Continuous delivery is an industry software development approach that aims to reduce the delivery time of software and increase the quality assurance within a short development cycle. The fast delivery and improved quality require continuous testing of the developed software service. Testing services are complicated and costly and postponed to the end of development due to unavailability of the requisite services. Therefore, an empirical approach that has been utilised to overcome these challenges is to automate software testing by virtualising the requisite services’ behaviour for the system being tested. Service virtualisation involves analysing the behaviour of software services to uncover their external behaviour in order to generate a light-weight executable model of the requisite services. There are different research areas which can be used to create such a virtual model of services from network interactions or service execution logs, including message format extraction, inferring control model, data model and multi-service dependencies.
- service virtualisation
- message format
- control model
- data model
- multi-service dependencies
1. Introduction
Recently, software systems have been structured as several different components which communicate to accomplish software tasks. Due to some limitations, testing of these components may end up very costly or time-consuming. One of the limitations is the unavailability of other internal or external requisite components for testing any of components. This limitation can lead to a delay in the delivery of the components to the time when all of them are developed. This example illustrates one of the situations when all the requisite components are from one vendor. Using different vendors for the requisite components can cause the problem of testing to be even more severe.
Continuous delivery is one of the approaches in software engineering to deliver higher quality software faster [1]. Embracing continuous delivery reduces the integration cost which makes the continuous integration plausible. Continuous integration requires the continuous testing of the components every time they are either developed or changed. For the continuous testing of each component, all the requisite components need to be present regardless of their development status.
Several approaches aimed to provide the required components and environments ready for testing each component. The first approach is the commonly used mock objects such as stubs [2][3]. The server-side interactive behaviour of each requisite component is simulated in this approach by coding them in specific languages. This manual coding needs to be repeated every time each component is being modified.
Virtual machines tools such as VirtualBox and VMW are the second commonly used approach which aims to provide a platform to install multiple server systems [4]. This approach requires the availability of the server systems to be installed on the virtual machines, which may not be accessible in some situations. The need for the real service resource for the installation causes the method to suffer from scalability issues, which limits the number of systems that can be installed on one system.
Another approach to alleviating the high system resource demand in hardware virtualisation is container technologies such as Docker [5]. In comparison to other hardware virtualisation approaches, this solution requires fewer system resources and provides protected portions of the operating system; therefore, it can set up a lighter testing environment with higher scalability. However, this method still suffers from scalability limitations.
Service emulation [6][7] is a slightly recent approach which tries to replace each requisite component with its behaviour estimation. This estimation is meant to be executable and very light-weight. This solution is used to target a specific component’s characteristics for the specific quality test and ignore the rest. Emulating each component in this approach requires the functionality information of each component and an expert’s manual configuration. The components’ functionality information may not be available in components with intricate behaviour.
To alleviate some of the service emulation limitations, the idea of service virtualisation (SV) [8] was proposed. SV aims to get information about components’ behaviour directly from their network interactions. By utilising tools such as Wireshark [9], this method can record the components’ network interactions. Then, instead of human experts, it aims at using machine learning techniques to drive light-weight executable component models [3][8][10][11][12]. Record-and-replay technique is another term used for the SV solution. This is because, in responding to a live request, the proposed SV tries to find the most similar request from those that have been recorded before and substitute some of its response fields to make it compatible with the new request. Figure 1 visualises the record-and-replay concept.
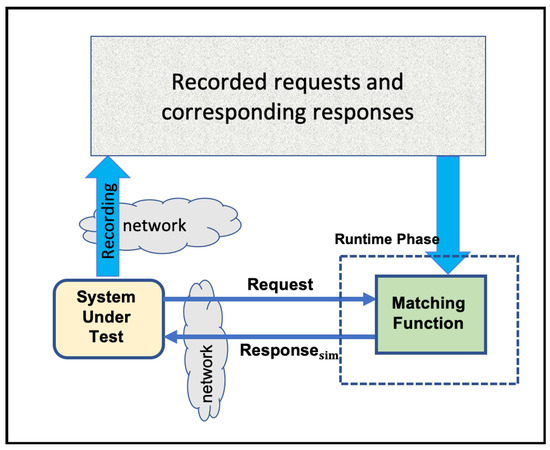
The referenced SV solutions cover some simple stateless protocols that do not require more than the current request to generate an accurate response message. To accommodate stateful protocols—when the response message requires not only the current request but also the previous relevant messages—there are a few methods proposed by Enişer and Sen [13] and Farahmandpour et al. [14][15]. However, the long short-term memory (LSTM) based method presented by Enişer and Sen to cover stateful protocols needs a long time and lots of resources to train.
These were the research efforts that directly contributed to the development and improvements of SV approaches. In contrast to the limited number of solutions within the SV field, there is a huge body of work that indirectly contributes to this area of the research. As a result, the rest of this paper provides an overview of different research efforts that can directly or indirectly contribute to the software virtualisation solution in a component based structure.
2. Related Work
3. Message Format
The message format is defined by the structural rules of forming the messages and their contents in a service’s interaction protocol or interface description. Every protocol may define several types of messages with each having its particular format. Understanding the protocol’s message format is crucial to mimic each service’s behaviour. Some of the researchers extract the key parts of messages and their offsets, which indicate their location from the start of the message, while others extract the full structure of messages. As Figure 2 shows, each message consists of a header and payload. Each header and payload can later be divided into their relevant bytes of information and tagged separately. This section starts with the research dedicated to discovering partial message format and then continues reviewing work focused on inferring the whole message format.
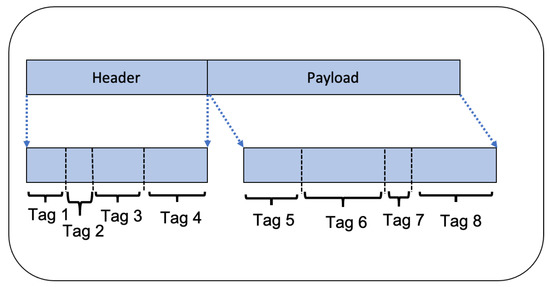
3.1. Summary of the message format
The related work surveyed above extracts the message structures used in a protocol. Some of them such as Du et al. [12][17][18], Cui et al. [19] and Comparetti et al. [20] cluster the messages based on their type in one cluster, and keep one common message as the template for the type. Then, they try to find the most important and dynamic parts of the messages that need to be changed in a new message using iterative clustering and/or statistical analysis such as frequency/entropy, TF/IDF, server’s behaviour such as executed code fragments, library, system calls, output and file system activity, etc.
Others such as Cui et al. [21], Leita et al. [22], Krueger et al. [23], Small et al. [24], Wang et al. [25] and Jiang et al. [26][27] go further and try to infer the whole structure of the messages, field by field, using iterative clustering and statistical analysis of the messages to find the structures for each cluster. In addition, Small et al. [24] and Wang et al. [25] infer one FSM for each cluster. The existing binary message format extraction methods rarely extract the hierarchical structure of messages where the dependencies between different fields in a message are identified. In addition, some of them are designed to extract the structure of messages that have fixed-length fields and cannot work on protocols with the variable length fields or complex structures.
4. Control Model
This section discusses existing methods for extracting the temporal ordering or control model of services from their logs. These methods analyse the network interactions of service with other services or its internal execution logs as the only external recorded documents of the system’s behaviour and extracts the service’s temporal behaviour in the form of a state machine. Following the state machine in these approaches, the next behaviour of the system is determined based on the previous behaviour of the system from the start of the session/interaction to the current point. Some other methods use deep learning methods to infer the next message or legitimate fields and values. The resulting control model for the service helps to identify the type of response messages for the incoming request messages.
4.1. Summary of control model
Some of the approaches reviewed in this section extract a temporal behavioural model of a system as temporal invariants from their network interactions or internal execution logs or both of them. They use different temporal patterns to capture the system’s behaviour, including always occurrence, immediate occurrence, non-occurrence, etc. Each of the statistically significant constraints are kept as building blocks of FSA and others are considered as outliers. Moreover, most of the papers discussed consider the inferred invariants in the global scope, i.e., the whole event trace needs to match the inferred constraints. There is also an example that defines a local region as the scope of the extracted pattern.
Existing studies try to mine and model services’ behaviour in the form of FSA based on two types of approaches. The first group, Comparetti et al. [20], Leita et al. [22][28], Wang et al. [25], Trifilò et al. [29], Antunes [30], and Kabir and Hun [10] build an FSA model from the logs (raw/pre-processed) and then try to abstract and generalize the model based on some heuristics or clustering methods. While Beschastnikh et al. [31], Yang and Evans [32], Lo et al. [33], and Le et al. [34] first infer invariants and refine them based on statistical techniques and then construct FSA. The papers tried to use a variety of methods to refine the FSA. They can be summarised as incrementally refining and merging likely equivalent states without violating the satisfied invariants, using counter-examples to split and refine the model, using domain-specific heuristics to identify similar states to merge, and bottom-up methods such as intra-trace refinement, which starts merging from each cluster of similar traces up to merging between different clusters called inter-trace merging.
As we can see, the existing literature infers a service’s temporal model based on its interaction behaviour with one service, without incorporating different types of dependencies to generate all the message payload required to virtualise a service’s behaviour. One service’s behaviour may be affected in different ways by another requisite service. Therefore, we need to expand the existing methods to consider the services’ mutual impacts on each other in generating both exact service response message types and their contents.
5. Data Models
This section surveys research efforts related to inferring data models from logged data. In some studies, data models are referred as data invariants. This section also reviews studies that add the inferred data models/data invariants to the temporal/control model.
The data invariants can help better understand software behaviour. Data dependency between two services can be considered at different levels of granularities. Intra-protocol data dependency are ones that concern data dependency between messages of one protocol. For example, at a more granular level, data dependency between the data fields of a request message and those of its corresponding response message are one type of inter-message dependency and part of the intra-protocol dependency. Such inter-message data dependency can help formulate a response message for a corresponding request message. We note that most of them utilise clustering to differentiate between different pairs of request–response messages.
5.1.Summary
Despite the advancement in the inference of the temporal model (control model), few researchers have addressed the problem of discovering data models. The above attempts tried to combine control models and some data invariant models in order to improve the inferred behavioural model. However, the coverage of the inferred data model in terms of the complexity of the model, the type, and the number of parameters are limited and can only reflect a limited range of data types and data dependency in the real environment. There remains a need to design and develop a more comprehensive dependency extraction method, which uses different methods of dependency discovery and different levels of complexity to infer complex data dependency models that describe the inter-dependency between systems.
6. Multi-Service Dependency
Looking to find the relevant work in other areas, such as multi-service dependency which could possibly be used to extract more complex dependency between services that can influence service behaviour has resulted in the following insights. As an example shown in Figure 3 taken from [35], we can see different dependencies that can influence the behaviour of service S3.
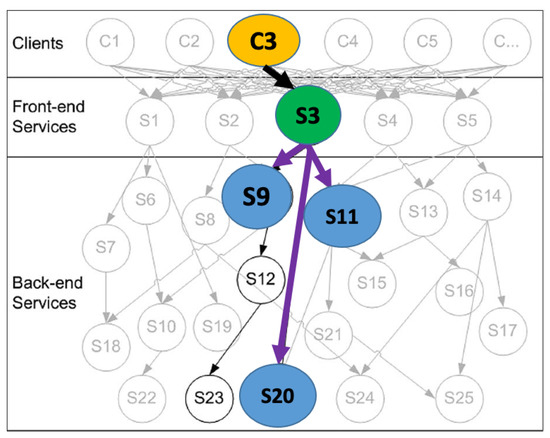
To extract the multi-service dependency model of distributed services, and get the total ordering of the events, the first step is the synchronisation of the services’ clock. In [36], Lamport examined the concept of one event happening before another in a distributed system and defined a partial ordering of the events. To synchronise a system of logical clocks, a distributed algorithm was introduced, which also can be used to totally order the events. Lamport then derived a bound on how far out of the synchrony the clock can become.
We categorise the related work below based on the type of data that they use to investigate the dependencies. Some of the studies use network-level data, some use application-level data, and others utilise both of them. Depending on criteria such as test goals, needs, and systems and resources access level, different methods are followed. Based on the captured data, they extract dependencies between distributed systems or components at different levels of granularities, and, in most cases, build a dependency graph to show the dependencies, their strength and direction of influence.
6.1. Summary
As we can see, the discussed methods try to extract the dependencies between distributed services or components. Some of them use network-level data, which use sending/receiving patterns in a time period, packet header data like (e.g., IP, port, protocol), delay distribution of the traffic, cross-correlation of data, equality of the attributes (key-based correlation) and reference-based correlation. Others leverage application-level data such as application ID and process ID, monitored data (e.g., resource usage, TCP/UDP connection number), and temporal dependency between the execution of systems, which allow them to have a better understanding of the systems’ behaviour and their dependencies.
The existing approaches try to extract simple explicit dependencies (i.e., dependencies between services with their direct traffic between them). Latent dependencies (where the dependencies cannot be identified at first glance and need mathematical calculation to discover) and implicit dependencies (data dependencies between distributed services without access to their traffic or through their traffic with other services) have only been covered in a very limited sense. For example, Oliner et al. [37] extracted part of latent dependencies using cross-correlation, but their effort only considers linear dependencies for the services that communicate directly in terms of sending and receiving messages. In general, each existing method tries to discover only one part of the simple dependencies in the real service’s traffic. Little attention has been paid to the selection of multiple and complex dependency functions that can identify latent dependencies or a combination of several dependencies. A major focus in existing service dependency discovery efforts has been on how to identify data-dependent services rather than incorporating their effects on the system’s behaviour. In general, there remains a need for efficient and systematic approaches that can cover all types of data dependencies between services and their mutual impacts on each other.
This entry is adapted from the peer-reviewed paper 10.3390/app11052381
References
- Humble, J.; Farley, D. Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation; Pearson Education: Boston, MA, USA, 2010.
- Mackinnon, T.; Freeman, S.; Craig, P. Endo-testing: Unit testing with mock objects. In Extreme Programming Examined; Succi, G., Marchesi, M., Eds.; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 2001; pp. 287–301.
- Spadini, D.; Aniche, M.; Bruntink, M.; Bacchelli, A. To Mock or Not to Mock? An Empirical Study on Mocking Practices. In Proceedings of the 14th International Conference on Mining Software Repositories, Buenos Aires, Argentina, 20–21 May 2017; pp. 402–412.
- Li, P. Selecting and using virtualization solutions: Our experiences with VMware and VirtualBox. J. Comput. Sci. Coll. 2010, 25, 11–17.
- Merkel, D. Docker: Lightweight linux containers for consistent development and deployment. Linux J. 2014, 2014, 2.
- Hine, C.; Schneider, J.G.; Han, J.; Versteeg, S. Scalable Emulation of Enterprise Systems. In Proceedings of the 20th Australian Software Engineering Conference (ASWEC 2009), Gold Coast, Australia, 14–17 April 2009; Fidge, C., Ed.; IEEE Computer Society Press: Gold Coast, Australia, 2009; pp. 142–151.
- Hine, C. Emulating Enterprise Software Environments. Ph.D. Thesis, Faculty of Science, Engineering and Technology, Swinburne University of Technology, Melbourne, Australia, 2012.
- Michelsen, J.; English, J. What is service virtualization? In Service Virtualization; Springer: New York, NY, USA, 2012; pp. 27–35.
- Orebaugh, A.; Ramirez, G.; Beale, J. Wireshark & Ethereal Network Protocol Analyzer Toolkit; Elsevier: Amsterdam, The Netherlands, 2006.
- Kabir, M.A.; Han, J.; Hossain, M.A.; Versteeg, S. SpecMiner: Heuristic-based mining of service behavioral models from interaction traces. Future Gener. Comput. Syst. 2020, 117, 59–71.
- Du, M.; Schneider, J.G.; Hine, C.; Grundy, J.; Versteeg, S. Generating service models by trace subsequence substitution. In Proceedings of the 9th international ACM Sigsoft Conference on Quality of Software Architectures, Vancouver, BC, Canada, 17–21 June 2013; Koziolek, A., Nord, R., Eds.; ACM: Vancouver, BC, Canada, 2013; pp. 123–132.
- Versteeg, S.; Du, M.; Schneider, J.G.; Grundy, J.; Han, J.; Goyal, M. Opaque Service Virtualisation: A Practical Tool for Emulating Endpoint Systems. In Proceedings of the 2016 IEEE/ACM 38th International Conference on Software Engineering Companion (ICSE-C), Austin, TX, USA, 14–22 May 2016; pp. 202–211.
- Enişer, H.F.; Sen, A. Testing service oriented architectures using stateful service visualization via machine learning. In Proceedings of the 13th International Workshop on Automation of Software Test, Gothenburg, Sweden, 28–29 May 2018; ACM: Gothenburg, Sweden, 2018; pp. 9–15.
- Farahmandpour, Z.; Seyedmahmoudian, M.; Stojcevski, A.; Moser, I.; Schneider, J.G. Cognitive Service Virtualisation: A New Machine Learning-Based Virtualisation to Generate Numeric Values. Sensors 2020, 20, 5664.
- Farahmandpour, Z.; Seyedmahmoudian, M.; Stojcevski, A. New Service Virtualisation Approach to Generate the Categorical Fields in the Service Response. Sensors 2020, 20, 6776.
- Du, M. Opaque Response Generation Enabling Automatic Creation of Virtual Services for Service Virtualisation. Ph.D. Thesis, Faculty of Science, Engineering and Technology, Swinburne University of Technology, Melbourne, Australia, 2016.
- Du, M.; Versteeg, S.; Schneider, J.G.; Grundy, J.C.; Han, J. From Network Traces to System Responses: Opaquely Emulating Software Services. arXiv 2015, arXiv:1510.01421.
- Du, M.; Versteeg, S.; Schneider, J.G.; Han, J.; Grundy, J. Interaction Traces Mining for Efficient System Responses Generation. SIGSOFT Softw. Eng. Notes 2015, 40, 1–8.
- Cui, W.; Paxson, V.; Weaver, N.; Katz, R.H. Protocol-Independent Adaptive Replay of Application Dialog; NDSS: San Diego, CA, USA, 2006.
- Comparetti, P.M.; Wondracek, G.; Kruegel, C.; Kirda, E. Prospex: Protocol Specification Extraction. In Proceedings of the 2009 30th IEEE Symposium on Security and Privacy, Oakland, CA, USA, 17–20 May 2009; pp. 110–125.
- Cui, W.; Kannan, J.; Wang, H.J. Discoverer: Automatic Protocol Reverse Engineering from Network Traces. In Proceedings of the USENIX Security Symposium, Boston, MA, USA, 6–10 August 2007; pp. 1–14.
- Leita., C.; Mermoud, K.; Dacier, M. ScriptGen: An automated script generation tool for Honeyd. In Proceedings of the 21st Annual Computer Security Applications Conference (ACSAC’05), Tucson, Arizona, 5–9 December 2005; pp. 12–214.
- Krueger, T.; Gascon, H.; Krämer, N.; Rieck, K. Learning Stateful Models for Network Honeypots. In Proceedings of the 5th ACM Workshop on Security and Artificial Intelligence, Sheraton Raleigh, NC, USA, 19 October 2012; ACM: New York, NY, USA, 2012; pp. 37–48.
- Small, S.; Mason, J.; Monrose, F.; Provos, N.; Stubblefield, A. To Catch a Predator: A Natural Language Approach for Eliciting Malicious Payloads. In Proceedings of the USENIX Security Symposium, San Jose, CA, USA, 28 July–1 August 2008; pp. 171–184.
- Wang, Y.; Zhang, N.; Wu, Y.m.; Su, B.b. Protocol Specification Inference Based on Keywords Identification. In Advanced Data Mining and Applications; Motoda, H., Wu, Z., Cao, L., Zaiane, O., Yao, M., Wang, W., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 443–454.
- Jiang, J.; Versteeg, S.; Han, J.; Hossain, M.A.; Schneider, J.G.; Farahmandpour, Z. P-Gram: Positional N-Gram for the Clustering of Machine-Generated Messages. IEEE Access 2019, 7, 88504–88516.
- Jiang, J.; Versteeg, S.; Han, J.; Hossain, M.A.; Schneider, J.G. A positional keyword-based approach to inferring fine-grained message formats. Future Gener. Comput. Syst. 2020, 102, 369–381.
- Leita, C.; Dacier, M.; Massicotte, F. Automatic Handling of Protocol Dependencies and Reaction to 0-Day Attacks with ScriptGen Based Honeypots. In Recent Advances in Intrusion Detection; Zamboni, D., Kruegel, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 185–205.
- Trifilò, A.; Burschka, S.; Biersack, E. Traffic to protocol reverse engineering. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–8.
- Antunes, J.A.; Neves, N. Automatically Complementing Protocol Specifications from Network Traces. In Proceedings of the 13th European Workshop on Dependable Computing, Pisa, Italy, 11–12 May 2011; ACM: New York, NY, USA, 2011; pp. 87–92.
- Beschastnikh, I.; Abrahamson, J.; Brun, Y.; Ernst, M.D. Synoptic: Studying Logged Behavior with Inferred Models. In Proceedings of the 19th ACM SIGSOFT Symposium and the 13th European Conference on Foundations of Software Engineering, Szeged, Hungary, 5–9 September 2011; ACM: New York, NY, USA, 2011; pp. 448–451.
- Yang, J.; Evans, D. Dynamically Inferring Temporal Properties. In Proceedings of the 5th ACM SIGPLAN-SIGSOFT Workshop on Program Analysis for Software Tools and Engineering, New York, NY, USA, June 2004; pp. 23–28.
- Lo, D.; Mariani, L.; Pezzè, M. Automatic Steering of Behavioral Model Inference. In Proceedings of the 7th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on the Foundations of Software Engineering, Amsterdam, The Netherlands, 24–28 August 2009; ACM: New York, NY, USA, 2009; pp. 345–354.
- Le, T.D.B.; Le, X.B.D.; Lo, D.; Beschastnikh, I. Synergizing Specification Miners through Model Fissions and Fusions (T). In Proceedings of the 2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), Lincoln, NE, USA, 9–13 November 2015; pp. 115–125.
- Novotny, P.; Ko, B.J.; Wolf, A.L. On-Demand Discovery of Software Service Dependencies in MANETs. IEEE Trans. Netw. Serv. Manag. 2015, 12, 278–292.
- Lamport, L. Time, Clocks, and the Ordering of Events in a Distributed System. Commun. ACM 1978, 21, 558–565.
- Oliner, A.J.; Kulkarni, A.V.; Aiken, A. Using correlated surprise to infer shared influence. In Proceedings of the 2010 IEEE/IFIP International Conference on Dependable Systems Networks (DSN), Chicago, IL, USA, 28 June–1 July 2010; pp. 191–200.