In the last decade, distraction detection of a driver gained a lot of significance due to
increases in the number of accidents. Many solutions, such as feature based, statistical, holistic, etc.,
have been proposed to solve this problem. With the advent of high processing power at cheaper
costs, deep learning-based driver distraction detection techniques have shown promising results. The
study proposes ReSVM, an approach combining deep features of ResNet-50 with the SVM classifier,
for distraction detection of a driver. ReSVM is compared with six state-of-the-art approaches on
four datasets, namely: State Farm Distracted Driver Detection, Boston University, DrivFace, and
FT-UMT. Experiments demonstrate that ReSVM outperforms the existing approaches and achieves a
classification accuracy as high as 95.5%. The study also compares ReSVM with its variants on the
aforementioned datasets.
- Deep Learning
- Driver’s Distraction Detection
Methadology:
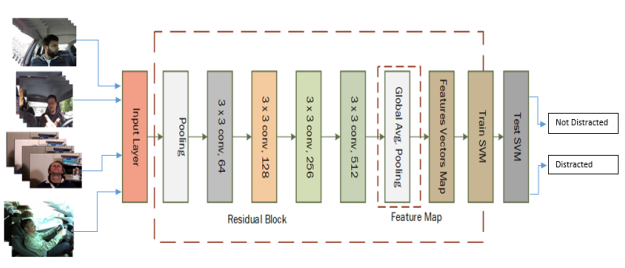
This study proposes a deep learning architecture, ReSVM, for driver’s distraction detection. ReSVM is an optimized version of ResNet-50 that uses deep features obtained
by the latter’s pooling layer and feeds these features to a support vector machine (SVM) as can be seen in Figure 3.
Previously, deep learning architectures, such as CNNs, could only use sigmoid functions for various computer vision tasks. Therefore, there was a limit on the number of layers of these networks. More recently, with the introduction of rectified linear unit, AlexNet and VGGNet have been able to use an increased number of layers i.e., 5 and 19, respectively. The increase in the number of layers resulted in an increase in training error. Later on, this degradation problem was addressed with the development of residual networks (ResNets) [30]. A large number of training samples from the ImageNet dataset were used for training a residual neural network (ResNet-50) to classify a diverse range of images including living things such as animals, birds, rodents, etc., and also various inanimate objects. The residual networks, with 50 or 101 layers, use residual blocks in their network architecture [30] and have consecutive 1 × 1, 3 × 3, and 1 × 1 convolution layers. Normally, deep ResNet layers contain 3 × 3 filters. Feature size is inversely proportional to the number of filters, i.e., if the feature map size is doubled, then the number of filters is reduced to half and vice versa. Due to this relationship, the time complexity is conserved.
Datasets We generated results on the four publicly available standard datasets given below to establish reliability of our approach and provide a comparison with state-of-the-art techniques. Since these datasets provide a broad coverage of the various types of distraction, by performing well on all of these, we establish that our approach can cater to a wide variety of scenarios.Various state-of-the-art approaches have generated results on specific datasets. In order to provide fair comparison with those aforementioned approaches, we had to generate results on those datasets as well. Moreover, these datasets provided sufficient coverage of
different activities that can be used to classify distraction detection.
State Farm Distracted Driver Detection
The study used the State Farm Distracted Driver Detection dataset (SFDDD) (https://www.kaggle.com/c/state-farm-distracted-driver-detection, accessed on 19 June 2022).
It consisted of 2D images from dashboard cameras. A total of 22,400 images, having a resolution of 640 × 840 pixels, were used in the experimentation. Out of these, 21,000
images contained a distracted driver. A detailed breakdown is given in Table 1. The dataset was divided into 20,400 training images and 2000 testing images. As shown in Figure, the dataset contained various activities that were indicative of distraction, namely: (i) texting,(ii) operating the radio, (iii) making phone calls, (iv) drinking, (v) combing, (vi) applying makeup, and (vii) talking

References
1. Baheti, B.; Gajre, S.; Talbar, S. Detection of distracted driver using convolutional neural network. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1032–1038.
2. Feng, Z.H.; Kittler, J.; Awais, M.; Huber, P.; Wu, X.J. Wing loss for robust facial landmark localisation with convolutional neural
networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22
Jun2018; pp. 2235–2245.
3. Cutsinger, M. December Is National Impaired Driving Prevention Month; Mothers Against Drunk Driving: Irving, TX, USA, 2017.
4. Rhanizar, A.; El Akkaoui, Z. A Predictive Framework of Speed Camera Locations for Road Safety. Comput. Inf. Sci. 2019,
12, 92–103. [CrossRef]
5. Figueredo, G.P.; Agrawal, U.; Mase, J.M.; Mesgarpour, M.; Wagner, C.; Soria, D.; Garibaldi, J.M.; Siebers, P.O.; John, R.I. Identifying
heavy goods vehicle driving styles in the united kingdom. IEEE Trans. Intell. Transp. Syst. 2018, 20, 3324–3336. [CrossRef]
6. Mase, J.M.; Agrawal, U.; Pekaslan, D.; Torres, M.T.; Figueredo, G.; Chapman, P.; Mesgarpour, M. Capturing uncertainty in heavy
goods vehicle driving behaviour. In Proceedings of the IEEE International Conference on Intelligent Transportation Systems,
Rhodes, Greece, 20–23 September 2020; Volume 2020.
7. LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [CrossRef]
8. Ouyang, W.; Wang, X.; Zeng, X.; Qiu, S.; Luo, P.; Tian, Y.; Li, H.; Yang, S.; Wang, Z.; Loy, C.C.; et al. Deepid-net: Deformable deep
convolutional neural networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern
Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2403–2412.
9. Sun, Y.; Wang, X.; Tang, X. Deep learning face representation from predicting 10,000 classes. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1891–1898.
10. Xiao, T.; Xia, T.; Yang, Y.; Huang, C.; Wang, X. Learning from massive noisy labeled data for image classification. In Proceedings
of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2691–2699.
11. Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; Van Der Laak, J.A.; Van Ginneken, B.; Sánchez, C.I.
A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [CrossRef]
12. Liu, Q.; Zhou, F.; Hang, R.; Yuan, X. Bidirectional-convolutional LSTM based spectral-spatial feature learning for hyperspectral
image classification. Remote Sens. 2017, 9, 1330. [CrossRef]
13. Kim, W.; Choi, H.K.; Jang, B.T.; Lim, J. Driver distraction detection using single convolutional neural network. In Proceedings
of the 2017 International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Korea, 18–20
October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1203–1205.
14. Majdi, M.S.; Ram, S.; Gill, J.T.; Rodríguez, J.J. Drive-net: Convolutional network for driver distraction detection. In Proceedings
of the 2018 IEEE Southwest Symposium on Image Analysis and Interpretation (SSIAI), Las Vegas, NV, USA, 8–10 April 2018;
IEEE: Piscataway, NJ, USA, 2018; pp. 1–4.
15. Abbas, T.; Ali, S.F.; Khan, A.Z.; Kareem, I. optNet-50: An Optimized Residual Neural Network Architecture of Deep Learning for
Driver’s Distraction. In Proceedings of the 2020 IEEE 23rd International Multitopic Conference (INMIC), Bahawalpur, Pakistan,
5–7 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–5.