Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Subjects:
Others
The goal of this study was to conduct a literature review of current approaches and techniques for identifying, understanding, and predicting human behaviors through mining a variety of sources of textual data with a focus on enabling classification of psychological behaviors regarding emotion, cognition, and social empathy.
- text mining
- human behavior
- sentiment analysis
- physiological profiling
Note: The following contents are extract from your paper. The entry will be online only after author check and submit it.
1. Introduction
At present, the vast amount of textual data being generated from myriad sources (e.g., formal or informal reports, interviews, call logs, emails, performance documents, blogs, tweets, comments, or social media entries) is rapidly increasing [1]. Although this increase in textual data allows for large repositories to be analyzed, summarized, and deciphered, using these data to make insightful decisions has become much more challenging. Thus, in this study, we sought to explore the current approaches through which the unstructured textual data can be analyzed by extracting valuable information to support decision-making for various purposes. Consequently, we conducted a systematic literature review of the techniques and methods used to identify, understand, and predict human behaviors by mining various textual data sources.
The problem of mining textual data has received substantial attention, owing to the proliferation of social networks that allow the distribution of opinions and sharing sentiment on diverse subject matters. This literature review is focused on the methods for understanding human psychological behavior through the use of textual data. Mining textual data can provide deep insights into an individual’s views, attitudes, sentiments, and emotions toward other individuals and help predict future social behaviors [2]. Such human behaviors can be identified and understood by extracting textual data with meaningful semantic properties, including metadata such as concepts, events, keywords, categories, including symmetric and asymmetric relationships. Such knowledge can facilitate improved decision-making (e.g., personnel selection and training) or intelligence analyses [3]. According to Bornstein et al. [4], human behavior is described as “the potential and expressed capacity for physical, mental, and social activity during the phases of human life.” Regarding the identification of behaviors by text mining, Tausczik et al. [5] stated that “by drawing on massive amounts of text, researchers can begin to link everyday language use with behavioral and self-reported measures of personality, social behavior, and cognitive styles.” Furthermore, Pennebaker and Stone [6] classified the use of language in the following categories: emotional experience, social relationships, time orientation, and cognitive abilities.
2. Human Behavior
This literature review proposes three main categories to classify human behavior in the context of text mining: cognitive, emotional, and social behaviors. Most of the literature conveys how textual data are analyzed to understand the activities, mental skills, and social interactions among people, with the goal of identifying emotional, social, and cognitive behaviors, whose characteristics are depicted in Figure 1 [55].
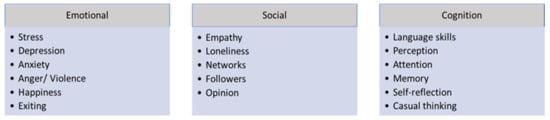
Figure 1. Classification of psychological behaviors.
Emotional behavior is correlated with mental health issues (e.g., stress, depression, anger, or violence), and the monitoring and treatment of mental disorders can be achieved by extracting textual data from communication devices. Several studies have explicitly shown that assumptions can be made about a given person’s current mood by analyzing variations in mobile usage patterns, texting, and calling [9]. Moreover, studies by Tausczik et al. [5] and Rutland et al. [70] described machine-learning methods to analyze the content of messages sent by short message service (SMS) to scan words from texts and link them to psychologically meaningful terms that can be used to asses emotions and changes in mood. In addition, audio data from mobile calls can be analyzed and translated to text, and the person’s mood can be extracted to detect emotional signatures [35].
Social behavior is associated with issues of social interaction, such as empathy or loneliness. Social networks, such as Twitter, LinkedIn, or Facebook, were used to study human social behavior. Textual comments were analyzed to identify sentiments to extract information about attitudes, social activity, and interactions with other users [27]. For example, the number of ongoing or outgoing comments or conversations can reflect the current mood of a given individual. In addition, people with mental health conditions tend to increase the number of texts sent during maniac episodes, whereas low levels of texts sent can be correlated with depression [14]. In terms of societies, governments, and leader actions, interesting advances using hybrid approaches such as complexity science, symmetry, and information systems (text) presented by Helbing et al. [91] demonstrate that they can contribute to areas such as understanding geopolitical tensions by analyzing an extensive data set from newspaper articles. The published news was used to search the text of the article for mentions of a given country along with a set of keywords typically associated with tensions (for example, crisis, conflict, antagonism, clash, contention, discord, fight, attack, combat) and have predictions about the subsequent actions.
Cognitive behavior is associated with the performance of mental processes such as thinking and casual reasoning [55]. The information expressed as textual data can be used to monitor an individual’s skills in different activities. Some authors divide cognitive functions into categories (e.g., perception, attention, memory, language skills, and executive functioning), which can be monitored by assessing performance in specific tasks within these categories. For example, textual analytics was used in SMS text messages from people with schizophrenia to help identify cognitive impairment [104].
2.1. Emotional Category
In this category, the included papers focused on using smartphones, written information, opinion mining, and customer feedback. Gravenhorst et al. [9] recognize smartphones as a promising technology for use in the treatment of mental disorders through the implementation of sensor devices to monitor illnesses. By using human–computer interfaces to support therapy and by collecting data from patients’ daily lives, smartphones can be beneficial for treating people with mental disorders. Grünerbl et al. [15] explored the use of mobile phones to recognize depressive and manic states in people with bipolar disorder. This sensor-based smartphone system can support the treatment of patients with bipolar disorder as a supplementary tool for health care professionals [15]. Muaremi et al. [35] demonstrated the applicability of phone calls to assess episodes of bipolar disorder in patients. Statistics were extracted from various phone call conversations by using speech cues, and different features, social signals, and emotional properties were identified [35]. Li and Qian [44] identified how long-term memory helps classify information by analyzing different emotions in texts. This method helps classify different sentences with a corresponding emotion and may be used to project possible trends in preferences [44].
Wang et al. [80] used emotion evolution law for emotion analysis. This method evaluates natural language text from web news by using one-step and limited-step shifts as well as path transfer; it was validated on a data set of titles, bodies, and comments from news articles. This method can identify feelings such as love-anger, sadness-anger, and joy, thus providing insight into applications regarding affective interaction in network public sentiment, social media communication, and human–computer interaction. Swain et al. [83] proposed a method for detecting suicide ideation by using sentiment analysis from tweets via supervised learning. By using Python language modules and machine learning models for opinion mining, the research using this method suggests that machine sentiment analysis can aid in timely detection and act as an alert system for suicidal tendencies. Similar work was recently presented by Bayram and Benhiba in [88], where with machine learning techniques, it was possible to identify a person’s suicide risk based on the short-term history of their tweets. Fareri et al. [86], in 2020, focused on the development of a data-driven approach using text mining techniques to analyze job profiles and quantify the readiness of employees of a large firm to adopt the Industry 4.0 paradigm. This approach provides a framework for estimating the Industry 4.0 readiness of enterprises.
Mahendran et al. [10] proposed classifying written information as positive, negative, or neutral to efficiently study raw data by using traditional approaches such as Bag of Words, Naïve Bayes classifier, and frequency distribution. Tausczik et al. [5] used the computerized text analysis program Linguistic Inquiry and Word Count (LIWC) to determine the physiological meaning of textual information. In this program, words are categorized into different psychological classes to assess peoples’ thought processes, emotional states, intentions, and motivations [5]. Turney [21] categorized data according to an analysis of the meanings of different words by using algorithms. For example, positive reviews (thumbs up) are determined if the review contains positive words, whereas negative reviews are determined by negative words (thumbs down). Nasukawa and Yi [37] applied a semantic analysis and achieved 70–95% precision in relating sentiments to positive or negative words in text documents from web pages and articles. Extracting information by using NLP can help determine sentiments expressed online [37]. Thakur and Han [105] presented an attractive approach for analyzing the acceptance of interaction with virtual assistants throughout different interactive devices with sentiment analysis using Natural Language Processing to explore the views, expressions, and beliefs expressed by older adults.
Pennebaker et al. [42] studied the software LIWC, which processes textual information to capture the beliefs, preferences, and sentiments of people expressed in words. This study provides evidence that the words that people use have psychological value [42]. Emotions play a critical role in the studies of human knowledge and behavior. These emotions can be determined by the environmental events of the individual or by their cognitive abilities and social skills. Knowledge management (KM) research considers them from specific angles, and, to date, a comprehensive understanding of the emotions that dominate KM and their prediction has been lacking. To offer a holistic view, this study investigated the presence of emotions in knowledge management publications by applying sentiment analysis [87].
Liu [2] introduced different aspects of sentiment analysis and opinion mining because these two fields have become the most critical approaches in analyzing people’s opinions, sentiments, emotions, and attitudes through the collection of textual language. Miedema [17] explored how sentiment classification can be used to arrange documents according to sentiments. This method was used to organize feelings gathered through movie reviews for the long short-term memory. Bo Pang et al. [18] indicated that some machine learning techniques have not performed correctly in classifying texts by sentiment. This aspect has become a concern because it makes sentiment analyses more challenging. Othman et al. [24] explored approaches for opinion mining and sentiment analysis to gather and analyze information about the opinions of the public. Machine learning can help collect the responses posted on different social media platforms so that data can be used for various purposes in the industry. Acheampong et al. [78] focused on sentiment analysis through emotional detection via text mining. With the ease of sourcing for data, the analysis of text mining has led to different approaches in the design of text-based emotional detection systems as well as different proposals regarding the concepts of contributions, approaches used, datasets used, results obtained, and strengths and weaknesses.
Vinodhini and Chandrasekaran [26] established that sentiment analysis and opinion mining can help predict future behavioral trends by elucidating the preferences of customers according to what they write. This capability is valuable for economic and marketing studies. Usability in logistics and supply chain management was used recently to examine customer perceptions of companies’ services. For example, Siby et al., in [90], presented an interesting application in last-mile logistics. The research used customer reviews about their delivery experience regarding quality, service quality, product return, refund policy, information sharing issues, etc. This work recommended suggestions for redesigning processes related to last-mile logistics by introducing artificial intelligence technology. Pang and Lee [25] compared traditional analyses and sentiment-aware applications that process information about the sentiments and opinions of people. Different techniques, benchmarking, future work, and resources were also studied. Salloum et al. [20] proposed a different classification system for the different aspects of opinion mining because the challenges of correctly detecting the meanings and interpretations of different opinions can complicate opinion mining (i.e., an understanding of the domain-specific opinion is required) [20].
Greco and Polli [77] focused on the abundance and use of textual data as a source of valuable information regarding opinions and feelings and discussed the use of emotional text mining in brand management. This method is used to profile social media users’ representations and sentiments about a topic by extracting information from a collection of texts such as Twitter. Raeesi Vanan [82] performed a study in which 3 million inbound tweets and outbound brand responses (tweets) were collected for brand sentiment analysis. Steps of CRIP-DM were used as a reference guide for business and data understanding, preparation, text mining, validation, and discussion of its contributions. The analytical conclusions regarding the sentiment trends were that the sentiments of customers toward a brand are significantly correlated with the brand’s proper response to a brand community over social media as well as providing customers with a deep feeling of reciprocal understanding of needs.
Pang and Lee [25] presented the importance of opinion mining and sentiment analysis, which has led to the development of several techniques and machines to gather and process information about the opinions and moods of people. The challenge is to seek better approaches to sentiment-aware applications. Haddi et al. [43] used support-vector machines (SVM) to explore the importance of text pre-processing in sentiment analysis because understanding the relevance of product opinion can be very challenging, owing to the diversity and quantity of unstructured data in existence. [43].
Binali et al. [11] indicated that determining the emotional experiences of e-learning students can be difficult; however, through mining techniques, analyses can detect emotion in online students. In addition, identifying the different emotions of e-learning students can help model more suitable educational programs. Another study [16] proposed summarizing customer reviews by choosing product features on which they commented, classifying whether the opinion was positive or negative, and summarizing the results. This analysis is important because extremely high numbers of reviews prevent potential customers from reviewing every single opinion. Mate [23] proposed a ranking of essential product features from the online reviews of consumers. These aspects were identified by the number of times the product features appeared in reports and how these aspects influenced the overall opinions of consumers.
Estrada et al. [79] performed a comparison of sentiment analysis classifying techniques, machine learning, deep learning, and EvoMSA to classify education opinions in an Intelligent Learning Environment called ILE-Java. The development of two corpora expressions, sentiTEXT, which has polarity positive and negative labels, and eduSERE, which has positive and negative learning-centered emotion labels, reflected students’ emotional states regarding teachers, exams, homework, and projects. EvoMSA produced the best results among the classifying techniques, with a 93% accuracy rating for the sentiTEXT corpus and an 84% accuracy rating for the eduSERE corpus. Two expressions in the programming language domain reflect the emotional states of students and their feelings regarding teachers’ exams, homework, and academic projects: sentiTEXT (positive and negative labels) and eduSERE (positive and negative learning-centered emotions labels. Misuraca et al., 2021 [81] discussed OM as a combination of statistics, linguistics, and computer science that evaluates sentiments of individual opinions and highlights semantic orientation. The discussion includes the induction of OM as a statistical text analysis tool in a learning environment to process student feedback from natural language producing useful analytics, and to explore text collections from a quantitative viewpoint.
Wu et al. [28] studied how information shared on Facebook pages can be beneficial in determining whether a company is correctly reaching its customers or the desired requirements are met. By analyzing the interactions of Facebook users and the reactions to their posts, companies can gather information, apply statistical analyses, and model behavioral trends [28]. Kaur and Bansal [34] introduced opinion mining as a powerful tool for e-commerce because it gathers information about how customers feel about different products. This collection of opinions can help companies make better decisions and align their efforts with what customers really want. The classification of e-commerce users represents an appealing area of study for marketers seeking to align their efforts to capture more consumers. [34]. Gamon [41] used large feature vectors and feature reduction to demonstrate that large, noisy data regarding customer feedback can be analyzed and classified. Feedback received from customers can present many challenges, and classifying these data is necessary to retrieve only the important information [41].
Bollen et al. [12] highlighted that many Twitter users express their emotions through this social media platform. With the use of a psychometric instrument, different social events were found to profoundly affect changes in public mood. The identification of these sentiments reflects personality trends, as well as the atmosphere and emotions of Twitter users. Basari et al. [22] examined how tweets can contain information about users’ preferences regarding movies. SVM can analyze natural language to determine patterns via opinion mining. Online reviews can help predict the possible preferences of the movie audience [22]. Zengin Alp and Gündüz Öğüdücü [38] introduced a method called Personalized PageRank, which integrates the information retrieved from network topology and the information of Twitter users regarding their actions and activities. This capability has become appealing for marketers because Twitter is an online platform where users share their preferences.
Saire and Cruz [84] focused on the use of text mining of data collected from social media and search trends to analyze the effects of COVID-19 on the population of Paris, France, from 23 April 2020 to 18 June 2020. The primary findings revealed a decreasing pattern of publication/interest in the health crisis and the health and economic effects on the population resulting from the effects of COVID-19. Chire-Saire [85] used analysis of social media through complex network representation and text mining to compare the effects of COVID-19 in other countries. Focusing on South American countries, the analysis of texts via Twitter indicated the existence of patterns similar to those in complex systems and confirmed the idea of system and visualization of adjacency matrices, which may potentially identify posts made by robots as opposed to humans.
Frost et al. [14] studied the system MONARCA 2.0 to collect relevant information from bipolar patients, with an aim to provide insight into the disease for both patients and clinicians by processing subjective and objective data about patient mood. This system helps identify patterns in behaviors and factors affecting the disease [14]. Lachmar et al. [27] gathered information shared by individuals with sentiments of depression on Twitter through the hashtag #MyDepressionLooksLike. These tweets presented dysfunctional thoughts, hopeless feelings, and unlovability characteristics, thus revealing how people with depression talk about their symptoms via social networking. Pijnenborg et al. [40] discussed the benefits of using SMS to decrease the effects of cognitive impairments in patients who have schizophrenia. Because schizophrenia also involves delusions and hallucinations, improvements in the status of patients using SMS can be very modest.
Bespalov et al. [13] proposed an approach to modeling higher-order sentences to a lower order to make the classification of data viable. Supervised latent n-gram analyses can help classify sentiments that are extracted from textual information. Davis et al. [29] determined how analytical models can enhance public safety with the help of probabilistic and parametric methods, as well as different nonlinear algebraic models, by analyzing uncertain data and identifying threats and false alarms, and detecting possible terrorist profiles [29].
Gill [33] illustrated the relationship between the language used and the personality projected by word choice. The personality traits of extraversion, neuroticism, and psychoticism can be determined by analyzing text from emails [33]. Boyd and Pennebaker [39] studied the language used by people to identify personality patterns. Rather than focusing on responses to self-reported questionnaires, language-based measures represent a new approach to model personality trends. A.S. Cohen et al. [3] applied computerized lexical analyses to determine positive or negative affectivity dimensions through natural speech. Measuring personality was possible because people with positive affectivity demonstrate high levels of positive emotions, whereas those with negative affectivity show high levels of negative emotions.
Brynielsson et al. [31] used different techniques for analyzing data to detect “lone wolf” terrorists with the goal of preventing possible attacks. Analytical models were created by using a platform to harvest and capture online information and trace possible lone wolves [31]. K. Cohen et al. [32] established the challenges of detecting lone wolves by using traditional police methods and introduced new tools and technologies that can detect weak signals in the form of linguistic markers that facilitate the identification of lone wolves’ profiles [32].
Hung et al. [30] introduced a new framework and technology called INSiGHT (Investigative Search for Graph-Trajectories) that helps detect groups or individuals whose behavior suggests a potential for violence by identifying radicalization trajectories over time [30]. Paul K. Davis et al. [36] studied behavioral patterns and their usage to predict possible acts of violence.
2.2. Social Category
In this category, Alexander Semenov et al. [45] studied the identification of possible school shooters by analyzing the content shared by users on different social media platforms. Future shooters can be identified by analyzing the emails, chats, texts, and social media feeds of prior school shooters sharing similar behaviors [45]. Bartlett and Reynolds [46] presented how social media faces legal and ethical responsibilities, yet also can be useful to prevent terrorism and preserve public safety. Privacy can protect the public and prevent the use of social media for terrorism and propagandistic purposes [46]. Marrese-Taylor et al. [52] tested the software Opinion Zoom to gather online information about tourism opinions to propose solutions to problems in the industry. A modular tool was used because tourism opinions on the web can help predict possible traveling patterns as well as preferences of travelers.
Kastrati et al. [49] investigated the activities of users on online social networks to identify crimes by applying the objective metric SEMCON. By retrieving online posts, feeds, or users’ comments, this method can determine whether a user is a suspect [49].
Bollen et al. [12] analyzed how OpinionFinder and Google-Profile of Mood States (GPMOS) can help determine the mood patterns presented on social media regarding worldwide events. This analysis can also help companies predict the behavior of customers regarding the stock market and minimize the effects of fluctuations in the stock market. Bucur [47] established that opinion mining had become a key technique for extracting and collecting relevant information needed for companies to make better decisions and that the opinions of customers are fundamental input. Opinion mining has become an appealing area of study for many businesses [47].
Dave et al. [48] extracted textual information and classified online reviews as positive or negative according to different product attributes. Opinions can be classified through semantic analysis of online reviews [48]. Zha et al. [51] introduced a ranking system for product aspects by identifying that a) the most important aspects are described by more consumers, and b) these aspects directly affect the overall opinion of consumers. Product aspect ranking has many applications in various industries, and the main use is to gather relevant information to make better decisions.
Nahm and Mooney [50] examined how DiscoTEX can help extract data by combining data mining and information extraction. This method can locate data within documents and transform unstructured text into a structured database, as well as predict additional information for extraction from other documents. The integration of data mining and information extraction can help combine data in a more readable structure [50]. McCallum [56] investigated how unstructured data present a challenge in interpreting information. Therefore, the aim of information extraction is to create a database by gathering loosely formatted texts in which patterns can be identified by data mining [56].
Diehl [53] examined not only the structural but also the cultural aspects of social networks. Relational sociology studies have tended to examine and retrieve information from text data, whereas the importance of the implications of face-to-face interactions when analyzing network information has largely been ignored. A. Semenov et al. [54] proposed three modules for long-term monitoring of different social networks: the crawler, the repository, and the analyzer. By crawling, storing, and analyzing different sites, longitudinal data from social media sites can be examined.
Pennebaker [55] analyzed the words that people use in emails, Twitter feeds, and Facebook posts to determine their emotions, thoughts, social relationships, and personalities. The focus was on word use rather than on how people were speaking. Mind mapping can help explore social and psychological trends. Ibrahim and Ahmad [57] researched how Requirements Analysis and Class Diagram Extraction (RACE) can expedite textual extractions and improve the analysis of the data requirements that are currently performed manually. Many NLP techniques were developed to extract relevant information from textual data.
2.3. Cognition Category
Eichinger et al. [58] introduced Affinity, a system that can assess similarities among the text message histories of users while preserving private information. A latent format is used, which does not allow for the reconstruction of the comparison words. Chung and Pennebaker [61] distinguished the adjectives most commonly used by college students by applying computerized text analytic tools. This study has established the strengths of analyzing open-ended texts to extract information from the natural language used by different participants. This method enables the examination of cultural patterns as well as personality characteristics.
Bond and Pennebaker [59] experimented with changing pronouns to moderate the health benefits of expressive writing by alternating the focus of participants. Expressive writing can therefore affect people’s physical and psychological health. Pennebaker and Stone [6] developed two projects showing the relationship between language use and aging: as people age, they tend to use more positive affect words than negative affect words and to use fewer self-references and fewer past-tense verbs.
Rajman and Besançon [62] established that text mining is a powerful technique to extract important information from a dataset by applying probabilistic associations of keywords because unstructured data can be challenging to interpret.
Fishhoff and Chauvin [106] investigated how intelligence analysis helps clear difficult situations and enhance valuable information for better decision-making by evaluating and integrating pertinent information. Intelligence analysis can help determine behavioral profiles and social conduct.
2.4. Other Studies
Kosala and Blockeel [65] explored the use of web mining by dividing it into three different categories—web content mining, web structure mining, and web usage mining—and studying representation issues, recess, and learning algorithms. Balazs and Velásquez [63] studied how information fusion seeks to correctly transform and compress data to transform them into a more understandable representation. Fusion processes and the development of surveys to extract relevant data can be helpful as the use of opinion mining steadily increases. Nigam et al. [67] evaluated maximum entropy techniques to establish how a uniform distribution can benefit the classification of data. More studies must be performed, but this technique appears promising.
Continuous efforts have been undertaken worldwide to propose new classification algorithms such as Tsetlin Machine [107] or Dendritic Neuron Models [108]. Rutland et al. [70] evaluated how the use of SMS can be measured with the SMS Problem Use Diagnostic Questionnaire (SMS-PUDQ) to determine behavioral addiction to SMS use. The time spent using SMS and other measures of mobile phone use were detected during the study. Aggarwal and Zhai [71] explored the importance of mining text data, an appealing research topic, given that the amount of web-enabled data has increased and facilitates the exploration of vast quantities of textual data. A comparison of the classical and modern aspects of text mining was also described. Berry and Kogan [72] studied the contributions of text mining, as well as major topics associated with text mining, by categorizing text into three different components to explore keyword extraction, classification, and the clustering of information presented in textual data. Akilan [73] investigated the field of text mining to extract unstructured data and identify interesting and non-trivial patterns from text documents. An exploration of the current challenges and projected directions of this field was described [73]. Chakraborty et al. [64] prepared various case studies and performed text mining and analysis to extract important information from textual data. Different scenarios were created wherein SAS was used to perform comprehensive text analytics to help industries leverage the textual data [64].
Shahbaz et al. [68] proposed a solution to the analysis of textual information by developing a system, Sentiment Miner, to process and classify text files according to opinions stated in various sentences by using NLP techniques and opinion mining algorithms. Weiss et al. [69] introduced methods to predict and analyze unstructured information presented on textual data. Methods used for data mining could be adapted to be applied to text.
Chakraborty et al. [64,109] collected insightful information from customers by analyzing textual data from various documents to improve business operations and performance. Analyses of unstructured data are possible by extracting important information when performing text analysis and sentiment mining. Weerdt et al. [74] described the importance of retrieving data to benefit business process management by applying process mining, which uses techniques to analyze and extract knowledge and information from system event logs.
Manning and Schutze [66] established the value of using statistical NLP to extract and interpret textual data, not only for businesses but also for government agencies and individuals who could benefit from extracting information from a large amount of data. The theory and practice of these techniques are also explored. [66]
Moraes et al. [75] compared SVM and artificial neural networks to determine the differences between these two approaches in performing sentiment analysis and determined that artificial neural networks perform better than SVMs. Fraley [76] presented guidelines on how to construct web-based surveys to conduct behavioral research. Strengths and limitations of online surveys are highlighted, as well as the factors affecting the design of internet-based research.
This entry is adapted from the peer-reviewed paper 10.3390/sym13071276
This entry is offline, you can click here to edit this entry!