escalating demands for diagnostics with increased cancer incidence, there is a serious shortage of pathologists [
3]. Hundreds of biopsies must be diagnosed daily by pathologists, thus it is almost impossible to thoroughly examine the entire slides. However, if only regions of interest are investigated, the chance of incorrect diagnosis may increase. To this end, in order to increase the efficiency and reliability of pathological examination, it is required to develop automatic detection techniques.
However, automated metastasis identification in sentinel lymph node from whole-slide image (WSI) is extremely challenging for the following reasons: first, the hard imitations in normal tissues usually look similar in morphology to metastatic areas, which leads to many false positives; second, the great varieties in biological structures and textures of metastatic and background areas; third, the varied circumstances of histological image processing, such as staining, cutting, sampling and digitization, enhance the variations of the appearance of image. This usually happens while tissue samples are taken at different time points or from different patients. Last but not least, WSI is incredibly huge, around 100,000 pixels × 200,000 pixels, and may not be directly input into any emerging method for cancer identification. Therefore, one of the major issues for automatic detection algorithms is how to analyze such a large pixel image effectively.
Artificial Intelligence (AI) technologies have developed rapidly in recent years. Especially in computer vision, image processing, and analysis, they have achieved outstanding breakthroughs. In histopathological diagnosis, AI has also exhibited potential advantages. With the help of AI-assisted diagnostic approaches, valuable information about diagnostics may be speedily extracted from big data, alleviating the workload of pathologists. At the same time, AI-aided diagnostics have more objective analysis capabilities and can avoid subjective discrepancies of manual analysis. To a certain extent, the use of artificial intelligence can not only improve work efficiency, but also reduce the rate of misdiagnosis by pathologists.
In the past few decades, a lot of works for breast histology image recognition have been developed. Early research used hand-made features to capture tissue properties in a specific area for automatic detection [
4,
5,
6]. However, hand-made features are not sufficiently discriminative to describe a wide variety of shapes and textures. Recently, a deep Convolutional Neural Network (CNN) has been utilized to detect cancer metastases that can learn more effective feature representation and obtain higher detection accuracy in a data-driven approach [
7,
8,
9]. The primary factor that may degrade the performance of CNN-based detection methods is the insufficiency of training samples, which may cause overfitting during the training process. In most medical circumstances, it is unrealistic to require understaffed radiologists to spend time creating such huge annotation sets for every new application. Therefore, in order to address the problem of lack of sufficient annotated data samples, it is critical to build less data-hungry algorithms capable of producing excellent performance with minimal annotations.
Self-supervised learning is a new unsupervised learning paradigm that does not require data annotations. In this paper, we propose a multi-task setting where we train the backbone model through joint supervision from the supervised detection target-task and an additional self-supervised contrastive learning task, as shown in Figure 1. Unlike most multi-task cases, where the goal is to achieve desired performance on all tasks at the same time, our aim is to enhance the performance of the backbone model through exploiting the supervision from the additional contrastive learning task. More specifically, we extend the initial training loss with an extra self-supervised contrastive loss. As a result, the artificially augmented training task contributes to learning a more diverse set of features. Furthermore, we can incorporate unlabeled data to the training process, since self-supervision does not need labeled data. Through increasing the number and diversity of training data in this semi-supervised manner, one may expect to acquire stronger image features and achieve further performance improvement.
Figure 1. Overview of the proposed architecture.
2. Related Work
In this section, we provide an overview of the relevant literature on breast cancer detection and self-supervised contrastive learning.
2.1 Breast Cancer Detection
In earlier years, most designed approaches employed hand-crafted features. Spanhol et al. demonstrate classification performance based on several hand-made textural features for distinguishing malignant from benign [
4]. Some works merged two or more hand-made features to enhance the accuracy of detection. In [
5], graph, haralick, Local Binary Patterns (LBP), and intensity features were used for cancer identification in H&E stained histopathological images. The histopathological images were represented via fusing color histograms, LBP, SIFT, and some efficient kernel features, and the significance of these pattern features was also studied in [
6]. However, it needs considerable efforts to design and validate these hand-made features. In addition, the properties of tissues with great variations in morphologies and textures cannot properly be represented, and consequently their detection performance is poor.
With the emergence of powerful computers, deep learning technology has made remarkable progress in a variety of domains, including natural language understanding, speech recognition, computer vision and image processing [
12]. These methods have also been successfully employed in various modalities of medical images for detection, classification, and segmentation tasks [
13]. Bejnordi et al. built a deep learning system to determine the stromal features of breast tissues associated with tumor for classifying Whole Slide Images (WSIs) [
14]. Spanhol et al. utilized AlexNet to categorize breast cancer in histopathological images to be malignant and benign [
7]. Bayramoglu et al. developed two distinct CNN architectures to classify breast cancer of pathology images [
8]. Single-task CNN was applied to identify malignant tumors. Multi-task CNN has been used for analyzing the properties of benign and malignant tumors. The hybrid CNN unit designed by Guo et al. could fully exploit the global and local features of image, and thus obtain superior prediction performance [
9]. Lin et al. proposed a dense and fast screening architecture (ScanNet) to identify metastatic breast cancer in WSIs [
15,
16]. In order to fully capture the spatial structure information between adjacent patches, Zanjani et al. [
17,
18] applied the conditional random field (CRF), whereas Kong et al. [
19] employed 2D Long Short-Term Memory (LSTM) on patch features, respectively, which are first obtained from a CNN classifier. As the limited number of training samples in medical applications may be insufficient to learn a powerful model, some methods [
20,
21,
22] transferred deep and rich feature hierarchies learned from a large number of cross-domain images, for which training data could be easily acquired.
2.2 Self-Supervised Contrastive Learning
Self-supervised learning is a new unsupervised learning paradigm. Recent research has shown that, by minimizing a suitable unsupervised loss during training, self-supervised learning can obtain valuable representations from unlabeled data [
23,
24,
25,
26]. The resulting network is a valid initialization for subsequent tasks.
The current revival of self-supervised learning started with intentionally devised annotation-free pretext tasks, such as colorization [
27], jigsaw puzzle solving [
25], relative patch prediction [
23], and rotation prediction [
26,
28]. Although more complex networks and longer training time can yield good results [
29], these pretext tasks more or less depend on ad-hoc heuristics, limiting the generality of learnt representations.
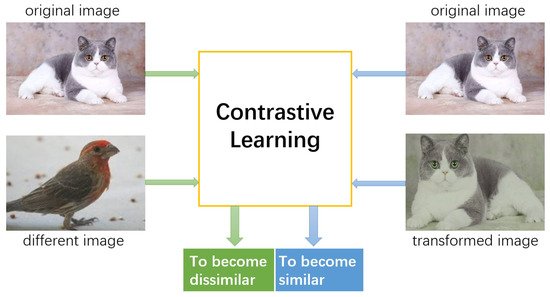
Contrastive learning is a discriminative technique that uses contrastive loss [
30] to group similar instances closer together and dissimilar instances far apart from each other [
31,
32,
33,
34,
35], as indicated in
Figure 2. Similarity is defined in an unsupervised manner. It is usually considered that various transformations of an image are similar [
36]. Ref. [
37] employed domain-specific knowledge of videos to model the global contrastive loss. Authors in [
38,
39,
40] maximized mutual information (MI) between global and local features from different layers of an encoder network, which is comparable to contrastive loss in implementation [
41]. Some works utilized memory bank [
31] or momentum contrast [
32,
33] to obtain more negative samples in each batch. MoCo [
32], SimCLR [
35], and SwAV [
42] with modified algorithms generated similar performance with the state-of-the-art supervised method on the ImageNet dataset [
43].
Figure 2. The core idea of contrastive learning: pushing the representations of original and transformed images closer together while separating the representations of original and different images far apart from each other.
3. Methodology
Our proposed method is introduced in this section. Figure 1 displays the overall framework of this method. The details of each component are presented in the following subsections.
This entry is adapted from the peer-reviewed paper 10.3390/math10142404