During the last years, different classifications of faults have been proposed in WSNs [
32,
35,
36,
37]. A clear understanding of these various classifications provides a defined foundation and enhancements to the proposed algorithms developed to address fault-related issues.
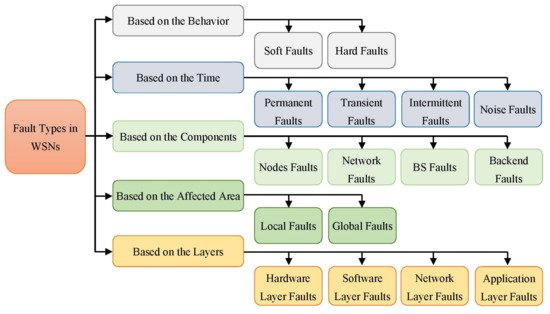
Figure 1 illustrates the various categories of errors in WSN as deliberated, respectively, in [
17,
21,
24]. Node behavioral faults, fault period, network infrastructure elements, the region impacted by a fault, and the layer where the error occurred are all factors considered in determining the overall categories [
36,
37].
Another type is based on network components: node, network, BS, and backend faults [
43]. The node failure is so popular in WSNs because the node plays a significant role in the network. Two main reasons cause node errors. Firstly, hardware errors include microcontroller failures, sensing unit failures, memory failures, and battery failures [
21,
24]. Secondly, software errors have routing failures, Media Access Control (MAC) failures, and application failures. In general, node failures result in erroneous network judgments, particularly when the failures are linked to cluster heads. When incorrect data are collected, and inaccurate information is delivered to the BS, improper information will be from the whole network. As a result, the majority of research focuses on failure detection and recovery in sensor nodes, particularly cluster heads, master nodes, and backbone nodes.
One of the most serious network flaws is routing process failure, which may result in the transmission of erroneous data or excessive delays [
16]. Because all networks are prone to a connection failure, unstable relationships between nodes result in network separation and dynamic changes in network topology. Network failures include radio interference, path faults, permanent or temporary path blockages, and simultaneous transmission. The data are sent to the backend system via the BS. This section may include errors resulting in the loss of network-wide data. For example, a problem with the BS may prohibit duties from being sent to sensors. Furthermore, congestion in a local region may extend to the BS, affecting data reception from other areas of the network [
30]. The lack of energy in this part of the network is one of the serious faults. Because BS is often situated distant from cities, it has limited and restricted energy and is prone to developing errors. Furthermore, the software utilized in BS may develop faults.
Lastly, the data collected in the BS is examined and assessed in the backend faults. Hackers may cause backend errors, resulting in defective nodes and network failure [
30,
31]. This failure impacts the whole network, resulting in system inefficiencies. Brief descriptions of faults are categorized according to their area of effect. A local fault occurs when a fault impacts one or more nodes. Nevertheless, some key nodes, such as the cluster head, backbone node, or manager node, have known issues regarded as global faults. Disregarding efforts to correct local problems creates global errors. For example, errors in sensor nodes lead to erroneous data being delivered to the BS.
Application layer errors are the fourth and last type in this taxonomy. Each application has its own set of faults that are distinct from those of the other applications. The most frequently encountered errors at the application layer relate to coverage and connectivity.
In conclusion, WSN is described as a network prone to failure, with many error types within it. Therefore, it is compulsory to have a complete fault tolerance structure to minimize the effect of these errors.
3. Proposed Classification of Fault Tolerance Management Approaches in WSN
Generally, no single fault tolerance structure fits all WSN applications due to its variety and wide use [
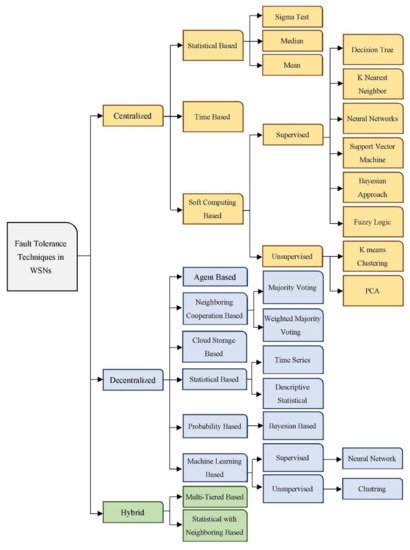
67]. Many approaches and frameworks have been proposed for the same primary purpose: to satisfy the fault-tolerance concept to gain a high level of reliability and integrity. A general categorization of fault management mechanisms is introduced in this section to make the representation of these schemes more understandable. The suggested categorization divided fault management structures into centralized, decentralized, and hybrid. Each category is subdivided into many subcategories.
Figure 3 illustrates the categorization of fault management schemes that have been suggested.
Figure 3. General taxonomy of fault tolerance approaches in WSNs.
3.1. Centralized Fault Tolerance Approaches
The center administrator or BS takes responsibility for fault detection and occurrence choices. By regularly injecting network status queries into the network to collect state information and evaluate this information to find faults, the BS identifies and handles all errors in the WSN. Although this method is easier for smaller networks, it has several drawbacks, including high message traffic near the BS and high energy usage [
68].
Based on their effectiveness, centralized approaches may be divided into statistical-based, soft computing-based, and time-based. With statistical methods, the statistics are transmitted to the BS and aggregated; then, it is examined to be assessed via the fault tolerance framework [
69]. This approach uses statistical methods to identify outliers in the data set under consideration, such as the sigma test, median, and mean.
Methods based on soft computing are algorithms primarily focused on machine learning methods [
70]. There are two types of learning methods: supervised learning and unsupervised learning. In supervised learning, an input-output collection is provided to a system, and the system is instructed to train a given input to outcome pairs in the group. To train the system, this technique needs some input data. Neural networks, support vector machines, K-nearest neighbor, Bayesian statistics, decision trees, and fuzzy logic are examples of learning methods [
21,
24,
31,
62]. However, in certain situations, supervised learning will not provide the desired results. Another machine learning technique is unsupervised learning. Learning is done on un-marked raw data to uncover unseen forms in unsupervised learning. Principal Component Analysis (PCA) and K-means clustering are examples of unsupervised learning [
71].
In time-based fault tolerance approaches, nodes utilize Carrier-Sense Multiple Access with Collision Avoidance (CSMA/CA) and constantly listen to the medium while the network is deployed. To begin, the BS builds a tree structure that links nodes and routes traffic. Data from adjacent nodes is collected at this stage. Finally, the BS allocates a slot to each sensor node for information transmission. Many slots are also allocated to nodes for time synchronization and error handling. Nodes use CSMA/CA for communication listening during the listening time to identify problems [
72]. Even though these methods depend on the nodes to detect the errors, the BS will make the main decision. As aforementioned, all centralized approaches suffer from high overhead and lack in scalability matter even though there are simple to implement. Generally, centralized methods have many drawbacks. First, because of the network’s size and density, a lot of information is communicated to the BS, rapidly depleting the energy of nodes nearby. Centralized paradigms are incompatible with large networks. The approaches also need a huge database to hold a huge number of data, increasing installation costs. Additionally, the BS is a weak point in centralized systems and it may have its own errors. When it fails, the output is inaccurate or absent. A faulty BS is tough to replace in many environments. Because the BS receives all network data, it becomes congested, affecting network performance. Lastly, centralized approaches transmit a huge amount of information over the wireless network to obtain information about its status, leading to increased energy consumption, bandwidth waste, and scalability issues [
73].
3.2. Decentralized Fault Tolerance Approaches
The decentralized fault-tolerant mechanisms will be tackled particularly in this sub-section. Unlike centralized control, these structures use numerous management stations spread throughout the whole wireless network. In decentralized frameworks, each node, cluster head, backbone node, or master node is in charge of a portion of the network. It has the ability to interact directly with other nodes to execute fault detection tasks performed by the BS in the last category [
19]. In distributed systems, sensor nodes control their resources and management systems. There is less need to communicate with BS when the nodes can make decisions regarding their status. In terms of functionality, distributed fault-tolerant structures are divided into six categories: neighborhood cooperation-based, statistical-based, probability-based, machine learning-based, cloud storage-based, and agent-based. The basic idea behind the neighborhood-based techniques is a correlation among nodes in the same region [
74].
Neighborhood voting may be split into majority voting and weighted majority voting. To determine the fault state of nodes, the majority of votes presume that neighboring nodes have the majority of error situations. For each node in the WSN, the weighted majority approach gathers weighted votes from all nearby nodes and forecasts a higher number of votes. Statistical methods are algorithms that identify errors in data using analytical techniques. Time-series-based and descriptive statistical-based are two subcategories of statistical methods. The time-series approach examines time-series data to identify patterns and calculate variations. Deviations in WSNs data are detected using tests. One of the preferable tests is the Kolmorgov Smirnov [
75]. On the other hand, descriptive statistical-based techniques are for determining defects that utilize one of the central tendency metrics, such as the mean of neighborhood nodes. Probability fault tolerance methods rely on the probability of node failure to identify the fault state of nodes in a distributed network environment
A node’s fault probability and the fault probability of its neighbors are used to compute the posterior fault probability, which is then used to identify the faulty nodes. Based on the Bayes theorem, Bayesian statistical approaches are used to determine the probability that a node is inaccurate. Machine-learning methods are a subclass of decentralized approaches that have lately received a lot of interest [
76].
These approaches may be divided into supervised and non-supervised detection techniques. Training data sets are used in supervised error detection methods to learn the difference between real and error data and to anticipate many sensor failures.
The node’s weight is used in neural network-based methods to anticipate data mistakes. Unlike supervised learning methods, unsupervised learning methods have not been given any datasets to work with and have not trained with any database. This area includes clustering methods. Clustering-based methods group nodes into different clusters and link them to a cluster head that examines each node. In agent-based algorithms, the ultimate error status of a sensor node is decided by agents chosen from across the WSN or by the sensor nodes themselves, depending on the methodology. Even though these methods use various information from neighbors, individual nodes or agents make the ultimate choice [
77]. Cloud-based methods take advantage of cloud-based resources to decrease the cost of computing tasks [
78].
The basic concept behind this method is to move the input data from the nodes to cloud storage and then utilize map reduction to parallelize the error detection process, which would decrease the time it takes to identify faults in the entire system [
79]. However, this method is not commonly used in WSNs.
The goal of decentralized fault tolerance approaches is to solve the issues that centralized fault management frameworks have, such as increasing energy efficiency and minimizing the total overhead [
19,
27]. Various numbers of nodes manage faults to achieve the goal instead of entirely depending on BS. However, distributed fault management systems still suffer from delays. They concentrate on lowering energy usage and increasing the accuracy of problem detection. The structures based on neighbor collaboration are focused on improving fault detection accuracy. Neighbor cooperation techniques are gaining popularity due to the requirement for more accurate fault tolerance frameworks in WSNs [
58,
59].
3.3. Hybrid Fault Tolerance Approaches
The last category in the proposed taxonomy is the hybrid fault tolerance structure, a combination of centralized and decentralized management approaches. Hybrid approaches can be divided into two main subcategories: multi-tiered based and statistical with neighboring based [
59]. Hybrid algorithms are employed in a large multi WSN, where nodes are grouped into clusters with cluster heads [
80]. Each cluster’s nodes transmit their information to the cluster leaders. Cluster heads then send the data to a central base station for processing [
2]. In the trust matrix method, a trust matrix is utilized to assess the trustworthiness of data. Hybrid algorithms also combine many detection methods that have been mentioned before into a single algorithm.
An example of this category is neighborhood algorithms in conjunction with descriptive statistical methods like mean and median. Hybrid methods’ main goal is to reduce energy usage and reduce the delay in fault detection. The fault detection time is minimal since nodes are responsible for detecting their own problems. Furthermore, implementing a fault tolerance system in the cluster heads and master nodes lowers node energy usage since nodes with more energy can detect and recover problems. However, the correct distribution of clusters in a network and their distance from the BS cause the network to become more complicated [
81].