The Industrial Revolution 4.0 (IR 4.0) has drastically impacted how the world operates. The Internet of Things (IoT), encompassed significantly by the Wireless Sensor Networks (WSNs), is an important subsection component of the IR 4.0. WSNs are a good demonstration of an ambient intelligence vision, in which the environment becomes intelligent and aware of its surroundings. WSN has unique features which create its own distinct network attributes and is deployed widely for critical real-time applications that require stringent prerequisites when dealing with faults to ensure the avoidance and tolerance management of catastrophic outcomes. Thus, the respective underlying Fault Tolerance (FT) structure is a critical requirement that needs to be considered when designing any algorithm in WSNs. Moreover, with the exponential evolution of IoT systems, substantial enhancements of current FT mechanisms will ensure that the system constantly provides high network reliability and integrity.
- Wireless Sensor Networks (WSNs)
- Fault Tolerance (FT)
- error detection
1. Introduction
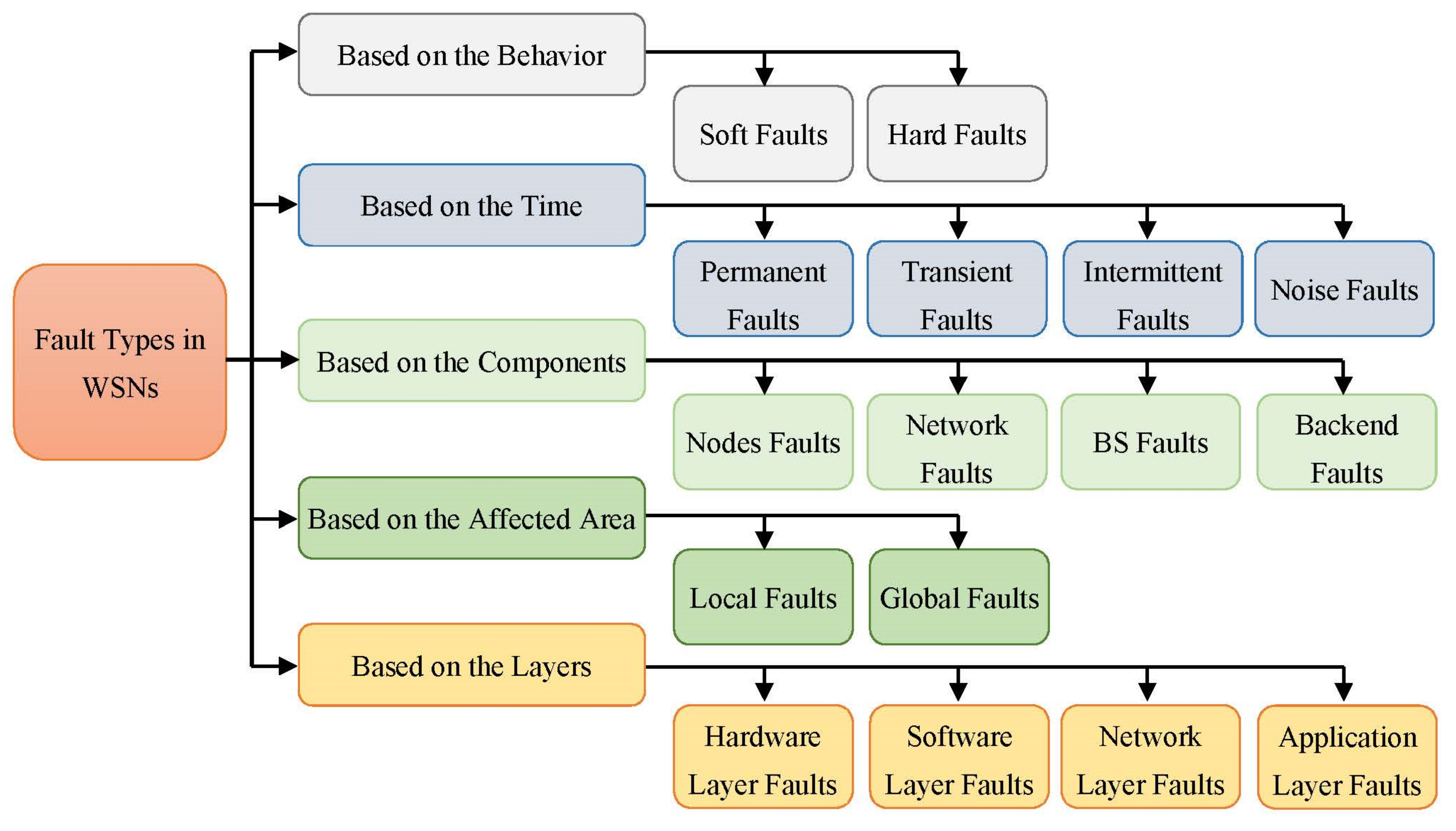
2. Faults Classifications in WSN
3. Proposed Classification of Fault Tolerance Management Approaches in WSN
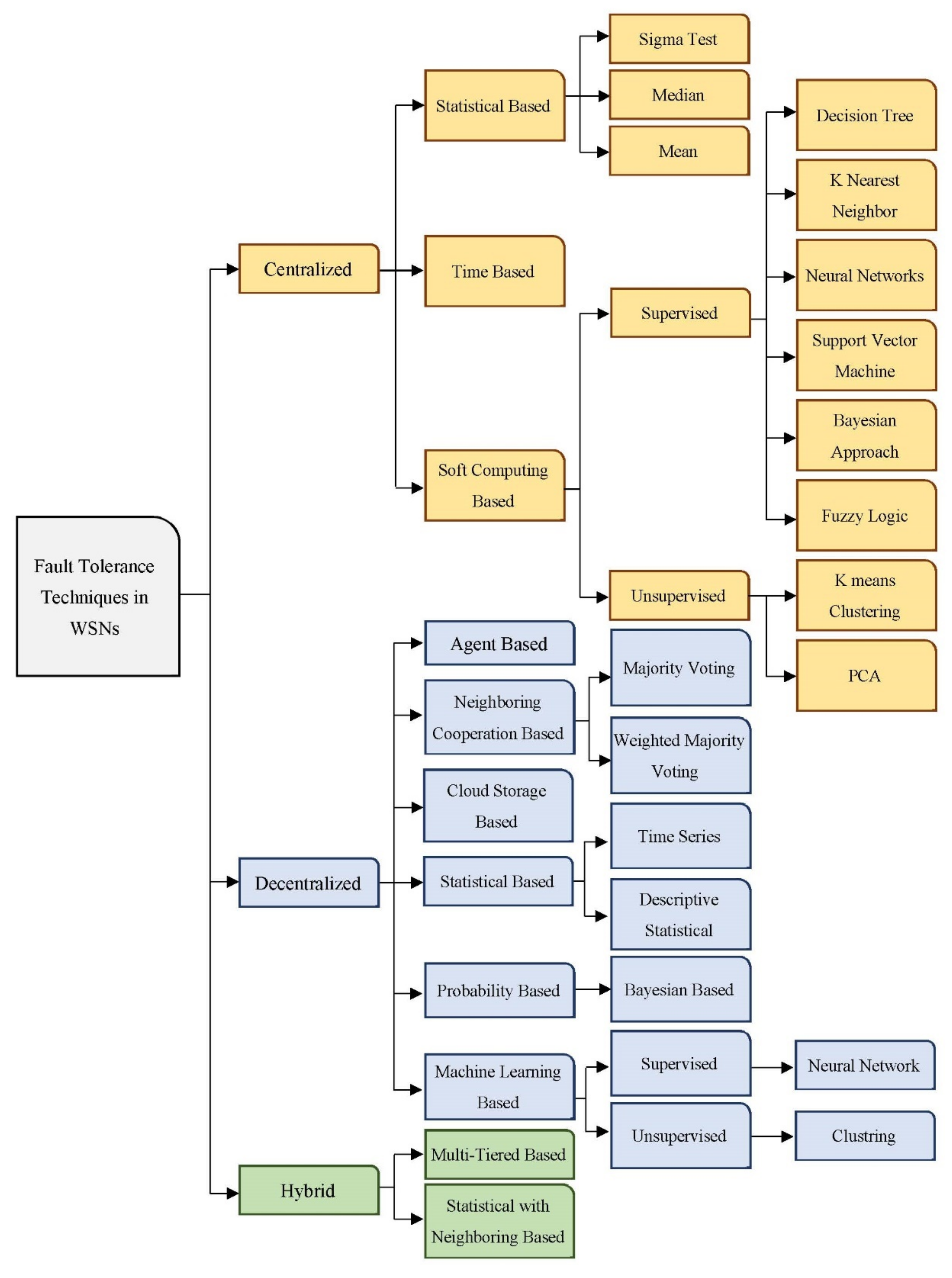
3.1. Centralized Fault Tolerance Approaches
3.2. Decentralized Fault Tolerance Approaches
3.3. Hybrid Fault Tolerance Approaches
This entry is adapted from the peer-reviewed paper 10.3390/s22166041
References
- Nagy, J.; Oláh, J.; Erdei, E.; Máté, D.; Popp, J. The Role and Impact of Industry 4.0 and the Internet of Things on the Business Strategy of the Value Chain—The Case of Hungary. Sustainability 2018, 10, 3491.
- Jaiswal, K.; Anand, V. FAGWO-H: A hybrid method towards fault-tolerant cluster-based routing in wireless sensor network for IoT applications. J. Supercomput. 2022, 78, 11195–11227.
- Dowlatshahi, M.B.; Rafsanjani, M.K.; Gupta, B.B. An energy aware grouping memetic algorithm to schedule the sensing activity in WSNs-based IoT for smart cities. Appl. Soft Comput. 2021, 108, 107473.
- Abdali, T.-A.N.; Hassan, R.; Aman, A.M.; Nguyen, Q.; Al-Khaleefa, A. Hyper-Angle Exploitative Searching for Enabling Multi-Objective Optimization of Fog Computing. Sensors 2021, 21, 558.
- Idrees, A.K.; Al-Qurabat, A.K.M. Energy-Efficient Data Transmission and Aggregation Protocol in Periodic Sensor Networks Based Fog Computing. J. Netw. Syst. Manag. 2021, 29, 1–24.
- Abdali, T.-A.N.; Hassan, R.; Aman, A.H.M.; Nguyen, Q.N. Fog Computing Advancement: Concept, Architecture, Applications, Advantages, and Open Issues. IEEE Access 2021, 9, 75961–75980.
- Gao, Y.; Xiao, F.; Liu, J.; Wang, R. Distributed Soft Fault Detection for Interval Type-2 Fuzzy-Model-Based Stochastic Systems With Wireless Sensor Networks. IEEE Trans. Ind. Inform. 2019, 15, 334–347.
- Li, L.; Dai, H.; Chen, G.; Zheng, J.; Dou, W.; Wu, X. Radiation Constrained Fair Charging for Wireless Power Transfer. ACM Trans. Sens. Netw. 2019, 15, 1–33.
- Alwan, H.; Agarwal, A. A Survey on Fault Tolerant Routing Techniques in Wireless Sensor Networks. In Proceedings of the 2009 Third International Conference on Sensor Technologies and Applications, Glyfada, Greece, 14–19 June 2009; pp. 366–371.
- Jiang, P. A New Method for Node Fault Detection in Wireless Sensor Networks. Sensors 2009, 9, 1282–1294.
- Alansari, Z.; Prasanth, A.; Belgaum, M.R. A Comparison Analysis of Fault Detection Algorithms in Wireless Sensor Networks. In Proceedings of the 2018 International Conference on Innovation and Intelligence for Informatics, Computing and Technologies (3ICT), Zallaq, Bahrain, 18–20 November 2018; pp. 1–6.
- Agarwal, V.; Tapaswi, S.; Chanak, P. Intelligent Fault-Tolerance Data Routing Scheme for IoT-enabled WSNs. IEEE Int. Things J. 2022, 4662, 1.
- Vihman, L.; Kruusmaa, M.; Raik, J. Systematic Review of Fault Tolerant Techniques in Underwater Sensor Networks. Sensors 2021, 21, 3264.
- Effah, E.; Thiare, O. Survey: Faults, Fault Detection and Fault Tolerance Techniques in Wireless Sensor Networks. Int. J. Comput. Sci. Inf. Secure 2018, 16, 1–14. Available online: https://sites.google.com/site/ijcsis/ (accessed on 1 October 2018).
- Chouikhi, S.; El Korbi, I.; Ghamri-Doudane, Y.; Saidane, L.A. A survey on fault tolerance in small and large scale wireless sensor networks. Comput. Commun. 2015, 69, 22–37.
- Krivulya, G.; Skarga-Bandurova, I.; Tatarchenko, Z.; Seredina, O.; Shcherbakova, M.; Shcherbakov, E. An Intelligent Functional Diagnostics of Wireless Sensor Network. In Proceedings of the 2019 7th International Conference on Future Internet of Things and Cloud Workshops (FiCloudW), Istanbul, Turkey, 26–28 August 2019; pp. 135–139.
- Saeed, U.; Lee, Y.-D.; Jan, S.; Koo, I. CAFD: Context-Aware Fault Diagnostic Scheme towards Sensor Faults Utilizing Machine Learning. Sensors 2021, 21, 617.
- Moridi, E.; Haghparast, M.; Hosseinzadeh, M.; Jassbi, S.J. Novel Fault Management Framework Using Markov Chain in Wireless Sensor Networks: FMMC. Wirel. Pers. Commun. 2020, 114, 583–608.
- Boussif, A.; Ghazel, M.; Basilio, J.C. Intermittent fault diagnosability of discrete event systems: An overview of automaton-based approaches. Discret. Event Dyn. Syst. 2021, 31, 59–102.
- Chen, L.; Li, G.; Huang, G. A hypergrid based adaptive learning method for detecting data faults in wireless sensor networks. Inf. Sci. 2021, 553, 49–65.
- Swain, R.R.; Khilar, P.M.; Bhoi, S.K. Underlying and Persistence Fault Diagnosis in Wireless Sensor Networks Using Majority Neighbors Co-ordination Approach. Wirel. Pers. Commun. 2020, 111, 763–798.
- Zagrouba, R.; Kardi, A. Comparative Study of Energy Efficient Routing Techniques in Wireless Sensor Networks. Information 2021, 12, 42.
- Mitra, S.; De Sarkar, A.; Roy, S. A review of fault management system in wireless sensor network. In Proceedings of the CUBE International Information Technology Conference on-CUBE’12, Pune, India, 3–6 September 2012; p. 144.
- Huangshui, H.; Guihe, Q. Fault Management Frameworks in Wireless Sensor Networks. In Proceedings of the 2011 Fourth International Conference on Intelligent Computation Technology and Automation, Shenzhen, Guangdong, 28–29 March 2011; pp. 1093–1096.
- Mitra, S.; Das, A.; Mazumder, S. Comparative study of fault recovery techniques in Wireless Sensor Network. In Proceedings of the 2016 IEEE International WIE Conference on Electrical and Computer Engineering (WIECON-ECE), Pune, India, 19–21 December 2016; pp. 130–133.
- Salayma, M.; Al-Dubai, A.; Romdhani, I.; Nasser, Y. Wireless Body Area Network (WBAN). ACM Comput. Surv. 2017, 50, 1–38.
- Baniata, M.; Reda, H.T.; Chilamkurti, N.; Abuadbba, A. Energy-Efficient Hybrid Routing Protocol for IoT Communication Systems in 5G and Beyond. Sensors 2021, 21, 537.
- Chanak, P.; Banerjee, I. Fuzzy rule-based faulty node classification and management scheme for large scale wireless sensor networks. Expert Syst. Appl. 2016, 45, 307–321.
- Yemeni, Z.; Wang, H.; Ismael, W.M.; Hawbani, A.; Chen, Z. CFDDR: A Centralized Faulty Data Detection and Recovery Approach for WSN With Faults Identification. IEEE Syst. J. 2021, 16, 3001–3012.
- Chander, B.; Kumaravelan, G. Outlier detection strategies for WSNs: A survey. J. King Saud Univ. Comput. Inf. Sci. 2021.
- Singh, J.; Kaur, R.; Singh, D. A survey and taxonomy on energy management schemes in wireless sensor networks. J. Syst. Arch. 2020, 111, 101782.
- Azzouz, I.; Boussaid, B.; Zouinkhi, A.; Abdelkrim, M.N. Multi-faults classification in WSN: A deep learning approach. In Proceedings of the International Conference on Sciences and Techniques of Automatic Control and Computer Engineering (STA), Monastir, Tunisia, 20–22 December 2020; pp. 343–348.
- Tavallali, P.; Tavallali, P.; Singhal, M. K-means tree: An optimal clustering tree for unsupervised learning. J. Supercomput. 2021, 77, 5239–5266.
- Lavanya, S.; Prasanth, A.; Jayachitra, S.; Shenbagarajan, A. A Tuned Classification Approach for Efficient Heterogeneous Fault Diagnosis in IoT-enabled WSN Applications. Measurement 2021, 183, 109771.
- Moridi, E.; Haghparast, M.; Hosseinzadeh, M.; Jassbi, S.J. Fault management frameworks in wireless sensor networks: A survey. Comput. Commun. 2020, 155, 205–226.
- Rajan, M.S.; Dilip, G.; Kannan, N.; Namratha, M.; Majji, S.; Mohapatra, S.K.; Patnala, T.R.; Karanam, S.R. Diagnosis of fault node in wireless sensor networks using adaptive neuro-fuzzy inference system. Appl. Nanosci. 2021, 1–9.
- Yu, T.; Akhtar, A.M.; Wang, X.; Shami, A. Temporal and spatial correlation based distributed fault detection in wireless sensor networks. In Proceedings of the 28th Canadian Conference on Electrical and Computer Engineering (CCECE), Halifax, NS, Canada, 3–6 May 2015; pp. 1351–1355.
- Jin, X.; Chow, T.W.S.; Sun, Y.; Shan, J.; Lau, B.C.P. Kuiper test and autoregressive model-based approach for wireless sensor network fault diagnosis. Wirel. Netw. 2015, 21, 829–839.
- Kaur, R.; Sandhu, J.K.; Sapra, L. Machine Learning Technique for Wireless Sensor Networks. In Proceedings of the International Conference on Parallel Distributed and Grid Computing (PDGC), Solan, India, 6–8 November 2020; pp. 332–335.
- Javaid, A.; Javaid, N.; Wadud, Z.; Saba, T.; Sheta, O.E.; Saleem, M.Q.; Alzahrani, M.E. Machine Learning Algorithms and Fault Detection for Improved Belief Function Based Decision Fusion in Wireless Sensor Networks. Sensors 2019, 19, 1334.
- Sutagundar, A.V.; Bennur, V.S.; Anusha, A.; Bhanu, K. Agent based fault tolerance in wireless sensor networks. In Proceedings of the 2016 International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 26–27 August 2016; pp. 1–6.
- Diaz, S.; Mendez, D.; Kraemer, R. A Review on Self-Healing and Self-Organizing Techniques for Wireless Sensor Networks. J. Circuits Syst. Comput. 2019, 28, 1930005.
- Seyfollahi, A.; Ghaffari, A. A lightweight load balancing and route minimizing solution for routing protocol for low-power and lossy networks. Comput. Netw. 2020, 179, 107368.
- Biswas, P.; Samanta, T. True Event-Driven and Fault-Tolerant Routing in Wireless Sensor Network. Wirel. Pers. Commun. 2020, 112, 439–461.
- Qiu, T.; Chen, N.; Li, K.; Qiao, D.; Fu, Z. Heterogeneous ad hoc networks: Architectures, advances and challenges. Ad Hoc Netw. 2017, 55, 143–152.
- Kiran, W.S.; Smys, S.; Bindhu, V. Clustering of WSN Based on PSO with Fault Tolerance and Efficient Multidirectional Routing. Wirel. Pers. Commun. 2021, 121, 31–47.