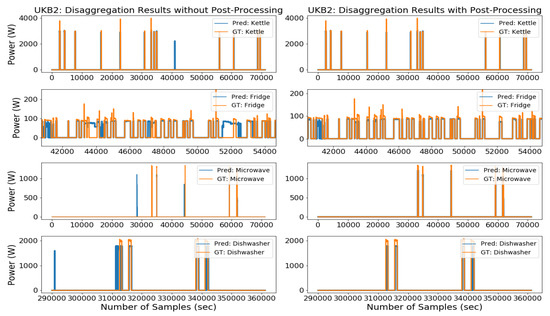
Testing in an Unseen Scenario (Unseen Data from UKDALE House-5)
The generalization capability of our network was tested using unseen data during training. Data used for testing the algorithms was completely unseen for the trained model. In this test case, we used entire house-5 data from the UKDALE dataset for disaggregation and made sure that the testing period contains activations from all target appliances. The UKDALE dataset contains 1-sec and 6-sec sampled mains and sub-metered data, therefore, we up-sampled ground truth data to 1-sec for comparison.
Performance evaluation results of the proposed algorithm with and without post-processing in the unseen scenario are presented in . In the unseen scenario, the post-processed MFS-LSTM algorithm achieved an overall F1-score of 0.746, which was 54% better than without post-processing. Similarly, MAE reduced from 26.90W to 10.33W, SAE reduced from 0.782 to 0.438, and estimation accuracy (EA) improved from 0.609 to 0.781 (28% improvement). When MAE, SAE, and EA scores of the unseen test case were compared with the seen scenario then a visible difference in overall results was observed. One obvious reason for this difference was the different power consumption patterns of house-5 appliances; also, %-NR was higher in house-5 (72%) as compared to the house-2 noise ratio, which was 19%. However, overall results prove that the proposed algorithm can estimate the power consumption of target appliances from the seen house but can also identify appliances from a completely unseen house with unseen appliance activations.
Table 4. Performance evaluation of the proposed algorithm in an unseen scenario based on the UKDALE dataset.
Energy Contributions by Target Appliances
Apart from individual appliance evaluation, it is also necessary to analyze total energy contributions from each target appliance. In this way, we can understand the overall performance of the algorithms when acting as a part of the NILM system. This information is helpful to analyze algorithm performance on estimating power consumption of composite appliances for a given period and how it is closely related to actual aggregated power consumption.
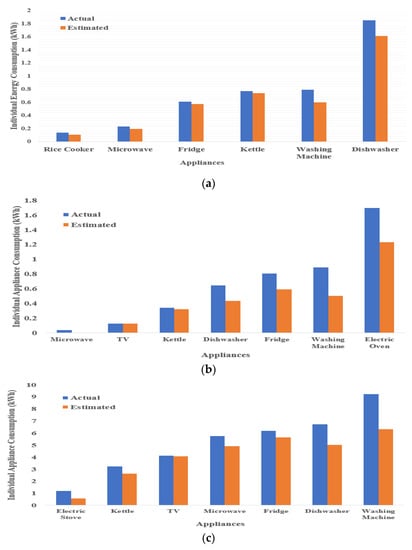
shows energy contributions from all target appliances in both seen and unseen test cases from the UKDALE and ECO datasets. The first thing to notice from is the amount of estimated power consumption, which is less than actual power consumption in both datasets. This happened because of the elimination of irrelevant activations which caused extra predicted energy. Another useful insight is the difference between the amount of estimated power consumption and actual consumption for type-2 appliances (dishwasher, washing machine, electric oven), which is relatively higher than the type-1 appliances difference. This could have happened due to multiple operational states of type-2 appliances which are very hard to identify as well as their power consumption is also very difficult to estimate by the DNN models. Energy contributions for all target appliances of the ECO dataset () are higher as compared to UKDALE appliances. This is due to the time span during which energy consumption by individual appliances was computed. For the UKDALE dataset, 1-week test data was used for evaluation. Whereas for the ECO dataset, one-month data was used for evaluation. Detailed results for energy consumption evaluation in terms of noise-ratio, percentage of disaggregated energy, and estimation accuracy are shown in .
Figure 9. Energy contributions by individual appliances from (a) UKDALE House-2, (b) UKDALE House-5, (c) ECO House-1 and 2.
Table 5. Details of energy contributions by target appliances in UKDALE and ECO datasets.
As described in
Section 3.3, the noise ratio refers to energy contribution by non-target appliances. In our test cases, total energy contributions by all target appliances in said houses were 80.66%, 27.92%, 16.24%, and 79.49% respectively. Based on the results presented in , our algorithm successfully estimated power consumption of target appliances with an accuracy of 0.891 in UKDALE house-2, 0.886 in UKDALE house-5, 0.900 for ECO house-1, and 0.916 for ECO house-2.
Performance Comparison with State-of-the-Art Disaggregation Algorithms
We compared the performance of our proposed MFS-LSTM algorithm with the neural-LSTM [
31], denoising autoencoder (dAE) algorithm [
32], CNN based sequence-to-sequence algorithm CNN(S-S) [
33], and benchmark implementations of the factorial hidden Markov model (FHMM) algorithm, and the combinatorial optimization (CO) algorithm [
12] from the NILM toolkit [
49]. We chose these algorithms for comparison for various reasons. First, the neural LSTM, dAE, and CNN(S-S) were also evaluated on the UKDALE dataset. Secondly, these algorithms were validated on individual appliance models as we did. Thirdly, [
31,
32,
33] also evaluated their approach on both seen and unseen scenarios. Lastly, recent NILM works [
45,
54,
55] have used these algorithms (CNN(S-S), CNN(S-P), neural-LSTM) to compare their approaches. That is why these three are referred to as benchmark algorithms in the NILM research.
UKDALE house-2 and house-5 data were used to train and test benchmark algorithms for seen and unseen test cases. Four-month data was used for training, whereas 10-day data was used for testing. The min-max scaling method was used to normalize the input data and individual models of five appliances were prepared for comparison. Hardware and software specifications were the same as described in
Section 3.2.
shows training and testing times for the above-mentioned disaggregation algorithms in terms of length of days. Many factors affect the training time of algorithms, including training samples, trainable parameters, hyper-parameters, GPU power, and complexity of the algorithm. Considering these factors, the combinatorial optimization (CO) algorithm has the lowest complexity, thus it is the fastest to execute [
56]. This can also be observed from the training time of the CO algorithm from . The FHMM algorithm was the second-fastest followed by the dAE algorithm. Training time results show that the proposed MFS-LSTM algorithm has faster execution time than the neural-LSTM and CNN(S-S) because of the fewer parameters and relatively simple deep RNN architecture.
Table 6. Computation time comparison between disaggregation algorithms (in seconds).
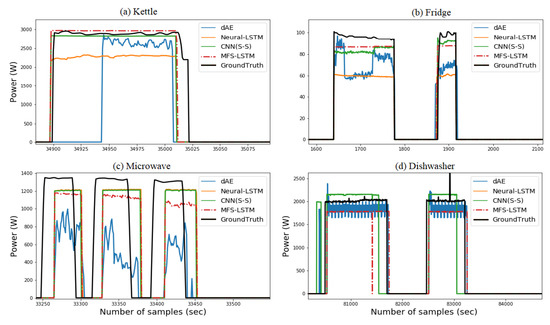
shows the load disaggregation comparison of the MFS-LSTM with dAE, CNN(S-S), and neural-LSTM algorithms in the seen scenario. Qualitative comparison from shows that the MFS-LSTM algorithm disaggregated all target appliances and proved better as compared to the dAE, neural-LSTM, and CNN(S-S) algorithms in terms of power estimation and states estimation accuracy. Although, all algorithms correctly estimated operational states of target appliances. However, the dAE algorithm showed relatively poor power estimation performance for the disaggregating kettle, fridge, and microwave. The CNN(S-S) performance was better for the disaggregating microwave. However, for all other appliances, its performance seemed to be comparative with the MFS-LSTM algorithm. These findings can be better understood through quantitative scores for all algorithms in terms of the F1 score and estimation accuracy as shown in .
Figure 10. Comparison of disaggregation algorithms in the seen scenario based on the UKDALE dataset.
Table 7. Performance evaluation of disaggregation algorithms in the seen scenario.
As shown in , the dAE’s F1 score was lower for the kettle as compared to all other algorithms. The neural-LSTM performed better in terms of the F1 score except for the dishwasher and washing machine. The CNN(S-S) performance remained comparative with the MFS-LSTM for all target appliances. The CO and FHMM algorithms showed lower state estimation accuracy compared to all other algorithms. When overall (average score) performance was considered, the MFS-LSTM achieved an overall F1 score of 0.887, which was 5% better than the CNN(S-S), 31% better than the dAE, and 43% better than the neural-LSTM and 200% better than the CO and FHMM algorithms. Considering the MAE scores, the MFS-LSTM achieved the lowest mean absolute error for all target appliances with an overall score of 5.908 watts. Only the CNN(S-S) scores were a bit close to the MFS-LSTM scores, however, the overall MAE score of the MSF-LSTM was two times less than CNN (S-S), almost four times less than the dAE, and six times less than the neural-LSTM.
Considering SAE scores, our algorithm achieved lowest SAE score of 0.043 for kettle, 0.121 for fridge, and 0.288 for dishwasher. MFS-LSTM algorithm’s consistent scores for all target appliances ensured an overall SAE score of 0.306, which was very competitive with CNN(S-S), Neural-LSTM and dAE. However, overall score of 0.306 was 71.6% lower than CO, and 92.5% lower than FHMM algorithm. When estimation accuracy scores were considered, then dAE power estimation accuracy was higher for fridge and dishwasher, and lower for microwave and washing machine. EA scores for Neural-LSTM algorithm were lower for multi-state appliances. However, MFS-LSTM algorithm achieved an overall estimation accuracy of 0.847 for being consistent in disaggregating all target appliances with high classification and power estimation accuracy.
shows performance evaluation scores for benchmark algorithms in unseen scenario. F1, MAE, SAE, and estimation accuracy scores again proves effectiveness of MFS-LSTM algorithm in unseen scenario compared to benchmark algorithms. Considering F1 score, it can be observed that MFS-LSTM algorithm achieved more than 0.76 score for all target appliances except for microwave. MFS-LSTM achieved an overall score of 0.746, which was 200% better than Neural-LSTM, 27% better than CNN(S-S) and 22% better than dAE algorithm. MAE scores for MFS-LSTM were lower for all target appliances as compared to benchmark algorithms in unseen scenario. Our algorithm achieved an overall score of 10.33 watt, which was six times lower than dAE and CNN(S-S), and seven times lower than Neural-LSTM. Same trend was also observed with SAE scores, in which MFS-LSTM algorithm achieved lowest SAE scores for all target appliances except for microwave. An overall SAE score of 0.438 for MFS-LSTM algorithm was 38% lower than CNN(S-S), 59% lower than CO, 80% lower than FHMM and 87% lower than Neural-LSTM.
Table 8. Performance evaluation of disaggregation algorithms in the unseen scenario.
Estimation accuracy scores were also high for the MFS-LSTM with an overall score of 0.781. One noticeable factor is the difference in scores between the MFS-LSTM and all other algorithms in the unseen scenario. The differences shown prove the superiority of the proposed algorithm in the unseen scenario as well. Considering the noised aggregate power signal, our multi-feature input space-based approach together with post-processing can disaggregate target appliances with high power estimation accuracy as compared to state-of-the-art algorithms.
In accordance with parameters, UKDALE house-2 and house-5 noise ratio was 19.34% and 72.08%, respectively. This implies that total predictable power was 80.66% and 27.92%. In order to estimate the percentage of predicted energy (energy contributions by all target appliances), estimation accuracy scores for all disaggregation algorithms are shown in . Presented results also highlight the proposed algorithm’s superior performance with an estimation accuracy of 0.994 and 0.956 in the seen and unseen test cases, respectively. These results suggest that our proposed algorithm efficiently estimates the power consumption of all target appliances for a given period of time.
Table 9. Evaluation of total energy contributions by target appliances in disaggregation algorithms.