This contribution assesses a new term that is proposed to be established within Land Change Science: Spatio-TEmporal Patterns of Land (‘STEPLand’). It refers to a specific workflow for analyzing land-use/land cover (LUC) patterns, identifying and modeling driving forces of LUC changes, assessing socio-environmental consequences, and contributing to defining future scenarios of land transformations. Researchers define this framework based on a comprehensive metaanalysis of 250 selected articles published in international scientific journals from 2000 to 2019. The empirical results demonstrate that STEPLand is a consolidated protocol applied globally, and the large diversity of journals, disciplines, and countries involved shows that it is becoming ubiquitous. The main characteristics of STEPLand are provided and discussed, demonstrating that the operational procedure can facilitate the interaction among researchers from different fields, and communication between researchers and policy makers.
- LUCC patterns
- spatial modeling of driving forces
- socio-environmental consequences
- future scenarios
- In-deep reading analysis
1. Introduction
2. STEPLand Framework
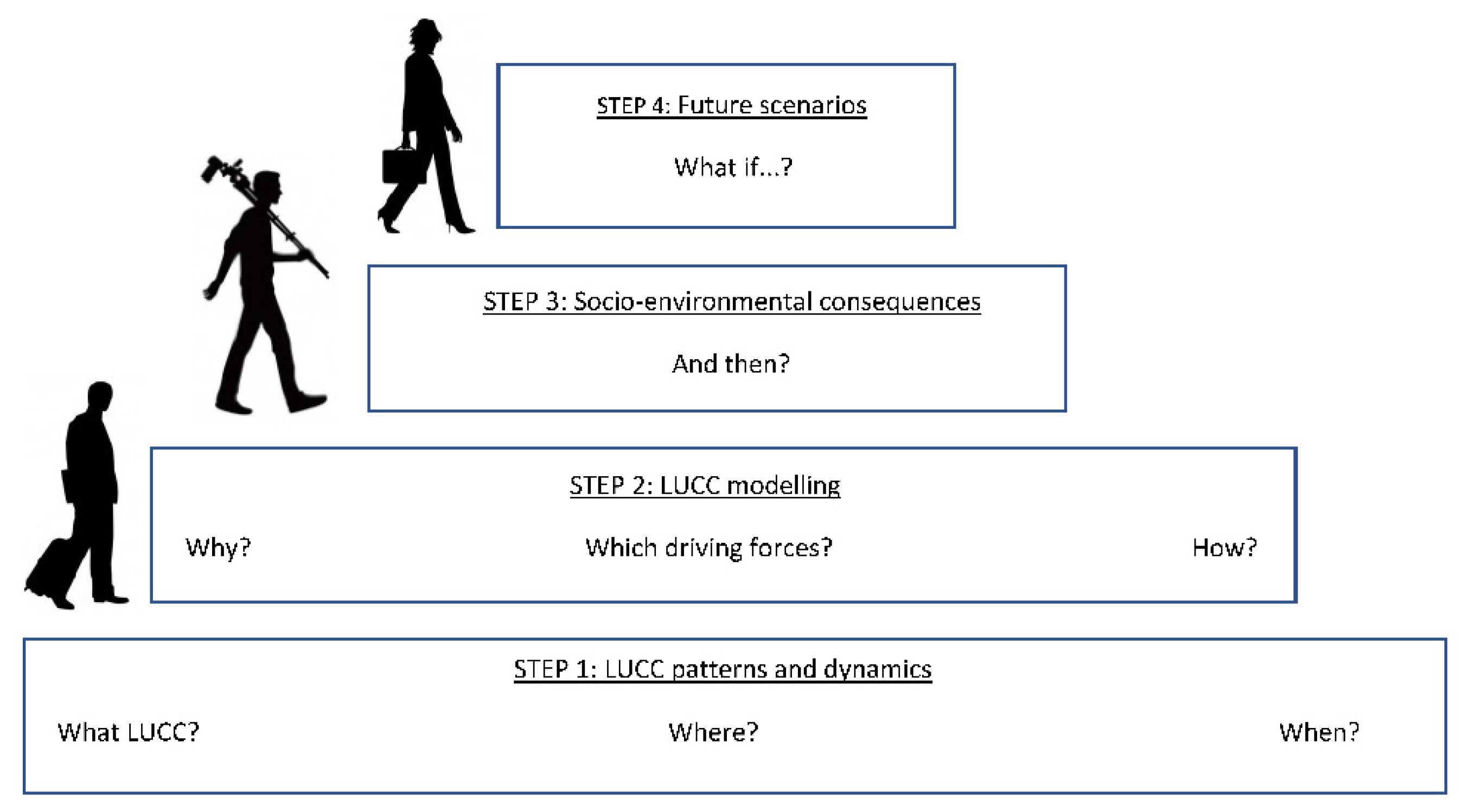
2.1. LUCC Patterns and Dynamics
2.2. LUCC Modeling
2.3. Socio-Environmental Consequences
2.4. Futures Scenarios
This entry is adapted from the peer-reviewed paper 10.3390/land11071065
References
- Turner, B.L., II; Lambin, E.F.; Reenberg, A. The emergence of land change science for global environmental change and sustainability. Proc. Natl. Acad. Sci. USA 2007, 104, 20666–20671.
- Brissoulis, H. Analysis of Land Use Change: Theoretical and Modeling Approaches, 2nd ed.; Loveridge, S., Jackson, R., Eds.; Regional Research Institute, West Virginia University: Morgantown, WV, USA, 2020; Available online: https://researchrepository.wvu.edu/rri-web-book/3 (accessed on 8 May 2020).
- Turner, B.L., II; Skole, D.; Sanderson, S.; Fischer, G.; Fresco, L.; Leemans, R. Land-Use and Land-Cover Change: Science/Research Plan; IGBP Report 35; IGBP/HDP; Royal Swedish Academy of Sciences: Stockholm, Sweden; Geneva, Switzerland, 1995.
- Seitzinger, S.P.; Gaffney, O.; Brasseur, G.; Broadgate, W.; Ciais, P.; Claussen, M.; Erisman, J.W.; Kiefer, T.; Lancelot, C.; Monks, P.S.; et al. International Geosphere–Biosphere Programme and Earth system science: Three decades of co-evolution. Anthropocene 2015, 12, 3–16.
- Arino, O.; Bicheron, P.; Achard, F.; Latham, J.; Witt, R.; Weber, J.L. Globcover: The Most Detailed Portrait of Earth; European Space Agency Bulletin: Frascati, Italy, 2008; Volume 136.
- Justice, C.; Gutman, G.; Vadrevu, K.P. NASA Land Cover and Land Use Change (LCLUC): An interdisciplinary research program. J. Environ. Manag. 2015, 148, 4–9.
- Verburg, P.H.; Crossman, N.; Ellis, E.C.; Heinimann, A.; Hostert, P.; Mertz, O.; Nagendra, H.; Sikor, T.; Erb, K.-H.; Golubiewski, N.; et al. Land system science and sustainable development of the earth system: A global land project perspective. Anthropocene 2015, 12, 29–41.
- Rounsevell, M.D.A.; Pedroli, B.; Erb, K.-H.; Gramberger, M.; Busck, A.G.; Haberl, H.; Kristensen, S.; Kuemmerle, T.; Lavorel, S.; Lindner, M.; et al. Challenges for land system science. Land Use Policy 2012, 29, 899–910.
- Gutman, G.; Janetos, A.C.; Justice, C.O.; Moran, E.F.; Mustard, J.F.; Rindfuss, R.R.; Skole, D.; Turner, B.L., II; Cochrane, M.A. Land Change Science: Observing, Monitoring and Understanding Trajectories of Change on the Earth’s Surface; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2004.
- Rindfuss, R.R.; Walsh, S.J.; Turner, B.L., II; Fox, J.; Mishra, V. Developing a science of land change: Challenges and methodological issues. Proc. Natl. Acad. Sci. USA 2004, 101, 13976–13981.
- Bajocco, S.; Dragoz, E.; Gitas, I.; Smiraglia, D.; Salvati, L.; Ricotta, C. Mapping forest fuels through vegetation phenology: The role of coarse-resolution satellite time-series. PLoS ONE 2015, 10, e0119811.
- Rindfuss, R.R.; Entwisle, B.; Walsh, S.J.; An, L.; Badenoch, N.; Brown, D.G.; Deadman, P.; Evans, T.P.; Fox, J.; Geoghegan, J.; et al. Land use change: Complexity and comparisons. J. Land Use Sci. 2008, 3, 1–10.
- Meyfroidt, P.; Chowdhury, R.R.; de Bremond, A.; Ellis, E.C.; Erb, K.-H.; Filatova, T.; Garrett, R.D.; Grove, J.M.; Heinimann, A.; Kuemmerle, T.; et al. Middle-range theories of land system change. Glob. Environ. Change 2018, 53, 52–67.
- Baynard, C.W. Remote sensing applications: Beyond land-use and land-cover change. Adv. Remote Sens. 2013, 2, 228–241.
- Nagabhatla, N.; Padmanabhan, M.; Kühle, P.; Vishnudas, S.; Betz, L.; Niemeyer, B. LCLUC as an entry point for transdisciplinary research–Reflections from an agriculture land use change study in South Asia. J. Environ. Manag. 2015, 148, 42–52.
- Long, H.; Tang, G.; Li, X.; Heilig, G.K. Socio-economic driving forces of land-use change in Kunshan, the Yangtze River Delta economic area of China. J. Environ. Manag. 2007, 83, 351–364.
- Uddin, K.; Chaudhary, S.; Chettri, N.; Kotru, R.; Murthy, M.; Chaudhary, R.P.; Ning, W.; Shrestha, S.M.; Gautam, S.K. The changing land cover and fragmenting forest on the Roof of the World: A case study in Nepal’s Kailash Sacred Landscape. Landsc. Urban Plan. 2015, 141, 1–10.
- Gómez, C.; White, J.C.; Wulder, M.A. Optical remotely sensed time series data for land cover classification: A review. ISPRS J. Photogramm. Remote Sens. 2016, 116, 55–72.
- Serra, P.; Pons, X. Monitoring farmers’ decisions on Mediterranean irrigated crops using satellite image time series. Int. J. Remote Sens. 2008, 29, 2293–2316.
- Wulder, M.A.; Masek, J.G.; Cohen, W.B.; Loveland, T.R.; Woodcock, C.E. Opening the archive: How free data has enabled the science and monitoring promise of Landsat. Remote Sens. Environ. 2012, 122, 2–10.
- Kuemmerle, T.; Erb, K.; Meyfroidt, P.; Muller, D.; Verburg, P.H.; Estel, S.; Haberl, H.; Hostert, P.; Jepsen, M.R.; Kastner, T.; et al. Challenges and opportunities in mapping land use intensity globally. Curr. Opin. Environ. Sustain. 2013, 5, 484–493.
- Sishodia, R.; Ray, R.L.; Singh, S.K. Applications of Remote Sensing in Precision Agriculture: A Review. Remote Sens. 2020, 12, 3136.
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870.
- Gilani, H.; Shrestha, H.L.; Murthy, M.S.R.; Phuntso, P.; Pradhan, S.; Bajracharya, B.; Shrestha, B. Decadal land cover change dynamics in Bhutan. J. Environ. Manag. 2015, 148, 91–100.
- Phiri, D.; Morgenroth, J. Developments in Landsat land cover classification methods: A review. Remote Sens. 2017, 9, 967.
- Alvarez-Martinez, J.M.; Suárez-Seoanea, S.; De Luis Calabuig, E. Modelling the risk of land cover change from environmental and socio-economic drivers in heterogeneous and changing landscapes: The role of uncertainty. Landsc. Urban Plan. 2011, 101, 108–119.
- Serra, P.; Pons, X. Two Mediterranean irrigation communities in front of water scarcity: A comparison using satellite image time series. J. Arid Environ. 2013, 98, 41–51.
- Kibret, K.S.; Marohn, C.; Cadisch, G. Assessment of land use and land cover change in South Central Ethiopia during four decades based on integrated analysis of multi-temporal images and geospatial vector data. Remote Sens. Appl. Soc. Environ. 2016, 3, 1–19.
- Clement, F.; Orange, D.; Williams, M.; Mulley, C.; Epprecht, M. Drivers of afforestation in Northern Vietnam: Assessing local variations using geographically weighted regression. Appl. Geogr. 2009, 29, 561–576.
- Ariti, A.T.; van Vliet, J.; Verburg, P.H. Land-use and land-cover changes in the Central Rift Valley of Ethiopia: Assessment of perception and adaptation of stakeholders. Appl. Geogr. 2015, 65, 28–37.
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201.
- Pontius, R.G.; Shusas, E.; McEachern, M. Detecting important categorical land changes while accounting for persistence. Agric. Ecosyst. Environ. 2004, 101, 251–268.
- Cuba, N. Research note: Sankey diagrams for visualizing land cover dynamics. Landsc. Urban Plan. 2015, 139, 163–167.
- Mas, J.F. Monitoring land-cover changes: A comparison of change detection techniques. Int. J. Remote Sens. 1999, 20, 139–152.
- Dewan, A.M.; Yamaguchi, Y.; Rahman, M.Z. Dynamics of land use/cover changes and the analysis of landscape fragmentation in Dhaka Metropolitan, Bangladesh. GeoJournal 2012, 77, 315–330.
- Aspinall, R.J.; Hill, M.J. Land cover change: A method for assessing the reliability of land cover changes measured from remotely-sensed data. In Proceedings of the International Geoscience and Remote Sensing Symposium, IGARSS ’97, Singapore, 4–8 August 1997; pp. 269–271.
- Serra, P.; Pons, X.; Saurí, D. Post-classification change detection with data from different sensors. Some accuracy considerations. Int. J. Remote Sens. 2003, 24, 3311–3340.
- Szabó, S.; Bertalan, L.; Kerekes, A.; Novák, T.J. Possibilities of land use change analysis in a mountainous rural area: A methodological approach. Int. J. Geogr. Inform. Sci. 2016, 30, 708–726.
- Chrisman, N.R. The accuracy of map overlays: A reassessment. Landsc. Urban Plan. 1987, 14, 427–439.
- Goodchild, M.F.; Guoqing, S.; Shiren, Y. Development and test of an error model for categorical data. Int. J. Geogr. Inf. Systems 1992, 6, 87–104.
- Frondoni, R.; Mollo, B.; Capotorti, G. A landscape analysis of land cover change in the Municipality of Rome (Italy): Spatio-temporal characteristics and ecological implications of land cover transitions from 1954 to 2001. Landsc. Urban Plan. 2011, 100, 117–128.
- Singh, A. Digital change detection techniques using remotely-sensed data. Int. J. Remote Sens. 1989, 10, 989–1003.
- Lambin, E.F.; Strahler, A.H. Change vector analysis in multitemporal space: A tool to detect and categorize land-cover change processes using high temporal resolution satellite data. Remote Sens. Environ. 1994, 48, 231–244.
- Were, K.O.; Dick, Ø.B.; Singh, B.R. Remotely sensing the spatial and temporal land cover changes in Eastern Mau forest reserve and Lake Nakuru drainage basin, Kenya. Appl. Geogr. 2013, 41, 75–86.
- Brown, D.G.; Verburg, P.H.; Pontius, R.G., Jr.; Lange, M. Opportunities to improve impact, integration, and evaluation of land change models. Curr. Opin. Environ. Sustain. 2013, 5, 452–457.
- Verburg, P.; Ritsema van Eck, J.; de Nijs, T.; Dijst, M.; Schot, P. Determinants of land use change patterns in the Netherlands. Environ. Plan. B Urban Anal. City Sci. 2004, 31, 125–150.
- Bürgi, M.; Hersperger, A.M.; Schneeberger, N. Driving forces of landscape change–Current and new directions. Landsc. Ecol. 2004, 19, 857–868.
- Hersperger, A.M.; Gennaio, M.P.; Verburg, P.H.; Bürgi, M. Linking land change with driving forces and actors: Four conceptual models. Ecol. Soc. 2010, 15, 1. Available online: http://www.ecologyandsociety.org/vol15/iss4/art1/ (accessed on 25 February 2020).
- Dang, A.N.; Kawasaki, A. A review of methodological integration in land-use change models. Int. J. Agric. Environ. Inf. Syst. 2016, 7, 1–25.
- Geist, H.J.; Lambin, E.F. What Drives Tropical Deforestation? A Meta-Analysis of Proximate and Underlying Causes of Deforestation Based on Subnational Case Study Evidence; Land-Use and Land-Cover Change (LUCC). Project IV. International Human Dimensions Programme on Global Environmental Change (IHDP); International Geosphere-Biosphere Programme (IGBP); LUCC International Project Office: Louvain-la-Neuve, Belgium, 2001.
- Serneels, S.; Lambin, E.F. Proximate causes of land-use change in Narok District, Kenya: A spatial statistical model. Agric. Ecosyst. Environ. 2001, 85, 65–81.
- Verburg, P.H.; Schot, P.P.; Dijst, M.J.; Veldkamp, A. Land use change modelling: Current practice and research priorities. GeoJournal 2004, 61, 309–324.
- Agarwal, C.; Green, G.L.; Grove, M.; Evans, T.; Schweik, C. A Review and Assessment of Land-Use Change Models: Dynamics of Space, Time and Human Choice; General Technical Report NE-297; United States Department of Agriculture, Indiana University: Bloomington, IN, USA, 2000.
- Schneeberger, N.; Bürgi, M.; Hersperger, A.M.; Ewald, K.C. Driving forces and rates of landscape change as a promising combination for landscape change research—An application on the northern fringe of the Swiss Alps. Land Use Policy 2007, 24, 349–361.
- Valbuena, D.; Verburg, P.H.; Bregt, A.K.; Ligtenberg, A. An agent-based approach to model land-use change at a regional scale. Landsc. Ecol. 2010, 25, 185–199.
- Mas, J.F.; Paegelow, M.; Camacho Olmedo, M.T. LUCC modeling approaches to calibration. In Geomatic Approaches for Modeling Land Change Scenarios; Camacho Olmedo, M.T., Paegelow, M., Mas, J.-F., Escobar, F., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 11–25.
- Parcerisas, L.L.; Marull, J.; Pino, J.; Tello, E.; Coll, F.; Basnou, C. Land use changes, landscape ecology and their socioeconomic driving forces in the Spanish Mediterranean coast (El Maresme County, 1850–2005). Environ. Sci. Policy 2012, 23, 120–132.
- Mas, J.F.; Kolb, M.; Paegelow, M.; Camacho Olmedo, M.T.; Houet, T. Inductive pattern-based land use/cover change models: A comparison of four software packages. Environ. Model. Softw. 2014, 51, 94–111.
- Pérez-Vega, A.; Mas, J.F.; Ligmann-Zielinska, A. Comparing two approaches to land use/cover change modeling and their implications for the assessment of biodiversity loss in a deciduous tropical forest. Environ. Model. Softw. 2012, 29, 11–23.
- Camacho Olmedo, M.T.; Paegelow, M.; Mas, J.-F.; Escobar, F. Geomatic Approaches for Modeling Land Change Scenarios; Springer International Publishing: Cham, Switzerland, 2018.
- Kolb, M.; Mas, J.F.; Galicia, L. Evaluating drivers of land-use change and transition potential models in a complex landscape in Southern Mexico. Int. J. Geogr. Inform. Sci. 2013, 27, 1804–1827.
- Entwisle, B.; Walsh, S.J.; Rindfuss, R.R.; Chamratrithirong, A. Land-use/land-cover and population dynamics, Nang Rong, Thailand. In People and Pixels. Linking Remote Sensing and Social Science; Liverman, D., Moran, E.F., Rindfuss, R.R., Stern, P.C., Eds.; National Academy Press: Washington, DC, USA, 1998; pp. 121–144.
- Walsh, S.J.; Crews-Meyer, K.A. Linking People, Place and Policy: A GIScience Approach; Kluwer Academic Publishers: Norwell, MA, USA, 2002.
- Fox, J.; Rindfuss, R.R.; Walsh, S.J.; Mishra, V. People and the Environment; Kluwer Academic Publishers: Boston, MA, USA, 2004.
- Zambon, I.; Colantoni, A.; Carlucci, M.; Morrow, N.; Sateriano, A.; Salvati, L. Land quality, sustainable development and environmental degradation in agricultural districts: A computational approach based on entropy indexes. Environ. Impact Assess. Rev. 2017, 64, 37–46.
- Salvati, L.; Ciommi, M.T.; Serra, P.; Chelli, F.M. Exploring the spatial structure of housing prices under economic expansion and stagnation: The role of socio-demographic factors in metropolitan Rome, Italy. Land Use Policy 2019, 81, 143–152.
- Bajocco, S.; Ceccarelli, T.; Smiraglia, D.; Salvati, L.; Ricotta, C. Modeling the ecological niche of long-term land use changes: The role of biophysical factors. Ecol. Indic. 2016, 60, 231–236.
- Wood, C.H.; Skole, D. Linking satellite, census, and survey data to study deforestation in the Brazilian Amazon. In People and Pixels. Linking Remote Sensing and Social Science; Liverman, D., Moran, E.F., Rindfuss, R.R., Stern, P.C., Eds.; National Academy Press: Washington, DC, USA, 1998; pp. 70–93.
- Perz, S.G.; Skole, D.L. Social determinants of secondary forests in the Brazilian Amazon. Soc. Sci. Res. 2003, 32, 25–60.
- Reger, B.; Otte, A.; Waldhardt, R. Identifying patterns of land-cover change and their physical attributes in a marginal European landscape. Landsc. Urban Plan. 2007, 81, 104–113.
- Shupe, S. Statistical and Spatial Analysis of Land Cover Impact on Selected Metro Vancouver, British Columbia Watersheds. Environ. Manag. 2013, 51, 18–31.
- Monteiro, A.T.; Fava, F.; Hiltbrunner, E.; Marianna, G.D.; Bocchi, S. Assessment of land cover changes and spatial drivers behind loss of permanent meadows in the lowlands of Italian Alps. Landsc. Urban Plan. 2011, 100, 287–294.
- Espindola, G.M.; de Aguiar, A.P.D.; Pebesma, E.; Câmara, G.; Fonseca, L. Agricultural land use dynamics in the Brazilian Amazon based on remote sensing and census data. Appl. Geogr. 2012, 32, 240–252.
- Chhabra, A.; Geist, H.; Houghton, R.A.; Haberl, H.; Braimoh, A.K.; Vlek, P.L.G.; Patz, J.; Xu, J.; Ramankutty, N.; Coomes, O.; et al. Multiple impacts pof land-use/cover change. In Land-Use and Land-Cover Change. Local Processes and Global Impacts; Lambin, E.F., Geist, H., Eds.; Springer: Heidelberg, Germany, 2006; pp. 71–116.
- Salvati, L.; Gemmiti, R.; Perini, L. Land degradation in Mediterranean urban areas: An unexplored link with planning? Area 2012, 44, 317–325.
- Dadashpoor, H.; Azizi, P.; Moghadas, M. Land use change, urbanization, and change in landscape pattern in a metropolitan area. Sci. Total Environ. 2019, 655, 707–719.
- Wu, Y.; Li, S.; Yu, S. Monitoring urban expansion and its effects on land use and land cover changes in Guangzhou city, China. Environ. Monit. Assess. 2016, 188, 54.
- McGarigal, K.; Cushman, S.; Ene, E. FRAGSTATS v4: Spatial Pattern Analysis Program for Categorical and Continuous Maps. 2012. Available online: https://www.umass.edu/landeco/research/fragstats/fragstats.html (accessed on 25 May 2021).
- Arowolo, A.O.; Deng, X.; Olatunji, O.A.; Obayelu, A.E. Assessing changes in the value of ecosystem services in response to land-use/land-cover dynamics in Nigeria. Sci. Total Environ. 2018, 636, 597–609.
- Burkhard, B.; Kroll, F.; Nedkov, S.; Müller, F. Mapping ecosystem service supply, demand and budgets. Ecol. Indic. 2012, 21, 17–29.
- Kertész, A.; Nagy, L.A.; Balázs, B. Effect of land use change on ecosystem services in Lake Balaton Catchment. Land Use Policy 2019, 80, 430–438.
- Basse, R.M.; Omrani, H.; Charif, O.; Gerber, P.; Bódis, K. Land use changes modelling using advanced methods: Cellular automata and artificial neural networks. The spatial and explicit representation of land cover dynamics at the cross-border region scale. Appl. Geogr. 2014, 53, 160–171.
- Aburas, M.M.; Ahamad, M.S.S.; Omar, N.Q. Spatio-temporal simulation and prediction of land-use change using conventional and machine learning models: A review. Environ. Monit. Assess. 2019, 205, 191–205.
- Hu, Y.; Batunacun; Zhen, L.; Zhuang, D. Assessment of land-use and land-cover change in Guangxi, China. Sci. Rep. 2019, 9, 2189.
- Garcia-Frapolli, E.; Ayala-Orozco, B.; Bonilla-Moheno, M.; Espadas-Manrique, C.; Ramos-Fernández, G. Biodiversity conservation, traditional agriculture and ecotourism: Land cover/land use change projections for a natural protected area in the northeastern Yucatan Peninsula, Mexico. Landsc. Urban Plan. 2007, 83, 137–153.
- Marshall, E.; Randhir, T.O. Spatial modeling of land cover change and watershed response using Markovian cellular automata and simulation. Water Resour. Res. 2008, 44, 1–10.
- Omrani, H.; Charif, O.; Gerber, P.; Bódis, K.; Basse, R.M. Simulation of Land Use Changes Using Cellular Automata and Artificial Neural Network; Working Paper No. 2012-01; CEPS/INSTEAD: Luxembourg, 2012.