Alzheimer’s disease (AD) is one of the most devastating brain diseases in the world, especially in the more advanced age groups. It is a progressive neurological disease that results in irreversible loss of neurons, particularly in the cortex and hippocampus, which leads to characteristic memory loss and behavioral changes in humans. Communicative difficulties (speech and language) constitute one of the groups of symptoms that most accompany dementia and, therefore, should be recognized as a central study instrument. This recognition aims to provide earlier diagnosis, resulting in greater effectiveness in delaying the disease evolution. Speech analysis, in general, represents an important source of information encompassing the phonetic, phonological, lexical-semantic, morphosyntactic, and pragmatic levels of language organization [72]. The first signs of cognitive decline are quite present in the discourse of neurodegenerative patients so that diagnosis via speech analysis of these patients is a viable and effective method, which may even lead to an earlier and more accurate diagnosis.
- Alzheimer’s disease (AD)
- speech
- classification
1. Speech and Language Impairments in Alzheimer’s Disease
| Function | Early Stages | Moderate to Severe Stages |
|---|---|---|
| Spontaneous Speech | Fluent, grammatical | Non-fluent, echolalic |
| Paraphrastic errors | Semantics | Semantic and phonetic |
| Repetition | Intact | Very affected |
| Naming objects | Slightly affected | Very affected |
| Understanding the words | Intact | Very affected |
| Syntactical understanding | Intact | Very affected |
| Reading | Intact | Very affected |
| Writing | ± |
| Intact | Very affected | |
| Semantic knowledge of words and objects | Difficulties with less used words and objects. | Very affected |
2. Speech- and Language-Based Classification of Alzheimer’s Disease
2.1. Machine Learning Pipeline
-
Data Preparation: In this step the extraction, optimization and normalization of features occurs. This consists in the selection of the most significant features (by removal of the non-dominant features) and in the transformation of ranges to similar limits, which will reduce training time and the complexity of the classification models. Metadata are “the data of the data”, more specifically, structured, and organized information on a given object (in this case voice recordings) that allow certain characteristics of it to be known. This metadata together with the results of the pre-processing of the recordings makes the final database. Incorrect or poor-quality data (e.g., outliers, wrong labels, noise, …), if not properly cared for, will lead to under optimized models and to unsatisfactory results. If data is not enough, for example when deep learning algorithms are used, then data augmentation techniques can be useful.
-
Training and Validation: The supporting database is divided into subsets, usually 70–90% for training and 30–10% for testing. The subsets can be randomly generated several times and the results can be averaged for additional confidence in the results, a procedure that is designated by cross-validation. The data model is trained, i.e., the involved parameters are adjusted, by one or many optimizers, and the performance is calculated using the test subset. This step allows categorizing and organizing the data to promote better analysis [30]. When data is not enough, then transfer learning approaches can be used.
-
Optimization: After model evaluation, it is possible to conclude on the parameters that need to be improved, as well as to proceed in a more effective way to the selection of the most interesting and relevant features, so that a new extraction and consequently a new process (iteration) of Training and Validation can be performed.
-
Run-Time: Having concluded the previous points, the system is ready to be deployed and to classify new unseen inputs. More specifically, from the recording of a patient’s voice, to classify it as possible healthy or possible Alzheimer’s patient.
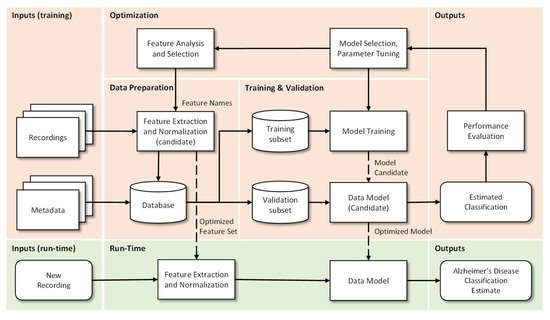
2.2. Speech and Language Resources
Table 2 presents the main databases that are referred in the scientific literature, accompanied by a summary of their characteristics. These resources are crucial for supporting the development of new systems, in particular when deep learning approaches are used. The use of similar databases in different studies, by different researchers, also provides a common ground for evaluation and performance comparison.
| Language | Database Name | Task | Population | Availability | Refs. | ||
|---|---|---|---|---|---|---|---|
| HC M/F |
MCI M/F |
AD M/F |
|||||
| English | DementiaBank (TalkBank) |
DF | 99 | - | 169 | Upon request | [32] |
| English | Pitt Corpus | PD | 75/142 | 27/16 | 87/170 | Upon request | [33] |
| English | WRAP | PD | 59/141 | 28/36 | - | Upon request | [34] |
| English | - | PD | 112 | - | 98 | Undefined | [35] |
| French | - | Mixed | 6/9 | 11/12 | 13/13 | Undefined | [36] |
| French | - | VF, PD, SS Counting |
- | 19/25 | 12/15 | Undefined | [37] |
| French | - | VF, Semantics | 5/19 | 23/24 | 8/16 | Undefined | [38] |
| French | - | Reading | 16 | 16 | 16 | Undefined | [39] |
| Greek | - | PD | 16/14 | - | 13/17 | Undefined | [40] |
| Hungarian | BEA | SS | 13/23 | 16/32 | - | Upon request | [13] [41] |
| 25 | 25 | 25 | |||||
| Italian | - | Mixture | 48 | 48 | - | Undefined | [42] |
| Mandarin | Lu Corpus | PD/SS | 4/6 | - | 6/4 | Upon request | [43] |
| Mandarin | - | PD/SS | 24 | 20 | 20 | Undefined | [44] |
| Portuguese | Cinderella | SS | 20 | 20 | 20 | Undefined | [45] |
| Spanish | AZTITXIKI (AZTIAHO) |
SS | 5 | - | 5 | Undefined | [46] |
| Spanish | AZTIAHORE (AZTIAHO) |
SS | 11/9 | - | 8/12 | Undefined | [47,48] |
| Spanish | PGA-OREKA | VF | 26/36 | 17/21 | - | Upon request | [47] |
| Mini-PGA | PD | 4/8 | - | 1/5 | |||
| Spanish | - | Reading | 30/68 | - | 14/33 | Undefined | [49] |
| Swedish | Gothenburg | PD | 13/23 | 15/16 | - | Undefined | [50] |
| Swedish | - | Mixed | 12/14 | 8/21 | - | Upon request | [51] |
| Swedish | - | Reading | 11/19 | 12/13 | - | Undefined | [52] |
| Turkish | - | SS/Interview | 31/20 | - | 18/10 | Undefined | [53] |
| Turkish | - | SS/Interview | 12/15 | 17/10 | Undefined | [54] | |
| Turkish | - | SS | 12/15 | - | 17/10 | Undefined | [55] |
3.3. Language and Speech Features
| Feature Type | Feature Name |
|---|---|
| Occurrence frequency | Words (3); Verbs (2); Nouns, Predicates (1); Coordinate and Subordinate Phrases (2); Reduced phrases (2); Incomplete Phrases/Ideas (3); Filling words (1); Unique words (2); Revisions/Repetitions (1); Word Replacement (2) |
| Time/Duration | Total speech (3); Speech Rate (3); Speech time (2); Average of syllables (2); Pauses (4); Maximum pause (2). |
| Parts of speech ratio | Nouns/Verbs (2); Pronouns/Substantives (1); Determinants/Substantives (2); Type/Token (2); Silence/Speaking (4); Hesitation/Speaking (3). |
| Semantic density | The density of the idea (1); Efficiency of the idea (1); Density of information (2); Density of the sentences (1). |
| POS (Parts-of-Speech) | Text tags (4). |
| Complexity | The entropy of words (1); Honore’s Statistics (1). |
| Lexical Variation | Variation: nominal (2), adjective (1), modifier (1), adverb (1), verbal (1), word (1); Brunet’s Index (1). |
| Feature Type | Feature Name |
|---|---|
| Hesitations | Filled Pauses (2); Silent Pauses (4); Long Pauses (3); Short Pauses (3); Voice Breaks (5). |
| Voice Segments | Period (4); Average duration (4); Accentuation (2). |
| Frequency | Fundamental frequency (8); Short term energy (7); Spectral centroid (1); Autocorrelation (2); Variation of voice frequencies (2). |
| Regularity | Jitter (11); Shimmer (11); Intensity (6); Square Energy Operator (1); Teager-Kaiser Energy Operator (1); Root Mean Square Amplitude (2). |
| Noise | Harmonic-Noise ratio (3); Noise-Harmonic ratio (2). |
| Phonetics | Articulation dynamics (1); the rate of articulation (1); Pause rate (5). |
| Intensity | From the voice segments (1); From the pause segments (1); |
| Timbre | Formant’s Structure (6); Formant’s Frequency (8). |
3.4. Classification Models
| Model | Characterization | References | |
|---|---|---|---|
| NB | Consists of a network, composed of a main node with other associated descending nodes that follow Bayes’ theorem [65]. | [13,35,40,53] | |
| SVM | Consists of building the hyperplane with maximum margin capable of optimally separating two classes of a data set [65]. | [13,37,38,39,40,41,50,51,52,53,54,55,61,66] | |
| RF | Relies on the creation of a large number of uncorrelated decision trees based on the average random selection of predictor variables [67]. | [13,61] | |
| DT | Consists of building a decision tree where each node in the tree specifies a test on an attribute, each branch descending from that node corresponds to one of the possible values for that attribute, and each leaf represents class labels associated with the instance. The instances of the training set are classified following the path from the root to a leaf, according to the result of the tests along the path [68]. | [39,53,54,55] | |
| KNN | Based on the memory principle in the sense that it stores all cases and classifies new cases based on similar measures [65]. | [42,46,48] | |
| LR | A model capable of finding an equation that predicts an outcome for a binary variable from one or more response variables [69]. | [42,51] | |
| LDA | It is a discriminatory approach based on the differences between samples of certain groups. Unsupervised learning technique where the objective is to maximize the relationship between the variance between groups and the variance within the same group [70]. | [54,55] | |
| ANN | DNN | Naturally inspired models. Supervised learning approach based on a theory of association (pattern recognition) between cognitive elements [71]. There are many possibilities with different elements, structures, layers, etc. The larger the number of parameters then the larger the dataset must be. | [42,43,46,47,48,52,53] |
| CNN | |||
| RNN | |||
| MLP | |||
3.5. Testing and Performance Indicators
| Model | Method | Reference |
|---|---|---|
| Cross Validation | k-Fold | [40,41,43,46,47,48,52,61] |
| Leave-pair-out | [51,66] | |
| Leave-one-out | [13,38,50,53,54,] | |
| Split Evaluation | 90–10% | [52] |
| 80–20% | [42] | |
| Random Sub-Sampling | - | [37] |
3. Future Work
This entry is adapted from the peer-reviewed paper 10.3390/bioengineering9010027