Quantum machine learning has emerged as a promising paradigm that could accelerate machine learning calculations. Inside this field, quantum reinforcement learning aims at designing and building quantum agents that may exchange information with their environment and adapt to it, with the aim of achieving some goal. Different quantum platforms have been considered for quantum machine learning and specifically for quantum reinforcement learning. Here, we review the field of quantum reinforcement learning and its implementation with quantum platforms. This quantum technology may enhance quantum computation and communication, as well as machine learning, via the fruitful marriage between these previously unrelated fields.
- quantum machine learning
- quantum reinforcement learning
- quantum photonics
- quantum technologies
- quantum communication
1. Introduction
The field of quantum machine learning promises to employ quantum systems for accelerating machine learning [1] calculations, as well as employing machine learning techniques to better control quantum systems. In the past few years, several books as well as reviews on this topic have appeared [2,3,4,5,6,7,8].
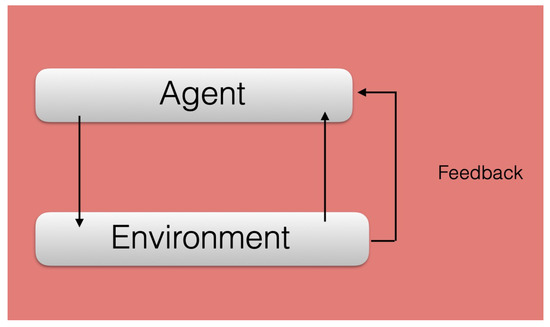
Inside artificial intelligence and machine learning, the area of reinforcement learning designs “intelligent” agents capable of interacting with their outer world, the “environment”, and adapt to it, via reward mechanisms [9], see Figure 1. These agents aim at achieving a final goal that maximizes their long-term rewards. This kind of machine learning protocol is, arguably, the most similar one to the way the human brain learns. The field of quantum machine learning is recently exploring the fruitful combination of reinforcement learning protocols with quantum systems, giving rise to quantum reinforcement learning [10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39].
Different quantum platforms are being considered for the implementation of quantum machine learning. Among them, trapped ions, superconducting circuits, and quantum photonics, seem promising due to the advanced development stage of the technology. In particular, the latter is appropriate because of the good integration with communication networks, information processing at the speed of light, as well as possible realization of quantum computations with integrated photonics [40]. Moreover, in the scenario with a reduced amount of measurements, quantum reinforcement learning with quantum photonics has been shown to perform better than standard quantum tomography [16]. Quantum reinforcement learning with quantum photonics has been proposed [15,17,20] and implemented [16,19] in diverse works. Even before these articles were produced, a pioneering experiment of quantum supervised and unsupervised learning with quantum photonics was carried out [41].
In this topic review, we give an overview of the field of quantum reinforcement learning, focusing mainly on quantum devices employed for reinforcement learning algorithms [10,11,12,13,14,15,16,17,18,19,20], in Section 2.
2. Quantum Reinforcement Learning
The fields of reinforcement learning and quantum technologies have started to merge recently in a novel area, named quantum reinforcement learning [10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,35]. A subset inside this field is composed of articles studying quantum systems that carry out reinforcement learning algorithms, ideally with some speedup [10,11,12,13,14,15,16,17,18,19,20].
In Ref. [10], a pioneer proposal for reinforcement learning using quantum systems was put forward. This employed a Grover-like search algorithm, which could provide a quadratic speedup in the learning process as compared to classical computers [10].
Ref. [11] provided a quantum algorithm for reinforcement learning in which a quantum agent, possessing a quantum processor, can couple classically with a classical environment, obtaining classical information from it. The speedup in this case would come from the quantum processing of the classical information, which could be done faster than with classical computers. This is also based on Grover search, with a corresponding quadratic speedup.
In Ref. [12], a quantum algorithm considers a quantum agent coupled to a quantum oracular environment, attaining a proven speedup with this kind of configuration, which can be exponential in some situations. The quantum algorithm could be applied to diverse kinds of learning, namely reinforcement learning, but also supervised and unsupervised learning.
Refs. [10,11,12] have speedups with respect to classical algorithms. While the first two rely on a polynomial gain due to a Grover-like algorithm, the latter achieves its proven speedup via a quantum oracular environment.
The series of articles in Refs. [13,14,15,16,17,18] study quantum reinforcement learning protocols with basic quantum systems coupled to small quantum environments. These works focus mainly on proposals for implementations [13,14,15,17] as well as experimental realizations in quantum photonics [16] and superconducting circuits [18]. In the theoretical proposals, small few-qubit quantum systems are proposed both for quantum agents and quantum environments. In Ref. [13], the aim of the agent is to achieve a final state which cannot be distinguished from the environment state, even if the latter has to be modified, as it is a single-copy protocol. In order to achieve this goal, measurements are allowed, as well as classical feedback inside the coherence time. Ref. [14] extends the previous protocol to the case in which measurements are not considered, but instead further ancillary qubits coupled via entangling gates to agent and environment are employed, and later on disregarded. In Ref. [15], several identical copies of the environment state are considered, such that the agent, via trial and error, or, equivalently, a balance between exploration and exploitation, iteratively approaches the environment state. This proposal was carried out in a quantum photonics experiment [16] as well as with superconducting circuits [18]. In Ref. [17], a further extension of Ref. [15] to operator estimation, instead of state estimation, was proposed and analyzed.
Ref. [16] obtained a speedup as well with respect to standard quantum tomography, in the scenario with a reduced amount of resources, in the sense of reduced number of measurements.
Finally, Ref. [20] considered different paradigms of learning inside a reinforcement learning framework, which included projective simulation [42] and a possible implementation with quantum photonics devices. The latter, with high-repetition rates, high-bandwith and low crosstalks, as well as the possibility to propagate to long distances, makes this quantum platform an attractive one for this kind of protocol.
This entry is adapted from the peer-reviewed paper 10.3390/photonics8020033