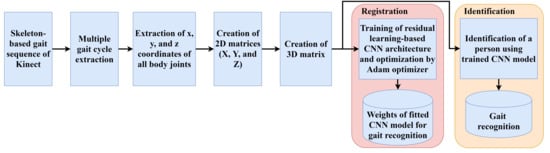
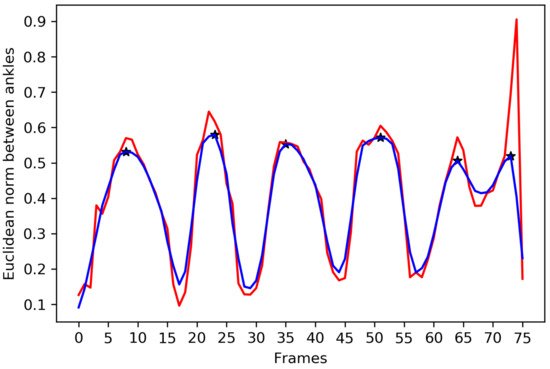
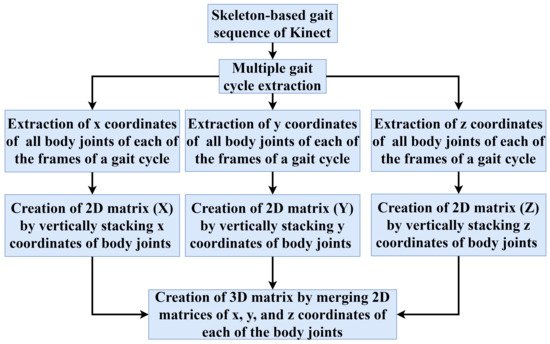
3.3. Proposed Convolutional Neural Network
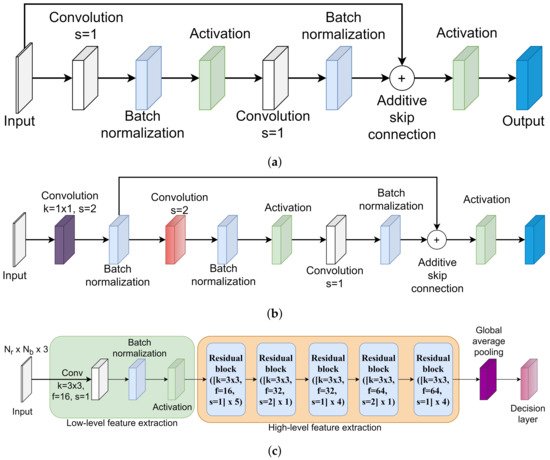
In this paper, a unique residual learning-based convolutional neural network is proposed for the Kinect-based gait recognition. The architecture of the proposed CNN model is shown in Figure 4. The purpose of designing the residual learning-based CNN architecture is to extract hierarchical distinctive features taking the variable dimensions of the 3D matrices as input while avoiding the degradation problem. A 3D matrix comprised of x, y, and z coordinates of each of the body joints over a gait cycle is the input for the proposed CNN architecture. If there are total N gait cycles extracted from all persons’ skeleton-based gait sequences, the input shape of the proposed CNN model becomes N × Nf × Nb × 3 where Nf is not a fixed value. The identification labels of each of the persons are converted into the one-hot encoded format. If there are total P persons’ gait sequences available in a dataset, the shape of the one-hot encoded identification label is N × P. Both the 3D matrix and one-hot encoded identification label are fed into the first layer of the CNN model.
Figure 4. Residual block ([kernel = K × K, filters = F, stride = S] × R) means residual blocks are stacked one after another R times and K × K kernel of F filters are used in the convolutional layer. Based on the value of S, one of the residual blocks of Figure 4a,b is selected. (a) Architecture of residual block when stride length is set to 1. (b) Architecture of residual block when stride length is set to 2. (c) Architecture of the KinectGaitNet.
The convolutional layer, batch normalization layer, and activation layer are the first three layers of the proposed CNN model. The spatial and temporal relationships among the body joints and the relationship among x, y, and z coordinates are extracted using the convolutional filters. Extracted features are required to be normalized to make faster convergence of the training with stability. Therefore, the batch normalization layer is subsequently included to transform the extracted features in linear fashion after the convolution layer. The scaled feature map is activated using the Rectified Linear Unit (ReLU) activation. The ReLU activation function is chosen for faster computation, monotonic derivative, reducing the likelihood of vanishing gradient, and faster training. The first three layers are responsible for extracting, scaling, and activating low-level features. Further layers of the KinectGaitNet extract high-level features based on low-level features using residual learning.
There are two types of residual blocks introduced in the proposed architecture in order to extract the hierarchical high-level feature map. The residual block takes the output of the previous layer, size of the kernel, number of filters, and stride length as an input. If the stride length is set to 1 in the residual block, the architecture of the residual block shown in Figure 4a is selected. On the other hand, if the stride length is set to 2 in the residual block, the architecture of the residual block shown in Figure 4b is applied. When the stride length is set to 1, the skip connection is introduced from the input matrix to the results of the batch normalization layer (see Figure 4a). To implement the skip connection, the merging layer of the addition type is used to add the original input matrix to the residual block and the output of the batch normalization layer. The merged results are fed into the ReLU activation layer. When the stride length is set to 2, a convolution operation is applied at first using the provided number of filters with 1 × 1 kernel. Next, the batch normalization layer is used to normalize the outputs. Consider the result of this batch normalization operation is represented as Bx1. The shortcut connection is added from Bx1 to the results of the batch normalization layer, according to Figure 4b, using the merging layer of addition type. The merged results are passed to the activation layer. The architectures of Figure 4a,b with skip connection are included in the KinectGaitNet to address the degradation problem, since the high-level feature extraction block is a deeper network.
Traditionally, the result of the final convolutional layer is flattened into the fully connected layer before the decision layer. However, a fully connected layer can not be added after the last residual block because the extracted feature map is in a variable dimension. Since the variable dimension of the 3D matrix is the input of the KinectGaitNet, the dimension of the extracted feature map after the residual block is not consistent for every gait cycle. The feature map needs to be accumulated in such a way that a consistent feature map can be generated and the accumulation process is learnable. To achieve that, we feed the output of the final residual block into a global average pooling layer [
36]. The global average pooling layer provides the ability of the KinectGaitNet to support the variable dimension of 3D matrices. It also significantly reduces the number of trainable parameters. Finally, the feature maps are transformed in such a way that the output of the global average pooling operation is closely related to the classification categories.
The softmax activation function is applied at the decision layer to classify persons’ identities in a multi-class gait recognition system. The categorical log loss objective function is optimized using the Adam optimizer to utilize the optimization gain of AdaGrad and RMSProp [
37]. Furthermore, the Adam optimizer provides the robustness while optimizing the hyperparameter with an adaptive learning rate.