Nondestructive evaluation (NDE) techniques are used in many industries to evaluate the properties of components and inspect for flaws and anomalies in structures without altering the part’s integrity or causing damage to the component being tested. This includes monitoring materials’ condition (Material State Awareness (MSA)) and health of structures (Structural Health Monitoring (SHM)). NDE techniques are highly valuable tools to help prevent potential losses and hazards arising from the failure of a component while saving time and cost by not compromising its future usage. On the other hand, Artificial Intelligence (AI) and Machine Learning (ML) techniques are useful tools which can help automating data collection and analyses, providing new insights, and potentially improving detection performance in a quick and low effort manner with great cost savings.
1. Introduction
Nondestructive Evaluation (NDE) is an accepted and well-established method of inspection, material state awareness (MSA), structural health monitoring (SHM) and in situ process monitoring for almost every part and product during manufacturing processes and service life of the components [1][2][3]. State-of-the-art and future of NDE requires a significant increase in accuracy, speed of both inspection and data processing, and reliability but at lower cost such that NDE can catch up with the advancements in manufacturing, advanced materials (such as composites and powder metallurgy), infrastructure and other relevant technologies [4][5][6]. In addition, the applications of robotics and automation in NDE have been increased significantly to reduce inspection time, reduce human error, improve probability of detection (POD) and facilitate the interpretation of NDE results [4][7][8].
NDE techniques require high level of intelligence and discernment in performing the experiments and interpreting the results. Artificial Intelligence (AI) which is the intelligence demonstrated by machines to do tasks is a well-suited tool for NDE applications [9][10]. Major elements which drive the widespread application of AI algorithms include: broader development and availability of algorithms which some of them are open source and easy to use, availability of large sets of data for training, development and advancement of computational devices and their capabilities, and strong interest in new technologies such as smart manufacturing, autonomous devices and automated data processing [11].
2. Artificial Intelligence in NDE
The requirements due to advances in NDE technologies and NDE automation implies the crucial need for consistent and accurate evaluation of test results in terms of signals, data, images and patterns. To address these emerging needs, an intelligence knowledge-based system is desired such that it can take the NDE testing results or data, and produce an intelligent output in the form of classified and systematic interpretation of the results. AI methods are promising and capable ways for the goals of automated and efficient evaluation of NDE data and test results. AI methods and algorithms have been recently used with success in various NDE, SHM and predictive-preventive maintenance applications
[11]. Shrifan et al. discussed prospect of using AI for microwave NDE
[12]. According to Shrifan, AI techniques combined with signal processing techniques are highly possible to enhance the efficiency and resolution of microwave NDE and have tremendous potential and viability for evaluating structures quality. Another main reason which makes AI a perfect tool for NDE and specifically automated NDE is that considering the large amount of complex signals and data from the NDE inspection, nobody needs to really study the details of the physics or manufacturing process to understand what the correct process parameters and the quality of the product are
[13]. Instead, AI algorithms aim to identify, by looking at training and/or test data, if the process or the part has passed the quality criteria. This is particularly useful for the operation and operators. However, development of AI algorithms in NDE requires the involvement of expert knowledge in each and every step in a systematic approach such as the flowchart shown in
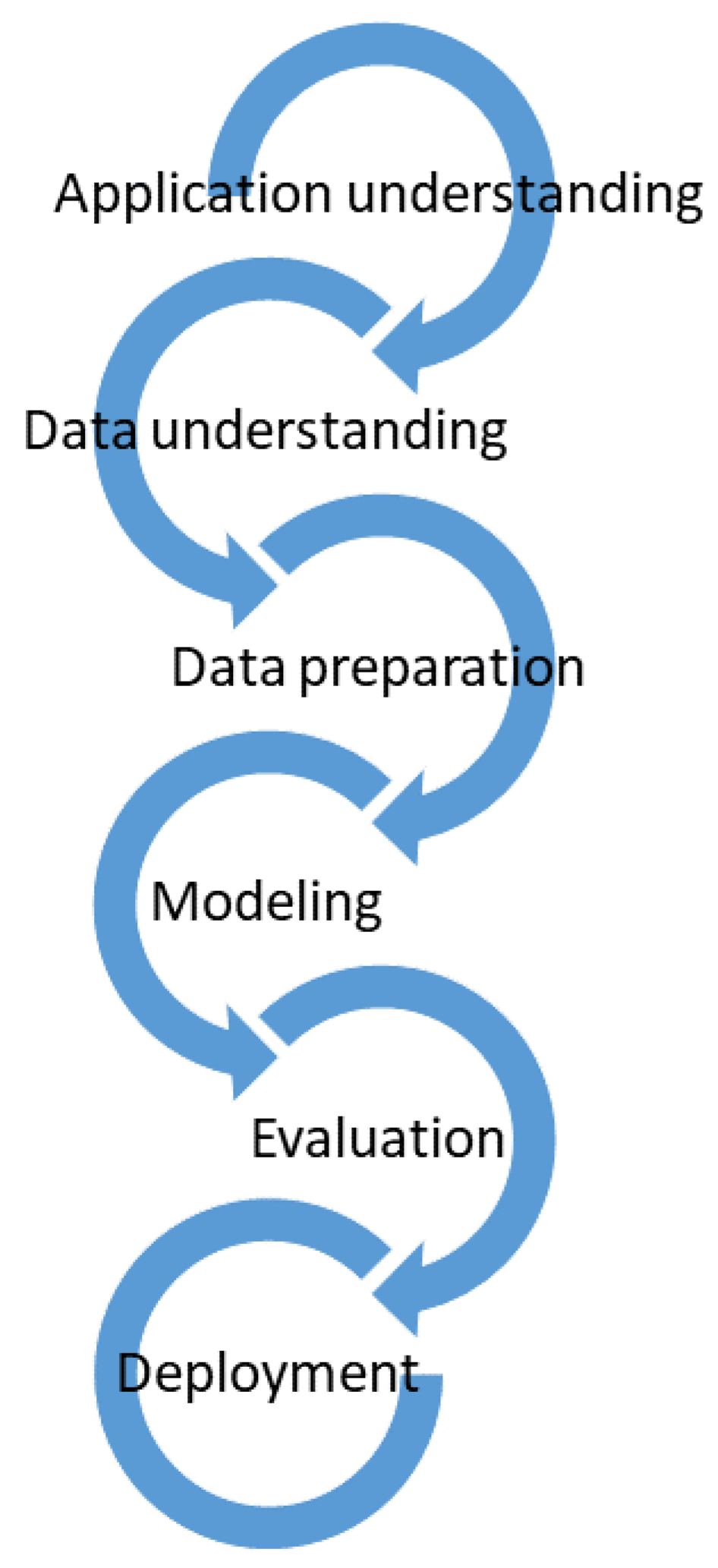
Figure 1.
Figure 1. Process model for application of AI in NDE.
2.1. Machine Learning
Machine learning (ML) is a subsection of the broad field of AI. This field aims to mimic the learning and recognition abilities of the human brain as well as the ability of self-optimization. The first person to formulate and use the term “Machine Learning” was the computer gaming and artificial intelligence pioneer, Arthur Samuel in 1959. He established that machine learning is an algorithm that is able to capture associations and learn patterns from data without enforcing specific and explicit code instructions
[14]. In other words, without prior information on how to recognize latent relationships in the data. This methodology is highly used when met with high-dimensional datasets given its use of statistics and large training datasets. NDE has a special interest in ML algorithms because of their ability to automate tasks, in this case, the structural health monitoring and condition assessment of materials. Statistical ML techniques can be used for prediction of defect’s characteristics based on known data set of defects due to their capabilities in estimating unknown values based on training data set
[15].
The desire to use ML algorithms in NDE stems from the need to have a precise prediction method to detect defects in materials and structures. With this in mind, the defect analysis and detection systems have to keep up with the increased industrial production of materials. Additionally, these systems should be as precise as possible and with minimum margin of error, including human error. The more data used to train the algorithms, the better it gets at predicting and classifying NDE data.
2.2. Unsupervised Learning
Unsupervised learning refers to the process of feeding unlabeled and unclassified data into an ML algorithm to extract patterns. The algorithm is expected to learn these patterns and underlying relationships to properly detect similarities and disparities of groups in the data without human intervention. Unsupervised learning algorithms are typically more difficult to train than Supervised Learning ones, clearly from their nature of minimal human interaction. For example, unsupervised learning algorithms cannot be applied to classification or regression problems. This stems from the need of an output target, which is unknown to the algorithm given it has no idea what it is looking for. The algorithm itself is merely trying to find common characteristics the data and grouping it. Using unsupervised learning algorithms is advantageous when trying to gain insight on the available data. However, the algorithms are not perfect and are prone to produce erroneous associations given that there is not target output. Unsupervised learning also partitions itself into two subsections: Clustering and Association.
2.3. Cluster Analysis
2.3.1. K-Means Algorithm
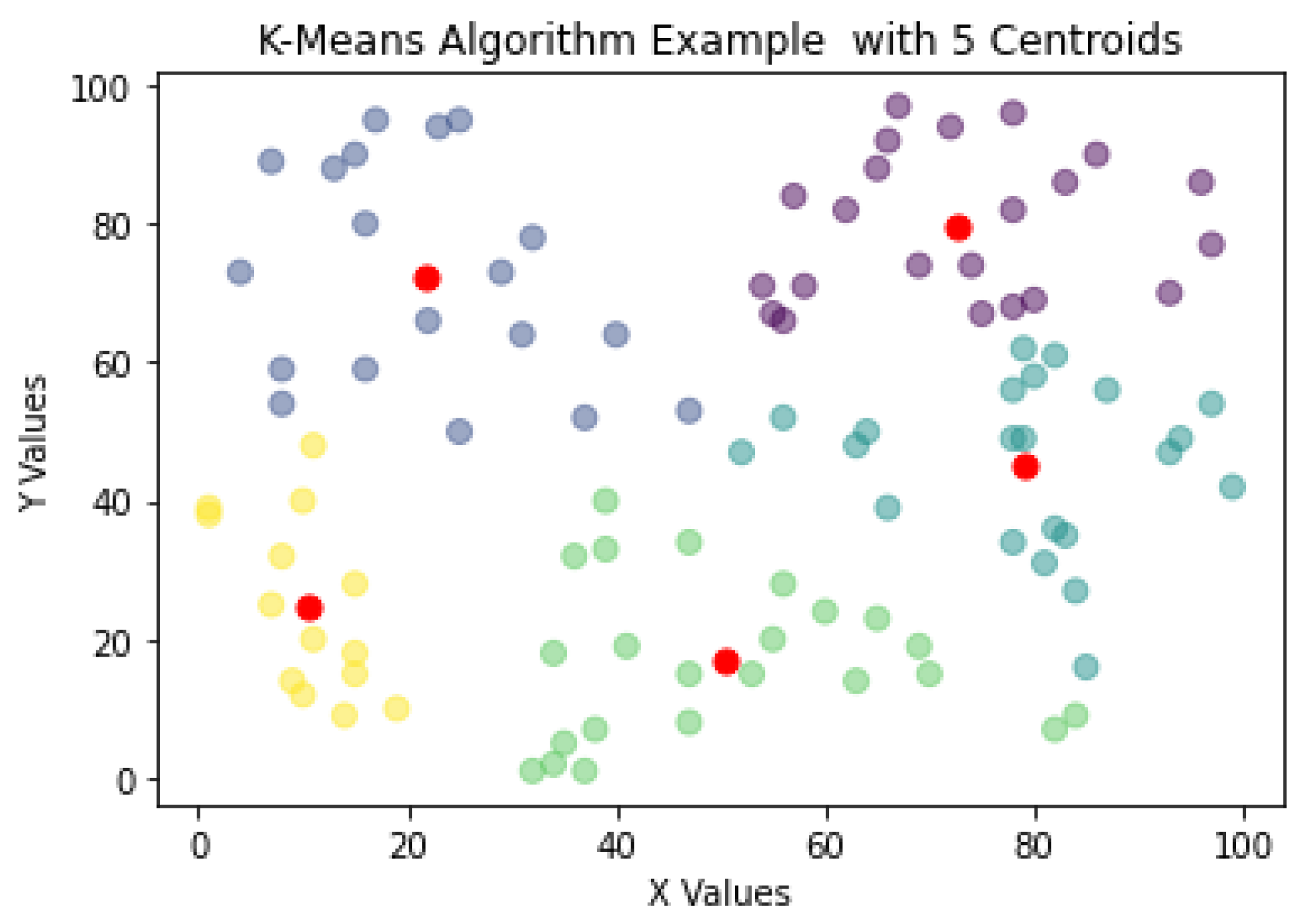
One of the most used algorithms for NDE is the K-means algorithm. When presented with an unlabeled dataset, the K-means algorithms partitions the data in k clusters defined by a centroid. A cluster is defined as a collection of data points placed together in space due to similar characteristics shared by the data points. Furthermore, the centroid is the location of the cluster’s center. It is defined that with the K-means clustering, the plane or data space will always form a Voronoi diagram. Figure 2 shows how the K-means algorithm would create clusters around a centroid, in this case k = 5 with the centroids marked as red data points.
Figure 2. K-means algorithm plot example with random data.
2.3.2. Density-Based Clustering
The Density-Based Clustering (DBC) algorithm is contingent on the idea that datasets contain dense data point regions separated by low regions of data points. In contrast to the K-means algorithm, the DBC algorithms do not need a predetermined k value. Discarding the k value allows for the DBC algorithms to find the number of clusters present in a dataset by analyzing the density distribution of data points in space. An advantage of these algorithms in comparison to the K-means is that it can discern noise and outliers in the data. The noise and outliers are presented as low regions of data point density. In other words, the K-means algorithm would pull these outliers into a cluster due to its k constraint while the DBC would inherently leave them alone. Regarding the use of the DBC algorithms in NDT, many papers predominantly use a branch of the DBC which is the Density-Based Spatial Clustering Applications with Noise (DBSCAN). The DBSCAN leverages a data point’s density reachability and density connectivity
[16]. The density reachability specifies the maximum distance of two data points to be considered neighbors and part of the same cluster. On the other hand, the density connectivity specifies the minimum number data points needed to define a cluster in a region of space. The fields of Civil and Manufacturing Engineering predominantly use the DBSCAN algorithm to monitor the structural health of materials. The study in
[17] explores Ultrasonic Testing (UT) to inspect the pressures of tubes in the of the Ontario Hydro. Canada’s system, Channel Inspection and Gauging Apparatus for Reactors (CIGAR) uses UT to obtain volumetric images of the pipelines and assess defective regions in them. The statistical properties of the ultrasonic signals are mapped as data points in space, from which the DBSCAN can conduct its analysis
[18]. An example of the DBSCAN algorithm in use can be observed in
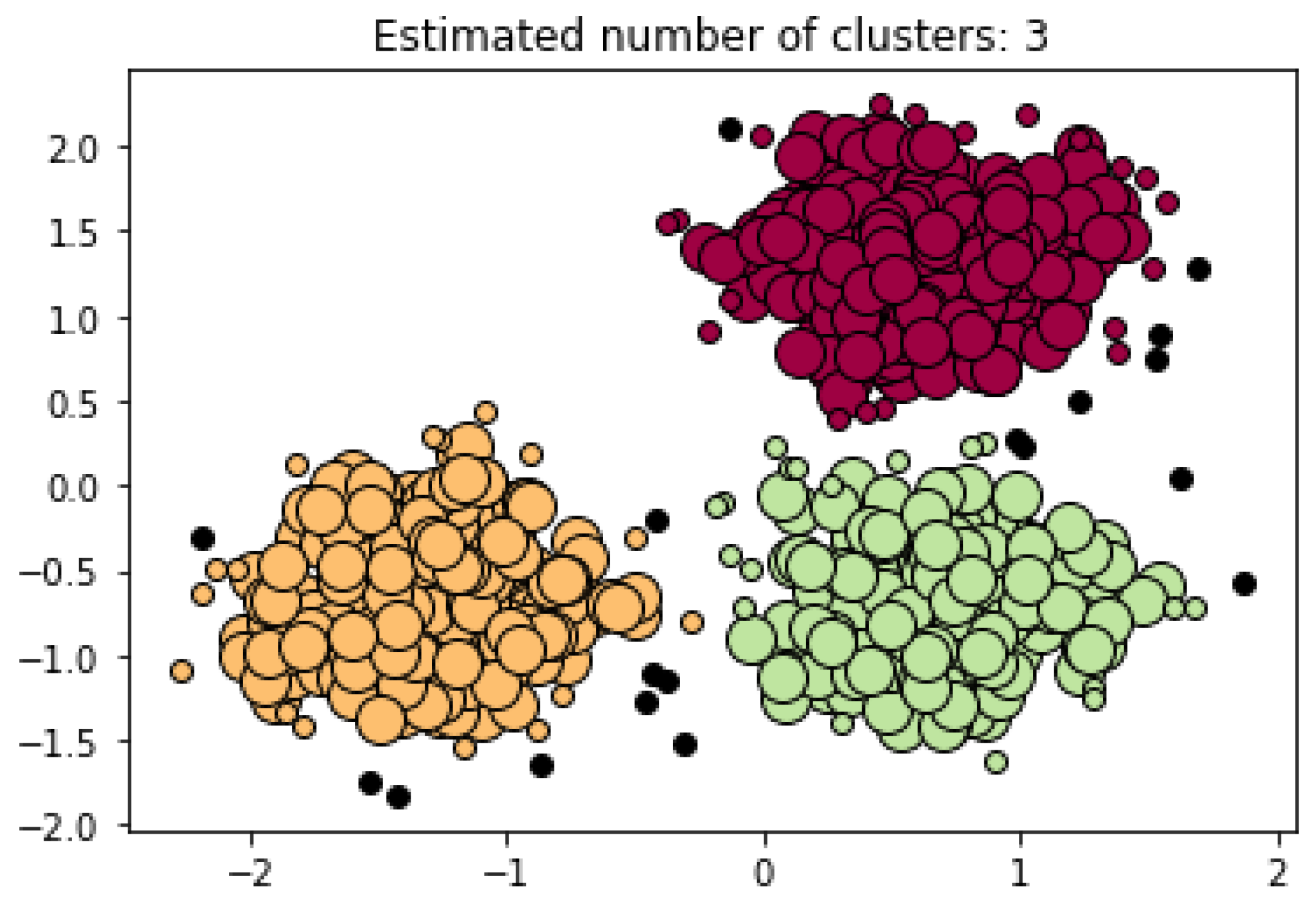
Figure 3. In this case, the algorithm constructed an analysis based on three clusters created by three dense regions encountered in the dataset. Furthermore, in this example the DBSCAN found 18 points of noise in the dataset.
Figure 3. DBSCAN Plot Example with 3 Dense Clusters (After
[19]).
2.3.3. Spectral Clustering
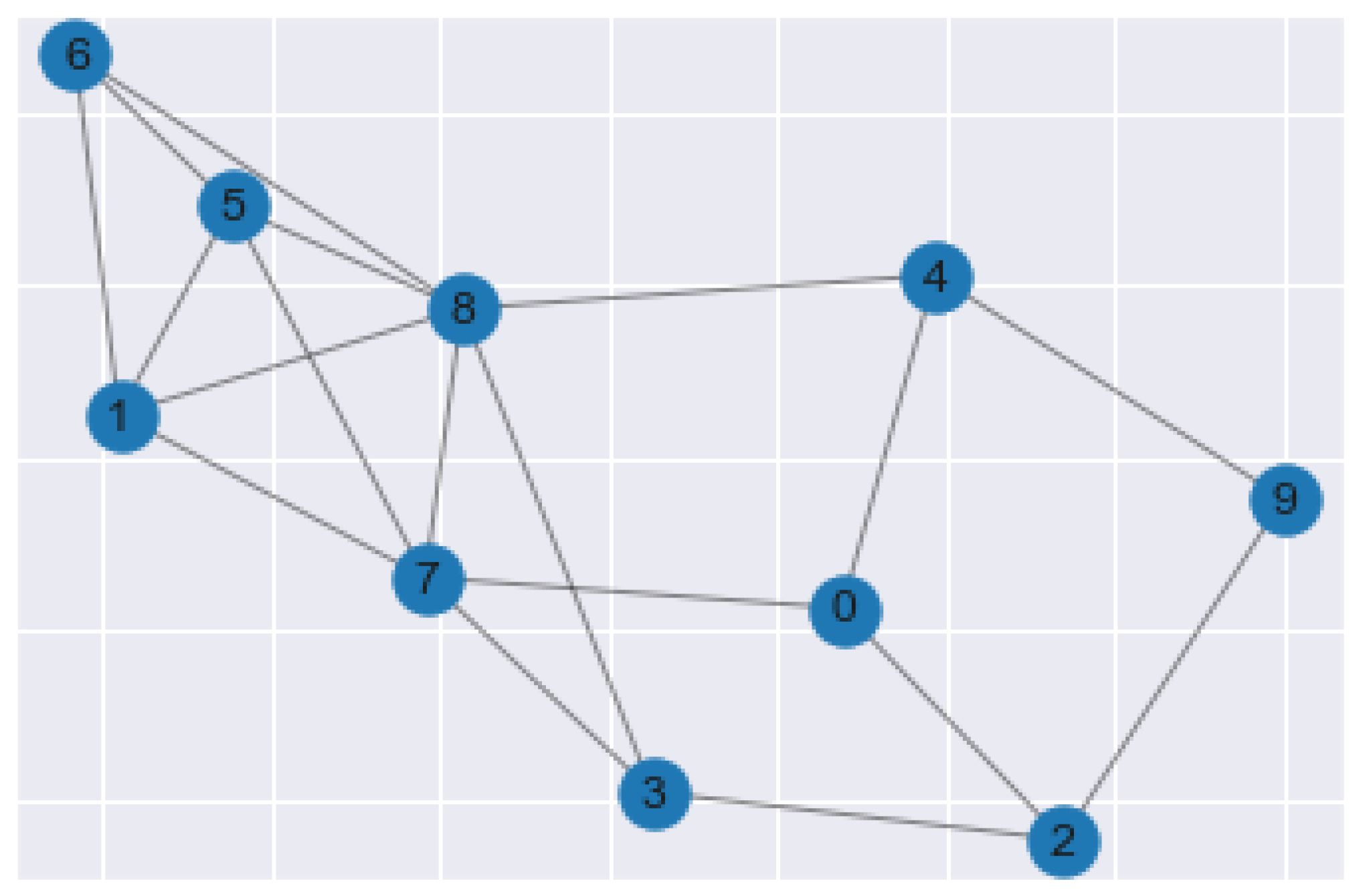
Spectral Clustering is the machine learning method in which the data points in the data set are treated as nodes of a graph. This algorithm is rooted in graph theory and is treated as a graph partitioning problem. The end goal of spectral clustering is to cluster data that is connected but not necessarily in round cluster shapes, as seen in Figure 4. The nodes, or data points, in a data set are projected into a low-dimensional space where connectivity clusters can be achieved. The first step of conducting this algorithm is to compute a similarity graph. The similarity graph is analogous to cluster formation.
Figure 4. Spectral Clustering Plot Example.
2.3.4. Hierarchical Clustering
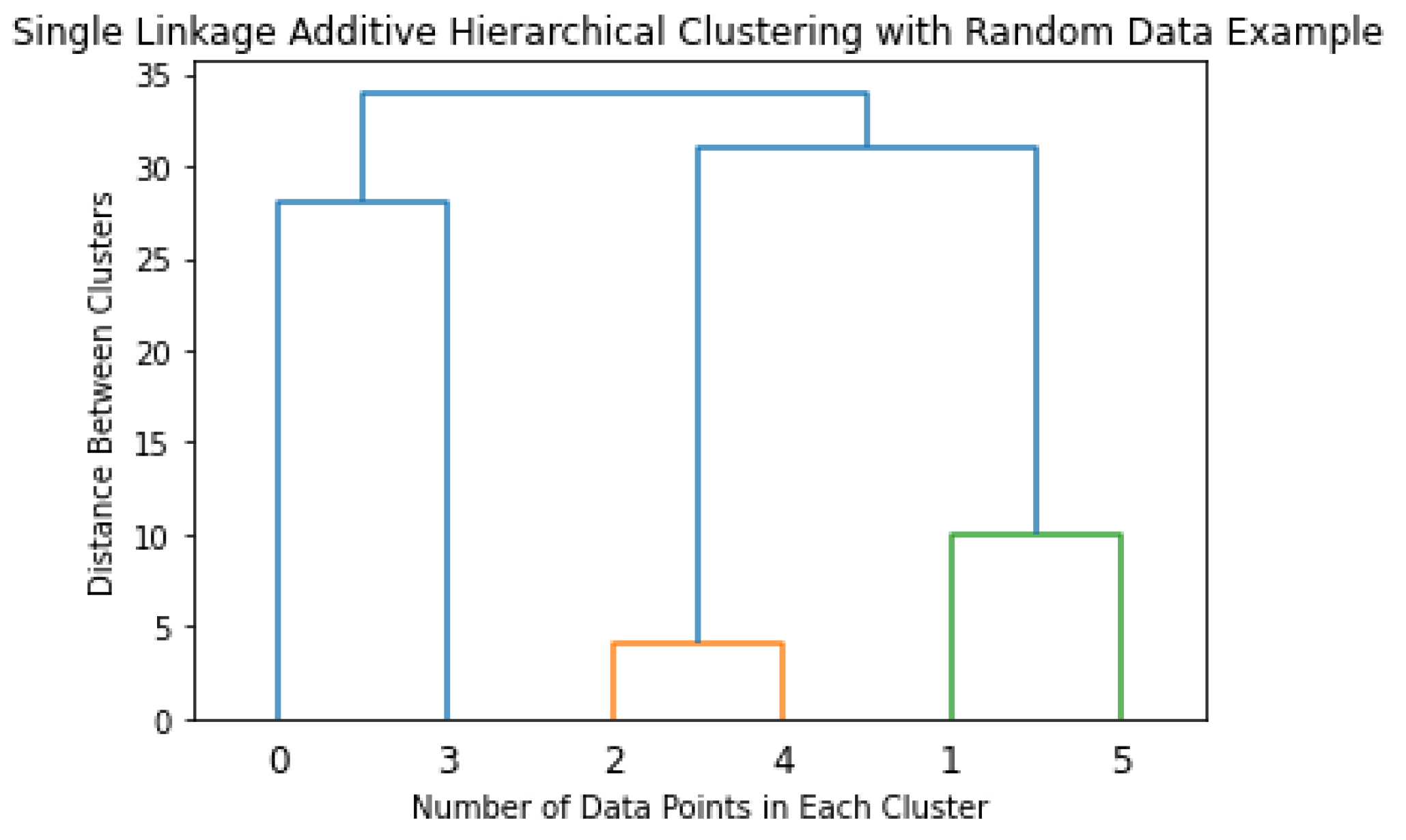
Hierarchical clustering is an analytical algorithm used to compute clusters of data points. This type of clustering algorithm is subdivided into two different techniques, agglomerative and divisive. The agglomerative technique imposes that each data point starts as its cluster. Furthermore, the algorithm computes a proximity matrix from each point in space. In every iteration, the algorithm merges the two closest pairs of clusters and a new proximity matrix is computed.
There exist four forms of cluster linkage to conduct additive hierarchical clustering. Complete linkage computes the similarity of the furthest pairs in the dataset; however, it is prone to errors if there exist outliers. Single linkage works similarly, but it conducts this comparison between the closest data points. In the same fashion as the previous linkage processes, centroid linkage compares the centroids of each cluster and merges them given found similarities. The last linkage method, group average, finds similarities between the overall clusters and merges them. The linkage process is repeated until a predetermined number of clusters is achieved. The optimal way of describing the additive hierarchical clustering is by creating a dendrogram, as shown in Figure 5.
Figure 5. Single Linkage Additive Hierarchical Clustering with Random Data.
2.4. Association Analysis
Association analysis is an unsupervised learning method that seeks to find underlying patterns and relationships to describe the data at hand. Association analysis is mainly used to find frequent patterns between different variables in a data set. These patterns can be found based on frequency of complimentary occurrences among variables. The descriptive nature of the association analysis algorithms allows for a better understanding of the data and ties into the area of feature engineering and extraction. Association analysis is frequently implemented with common statistical methods. Common association analysis deals with the occurrence of one variable with another. The process seeks to find frequent patterns that can help explain the data.
Due to its characteristics, association analysis is a useful technique for discovering interesting relationships hidden in large data sets. Such situations is common in recent methods of continuous monitoring NDE and SHM. Through recent advancements in sensors and sensing technologies such as distributed fiber optic sensors and multi-point laser vibrometers for SHM, or even acoustic emission sensors and data acquisition units for manufacturing process monitoring
[20], it is possible to acquire large data sets which often contain uncovered relationships in features of the data, useful for structural integrity assessment. Engineers, designers and technicians can use this type of relations and conclusions to establish enhanced predictive and preventive maintenance plans.
2.5. Supervised Learning
Supervised learning is a branch of ML in which the user feeds labeled and classified data to the machine learning algorithms. This data-input methodology helps the algorithm to detect the relationships and patterns faster. Supervised learning is often divided into different categories based on the desired output. The first category in supervised learning is the algorithms with a discrete classification end goal. These algorithms are trained to differentiate among different classification categories from which they were previously trained. The input is analyzed by the supervised learning algorithm and placed in a category that the algorithm finds more suitable given the information extracted from the input (show a feature map and classification examples, very general). The second category of supervised learning is made of algorithms that produce a continuous output (e.g., Regression Analysis)
[15].
2.5.1. Support Vector Machine
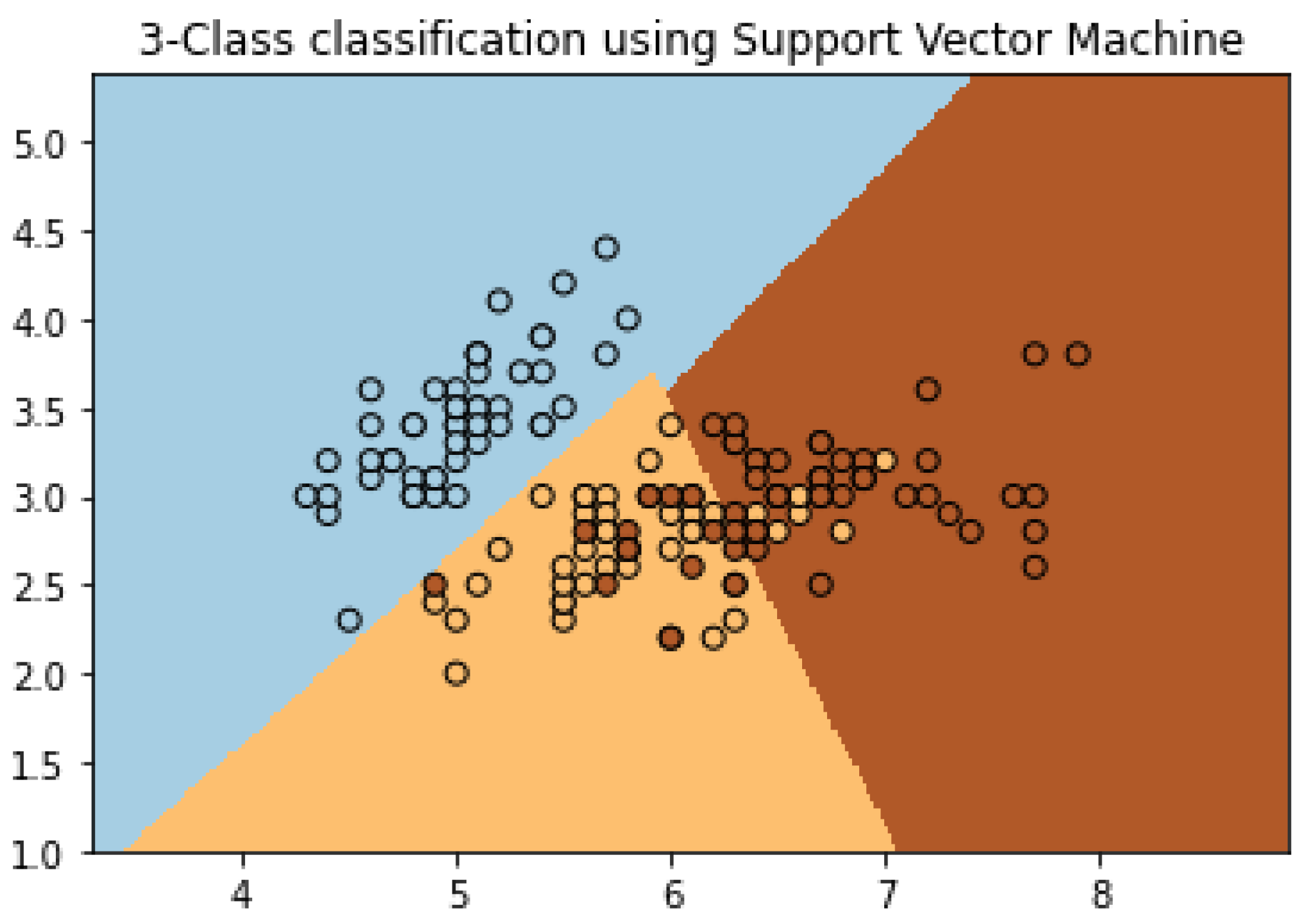
One of the techniques in non-destructive testing that classifies and at the same time obtains a regression from the input data is the Support Vector Machine (SVM) algorithm. This algorithm creates support vector representations from fed labeled examples to properly classify said labels. The support vectors for each class are the most difficult points to classify since they are the closest to the boundary that separates those classes. The separating hyperplanes serve as the plane that separates data into different classes and is highly effective in multidimensional data classification (e.g., two or more classes). One can observe the hyperplane as a line that separates the data in a two-dimensional plane into three different classes, as seen in Figure 6. This line can then be expanded into higher dimensionalities, e.g., a hyperplane, when more classes are introduced in the data.
Figure 6. Support Vector Machine Example (After
[19]).
2.5.2. K-Nearest Neighbor
The K-Nearest Neighbor (KNN) algorithm relies on the idea that similar data points in a data set are going to be close to each other in space, in other words; neighbors. KNN falls under supervised learning algorithms, however it can perform both regression and classification problems. The KNN algorithm assumes that point proximity represents class similarity. The number of points necessary to determine the output classification label of a data point is established by the hyperparameter k, which is not to be confused with the k from clustering analysis techniques. The closest k points to the query input point have their own label and this will help determine the output label of the query point.
The measuring technique used to measure the distance between two points defines if KNN is being used for categorical or quantitative data. To measure the distance between two categorical values, the algorithm implements the Hamming distance measurement. On the other hand, KNN implements three possible distance functions for quantitative measurement. The Euclidean function is one of the most common ones, followed but the Manhattan function and then the Minkowski function.
2.5.3. Neural Networks
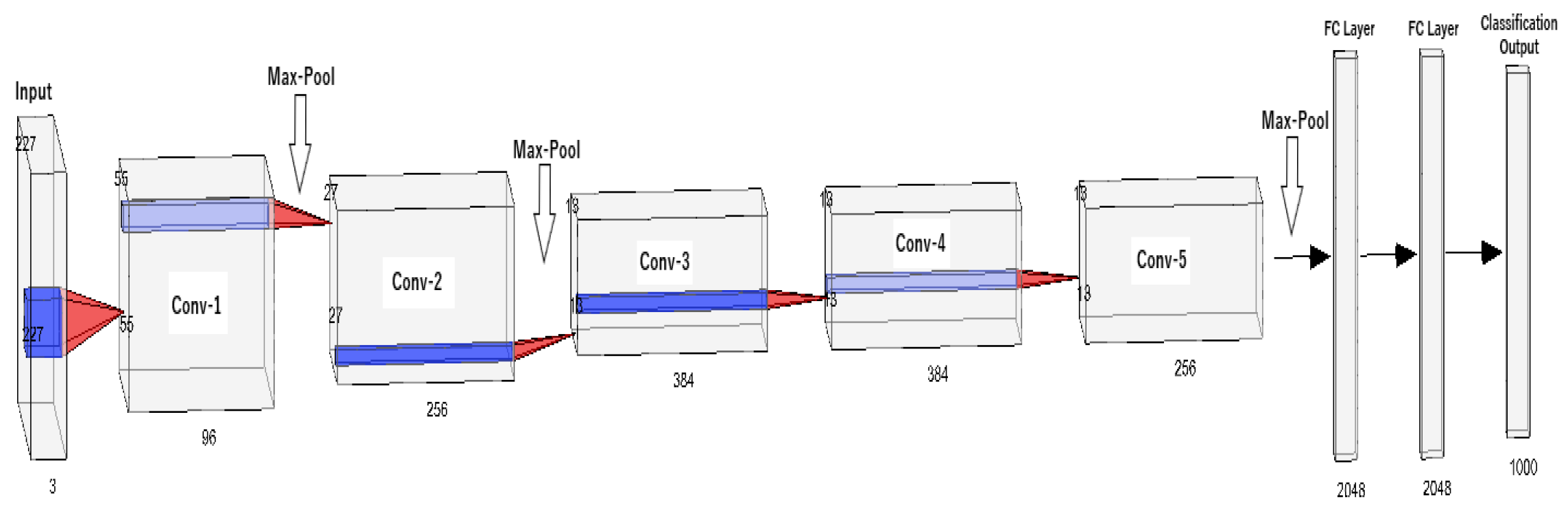
Neural networks are machine learning algorithms inspired by the workings of the biological neurons of the human brain. This approach is also referred as “deep learning”. These algorithms are built upon stacking node layers made up of an input layer, output layer, and hidden layers. All individual nodes in a node layer have a specific value that activates them. Once a node is activated, it will send information to next node layer. The connections between the nodes are represented by a number, also known as the weight. The weight also holds influence on the nodes, meaning the higher the weight the more leverage it has on the network. In many cases, the neural network has a fully connected design which allows feed forward and feedback information. With this structure, the neural network can deduct information and improve itself based on previous decisions. One of the pillar neural networks in Artificial Intelligence is the LeNet 5 network created by Yann LeCun, et al.
[21]. This network was developed to recognize handwritten digits and has been a base for many new and emerging networks in the field. Stemming from the same branch as LeNet 5, the famous Convolutional Neural Networks (CNN) have emerged. The widely popular AlexNet
[22], a CNN variation, has been implemented across several fields to understand nonlinear data for classification.
Figure 7 showcases the architectural design of AlexNet.
Figure 7. AlexNet Architecture.
2.6. Feature Extraction
A common technique in data analysis is feature extraction, which allows for dimensionality reduction of a data set. Moreover, a feature is an individual measurable property in a data set, such as length, width, height, etc. Data sets nowadays contain more and more features that intertwine with each other. However, when these data sets are fed into a machine-learning algorithm to train it, the algorithm will show overfitting when tested with unseen data before. With this in consideration, feature extraction aims to reduce the number of features or dimensions of a dataset by creating new features from existing ones. The new features are combined to create representations of the old features, which can now be discarded. This process also allows for the removal of data redundancy. Many machine learning algorithms implement feature extraction to reduce the dimensionality of their datasets. These algorithms include Random Forests, Artificial Neural Networks, and Autoencoders.
2.7. Machine Vision
The field of computer vision has experienced a boom in the past decade, with examples such as Facial & Object Recognition and Text Recognition. Moreover, this field is now joining Nondestructive Evaluation to automate the industrial and manufacturing processes. The use of computer vision algorithms helps the industry maintain and increase manufacturing quality. The analysis of information coming from images provides an easier and faster way to detect material flaws and avoid human error. Inspection systems using computer vision are designed to detect flaws with high precision and at faster rates than what human inspectors can. Furthermore, the algorithms profit from having scalability, meaning they can be used for large or small input datasets. Computer vision models also have the advantage of finding and leveraging feature importance to accurately detect flaws. Testing techniques that use these types of computer vision algorithms include X-rays, Thermal Images, Light Cameras, and Fluorescent Penetration Inspection to name a few. Image processing has allowed the manufacturing industry to further enhance their quality processes and automate the industry. In
[23], 3D machine vision methods for pose (spatial position and orientation) estimation is investigated where an RGB-D camera observes the asset under inspection along with the probe; 3D machine vision processes the camera data to actively track the probe in relation to the asset, which further allows one to augment each NDE dataset with its inspection location.
In addition to NDE applications
[24][25], Machine vision has also paved its way in SHM applications
[26][27]. 3D visualization models can be generated to simulate the defect development in structure and infrastructures using machine vision techniques. In
[28], spalling distress defects in subway networks were detected and quantified using image data processing and machine vision. Spalling is a significant surface defect that can compromise the integrity and durability of concrete structures. The core idea behind this technique was to create a complementary scheme of image preprocessing which is effective in isolating the object of interest from the background of the image.
This entry is adapted from the peer-reviewed paper 10.3390/s22114055