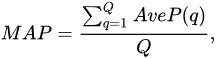Multi-object Re-Identification (ReID), based on a wide range of surveillance cameras, is nowadays a vital aspect in modern cities, to better understand city movement patterns among the different infrastructures, with the primary intention of rapidly mitigate abnormal situations, such as tracking car thieves, wanted persons, or even lost children.
1. Introduction
The task of object ReID on image cameras has been studied for several years by the computer vision and pattern recognition communities [
1], with the primary goal to ReID a query object among different cameras.
Multi-object ReID, based on a wide range of surveillance cameras, is nowadays a vital aspect in modern cities, to better understand city movement patterns among the different infrastructures [
2], with the primary intention of rapidly mitigate abnormal situations, such as tracking car thieves, wanted persons, or even lost children.
This is still a challenging task, since an object’s appearance may dramatically change across camera views due to the significant variations in illumination, poses or viewpoints, or even cluttered backgrounds [
2] (
Figure 1). According to the state-of-the-art research studies, existing object ReID methodologies can be divided into two main categories: image-based and video-based object ReID.
Figure 1. Some common problems found in object ReID.
The former category focuses on matching a probe image of one object, with an image of the object with the same ID among gallery sets, which is mainly established based on image content analysis and matching. In contrast, the latter category focuses on matching two videos, exploiting different information, such as temporal, and motion-based information. A gallery corresponds to a collection of object images gathered from different perspectives over time. In both approaches, the pairs of objects to be matched are analogous. However, in real scenarios, object ReID needs to be conducted between the image and video. For example, given a picture of a criminal suspect, the police would like to quickly locate and track the suspect from hundreds of city surveillance videos. The ReID under this scenario is called image-to-video person ReID, where a probe image is searched in a gallery of videos acquired from different surveillance cameras.
Although videos contain more information, image-to-video ReID share the same challenges with image-based and video-based objects ReID, namely, similar appearance, low resolution, substantial variation in poses, occlusion, and different viewpoints. In addition, an extra difficulty resides on the match between two different datasets, one static and another dynamic, i.e., image and video, respectively.
Image and video are usually represented using different features. While only visual features can be obtained from a single image, both visual features and spatial–temporal features can be extracted from a video. Recently, CNN has shown potential for learning state-of-the-art image feature embedding [
3,
4] and Recurrent Neural Network (RNN) yields a promising performance in obtaining spatial–temporal features from videos [
5,
6].
In general, there are two major types of deep learning structures for object ReID; namely, verification models and identification models. Verification models take a pair of data as input and determine whether they belong to the same object or not, by leveraging weak ReID labels that can be regarded as a binary-class classification or similarity task [
7]. In contrast, identification models aim at feature learning by treating object ReID as a multi-class classification task [
4], but lack direct similarity measurement between input pairs. Due to their complementary advantages and limitations, the two models have been combined to improve the ReID performance [
8]. However, in the image-to-video object ReID task, a cross-modal system, directly using DNN and the information provided by the target task still cannot perfectly bridge the “media gap”, which means that representations of different datasets are inconsistent. Therefore, most of the current works directly rely on weights from pre-trained deep networks as the backbone to obtain initial values for the target model and initiate the pre-trained network structure to facilitate the training of the new deep model.
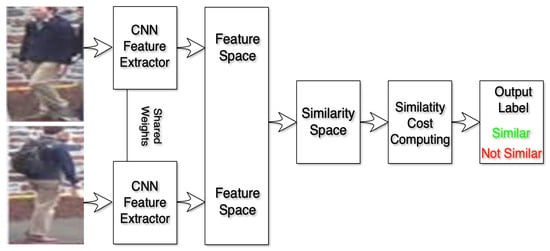
Figure 2 depicts the common base architecture for person ReID.
Figure 2. Common base architecture for person ReID.
2. Deep Learning for Object Re-Identification
A turning point in the history of machine learning and computer vision was reached by researchers of the University of Toronto, who proposed a new image classification approach and achieved excellent results in the ImageNet [
9] competition [
10]. The winning proposal, defined as AlexNet, consisted of a CNN composed of a set of stacked deep layers and dense layers that enabled the reduction of the error drastically. However, the first appearances of CNN dated from 1990, when Lecun et al. [
11] proposed a CNN method addressing the task of hand-written digit recognition to alleviate the work of the postal office.
A CNN multi-layer contains at least one layer to perform convolution operations from image inputs, by using filters of kernels that are translated across and down the input matrix, to generate a feature representation map of the original image input. The characteristics of these filters can be widely different, and each one of them is composed of learnable parameters, updated through a gradient descent optimization scheme. The same layer can employ other filters. For the same part of the image, each filter produces a set of local responses, enabling correlation of specific pixel information with the content of the adjacent pixels. After the proposal by [
10], many different network architectures were developed to address such a problem, each one with its inner characteristics, to name a few, the VGG [
12], Inception [
13], and ResNet [
13] architectures. Many other network architectures were proposed, but in summary, they all share some building blocks.
In regard to the ReID task, the most used backbone model architecture is ResNet [
14], due to its flexibility and ease of reusing and implementation to solve new problems. Most of the ReID tasks explore the use of pre-trained ResNet as backbones for feature extraction for the object ReID task.
ResNets can address the vanishing gradient problem when the networks are too deep, making the gradients quickly shrink to zero after several chain rule applications, leading toward "not updating" the weights and, therefore, harming of the learning process. With ResNets, the gradients can flow directly through the skip connections backward from later layers to the initial filters.
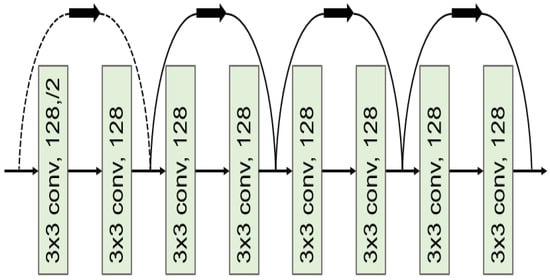
ResNets can have different sizes, depending on how big each model layer is, and how many layers it contains. As an example, ResNet 34 [
15] contains one convolution and pooling layer step, followed by four similar layers (
Figure 3). Each layer follows the same pattern by performing
3×3convolutions with a fixed feature map dimension, and by bypassing the input every two convolutions. A concern with the special characteristics of ResNet 34 is the fact that the width W and height H dimensions remain constant during the entire single layer. The size reduction is achieved by the stride size used in the convolution kernels, instead of the polling layers commonly used in other models.
Figure 3. A common ResNet block architecture.
Every layer of a ResNet is composed of several blocks, enabling it to go deeper. This deepness is achieved by increasing the number of operations within a block, while maintaining the total number of layers. Each operation comprises a convolution step, batch normalization, and a ReLU activation to a particular input; except for the last operation of the block, which does not contain a ReLU activation function.
3. Evaluation Metrics
Cumulative Matching Characteristic curve (CMC) is a common evaluation metric for person or object ReID methods. It can be considered a simple single-gallery-shot setting, where each gallery identity only has one instance. Given a probe image, an algorithm will rank the entire gallery sample according to the distances to the probe, with the CMC top-k accuracy given as:
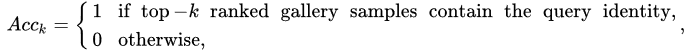
which is a shifted step function. The final Cumulative Matching Characteristics (CMC) curve is built by averaging the shifted step functions over all the queries.
Another commonly used metric is the mean Average Precision (mAP), which is very often employed on each image query, and defined as:
where Q is the number of queries.
4. Person Re-Identification
Person ReID is the problem of matching the same individuals across multiple image cameras or across time within a single image camera. The computer vision and pattern recognition research communities have paid particular attention to it due to its relevance in many applications, such as video surveillance, human–computer interactions, robotics, and content-based video retrieval. However, despite years of effort, person ReID remains a challenging task for several reasons [
16], such as variations in visual appearance and the ambient environment caused by different viewpoints from different cameras.
Significant changes in humans pose—across time and space—background clutter and occlusions; different individuals with similar appearances present difficulties to the ReID tasks. Moreover, with little or no visible image faces due to low image resolution, the exploitation of biometric and soft-biometric features for person ReID is limited. For the person ReID task, databases and different approaches have been proposed by several authors.
4.1. Person Re-Identification Databases
The recognition of human attributes, such as gender and clothing types, has excellent prospects in real applications. However, the development of suitable benchmark datasets for attribute recognition remains lagged. Existing human attribute datasets are collected from various sources or from integrating pedestrian ReID datasets. Such heterogeneous collections pose a significant challenge in developing high-quality fine-grained attribute recognition algorithms.
Among the public databases that have been proposed for person ReID, some examples can be found in the open domain, such as the Richly Annotated Pedestrian (RAP) [
17], which contains images gathered from real multi-camera surveillance scenarios with long-term collections, where data samples are annotated, not only with fine-grained human attributes, but also with environmental and contextual factors. RAP contains a total of 41,585 pedestrian image samples, each with 72 annotated attributes, as well as viewpoints, occlusions, and body part information.
Another example is the VIPeR [
18] database, which contains 632 identities acquired from 2 cameras, forming a total of 1264 images. All images were manually annotated, with each image having a resolution of 128 x 48pixels.
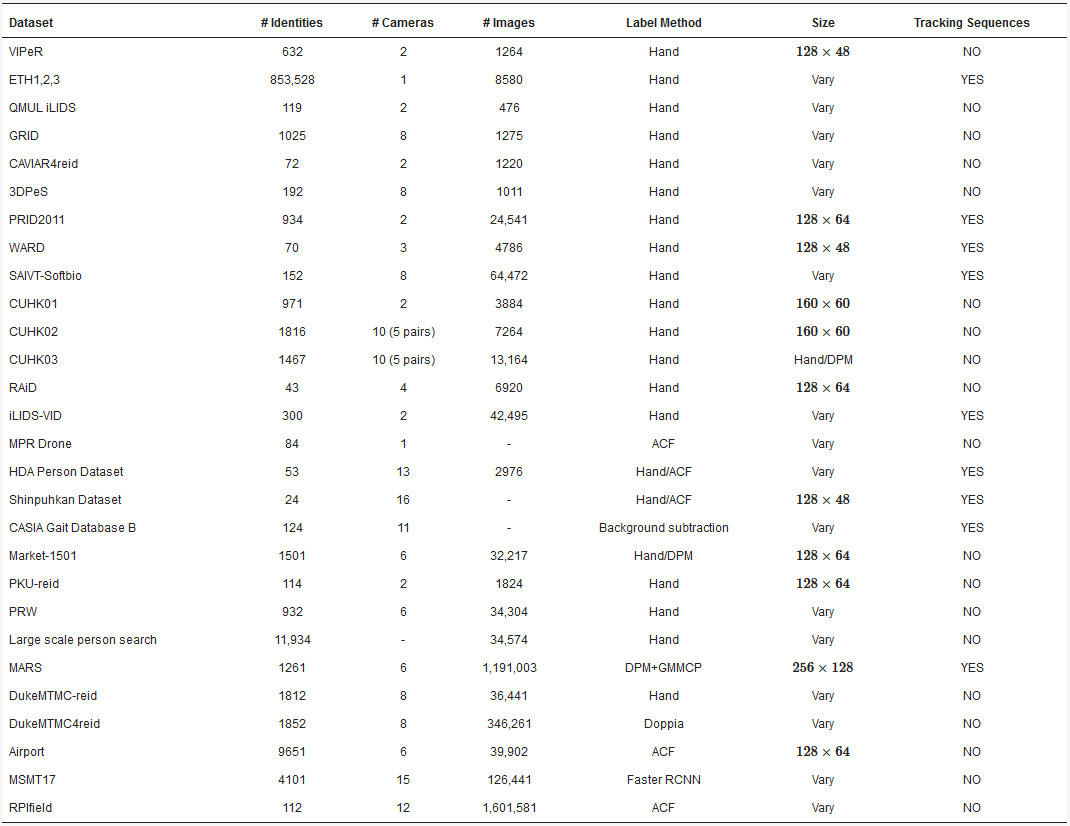
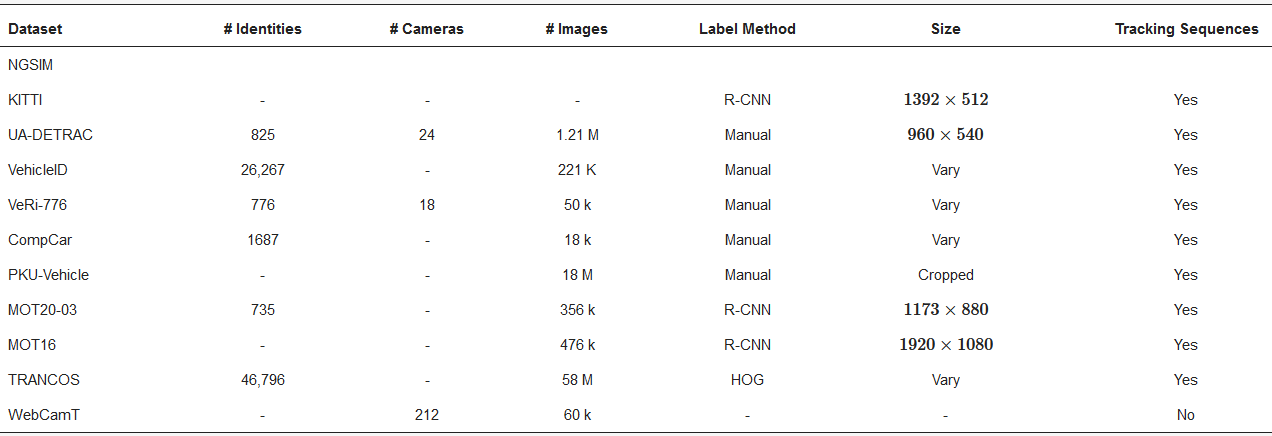
A summary of the public available databases for person ReID, with main characteristics, is presented in Table 1.
Table 1. Global overview of the found public available databases for person ReID.
DPM—deformable part models, ACF—pyramid features, GMMCP—generalized maximum multi clique.
Although many other datasets suitable for object ReID can be found, the ones listed in Table 1 are widely used by most of the authors as benchmarks for performance evaluation and comparison of the proposed works.
4.2. Person Re-Identification Methods
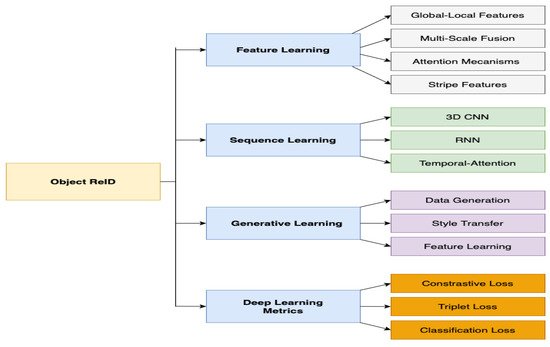
In this section, deep learning-based person ReID methods are grouped into four main categories, as represented in Figure 4, including methods for feature learning, sequence learning, generative learning, and deep learning metrics. These categories encompassed several methods, and they are discussed in the following in terms of their main aspects and experimental results.
Figure 4. Deep learning-based person re-identification methods.
5. ReID and Spatial–Temporal Multi Object ReID Methods
One of the main difficulties of object ReID is to operate in distributed scenarios and account for spatial–temporal constraints for multi-object ReID. Main techniques explore the use of RNN models to construct tracklets to assign IDs to objects, enabling to robustly handle occlusions. In contrast, others rely on 3D CNN to attain temporal dependencies of the object in track.
5.1. Multi Object ReID Datasets with Trajectories
Multi-Object ReID considers attributes, such as shape and category combined with trajectories, and is one of the objectives that go towards the objective to perform multi-object ReID in a real urban scenario. However, the development of suitable benchmark datasets for attribute recognition remains sparse. Some object ReID datasets contain trajectories collected from various sources, and such heterogeneous collection poses a significant challenge in developing high-quality fine-grained multi-object recognition algorithms.
Among the publicly available datasets for ReID, one example is the NGSIM dataset [
78], a publicly available data set with hand-coded Ground Truth (GT) that enables evaluating multi-camera, multi-vehicle tracking algorithms on real data, quantitatively. This dataset includes multiple views of a dense traffic scene with stop-and-go driving patterns, numerous partial and complete occlusions, and several intersections.
Another example is the KITTI Vision Benchmark Suite [
79], which is composed of several datasets for a wide range of tasks, such as stereo, optical flow, visual odometry, 3D object detection, and 3D tracking, complemented with accurate ground truth provided by Velodyne laser 3D scanner and real GPS localization system,
Figure 5. The datasets were captured by driving around the mid-size city of Karlsruhe, in Germany, in rural areas, and on highways, and on average, there are up to 15 cars and 30 pedestrians per image. A detailed evaluation metric and evaluation site are also provided.
Figure 5. Example of the multi-object tracking and segmentation system (MOTS).
A summary of the public available databases for multi-object car ReID with trajectories is presented on Table 2.
Table 2. Global overview of the public available databases for multi-object car ReID with trajectories.
R-CNN—region proposals with CNN, HOG—histogram oriented gradients.
In addition, the PASCAL VOC project [
80], provides standardized image datasets for object class recognition, with annotations that enable evaluation and comparison of different methods. Another useful dataset is ImageNet [
10]. This image database is organized according to the WordNet hierarchy (currently only the nouns), where each node is represented by hundreds and thousands of images. Currently, each node contains an average of over 500 images. The dataset encompasses a total of 21,841 non-empty sets, forming a total number of images of around 14 million, with several images with bounding box annotations of 1 million. In addition, it contains 1.2 million images with pre-computed SIFT features [
81]. Pre-trained networks on these two datasets are commonly reused as backbones for feature extraction to perform several tasks, such as object ReID.
5.2. Spatial–Temporal Constrained and Multi Object ReID Methods
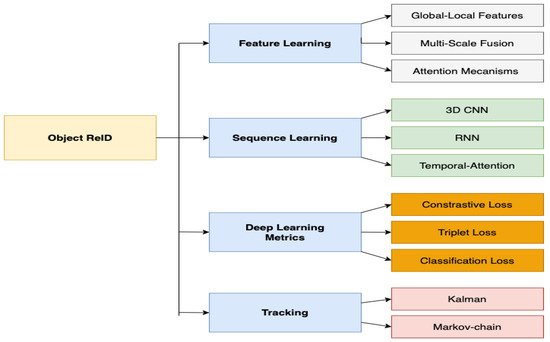
In this section, deep learning-based vehicle ReID methods are grouped into four main categories, as represented in Figure 6; which includes methods for feature learning, sequence learning, deep learning metrics, and tracking, with these categories encompassing several methods. The main aspects of each category method and their experimental results are discussed in the following.
Figure 6. Deep learning-based vehicle re-identification methods.
6. Methods for Image Enhancement
Severe weather conditions, such as rain and snow, adversely may affect the visual quality of the images acquired under such conditions; thus, rendering them useless for further usage and sharing. In addition, such degraded images usually drastically affect the performance of vision systems. Mainly, it is essential to address the problem of single image de-raining. However, the inherent ill-posed nature of the situation presents several challenges.
In [
107], it is proposed an image de-raining conditional generative adversarial network (ID-CGAN) that account for quantitative, visual, and also discriminative performance into the objective function. The proposal method explores the capabilities of conditional generative adversarial networks (CGAN), in combination with additional constraint to enforce the de-rained image to be indistinguishable from its corresponding GT clean image. A refined loss function and other architectural novelties in the generator–discriminator pair were also introduced, with the loss function aimed towards the reduction of artifacts introduced by GAN, ensuring better visual quality. The generator sub-network is constructed using densely connected networks, whereas the discriminator is designed to leverage global and local information and between real/fake images. Exhaustive experiments were conducted against several State-of-the-Art (SOTA) methods using synthetic datasets derived from the UCID [
108] and BSD-500 [
109] datasets, and with external noise artifacts added. The experiments were evaluated on synthetic and real images using several evaluation metrics such as peak signal to noise ratio (PSNR), structural similarity index (SSIM) [
110], universal quality index (UQI) [
111], and visual information fidelity (VIF) [
112], with the proposed model achieving an PSNR (DB) of 24.34. Moreover, experimental results evaluated on object detection methods, such as FasterRCNN [
94], demonstrated the effectiveness of the proposed method in improving the detection performance on images degraded by rain.
A single-image-based rain removal framework was proposed in [
113] by properly formulating the rain removal problem as an image decomposition problem based on the morphological decomposition analysis. The alternative to applying a conventional image decomposition technique, the proposed method first decomposes an image into the low and high-frequency (HF) components by employing a bilateral filter. The HF part is then decomposed into a “rain component” and a “non-rain component” using sparse coding. The model experiments were conducted on synthetic rain images built using an image software, with the model achieving a VIF of 0.60. While the method has some degree of performance with common rain conditions, it has difficulties to handling more complex rain dynamic scenarios.
In [
114], an effective method based on simple patch-based priors for both the background and rain layers is proposed, which is based on the Gaussian mixture model (GMM) to accommodate multiple orientations and scales of the rain streaks. The two GMMs for the background and rain layers, defined as GB and GR, are based on a pre-trained GMM model with 200 mixture components. The method was evaluated using synthetic and real images, and the results compared to SOTA methods, with the proposed method achieving an SSIM of 0.88.
In [
115], it is proposed a DNN architecture called DerainNet for removing rain streaks from an image. The architecture is based on a CNN, enabling the direct map of the relationship between rainy and clean image detail layers from the data. For effective enhancement, each image is decomposed into a low-frequency base layer and a high-frequency detail layer. The detail layer corresponds to the input to the CNN for rain removal to be combined at a final stage with the low-frequency component. The CNN model was trained using synthesized images with rain, with the model achieving an SSIM of 0.900, increasing by 2% the performance in comparison to [
114] using GMM.
A performance evaluation of the reviewed image de-raining methods is given in Table 3.
Table 3. Performance evaluation of the reviewed image de-raining methods.
|
Reference
|
Main Techniques
|
# Data
Success
|
Pros/Cons
|
|
[107]
|
GANS,
conditional GAN
|
UCID
PSNR 24.34
|
Robust,
SOTA
|
|
[113]
|
Bilateral filter,
image decomposition
|
Systeticg
VIF 0.60
|
Simple,
Parameter dependent
|
|
[114]
|
GMM,
image decomposition
|
Systetic
SSIM 0.880
|
Simple,
Pre-trained dependent
|
|
[115]
|
CNN,
HF component layer
|
Systetic
SSIM 0.900
|
Simple,
Robust
|
PSNR—peak signal to noise ratio (higher, the better; range: [0.0,—]), VIF—Information Fidelity (higher the better, range: [0.0, 1.0]), SSIM—structural similarity index (higher, the better; range: [0.0, 1.0]).
This entry is adapted from the peer-reviewed paper 10.3390/app112210809