Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Along with the prevalence and increasing influence of the speaker recognition technology, its security has drawn broad attention. Though speaker recognition systems (SRSs) have reached a high recognition accuracy, their security remains a big concern since a minor perturbation on the audio input may result in reduced recognition accuracy.
- speaker recognition
- adversarial examples
1. Overview of SRS
Speaker verification systems consist of two modules: front-end embedding and back-end scoring. For any given audio, the embedding module represents the acoustic features of the audio by fixed-length high-dimensional feature vectors, and these vectors are then input to the back-end scoring module for similarity calculation to obtain the corresponding speaker labels for this segment of audio.
The earliest SR models, such as the dynamic time warping (DTW) model [45], recognize the speakers based on the speech signals by template matching. Later, some Gaussian mixture models (GMMs) [46,47], like the Gaussian mixture model-universal background model (GMM-UBM) and the Gaussian mixture model-support vector machine (GMM-SVM) model were developed, which represent the original audio signals by the trained model to recognize the speaker. Then, identifying vector models (i-vector) [48] that recognize speaker voice features became the mainstream method because they rely on data of smaller lengths. As deep learning technology advances, deep speaker vectors come to play a dominating role: deep neural networks are trained to extract speech features and represent the speech features as d-vectors [49] or x-vectors [8]. Bai et al. [50] made a detailed summary of works on DNN-based SRSs.
Figure 1 presents the general framework of traditional SR and deep learning-based SRSs, which comprises three stages: training, enrolling, and verification.
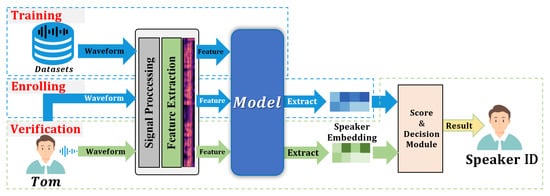
Figure 1. The general framework of the speaker recognition systems.
-
Training: over ten thousand audio clips from large amounts of speakers are used to train the speaker embedding module and obtain human voice feature distributions, regardless of single speakers;
-
Enrolling: the enrolled speaker utterance is mapped onto a unique labeled speaker embedding through the speaker embedding module, and this high-dimensional feature vector is this speaker’s unique identity;
-
Verification: the model scores the utterance of an unknown speaker by extracting high-dimensional feature vectors from the embedding module. The scoring module assesses the similarity between the recorded embedding and the speaker embedding, and the score and decision module is based on to judge whether the speaker is legitimate.
At the training stage, the feature extraction module converts the original speech signals into acoustic waveforms with primary signal features. Regular feature extraction algorithms include Mel frequency analysis, filter-bank, Mel-scale frequency cepstral coefficients (MFCC) [51], and perceptual linear predictive (PLP) [52]. The speaker embedding network can be modeled by models such as LSTM, ResNet, time-delay neural network (TDNN), etc. There are two types of back-end scoring models: probabilistic linear discriminant analysis (PLDA) [53] and cosine similarity [54]: the former works well in most cases, but requires training based on utterances [55]; the latter provides an alternative to PLDA but dispenses with the need for training.
2. SR Task
SR tasks can be divided into text-dependent and text-independent tasks by whether the audio clips are recorded by specific texts at the enrolling and verification stages. In text-dependent tasks, speech examples of specific texts are produced in both the training and testing stages, and though the model training consumes little time, the text is specific, and hence the model is short of universality. Text-independent tasks do not depend on the content of the audio, and the verification module recognizes the speaker by converting the audio content into the speaker’s high-dimensional speaker feature vectors, which is convenient but consumes considerable quantities of training resources. In the present work, we consider only the adversarial attack and defense of text-independent SRSs (in fact, most works in this regard focus on text-independent SRSs). In text-independent SRSs, SR tasks can be divided by the task target into close-set speaker identification (CSI) tasks, open-set speaker identification (OSI) tasks, and speaker verification (SV) tasks.
2.1. CSI Task
Close-set speaker identification (CSI) tasks [56,57] can be regarded as a multi-classification problem, which identifies a specific speaker from the corpus of a set of enrolled speakers, i.e., the system always identifies input audio as a specific label in the training dataset. Chen et al. [58] divided CSI tasks into two sub-tasks: CSI with enrollment (CSI-E) and CSI with no enrollment (CSI-NE). CSI-E strictly follows the process described above. In contrast, CSI-NE has no enrollment, and the speaker embedding module can be used directly to recognize the speaker. Thus, ideally speaking, in CSI-NE tasks, the identified speaker will take part in the training stage, whereas in CSI-E tasks, the identified speaker has already been enrolled in the enrolling stage but does not necessarily take part in the training stage. Equation (1) describes the general process of CSI tasks:
where I denotes the speaker label, θ is the parameter of the embedding model, and N is the number of registered speakers. f(⋅) denotes the similarity score calculated between the registered vector xe and the test vector xt, and the model outputs the speaker ID with the highest score.
2.2. OSI Task
Different from CSI tasks, in open-set speaker identification (OSI) tasks [8], the model obtains a threshold by the PLDA or cosine similarity algorithm, and recognizes the test utterance as an enrolled speaker by comparing the calculated similarity score and the preset threshold. OSI tasks can also identify unknown speakers. That is, a speaker that is not in the original training dataset can also be enrolled in the OSI system to generate specific feature vectors, and in the verification process, the model converts the to-be-identified speaker into high-dimensional vector embeddings, and uses the back-end scoring module to produce a similarity score: if the maximum score is below the preset threshold, then the speaker is identified as an unenrolled speaker and hence is denied access. Similarly, the process of OSI tasks can be summarized by an equation, as shown in Equation (2):
where τ is a pre-received threshold in the model, the test audio will be accepted and correctly recognized by the system when and only when the maximum score exceeds the threshold τ in OSI, otherwise the model will directly filter out the audio.
2.3. SV Task
Both CSI and OSI tasks can be termed collectively as a 1:N identification task (i.e., discriminating input audio among a collection of N-registered speakers), and they require a large number of different speakers’ speech for model training. In contrast, the SV system aims to verify whether an input voice (virtual speaker) is pronounced according to his/her pre-recorded words, which is a 1:1 identification task that models the vocal characteristics of only one speaker, and then verifies whether the input voice is produced by a unique registered speaker according to a predefined threshold, and if the score does not exceed the threshold, the input voice is considered an impostor and is rejected.
where f(⋅) represents the calculation of the similarity score S between the registered vector xe and the test vector xt, and θ is the parameter of the embedding model. The score is accepted if it is greater than a threshold value and rejected otherwise.
3. Victim Models
Existing speaker attacks are mainly against SR models built on deep neural networks (DNNs), such as SincNet, d-vector, and x-vector, rather than the template matching-based DTW models and the statistical distribution-based GMM, GMM-UBM, and GMM-SVM models.
As Table 1 shows, the i-vector SR model proposed by Kanagasundaram [59] shifts the high-dimensional speaker features into a lower-dimension full-factor subspace, models global differences in data in low dimensions, and combines systems, such as GMM-MMI, to enhance the recognition capability of the model in this low-dimensional subspace, and improves the identification capacity of the model in this low-dimension space by GMM-MMI and other systems, which reduces the computing complexity and training time. However, as the i-vector model maps the data into the full-factor subspace, the system is susceptible to noises. Therefore, Variani et al. [49] proposed to use DNN for the feature extraction of speaker audio and took the output of the last hidden layer as the speaker’s features and took the average of all the speaker’s features as the speaker’s vocal embedding vector, a model called d-vector. The d-vector model has a better performance compared to the i-vector model both in clean and noisy environments. David Snyder proposed the x-vector model [8], which uses the TDNN structure for feature extraction, and compared to the d-vector, which simply averages the speaker features as the voice pattern model, the x-vector aggregates the speaker features and inputs them into the DNN again to obtain the final voice pattern model. The r-vector model proposed by Hossein et al. [60] applies ResNet, which further reduces the EER compared to the x-vector model. Mirco Ravanelli [61] argues that acoustic features extracted by traditional i-vector methods and deep learning methods using signal processing techniques (e.g., MFCC, and FBank) would lead to a loss of acoustic features in the original audio, for which he proposed the SincNet model, which uses a data-driven approach to learn filter parameters directly, allowing the model to learn narrowband speaker characteristics, such as pitch and resonance peaks, well from the original data. In recent studies, Brecht et al. [9] proposed ECAPA-TDNN, a new TDNN-based vocal feature extractor; ECAPA-TDNN further develops on the original x-vector architecture, focusing more on the channels as well as the propagation and aggregation of features, resulting in a 19% improvement in the EER performance of the system compared to the x-vector model. The deep speaker [62] proposed by Baidu adopts an end-to-end strategy to aggregate feature extraction and speaker recognition into the network structure, which can improve the performance of the fixed speaker list.
Table 1. Common victim SR models.
| Strategy | Model | Dataset | Task | Metrics | Performance |
|---|---|---|---|---|---|
| Statistics | GMM-UBM | NIST SRE | OSI/SV | EER | 1.81% |
| i-vector | NIST 2008 | OSI/SV | EER | 6.3% | |
| Embedding | AudioNet | LibriSpeech | CSI | ACC | 99.7% |
| VGGvox | Voxceleb1 | CSI | ACC | 92.1% | |
| d-Vector | Google data | OSI/SV | EER | 4.54% | |
| x-vector | VoxCeleb | OSI/SV | EER | 4.16% | |
| r-Vector | VoxCeleb | OSI/SV | EER | 1.49% | |
| SincNet | LibriSpeech | OSI/SV | EER | 0.96% | |
| ECAPA-TDNN | VoxCeleb2 | OSI/SV | EER | 0.87% | |
| End to End | ResCNN | MTurk | OSI/SV | EER | 2.83% |
| GRU | MTurk | OSI/SV | EER | 2.78% |
4. Datasets
Depending on different tasks and target models, researchers choose publicly available mainstream datasets to evaluate their attack performance. Some mainstream datasets are presented here: TIMIT [63], NTIMIT [64], Aishell [65,66], LibriSpeech [67], Voxceleb1/2 [62,68], YOHO [69], and CSTR VCTK [70], and their details are shown in Table 2 below.
Table 2. Generic datasets for speaker recognition.
| Datasets | Sample Rate |
Data Size | Spk Num | Language | Text Dependency |
Condition |
|---|---|---|---|---|---|---|
| TIMIT | 16 kHz | 6300 sentences |
630 | English | TI | Clean |
| NTIMIT | 8 kHz | 6300 sentences |
630 | English | TI | Telephone line |
| Aishell | 16 kHz | 178 h | 400 | Chinese | TI | No noise |
| LibriSpeech | 16 kHz | 153,516 utterances |
>9000 | English | TI | / |
| VoxCeleb1 | 16 kHz | 1,128,246 utterances |
1251 | English | TI | Multi-media |
| VoxCeleb2 | - | 100 w sentences |
6112 | Multilingual | TI | Multi-media |
| YOHO | 8 kHz | 5500 phrases |
138 | English | TD | Office |
| CSTR VCTK | 48 kHz | 1000 sentences |
30 | English | TD | Wild |
-
TIMIT: The standard dataset in the field of speech recognition is a relatively small dataset that enables the training and testing of models in a short period of time, and its database is manually annotated down to the phoneme, with speakers from all parts of the United States, and provides detailed speaker information, such as ethnicity, education, and even height.
-
NTIMIT: The dataset that puts the audio data in TIMIT on a different telephone line for transmission and then the reception is a dataset created to implement voice recognition in the telephone network.
-
Aishell: Aishell-1 is the first large data volume Chinese dataset, with 178 h of speech, 400 speakers, 340 people in the training set, 20 people in the test set, and 40 people in the validation set, each of whom speaks about 300 sentences. Aishell-2 expands the data volume to 1000 h of speech, with 1991 speakers, each of whom speaks 500 sentences. The words spoken by each person may be repeated.
-
LibriSpeech: The dataset is a large corpus containing approximately 1000 h of English speech. The data come from the audiobook recordings read by different readers of the LibriVox project, organized according to the sections of the audiobooks. It is segmented and correctly aligned.
-
Voxceleb1,Voxceleb2: Two speaker recognition datasets without intersection, both of which are obtained from open source video sites captured by a set of fully automated programs based on computer vision technology development. They differ in size, with VoxCeleb2 compensating for the lack of ethnic diversity in VoxCeleb1 by being five times larger than VoxCeleb1 in terms of data size.
-
YOHO: A speech dataset collected in an office environment that is text-dependent, where the speaker speaks in a restricted textural combination.
-
CSTR VCTK: A dataset including noisy and non-noisy speech with a sampling rate of 48 kHz and in which the speaker is accented.
This entry is adapted from the peer-reviewed paper 10.3390/electronics11142183
This entry is offline, you can click here to edit this entry!