Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Deep learning techniques, such as convolutional neural networks (CNNs), generative adversarial networks (GANs), and graph neural networks (GNNs) have, over the past decade, changed the accuracy of prediction in many diverse fields. In recent years, the application of deep learning techniques in computer vision tasks in pathology has demonstrated extraordinary potential in assisting clinicians, automating diagnoses, and reducing costs for patients.
- deep learning
- machine learning
- histopathology
- computational pathology
1. Classification and Feature Prediction
With the success of CNN models in various real-world computer-vision classification tasks, researchers and scientists have also trained and tested these models in case scenarios in biomedical fields, including pathology. These studies may involve training an existing CNN architecture from scratch. However, it requires more data, and the data augmentation techniques may not always be suitable for biomedical images. Alternatively, transfer learning techniques, which freeze most of the parameters from a model often pre-trained on ImageNet, have more advantages in terms of the data size requirements. For example, an InceptionV3-based ImageNet pre-trained CNN model can achieve a high level of accuracy in determining skin lesion malignancy and the possibility of melanoma [13,54].
In clinical settings, pathologists typically examine histopathology slides under microscopes to provide diagnosis or other clinical information. Due to the development of digital pathology equipment, digitizing histopathology slides is cheaper and more accessible. As a result, more and more deidentified digital histopathology slide images have become available in many databases. These images, often with extremely large dimensions, are saved in special image file formats (e.g., .svs or .scn), which is a tuple of the same image with different resolutions [55]. Thus, in order to fit these digital histopathology images into CNN architectures, people usually develop their own customized pipelines with commonly used techniques, such as tiling the whole slide images (WSI) or sampling regions of interest (ROIs) (Figure 3) [56]. In the past few years, classification CNN models trained on histopathology images have shown phenomenally high performance and promising clinical potential in predicting both morphological features and molecular features. The visualization techniques also reveal results that often match pathologists’ expectations and many models are generalizable to independent real-world clinical images. For example, Inception and InceptionResNet architectural models demonstrate high accuracy and other statistical metrics in predicting subtypes and key biomarker mutations, such as STK11 and EGFR, in non-small-cell lung cancer histopathology slides [14,57,58]. With the integration of other critical clinical variables and images, immune response, G-CIMP, and telomere length can be predicted in glioblastoma patients [59]. BRAF mutation, a well-known biomarker in malignant melanoma, can also be accurately predicted with a CNN-based model [60]. Other molecular and genomic features, such as microsatellite instability (MSI), can be predicted from histopathology slides with a reasonable accuracy as well [15]. The critical gene expression level could also be inferred by applying these CNN classification models to WSI [61]. Some contemporary models also show successful classification results in the histopathology images of multiple tissue types [62,63]. These successful cases indicate that CNNs represent a suitable approach to study the correlation between molecular features and morphological features in histopathology slides, some of which may be undetectable or often ignored by human pathologists.
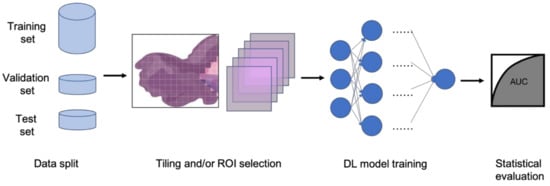
Figure 3. Typical classification model pipeline for histopathology images.
However, histopathology images are quite different from the images in the ImageNet because of their extremely large sizes, higher resolution, and sparser useful feature distributions [11,55,64]. Deep learning architectures that could take advantage of these characteristics are very likely to achieve better results, unveiling more interesting hidden features in histopathology image classification tasks. For instance, a multi-resolution CNN model, which takes advantage of the data structure of .svs and .scn image files, achieves higher performance in classifying endometrial cancer molecular features than its single resolution counterparts [65]. Weakly supervised techniques, such as multiple instance learning, also demonstrate decent performance in classification tasks of histopathology images, and have gained popularity in recent years [64,66,67]. The innovative idea of bringing GNN models into solving histopathology classification problems develops greater capacity in understanding the subtle relationships between features of different tissue structures and at different locations on giant digital histopathology slides [68,69].
2. Segmentation
In addition to classification tasks, CNN models are also capable of segmenting cells or tissue in histopathology slides [9,55]. The segmented cells or tissue could then be used to train classification models for different prediction tasks, including the recurrence of non-small-cell lung cancer [70] and endometrial tissue types [71]. A popular segmentation CNN architecture used in the biomedical field is U-net, which has a similar structure to an autoencoder [72]. A 3D version of U-net, which has 3D convolutional layers instead of 2D convolutional layers, is capable of segmenting volumetric images [22]. Modified U-net architectures, such as USE-net [73], Focus U-net [74], and U-net with attention gate [75], have achieved even better performance in various biomedical image segmentation tasks than vanilla U-net. Other autoencoder-based methods have also achieved promising results in segmentation tasks of histopathology images, such as highlighting tumor regions in liver cancer WSI [76]. Well-trained style transfer models are also viable options for segmentation tasks [48]. With the introduction of GAN, using conditional-GAN or cycle-GAN models and in combination with CNN models for segmentation problems is also shown to be viable, with less stringent training data requirements [46,53,77]. Unlike most classification models, the segmentation models can be more adaptive to different types of tissues due to the similarities of the stained features and textures of the histopathology slides [78]. Additionally, the evaluation metrics of these classification models can be drastically different from those of the classification models. The segmentation labels are also usually images; therefore, it is not easy to determine a binary prediction or even a prediction score at the per-image level. Hence, typical statistical metrics, such as AUROC or precision and recall, are often not capable of fairly evaluating segmentation tasks. Pixel-level metrics, such as intersection over the union (IoU), also pose weaknesses because it cannot objectively give relative importance to pixels of different regions. Object-level metrics can be an optimal alternative, but the requirement of identifying all objects on the label images prohibits its adoption in real-world model evaluation. Therefore, researchers often use customized evaluation metrics with a combination of customized pixel weights, dice loss, and IoU with specific thresholds [79,80].
This entry is adapted from the peer-reviewed paper 10.3390/biomedinformatics2010010
This entry is offline, you can click here to edit this entry!