The traffic composition in developing countries comprises of variety of vehicles which include cars, buses, trucks, and motorcycles. Motorcycles dominate the road with 77.5% compared to other types. Meanwhile, route recommendation such as navigation and Advanced Driver Assistance Systems (ADAS) is limited to particular vehicles only. Traffic condition prediction aims to discuss the proper method to result a better prediction analysis. Route recommendation aims to explore the existing work on how to provide the best route for users. The two domains would be the parts of our framework to result contextual route recommendations in heterogeneous traffic flow.
- route recommendation
- heterogeneous traffic flow
- traffic prediction
- knowledge growing bayes classifier
- artificial intelligence
1. Prediction of Traffic Condition
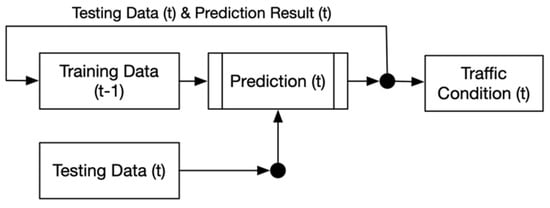
2. Route Recommendation
Attributes of Road Situation
| Data Source | Attributes | User Preferences | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Traffic Condition | Weather | Temperature | Humidity | Road Infrastructure | Travel Time | Heterogeneity | Compatibility | |||
| [27] | Electric Vehicle | × | × | × | × | ✓ | ✓ | × | × | × |
| [24] | Mobil Robots | × | × | × | × | × | ✓ | × | × | × |
| [25] | PetriNets | × | × | × | × | × | ✓ | × | × | × |
| [21] | GPS | × | × | × | × | × | ✓ | × | × | × |
| [26] | - | × | × | × | × | × | ✓ | × | × | ✓ |
| [28] | Real Data | × | × | × | × | × | × | ✓ | × | × |
| [19] | Live Traffic Data | ✓ | × | × | × | ✓ | ✓ | × | × | × |
| [36] | Vehicle’s Trajectories | × | × | × | × | ✓ | ✓ | × | × | ✓ |
| [37] | - | × | × | × | × | × | ✓ | × | × | × |
| [38] | Multi Sensors | × | ✓ | ✓ | ✓ | × | × | × | ✓ | ✓ |
| [20] | GPS Log | × | × | × | × | ✓ | × | × | × | × |
| [39] | - | × | × | × | × | ✓ | ✓ | × | × | ✓ |
| [40] | Smartphone & IoT | × | × | × | × | × | ✓ | × | × | ✓ |
| [41] | Real Weather Data | × | ✓ | ✓ | × | × | ✓ | × | ✓ | × |
| Proposed Framework | CCTV & TomTom | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
This entry is adapted from the peer-reviewed paper 10.3390/su132313191
References
- Kumar, K.; Parida, M.; Katiyar, V.K. Short Term Traffic Flow Prediction for a Non Urban Highway Using Artificial Neural Network. Procedia—Soc. Behav. Sci. 2013, 104, 755–764.
- Hu, W.; Liu, Y.; Li, L.; Xin, S. The Short-Term Traffic Flow Prediction Based on Neural Network. In Proceedings of the 2nd International Conference on Future Computer and Communication, Wuhan, China, 21–24 May 2010.
- Nasution, S.M.; Husni, E.; Yusuf, R.; Kuspriyanto. Semi-Ensemble Learning Using Neural Network for Classifying Traffic Condition. In Proceedings of the 6th International Conference on Information Technology Systems and Innovation, ICITSI 2020, Bandung, Indonesia, 19–23 October 2020.
- Yi, H.; Jung, H.; Bae, S. Deep Neural Networks for Traffic Flow Prediction. In Proceedings of the IEEE international conference on big data and smart computing (BigComp), Jeju Island, Korea, 13–16 February 2017.
- Lv, Y.; Duan, Y.; Kang, W.; Li, Z.; Wang, F.-Y. Traffic Flow Prediction With Big Data: A Deep Learning Approach. Intell. Transp. Syst. IEEE Trans. 2014, 16, 1–9.
- Kumar, S.V.; Vanajakshi, L. Short-Term Traffic Flow Prediction Using Seasonal ARIMA Model with Limited Input Data. Eur. Transp. Res. Rev. 2015, 7, 1–9.
- Chen, E.; Ye, Z.; Wang, C.; Xu, M. Subway Passenger Flow Prediction for Special Events Using Smart Card Data. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1109–1120.
- Sujatha, R.; Nithya, R.A.; Subhapradha, S.; Srinithibharathi, S. Decision Tree Classification for Traffic Congestion Detection Using Data Mining. Int. J. Eng. Tech. 2018, 4, 166–173.
- Rahman, F.I.; Hasnat, A.; Lisa, A.A. Traffic Flow Prediction by Incorporating Weather Information in Naïve Bayes Classifier. J. Adv. Civ. Eng. Pract. Res. 2019, 8, 10–16.
- Khan, S.Z.; Rahuman, W.M.A.; Dey, S.; Anwar, T.; Kayes, A.S.M. Road Crowd: An Approach to Road Traffic Forecasting at Junctions Using Crowd-Sourcing and Bayesian Model. In Proceedings of the International Conference on Research and Innovation in Information Systems (ICRIIS), Langkawi Island, Malaysia, 16–17 July 2017; pp. 1–6.
- Anitha, E.B.; Aravinth, R.; Deepak, S.; Jotheeswari, R.; Karthikeyan, G. Prediction of Road Traffic Using Naive Bayes Algorithm. Int. J. Eng. Res. Technol. 2019, 7, 1–4.
- Sumari, A.; Ahmad, A.; Wuryandari, A. Knowledge Growing System: A New Perspective on Artificial Intelligence. In Proceedings of the 5th International Conference Information & Communication Technology and System, London, UK, 20–21 February 2009.
- Sumari, A.D.W.; Ahmad, A.S.; Wuryandari, A.I.; Sembiring, J.; Widjajati, F.A. An Introduction To Knowledge-Growing System: A Novel Field in Artificial Intelligence. JUTI J. Ilm. Teknol. Inf. 2010, 8, 11.
- Husni, E.; Nasution, S.M.; Kuspriyanto; Yusuf, R. Predicting Traffic Conditions Using Knowledge-Growing Bayes Classifier. IEEE Access 2020, 8, 191510–191518.
- Li, D.; Yang, M.; Jin, C.J.; Ren, G.; Liu, X.; Liu, H. Multi-Modal Combined Route Choice Modeling in the MaaS Age Considering Generalized Path Overlapping Problem. IEEE Trans. Intell. Transp. Syst. 2021, 22, 2430–2441.
- Cao, Q.; Ren, G.; Li, D.; Ma, J.; Li, H. Semi-Supervised Route Choice Modeling with Sparse Automatic Vehicle Identification Data. Transp. Res. Part C Emerg. Technol. 2020, 121, 102857.
- Ben-Akiva, M.E.; Ramming, M.S.; Bekhor, S. Route Choice Models. In Human Behaviour and Traffic Networks; Springer: Berlin/Heidelberg, Germany, 2004; pp. 23–45.
- Prato, C.G. Route Choice Modeling: Past, Present and Future Research Directions. J. Choice Model. 2009, 2, 65–100.
- Namoun, A.; Tufail, A.; Mehandjiev, N.; Alrehaili, A.; Akhlaghinia, J.; Peytchev, E. An Eco-Friendly Multimodal Route Guidance System for Urban Areas Using Multi-Agent Technology. Appl. Sci. 2021, 11, 2057.
- Ge, Y.; Li, H.; Tuzhilin, A. Route Recommendations for Intelligent Transportation Services. IEEE Trans. Knowl. Data Eng. 2021, 33, 1169–1182.
- Yang, Z.S.; Cai, C.Q.; Bao, L.X. Intelligent In-Vehicle Control and Navigation Based on Multi-Route Traffic Optimization. In Proceedings of the International Conference on Machine Learning and Cybernetics, Dalian, China, 13–16 August 2006; pp. 962–966.
- Wu, C.; le Vine, S.; Sivakumar, A.; Polak, J. Dynamic Pricing of Free-Floating Carsharing Networks with Sensitivity to Travellers’ Attitudes towards Risk. Transportation 2021, 2019, 16.
- Ma, J.; Xu, M.; Meng, Q.; Cheng, L. Ridesharing User Equilibrium Problem under OD-Based Surge Pricing Strategy. Transp. Res. Part B Methodol. 2020, 134, 1–24.
- Das, P.; Ribas-Xirgo, L. Parameter Estimation for Optimal Path Planning in Internal Transportation. CoRR 2018, arXiv:1808.00522.
- Qu, Y.; Li, L.; Liu, Y.; Chen, Y. Travel Routes Estimation in Transportation Systems Modeled by Petri Nets. In Proceedings of the 2010 IEEE International Conference on Vehicular Electronics and Safety, QingDao, China, 15–17 July 2010; pp. 73–77.
- Zhou, S.; Yan, X. Driver’s Route Choice Model Based on Traffic Signal Control. In Proceedings of the 3rd IEEE Conference on Industrial Electronics and Applications, Singapore, 3–5 June 2008; pp. 2331–2334.
- Ferreira, H.; Rodrigues, C.M.; Pinho, C. Impact of Road Geometry on Vehicle Energy Consumption and CO2 Emissions: An Energy-Efficiency Rating Methodology. Energies 2019, 13, 119.
- Sayarshad, H.R.; Mahmoodian, V.; Bojović, N. Dynamic Inventory Routing and Pricing Problem with a Mixed Fleet of Electric and Conventional Urban Freight Vehicles. Sustainability 2021, 13, 6703.
- Alirezaei, M.; Onat, N.; Tatari, O.; Abdel-Aty, M. The Climate Change-Road Safety-Economy Nexus: A System Dynamics Approach to Understanding Complex Interdependencies. Systems 2017, 5, 6.
- Akin, D.; Sisiopiku, V.P.; Skabardonis, A. Impacts of Weather on Traffic Flow Characteristics of Urban Freeways in Istanbul. Procedia—Soc. Behav. Sci. 2011, 16, 89–99.
- Omranian, E.; Sharif, H.; Dessouky, S.; Weissmann, J. Exploring Rainfall Impacts on the Crash Risk on Texas Roadways: A Crash-Based Matched-Pairs Analysis Approach. Accid. Anal. Prev. 2018, 117, 10–20.
- Ali, Q.; Yaseen, M.R.; Khan, M.T.I. The Impact of Temperature, Rainfall, and Health Worker Density Index on Road Traffic Fatalities in Pakistan. Environ. Sci. Pollut. Res. 2020, 27, 19510–19529.
- Afshari, A.; Schuch, F.; Marpu, P. Estimation of the Traffic Related Anthropogenic Heat Release Using BTEX Measurements—A Case Study in Abu Dhabi. Urban Clim. 2018, 24, 311–325.
- Khalifa, A.; Bouzouidja, R.; Marchetti, M.; Buès, M.; Bouilloud, L.; Martin, E.; Chancibaut, K. Individual Contributions of Anthropogenic Physical Processes Associated to Urban Traffic in Improving the Road Surface Temperature Forecast Using TEB Model. Urban Clim. 2018, 24, 778–795.
- Gładyszewska-Fiedoruk, K.; Teleszewski, T.J. Modeling of Humidity in Passenger Cars Equipped with Mechanical Ventilation. Energies 2020, 13, 2987.
- He, Z.; Chen, K.; Chen, X. A Collaborative Method for Route Discovery Using Taxi Drivers’ Experience and Preferences. IEEE Trans. Intell. Transp. Syst. 2018, 19, 2505–2514.
- Kazhaev, A.; Almetova, Z.; Shepelev, V.; Shubenkova, K. Modelling Urban Route Transport Network Parameters with Traffic, Demand and Infrastructural Limitations Being Considered. In Proceedings of the IOP Conference Series Earth and Environmental Science, Moscow, Russia, 18 May 2018.
- Paiva, S.; Pañeda, X.G.; Corcoba, V.; García, R.; Morán, P.; Pozueco, L.; Valdés, M.; del Camino, C. User Preferences in the Design of Advanced Driver Assistance Systems. Sustainability 2021, 13, 3932.
- Jung, J.; Park, S.; Kim, Y.; Park, S. Route Recommendation with Dynamic User Preference on Road Networks. In Proceedings of the IEEE International Conference on Big Data and Smart Computing (BigComp), Kyoto, Japan, 27 March 2019; pp. 1–7.
- Bin, C.; Gu, T.; Sun, Y.; Chang, L.; Sun, L. A Travel Route Recommendation System Based on Smart Phones and IoT Environment. Wirel. Commun. Mob. Comput. 2019, 2019, 1–16.
- Litzinger, P.; Navratil, G.; Sivertun, Å.; Knorr, D. Using Weather Information to Improve Route Planning. In Bridging the Geographic Information Sciences; Springer: Berlin/Heidelberg, Germany, 2012.