Paddy rice is a staple food of three billion people in the world. Timely and accurate estimation of the paddy rice planting area and paddy rice yield can provide valuable information for the gov-ernment, planners and decision makers to formulate policies.
- : optical remote sensing
- microwave remote sensing
Note: The following contents are extract from your paper. The entry will be online only after author check and submit it.
1. Introduction
Paddy rice, as a major staple food, feeds almost half the world’s population [1]. As the population grows, the demand for food grows. In terms of water use, about one-quarter to one-third of the world’s freshwater resources are used for paddy rice irrigation [2]. Paddy rice fields are a major source of methane (CH4) emissions [3]. Globally, methane (CH4) emissions from paddy rice account for more than 10% of the total amount of CH4 in the atmosphere [4]. Methane is the second most abundant greenhouse gas after carbon dioxide [5]. Paddy rice fields serve as habitats for birds, ducks, and other species, which are the origin of highly pathogenic avian influenza [6]. Therefore, the development of paddy rice distribution maps is of great significance for understanding and assessing the environmental conditions of food security, climate change, disease transmission and water use at regional, national and global levels [7].
An in-depth understanding of paddy rice cultivation and physiology is the premise of paddy rice mapping. The general physical characteristics of different crops are different, and the characteristics of paddy rice at different growth stages are also different. The paddy rice growth period can be divided into four stages [7]: (1) from sowing to transplanting in the nursery stage (~1 month), (2) from the transplanting to the heading stage (1.5 to 3 months), (3) from the heading to the reproductive stage with flowering (~1 month, including start, heading and flowering, stem elongation and panicle development), and (4) from flowering to mature stages at full maturity (~1 month, including milk stage, dough, and ripe grains). The morphology of paddy rice at the main growth stages is shown in Figure 1. Paddy rice is the only crop that needs extensive water during the growing phase and is the only staple that needs transplanting. Therefore, paddy rice can be identified by studying the sensitive spectral bands or indices during the period of water, soil, and vegetation mixing. Temporal variation in water–soil–vegetation composition is a key factor in paddy rice identification.

Figure 1. The example of paddy rice growth stages.
In previous research, some scholars summarized and analyzed the content related to rice mapping. Dong et al. [7] discussed the evolution of rice mapping methods from the 1980s to 2015 and summarized the methods used to characterize each stage and future development trends. Claudia et al. [1] mainly discussed the basic work of rice mapping. Based on a large number of studies, they summarized the characteristics of rice mapping (such as sensors, vegetation index, biomass) and summarized the application fields of different satellite sensors. Mostafa et al. [8] discussed the applicability of remote sensing images to rice area mapping and yield prediction. Methods and limitations of mapping and yield prediction using different remote sensing sensors are briefly described. Niel et al. [9] mainly discussed the current status of the application of remote sensing technology in rice planting areas in Australia, including crop identification, area measurement, and yield prediction.
2. Evolution of Paddy Rice Mapping Methods
Remote sensing platforms can repeatedly observe the Earth’s surface and collect a variety of data, so several remotely based methods have been developed to map paddy rice areas around the world. There are three types of methods based on different data sources. These methods are described in the following sections.
2.1. Optical Remote Sensing-Based Mapping Methods
Optical remote sensing sensors have been used extensively for mapping paddy rice areas around the world. The earliest method of paddy rice monitoring was to extract paddy rice by using remote sensing images and classification methods. Later, with the emergence of the vegetation index, phenological algorithm, cloud computing, and machine learning, the precision of paddy rice mapping based on optical remote sensing was constantly improved.
2.1.1. Machine Learning
Machine learning methods are commonly used methods of rice mapping, including traditional machine learning and deep learning. Traditional machine learning includes supervised and unsupervised classification, such as ISODATA, decision tree (DT), random forest (RF), support vector machine (SVM). The principle of this type of method is to first collect images and sample training data and determine the decision rules to extract rice based on characteristic parameters.
Supervised classification is based on the samples provided by the known training area to obtain feature parameters to establish decision rules. Unsupervised classification obtains feature parameters through computer agglomeration statistical analysis of images to establish decision rules. The latter is an image classification method without a priori classification criteria. The input into the classifier is mainly preprocessed spectral images [13,21]. In recent years, normalized difference vegetation index (NDVI) temporal curves have also been used as the characteristic parameter for classification [18]. Manjunath et al. [17] used multitemporal SPOT VGT NDVI data for analysis. The ISODATA clustering method is used to distinguish between paddy rice areas and non-paddy rice areas. Then, the auxiliary data set is used to further subdivide the areas. Similarly, Okamoto et al. [13] used this method to extract paddy rice fields in Heilongjiang. The difference is that this study used Landsat TM/ETM+ as the data source. Gumma et al. used MODIS data products combined with the k-means clustering algorithm to map the paddy rice area. In 2011 and 2015, they used the same method to map paddy rice in different regions [18,19]. The results were relatively good, with a correlation of more than 90% with local statistics. Paddy rice mapping is also carried out using supervised classification methods, such as SVM [20] and RF [21]. The advantage of this method is its strong operability. The basic principles are easy to understand. The difficulty of the supervised method may be the collection of training samples. However, Google Earth’s high-resolution images and the global geo-referenced field photo library (http://eomf.ou.edu/photos/) provide convenience. The disadvantage of this method is that the validity of the image will affect the accuracy of the results. For example, cloudy and foggy areas, broken terrain areas, and mixed pixel problems will affect the results. In addition, the threshold settings in supervised classification and unsupervised classification methods will change according to the study area.
Deep learning performs well in image recognition and signal processing. In optical remote sensing, the CNN method is mainly used. Convolutional neural network (CNN) is well applied in the field of image analysis. In terms of scene classification, the CNN algorithm has higher classification accuracy than traditional algorithms. CNN is composed of several layers with different functions: input layer, convolution layer, pool layer, fully connected layer and output layer. The input layer is used to import training data, and the convolutional layer is used to extract features. The steps of applying this method to rice mapping are as follows: (1) Use the University of California Merced land-use data set, land-use/land-cover (LULC) Map, Google Earth high-resolution images, and field survey data to pretrain the model. (2) Input the original image into the model and output the result. In this step, in addition to the spectral data, NDVI, Land Surface Temperature (LST), and related phenological information can also be imported into the model [22]. Common training outputs classification results. Zhao et al. [23] combined CNN classification results with the results of NDVI under the DT to achieve further classification and output the final classification results.
The accuracy of this method is generally high. The overall accuracy is greater than 93%. The advantage is improved classification of complex surfaces and the broken landscapes. The disadvantage is that complex models require a lot of data for training. If the tagged data are not enough to support the entire training process, the deep learning model will have poor results. Therefore, the correct amount of training data guarantees the reliability and rationality of the training model.
2.1.2. Time Series Similarity Method
A new method that appeared in recent years is the time series similarity method of dynamic time warping (DTW) distance [24,25]. Time series similarity measures are used to describe the characteristics of data changes over time. DTW distance was initially applied to text data matching, speech processing, and visual pattern recognition. The research shows that algorithms based on the nonlinear bending technique can obtain high recognition and matching accuracy. The steps in this method are as follows: first, establish the standard NDVI sequence curve of the paddy rice growth cycle through field sample data, and then determine the threshold based on the DTW distance between the NDVI time series of standard paddy rice growth and the NDVI time series of the pixels to extract the paddy rice field. The principle of the time sequence similarity method based on the DTW distance is as follows:
Suppose two time series, i.e.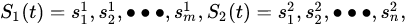
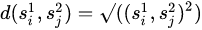
Monotonicity constraint: ,
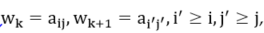
Continuity constraint:
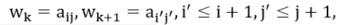
Endpoint constraint: .
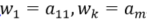
This element satisfies the condition 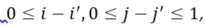
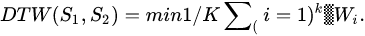
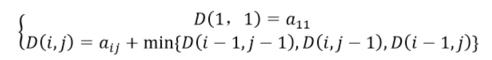 |
(1) |
where i = 2,3.m, j =2,3.n, D (m, n) is the minimum cumulative value of the winding paths.
The DTW distance can reflect the similarity and difference between the standard paddy rice growth NDVI time series and the NDVI time series of a pixel. In the DTW algorithm, when the DTW distance is short, the curve of the NDVI time series shows high similarity. We performed correlation analysis on the NDVI time series and ground truth data to determine the DTW distance threshold for identifying single- and multi-cropping paddy rice. Assuming that the DTW distance of the pixel is greater than the threshold shown, the pixel is unlikely to be paddy rice.
In 2014, Guan et al. [24] extracted rice areas from Southeast Asia and initially explored the applicability of this method in cloudy and rainy areas with good results. In 2018, the same team used this method to extract rice areas in Vietnam, and the results correlated well with statistical data (). This result showed once again the potential of this method for rice mapping in monsoon regions and multiple cropping systems with diverse cultivation processes [25].
The accuracy of this method is good, and the overall accuracy is 83%. The advantage of this method is that it is suitable for cloudy and rainy areas, and the similarity analysis based on DTW distance can solve the overall curve deviation caused by the flexibility of paddy rice planting. This method has good application potential in different crops and different cropping systems. The disadvantages are the determination of the empirical model threshold and the determination of the NDVI standard curve. Affected by the spatial resolution of satellite data, the accuracy of the national scale is high and that of the provincial scale is low.
2.1.3. Vegetation Index Feature-Based Method
The third method is the vegetation index feature-based method. This method can be divided into two categories. One is the features are obtained through mathematical analysis. The threshold formula is established by mathematical analysis of the vegetation index time series curve. The other is the phenology algorithm. The principle is to extract paddy rice, which is grown on flooded soils, based on the unique physical characteristics. NDVI < Land Surface Water Index (LSWI) or Enhanced Vegetation Index (EVI) < LSWI during the flooding period of paddy rice, but the EVI value of other vegetation (non-flooded) is usually greater than the LSWI value.
Mathematical methods include correlation analysis, analysis of variance, and normal distribution. The principle of the correlation analysis method is to extract 100 sample pixels to generate the NDVI time profile curve and calculate the average [26]. Then, the correlation coefficient of 100 pixels is calculated to set the threshold for rice extraction. Then, the symbol test method is used to evaluate the difference between each pair of data from two related samples to compare the significance of the two samples. The variance analysis method uses multitemporal image data to calculate the time series curves of the vegetation index and calculate the standard deviation and variance of the vegetation index in each pixel, and then determines the threshold range by Formula (2). If the pixel value falls within the threshold range, it is determined as a paddy rice pixel [27]. The normal distribution method has the following assumption: the probability distribution function (PDF) of the land cover type follows a normal distribution [28]. We use the mean and standard deviation of each land cover type to define its normal distribution function, and two parameters are obtained from the training data set. The key to correctly distinguishing one specific land cover type is to minimize the overlaps between the target and the neighboring ordinary PDFs. For two land cover types L1 and L2, assuming L1~N(, ) and L2~N(, ), then the intersection between L1 and L2 is calculated by Formula (3).
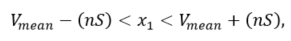 |
(2) |
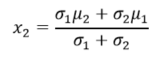 |
(3) |
where , n, S, μ, σ, , and are the average of the variance of the paddy rice field, the maximum distance from the standard deviation, the standard deviation of the variance of the paddy rice field, and the average variance of the image to be classified, the mean of each land cover type, the standard deviation of each land cover type, the intersection between two land cover types. Generally, the two land cover types can be thought separable if is outside of [μ − σ, μ + σ].
Chen used statistical methods to classify double-cropping paddy rice in Taiwan [26]. In addition, this paper also compared the accuracy of different smoothing methods with different NDVI time curves. Studies have shown that classification methods based on empirical mode decomposition (EMD) filtered data produce better classification results than wavelet transform. Nuarsa et al. [27] used the method of variance analysis and MODIS images to extract paddy rice from Bali, Indonesia. The results were good, and the kappa coefficient reached 0.8371. Wang et al. [28] used a normal distribution to process the threshold value of the vegetation index curve for paddy rice extraction in the eastern plains of China. This method was mainly applied to single-season rice. This method is only applied to the key phenological phase images of paddy rice growth. In addition, some studies have used the difference in NDVI during the critical phenology period to define the threshold for paddy rice mapping [12]. Liu et al. [29] proposed a subpixel method that used the relationship between the coefficient of variation (CV) of the LSWI and the planting fraction to estimate the planting fraction of paddy rice. The new method calculated the scale of paddy rice area based on the CV of the LSWI determined for pure water bodies and upland pixels, which can be automatically obtained from the MCD12Q1 land cover product. The overall accuracy was 88%.
The overall accuracy of this method is greater than 85%, and the kappa coefficient is greater than 0.7. The method has the advantages of simple principles and easy operation. The disadvantage is that the applicability of cloudy areas needs to be investigated. Mixed pixels and boundary effects will reduce the classification accuracy. Furthermore, it remains to be studied whether the accuracy of the method will be improved under the conditions of improved image spatial resolution, extended time series, and large-scale research areas.
The use of the phenology algorithm began in approximately 2000. Xiao et al. discovered the characteristics of the vegetation index and conducted paddy rice extraction studies in large areas such as South Asia and central and southern regions [30,31]. The results were good and showed the effectiveness of the phenology algorithm in paddy rice mapping. The previous method has some drawbacks. For example, the critical time window for paddy rice growth is obtained based on a large amount of agricultural phenology data. Incomplete agricultural phenology data in some areas will hinder the implementation of this method.
In recent years, paddy rice mapping methods have been continuously improved. The improvement is reflected in the use of high-resolution data sources, the increase in the complexity of the study area, the study of long-term sequences, and the increase in auxiliary materials (phenology information, other land cover masks, etc.). First, we will discuss high-resolution data sources. Previously, the MOD09A1 MODIS product was mostly used, but it has a spatial resolution of 500 m. For precision agriculture, there will still be mistakes. Subsequent studies used Landsat images and HJ-1A/B with a spatial resolution of 30 m, and Sentinel-2 with a spatial resolution of 10 m [10,11,14,28,33,40]. The accuracy has been further improved. Other studies have considered the issue of temporal resolution. MODIS and Landsat data have been integrated, and these data were then combined with a phenology algorithm for paddy rice mapping [10,32,41]. Second, the complexity of the study area also has an impact. Early studies were mostly concentrated in South Asia and other regions, and summer rainfall was mostly taken into consideration. With the expansion of paddy rice in Northeast Asia, the research area moved northward [14,33,34]. Compared with South Asia, the impact of early spring snowmelt should be considered due to the climate of the northeast region. Some scholars have studied the changes in the area of paddy rice in high temperature disaster areas [35]. Initially, research focused on paddy rice extraction in a specific area in a certain year to verify the accuracy of the algorithm. Subsequent related studies focused on long-term sequence studies to study the expansion of paddy rice fields and changes in the planting area [14,33,36]. Finally, the increase in auxiliary information should also be considered. Some recent studies have attempted to use surface temperature or air temperature to define the time window that defines the temperature that should be reached during the key growing period of paddy rice, effectively excluding the effects of summer rainfall and early spring snow melt on monitoring [10,11,14,33–38]. Other relevant mask data also include cloud cover, snow cover, seasonal water cover, evergreen vegetation, and DEM. The algorithm flow chart is shown in Figure 2. The statistical data brought by the state’s advocacy for refined agriculture have greatly facilitated the extraction of paddy rice. In addition, some studies have used the phenology algorithm to extract the spatial distribution of paddy rice with different planting intensities, which showed the potential of the phenology algorithm in describing two- and three-season paddy rice [39]. Some studies have added the results of field spectrometer measurements on the basis of previous optical remote sensing data to verify the changes in the rice vegetation index curve [32].
The accuracy of rice mapping methods based on phenology is usually high, exceeding 80%. The advantage of this method is that it is suitable for long-term sequence dynamic analysis and large-scale observations. Based on phenological observations, the rice growth period can be accurately identified, reducing the need for data processing work. The principle of the method is simple and operable. The disadvantages of this method include errors in the cloud coverage area, mixed pixel problems, and limited observations over scattered landscapes. The recognition accuracy of clouds is high, but the recognition accuracy of cloud shadows is usually low. Because cloud shadow pixels usually meet the threshold of LSWI–EVI > 0, they may affect paddy rice field mapping. In addition, the inundation of the surface caused by extreme precipitation events can also affect paddy rice mapping [10].
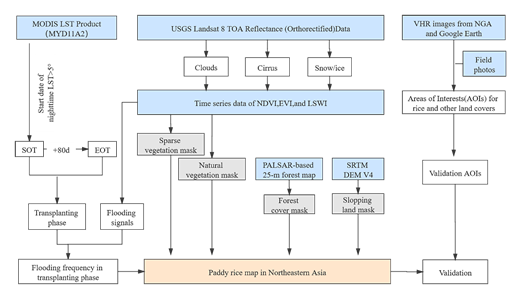
Figure 2. The workflow for phenology and pixel-based paddy rice mapping, major modules include time window determination of the rice transplanting phase (starting point: SOT, ending point: EOT), Landsat data preprocessing, phenology- and pixel-based mapping for non-cropland masks and paddy rice flooding, validation based on the areas of interest (AOIs) from very high-resolution (VHR) images and field photos [33].
2.1.4. Object-Based Image Analysis
There are three key steps of the object-based image analysis method: (1) segmentation of generated image object; (2) determination of features based on feature extraction of objects; and (3) classification (multiple classification methods). Su [42] focused on using phenology to classify paddy rice under the object-based image analysis framework. The main purpose of this framework is to study the applicability of phenology in the localization of paddy rice based on object-based image analysis. The image segmentation is performed using the multiresolution segmentation algorithm in eCognition software. Then it is classified based on the neural network classification method. Singha et al. [43], in order to improve the segmentation quality, improved the fusion criterion on the basis of the commonly used fractal network evolution method, and a new segmentation algorithm was proposed. An unsupervised scale selection method was proposed to determine the optimal scale parameters for image segmentation, and to automate the process of determining scale parameters. After segmentation, geometric, spectral and texture features were extracted and input into the subsequent classification process. Paddy fields and non-paddy fields were classified by a random forest classifier. Zhang et al. [44] also performed image segmentation by using the multiresolution segmentation algorithm in eCognition 9.0 software. The prototype objects were classified by using the random tree (RT) classifier.
The accuracy of this method is generally better than that of other methods. The overall accuracy is over 90%, and the kappa >0.82. The advantages of this method are that geometric information, texture information and spectral information can be used simultaneously to improve the extraction accuracy, and the method analyzes objects by integrating neighborhood information rather than pixels, which will reduce the “salt and pepper” effect when rendering heterogeneous landscapes to classify paddy rice fields more accurately. Object-based image analysis shows advantages in identifying broken paddy rice fields. The disadvantage of this method is that the accuracy of the method is related to the accuracy of data, cloud pollution, spatial resolution, and processing of mixed pixels. In addition, image segmentation is still a challenging problem. Improving the quality of image segmentation is a key factor.
2.2. Microwave Remote Sensing-Based Mapping Methods
The use of a microwave source is a second type of mapping method for paddy rice. The first spaceborne synthetic aperture radar (SAR) sensor for paddy rice mapping used data from the European Remote Sensing Satellite 1 (ERS-1), which showed good results [45]. These groundbreaking studies were often limited to small-scale studies due to a lack of high-quality ground truth images, single polarization, or large data volumes. Subsequent research began to focus on using multiple SAR sensors to improve rice mapping over large land areas, and ERS-1, ERS-2, and RADARSAT were used to test various algorithms. Recent research included RADARSAT-2 data, combined optical and SAR data, object-oriented crop mapping, and Sentinel-1 C-band SAR data. Sentinel-1 satellite data can be obtained freely and openly all over the world, further promoting large-scale rice monitoring operations using radar data.
The main advantage of microwave remote sensing is theoretically the ability to acquire images under any weather conditions, such as cloud cover, rain, snow, and solar irradiance. In most cases, paddy rice cultivation is carried out during the rainy season when overcast and rainy weather prevails. Therefore, the radar image collected by the microwave sensor is an excellent image source for mapping paddy rice areas. In the growth process of paddy rice, the time series change in the radar backscatter coefficient is the key factor to distinguish paddy rice areas. The characteristic of the backscattering coefficient in the growth stage of paddy rice is that in the nutrition and reproduction stage, the backscattering increases continuously until it reaches the maximum at the heading stage. With the development of paddy rice phenology, stems elongate and leaf area, plant water and biomass increase. These changes increase the area available for radar wave reflection, leading to an increase in measured backscatter. After the heading stage, due to plant water, leaf area and biomass begin to decrease, the aforementioned scattering effect is reduced, resulting in a decrease in SAR backscatter. This time backscattering behavior is illustrated in Figure 3, which is based on multiyear advanced synthetic aperture radar (ASAR) wide swath mode (WSM) time series data and shows the SAR backscattering behavior with triple-cropped rice growing stages.
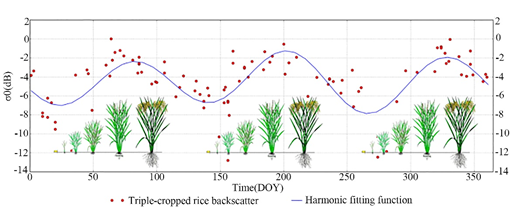
Figure 3. SAR backscatter behavior with triple-cropped rice growing stages based on a multiyear ASAR WSM time series [49].
2.2.1. Empirical Model
The earliest method of applying radar data to paddy rice mapping was to observe the changes in the backscattering coefficient during the paddy rice growth cycle to establish an empirical model. The principle of this method is to establish a mathematical formula based on the change in the backscattering coefficient during the paddy rice growth cycle, determine the threshold, coefficient and other parameters, and extract and map the paddy rice according to the parameters. In 2001, Shao et al. [46] investigated the backscattering behavior of paddy rice throughout the growth cycle, and paddy rice monitoring and extraction were carried out according to its characteristics. An empirical model of the paddy rice growth cycle and backscattering coefficient was established with an accuracy of 91%. However, the disadvantage of this method is that it has a single channel and a fixed angle of incidence. It is difficult to estimate multiple parameters for a target, and the target recognition ability needs to be strengthened.
In the past few years, with the advancement of algorithms and the diversity of data, empirical models have also been developed. In 2011, Bouvet used multitrack wide-swath data sets combined with former methods, using temporal backscatter changes as a classification feature for mapping. Compared with the previously used single-track narrow-swath data sets, this method can significantly increase the observation frequency and the size of the mapping areas [47]. The disadvantage is that the establishment of the empirical model must use the existing detailed land cover data to establish the equation and determine the classification threshold. When no ground information is available, the values in the previous literature are used, and there will be errors.
Radar data contain band information of different frequencies, and most previous methods have used C-band information. In 2018, Hoa et al. [48] used COSMO-SkyMed X-band SAR data to analyze the changes in the SAR intensity over time for short- and long-period paddy rice varieties and field seeding periods in the Anjiang region of the Mekong Delta. First, based on the survey data, a comprehensive analysis of the characteristics and cultivation techniques of paddy rice crops in the region was carried out. Then they analyzed the differences of backscattering intensity between paddy rice and other land cover types in this area under vertical transmission/vertical receive (VV), horizontal transmission/horizontal receive (HH) and HH/VV, and obtained indicators closely related to paddy rice mapping. Paddy rice fields were distinguished from other LULCs, and indicators derived from HH polarization could be used to map other LULCs (water, forests, and built-up areas). These maps can be used as auxiliary data to improve the accuracy of the results. The results showed that, due to the vertical structure of the paddy rice plants, this ratio was a good indicator for paddy rice field mapping. Vertically polarized waves are more attenuated than horizontally polarized waves, so the ratio of the backscattered intensity of HH and VV is higher over paddy rice than most other land cover types. The accuracy of the paddy rice planting area has been found to be as high as 92%. However, for provincial and national surveying and mapping, the coverage of satellite data sources is a limitation. In this case, this method is more suitable for large coverage data with frequent repetition cycles.
The advantage of this method is that the idea is relatively simple, and the threshold can be developed for analysis and extraction after determining the threshold according to the data extraction features of the long-term sequence. The disadvantage is that this method depends on long-term observation data and is limited by data availability. The temporal resolution must meet the needs of the paddy rice growth cycle. On the other hand, there must be accurate prior knowledge in the study area to facilitate the establishment of equations and verification of results. The universality of the method is also limited. The backscattering coefficients of paddy rice will show different characteristics in different regions, and the parameters will change.
2.2.2. Machine Learning
In recent years, the machine learning method has mostly been used for paddy rice mapping based on radar data, which extracts the eigenvalues of the backscatter coefficient and inputs these values into the classifier for paddy rice mapping. Classification models mainly include traditional machine learning models (DT, SVM, RF) and deep learning models such as CNN and recurrent neural network (RNN). There are similar methods based on optical remote sensing data. The principles of these two methods are similar. The difference is the input of the training sample. The former method’s input data include optical images and vegetation index curves. The latter inputs the backscatter coefficient value extracted after radar image processing. Both methods will consider the input of phenology information and texture feature information to improve the accuracy of the results.
In 2015, Nguyen et al. [49] normalized the data collected over many years and multitrack SAR with a statistical method and then classified it through a knowledge-based DT method. This study obtained an overall accuracy of 85.3%, kappa coefficient of 0.74. He et al. [50] used the backscattering coefficient and its combination with phenological information as inputs to the DT classifier for classification, and HH/VV, VV/VH, and HH/VH ratios were found to have the greatest potential for phenology monitoring. The overall accuracy level of 86.2% was obtained in this study. In March 2017, the Sentinel-2 satellite was launched. The following radar data research mostly used Sentinel-2 data as the data source. In 2019, the temporal behavior of the SAR backscattering coefficient over 832 plots containing different crop types was analyzed. Using the derived metrics, paddy rice plots were mapped through two different methods of DT and RF. The overall accuracy is high; the former has an overall accuracy of 96.3%, and the latter is 96.6% [51]. In addition, researchers have done further research on the combination of SAR and deep learning. Wang et al. [55] used crowdsourced data, Sentinel-2 and DigitalGlobe images, and CNN to map crop types with an overall accuracy of 74%. Secondly, we consider the RNN model. The commonly used method in the RNN model is the long short-term memory (LSTM) model and its improvements, such as bidirectional LSTM (Bi-LSTM). Researchers use the model and backscatter coefficient time series data to achieve a paddy rice map. Compared with traditional machine learning models [56–58], the research results show that the overall accuracy of RNN model results is 95%, and the accuracy of deep learning models is better than traditional machine learning models. One point to mention is that different radar polarization methods have different results. In 2016, Hoang and others used SAR to map paddy rice crops in the Mekong Delta [52]. This study used two methods of single polarization, dual polarization and full polarization to map paddy rice, and the classification accuracy increased with the complexity of the polarization method. In 2018, Lasko et al. used a random forest algorithm and Sentinel-1 radar time series images to draw a double-season and single-season paddy rice map of Hanoi, Vietnam, with resolutions of 10 and 20 m, respectively, using VV and VH polarization methods [53]. The overall accuracy of the 10-meter VV and VH polarization was the highest (93.5%). Subsequent research can focus on the comparison of multipolarized SAR data with different frequencies (C, X, L) to obtain the optimal combination.
Moreover, in 2017, Clauss et al. [54] proposed a method of drawing paddy rice planted area maps using Sentinel-1 time series using superpixel segmentation and phenology-based DTs. Superpixel segmentation is the establishment of a spatially averaged backscattering time series, which has the characteristics of robustness to speckles and reduces the amount of data to be processed. However, the classifier depends on the phenology-based empirical thresholds of the research site. If this method is applied to other regions, it is recommended to adapt the threshold parameters.
The advantage of this method is that paddy rice mapping is carried out by means of machine learning, feature extraction is performed using a large amount of data, and the overall accuracy is improved. However, this method relies on the input of training data to determine the parameters, and different regions will result in different parameters. The completeness and diversity of the training data determine the accuracy of this method.
In general, the accuracy of extraction algorithms based on optical remote sensing improves with the improvement of the method and the improvement of data quality. Most of the time series studies focus on annual series changes. The study areas are relatively large, covering the national scale, and these data generally have high spatial resolution. From the original spatial resolution of 500 m to the current spatial resolution of 30 m, it has been continuously improved, and the characteristics of the data are mainly large-scale. The research mainly focuses on the dynamic changes in the paddy rice area and the changes in the centroid of the paddy rice planting in the region. Extraction algorithms based on microwave remote sensing and rice monitoring based on the backscattering coefficient generally have high accuracy, approximately 90%, and the time series are mainly concentrated on the monthly scale. The study area is mostly within the province and city, with a resolution of 10 m, and its largest advantage is the tropics, where cloudy and rainy conditions dominate.
2.3. Integration of Optical and Microwave Remote Sensing-Based Mapping Methods
Optical remote sensing images and microwave data have their respective advantages. To improve the data accuracy, integrated analysis using both methods is essential. The integration methods are mainly the following, and the accuracy of the results is higher than that of a single data source.
2.3.1. Complementary Method
The main principle of this method is to first obtain the rice extraction layer with optical remote sensing or radar data and then supplement the layered data from another data research institute or use these two data sources as the input layer for the classifier for a comprehensive analysis. This method mainly includes the following complementary methods: (Ⅰ) The phenological information is determined based on the optical data. Radar images are collected based on phenological information for rice mapping. (Ⅱ) The optical features of rice and the radar features are input into the classifier together for rice mapping. (Ⅲ) The results are output separately based on the two data sources. The intersection of the two results is treated as the final result.
Using the first type of method, Asilo et al. [59] extracted paddy rice planting information based on MODIS and SAR images, and the results indicated that MODIS can be used to guide SAR image acquisition and planning to a large extent. Torbick et al. [60] conducted a large-scale paddy rice extraction experiment in Myanmar. In this study, Landsat 8 and other data were used to generate a large-scale land cover map, and then the radar image backscatter coefficient was used to create a detailed range of paddy rice masks. Using the second type of method, Mansaray et al. [61] focused on rice extraction in Shanghai, China. By combining the backscatter coefficient of the radar image with the vegetation index, the decision-making classification method was used to extract rice. Tian et al. [62] used the characteristics of the backscattering coefficient and NDVI to enhance image information and combined this information with k-means unsupervised classification to determine the rice area of Poyang Lake in China. Fiorillo et al. [64] used Sentinel1 and Sentinel-2 data to extract rice spectra and backscatter coefficient features in degraded areas, and input them to the RF classifier together. The combination of Sentinel-1 and Sentinel-2 dense time series provided reliable predictors for RF classification, and the results were good. The overall accuracy is greater than 80%. Chen et al. [65] applied this method in a multi-cloud area and used the Google Earth Engine (GEE) platform. Overall accuracy is 66%. In the third type of method, Guo et al. [63] proposed an optical SAR collaborative paddy rice extraction method. The characteristics of rice growth were collected and analyzed under optical images and SAR for classification. Based on the rule that pixels with one of the classification results as rice are classified as rice, a collaborative fusion method was developed. In one area of Australia, the overall accuracy rate reached 94.7%. Ramadhani et al. [16] first extracted rice using Sentinel-1 and -2 and MODIS data, respectively combined with the SVM classification method, and then fused the two results to generate a multitemporal rice map. The advantage of this method is that it combines the advantages of two data sources. This method also effectively avoids the defects of a single data source. To a certain extent, the accuracy of the results has been improved. However, shortcomings still exist. For example, the spectral similarity of different crops is one shortcoming. Both data sources suffer from this problem. Whether data fusion effectively avoids this problem remains to be studied.
2.3.2. Comparison Class Method
The principle of this method is mainly based on different data combination methods, different classification methods, and the results of different regions to obtain the optimal combination of methods for paddy rice extraction. For example, the results of the same data input to different classifiers can be compared, and the results of radar data in different polarization modes combined with the same optical index can also be compared. Comparisons between pixel-based classification and area-based classification have also been conducted.
Onojeghuo et al. [66] took the Sanjiang Plain in northeast China as the research area, utilized NDVI images and dual-polarization (VH/VV) SAR as input data, and used RF and SVM machine learning classification algorithms to perform paddy rice mapping. The results showed that the RF algorithm applied to multitemporal VH polarization and NDVI data produced the highest classification accuracy (96.7%). Zhang et al. [67] first performed image preprocessing on Google Earth Engine (GEE) and combined the pixel-based classification results with object-based segmentation results to output a paddy rice area map. The combination of the two methods eliminated the noise that is common in medium- and high-resolution pixel classification and brought the rice planting area closer to official statistics. As a result, rice maps with a resolution of 10 m were established in Heilongjiang, Hunan and Guangxi provinces of China, with a total accuracy of approximately 90%. In the same year, Yang et al. [68] combined the characteristics of multiple watershed and mountainous areas in Wuhua County, South China, and used region-based and pixel-based methods to map the paddy rice planting area. The results showed that the accuracy of the area-based method was 1.18% higher than that of the pixel-based method (91.38%). The area-based method mainly eliminates the influence of speckle noise. Park et al. [69] classified paddy rice based on different data input combinations (original image, vegetation index, backscatter coefficient) combined with RF and SVM. The results showed that the fusion optics and SAR data had the highest accuracy. In this study, the Paddy Rice Mapping Index (PMI) was established based on the spectral and phenological characteristics of paddy rice, which could be used to extract paddy rice over a large area.
In fact, this kind of method is complementary to the first method. Here, we focus on the comparison between different methods. Researchers can choose the appropriate method according to their own research needs. For the advantages and disadvantages, please refer to the advantages and disadvantages of the first method. There is limited literature on data fusion, and such studies have only appeared in recent years. These studies catered to the development trend of multisource data. Therefore, the problem of how to achieve the best fusion effect will be a focus of future work.
This entry is adapted from the peer-reviewed paper 10.3390/su13020503