With the rapid development of automated vehicles (AVs), more and more demands are proposed towards environmental perception. Among the commonly used sensors, MMW radar plays an important role due to its low cost, adaptability In different weather, and motion detection capability. Radar can provide different data types to satisfy requirements for various levels of autonomous driving. The objective of this study is to present an overview of the state-of-the-art radar-based technologies applied In AVs. Although several published research papers focus on MMW Radars for intelligent vehicles, no general survey on deep learning applied In radar data for autonomous vehicles exists. Therefore, we try to provide related survey In this paper. First, we introduce models and representations from millimeter-wave (MMW) radar data. Secondly, we present radar-based applications used on AVs. For low-level automated driving, radar data have been widely used In advanced driving-assistance systems (ADAS). For high-level automated driving, radar data is used In object detection, object tracking, motion prediction, and self-localization. Finally, we discuss the remaining challenges and future development direction of related studies.
- MMW radar
- autonomous driving
- environmental perception
- self-localization
1. Introduction
At present, the rapid development towards higher-level automated driving is one of the major trends In technology. Autonomous driving is an important direction to improve vehicle performance. Safe, comfortable, and efficient driving can be achieved by using a combination of a variety of different sensors, controllers, actuators, and other devices as well as using a variety of technologies such as environmental perception, high precision self-localization, decision-making, and motion planning. MMW radar, as a common and necessary perceptive sensor on automated vehicles, enables long measuring distance range, low cost, dynamic target detection capacity, and environmental adaptability, which enhances the overall stability, security, and reliability of the vehicle.
Based on the measuring principle and characteristics of millimeter waves, radar perception data has the following advantages compared with other common perceptive sensors such as visual sensors and LIDAR [1]: first, MMW radar has the capability of penetrating fog, smoke, and dust. It has good environmental adaptability to different lighting conditions and weather. Secondly, Long Range Radar (LRR) can detect targets withIn the range of 250 m. This is of great significance to the safe driving of cars. Thirdly, MMW radar can measure targets’ relative velocity (resolution up to 0.1 m/s) according to the Doppler effect, which is very important for motion prediction and driving decision. Due to these characteristics of MMW radar and its low cost, it is an irreplaceable sensor on intelligent vehicles and has been already applied to production cars, especially for advanced driving-assistance systems (ADAS).
However, MMW radar also has some disadvantages [2][3]: first, the angular resolution of radar is relatively low. To improve the angular resolution, the signal bandwidth needs to be increased, which costs more computing resources accordingly. Second, radar measurements lack semantic information which makes it impossible to fully meet perception requirements In high-level automated driving. Third, clutter cannot be completely filtered out of radar measurements, leading to false detections which are hard to eliminate In the subsequent data processing. More detailed comparisons between MMW radar and other on-board sensors are listed In Figure 1.
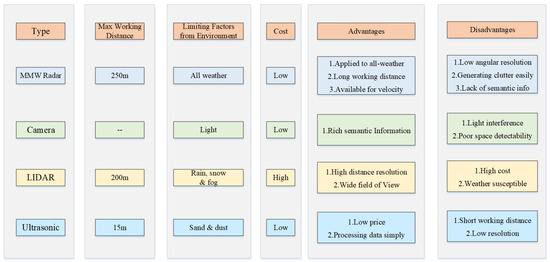
Figure 1. Comparisons of different sensors.
2. MMW Radar Perception Approaches
2.1. Object Detection and Tracking
2.1.1. Radar-Only
In recent years, more and more studies employ diversiform methods to enhance the results of object detection and classification based on MMW radar data [4][5][6]. Researchers chose to process radar data with neural networks or grid-mapping to obtain rich target perception information.
Because the MMW radar point cloud is relatively sparse and objective characteristics are not obvious, using DL methods to realize object detection and classification is very challenging based on this type of data. According to related research works, there are mainly two approaches to solve this problem at present. The first method is using radar-based grid maps determined by the accumulation of multiple frames data. As gridmaps are not quite sparse, they can improve this problem to a certain degree. Then use segmentation networks to process radar-based gridmaps like processing images [7][6][8]. Connected area analysis and convolutional neural network are used in [7]. Then radar grid map can be used to classify static traffic targets (vehicles, buildings, fences) and recognize different orientations of targets represented in grids. Furthermore, the full convolutional neural network (FCN) [9] is used to conduct semantic segmentation for radar OGM, to distinguish vehicles and background information in OGM at pixel level [8]. In the newest research, occupancy grid map, SNR grid map, and height grid map constructed from high-resolution radar are regarded as three different channels, which are sent to semantic segmentation neural network FCN, U-Net [10], SegNet [11], etc., for the segmentation and classification of multiple traffic targets in the environment [6].
However, the segmentation network based on grid maps can only be used to classify static targets and cannot be fully used for the dynamic detection capability of MMW radar. Therefore, In other research works, the second method using DL to process radar data is directly processing the original radar point cloud as LIDAR data is more similar to radar data than images. Furthermore, these studies modify the network to make it more suitable to the density and sampling rate of radar data [4]. In [4], it is mentioned that the modified neural network PointNet++ [12] is used to sample and cluster the radar measurement, while a semantic segmentation network is used to obtain the point cloud level classification results. The data processing flow and segmentation result are displayed in Figure 2. However, the shortcoming is that the detection outputs are not integrated at the object level. In [13], a 2D target vector table determined by radar is used to represent targets around a vehicle and perception accuracy, so as to further detect the parking space adjacent to the vehicle. Besides CNN, RNN network LTSM (Long–Short-Term Memory) is used to classify pedestrians, vehicles, and other traffic targets in [5][14], and can identify categories that have not been seen during the training.
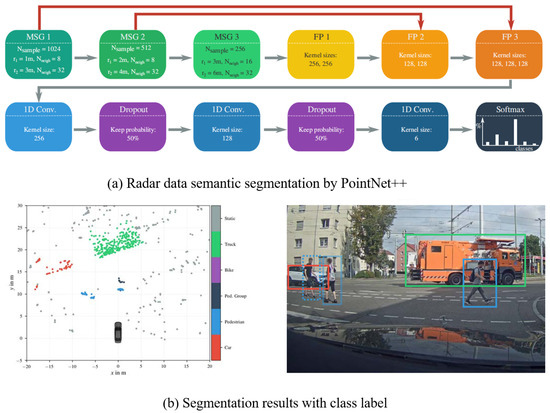
Figure 2. Semantic segmentation on radar point cloud [4].
2.1.2. Sensor Fusion
Object detection and classification is a key aspect of environment perception where MMW radar plays an important role. Complex and dynamic traffic environment requires high accuracy and strong real-time performance of the vehicle perception system [15], especially in highly automated driving. As sensor fusion complements sensors’ advantages to improve the accuracy, real-time performance, and robustness of perception results, plenty of research works focus on multi-sensor information fusion. MMW radar is a common autonomous sensor used for multi-sensor fusion in object detection and tracking.
One common sensor fusion detection solution is combining MMW radar and visual information. It takes advantage of rich semantic information from images as well as position and movement information from radar to improve the confidence of perception results, obtain more detailed environmental information, and build a good foundation for decision-making and control of intelligent vehicles [16]. Radar-vision fusion is mainly divided into data-level fusion and object-level fusion.
For object-level fusion, at first each sensor processes raw measurement separately. For radar, single-sensor data processing is mainly carried out from the perspective of kinematics. For visual data, studies usually adopt machine learning methods to extract Haar features or Hog features [17] and use SVM or Adaboost to identify specific categories of objects [18]. With the development of deep learning, Faster RCNN [19], YOLO [20], and SSD [21] predict object bounding boxes and classification jointly with outstanding accuracy. Therefore, more and more object-level fusion algorithms use deep learning methods for image processing. The perception results of single sensors are then matched and fused to determine the final result [22] to improve the detection confidence and accuracy [23] and realize joint tracking at further steps [24]. Data association is needed to match perception results of different single sensors. Frequently used algorithms for data association include the nearest-neighbor algorithm (NN) [25], probabilistic data association such as joint probabilistic data association (JPDA) [26], and multiple hypothesis tracking (MHT) [27]. Then state filters such as Kalman Filters (KF) [28], Extended Kalman Filters (EKF) [29], and Unscented Kalman Filters (UKF) [30] are commonly applied to solve the problem of multi-sensor multiple object tracking. Bayesian probabilistic reasoning method and the Dempster-Shafer (D-S) theory of evidence [31] are often used to cope with uncertainty and conflicts on detection results from different sensors [32]. Figure 3 shows the overview of object-level fusion. Moreover, these fusion theories are also used for hybrid-level fusion and proved to be effective when tested on real data [33]. In conclusion, object-level fusion framework has a small dependence on single sensor and is robust to single-sensor failure. However, it also has obvious information loss, and fails to take full advantage of sensor data [34].
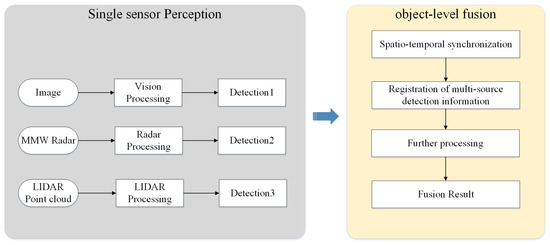
Figure 3. Overview of object-level fusion.
For data-level fusion, the raw information of all sensors is transmitted to a fusion center for centralized data processing. Through joint calibration, the conversion between the spatial relation of the two sensors is established. Radar provides the Region of Interest (ROI) which indicates an object’s location. Then ROIs are projected onto the image space [35]. Then, deep learning [36] or machine learning [37] are used to realize visual object detection and classification. Data-level fusion makes image processing more targeted and improve the algorithm’s efficiency [38]. However, if radar information contains numerous false detections or missed detections, the accuracy of data-level fusion results will be impacted greatly [39]. Moreover, data-level fusion requires high accuracy of spatio-temporal correspondence of multiple sensors and high communication bandwidth [40]. Therefore, the computing load of the centralized fusion center is large, which poses a challenge to the real-time perception. With the development of DL, vision detection algorithms using CNN have achieved excellent performance on the accuracy and efficiency at the same time. The main advantages of classical data-level fusion are gradually replaced, so the subsequent research using machine learning are gradually reduced by deep fusion.
With the development of deep learning and neural networks, deep fusion has become the latest trend of radar-vision fusion. According to different implementation methods, deep fusion of MWR and vision can be divided into two kinds. The first one regards the image coordinate system as the reference coordinate system. According to different object detection frameworks, deep fusion can be divided into two-stage detection [41] and one-stage detection [42]. Figure 4 shows the radar processing procedure of this two kinds of deep fusion.
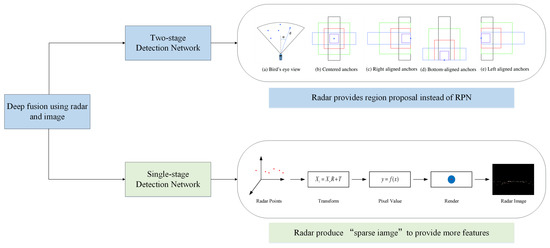
In the two-stage detection, the position of objects provided by radar replaces the role of region proposal network (RPN), and image information is further used to realize the refinement of the candidate area and the classification of objects. In addition, the related algorithm using RPN with Fast RCNN has been proved to be more efficient and accurate than the same backbone with selective search [41].
2.2. Radar-Based Vehicle Self-Localization
For highly automated driving, accurate pose (i.e., position and orientation) estimation in a highly dynamic environment is essential but challenging. Autonomous vehicles commonly rely on satellite-based localization systems to localize globally when driving. However, in some special situations such as near tall buildings or inside tunnels, signal shielding may occur which disturbs satellite visibility. An important compensation method to realize vehicle localization is based on environmental sensing. When a vehicle is driving, sensors record distinctive features along the road called landmarks. These landmarks are stored in a public database, and accurate pose information is obtained through highly precise reference measuring. When a vehicle drives along the same road again, the same sensor builds a local environmental map and extract features from the map. These features are then associated with landmarks and help to estimate the vehicle pose regarding landmarks. The vehicle’s global pose is deduced from the landmarks’ accurate reference pose information. Technologies used in this process include the sensor perception algorithm, environmental map construction, and self-vehicle pose estimation. Meanwhile, as the driving environment changes with time, environment mapping also needs the support of map updating technology [44].
To realize vehicle localization and map updating, different mapping methods are used with different sensors. For ranging sensors, the LIDAR is typically used to represent environmental information in related algorithms due to its high resolution and precision. For vision sensors, feature-based spatial representation methods such as the vector map are usually established which take less memory but more computational cost than the former. Compared with LIDAR and camera, radar-based localization algorithms are less popular because data semantic features provided by radar are not obvious and the point cloud is relatively sparse [45]. Nevertheless, recent research works begin to attach importance to radar-based vehicle self-localization [46][47]. Since radar sensors are indifferent to changing weather, inexpensive, capable of detection through penetrability, and can also provide characteristic information needed by environmental mapping and localization [3]. Thus, radar-based localization is a reliable complementary methods of other localization techniques and the research work is challenging but meaningful [48]. Through multiple radar measurements, a static environment map can be established, and interesting areas can be extracted according to different map types. Then these areas can be matched with landmarks which have been stored in the public database. Finally, the vehicle localization result can be obtained through pose estimation. This process is illustrated in Figure 5. According to the distinction of mapping methods, radar-based localization algorithms are often presented in three kinds: OGM, AGM, and point cloud map. In addition, according to the different map data formats, different association methods and estimation methods can be applied. For OGM, classical SLAM algorithms which use state filters such as EKF and PF are often chosen to realize further data processing. Or we can regard OGM as an intermediate model for features-based spatial expression and combine graph-SLAM with OGM to accomplish feature matching. While using AGM as the map representation, algorithms such as Rough-Cough are applied to match interesting areas with landmarks. As to point cloud map, Cluster-SLAM is proposed to realize localization.
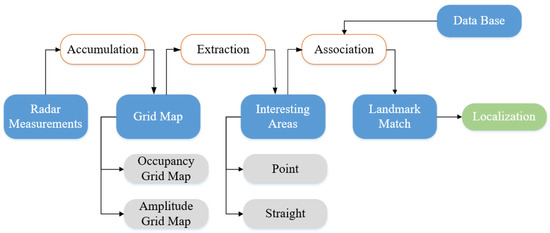
Figure 5. Overview of radar-based vehicle localization.
The most direct method to realize radar-based self-localization is building OGMs and extracting the relevant interested environmental information from OGMs. However, this method is only suitable to establish a static localization system. Some scholars adjust the measurement model to make it adaptable for dynamic detection [49] or track dynamic targets In the process of map construction [50]. These methods only improve the localization of short-term dynamic environment. In [51], through random analysis of interesting area from prior measurements and the semi-Markov chain theory, multiple measurements based on OGMs are unified to the same framework. This approach can improve localization effect when the environment is in long-term change, but still cannot solve the problem of complete SLAM.
3. Conclusions
In summary, in the face of dynamic driving environment and complex weather conditions, MMW radar is an irreplaceable selection among the commonly used autonomous perception sensors. in the field of autonomous driving, many modeling and expressions from radar data have been realized. In addition, various applications or studies have been realized in the fields of active safety, detection and tracking, vehicle self-localization, and HD map updating.
Due to the low resolution and the lack of semantic features, radar-related technologies for object detection and map updating is still insufficient compared with other perception sensors in high autonomous driving. However, radar-based research works have been increasing due to the irreplaceable advantage of the radar sensor. Improving the quality and imaging capability of MMW radar data as well as exploring the radar sensors’ use potentiality makes considerable sense if we wish to get full understanding of the driving environment.
This entry is adapted from the peer-reviewed paper 10.3390/s20247283
References
- Yang, D.; Jiang, K.; Zhao, D.; Yu, C.; Cao, Z.; Xie, S.; Xiao, Z.; Jiao, X.; Wang, S.; Zhang, K. Intelligent and connected vehicles: Current status and future perspectives. Sci. China Technol. Sci. 2018, 61, 1446–1471.
- Dickmann, J.; Klappstein, J.; Hahn, M.; Appenrodt, N.; Bloecher, H.L.; Werber, K.; Sailer, A. Automotive radar the key technology for autonomous driving: From detection and ranging to environmental understanding. In Proceedings of the IEEE Radar Conference (RadarConf), Philadelphia, PA, USA, 1–6 May 2016; pp. 1–6.
- Dickmann, J.; Appenrodt, N.; Bloecher, H.L.; Brenk, C.; Hackbarth, T.; Hahn, M.; Klappstein, J.; Muntzinger, M.; Sailer, A. Radar contribution to highly automated driving. In Proceedings of the 44th European Microwave Conference, Rome, Italy, 6–9 October 2014; pp. 1715–1718.
- Schumann, O.; Hahn, M.; Dickmann, J.; Wöhler, C. Semantic segmentation on radar point clouds. In Proceedings of the 21st International Conference on Information Fusion (FUSION), Cambridge, UK, 10–13 July 2018; pp. 2179–2186.
- Scheiner, N.; Appenrodt, N.; Dickmann, J.; Sick, B. Radar-based road user classification and novelty detection with recurrent neural network ensembles. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 722–729.
- Prophet, R.; Li, G.; Sturm, C.; Vossiek, M. Semantic Segmentation on Automotive Radar Maps. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 756–763.
- Lombacher, J.; Hahn, M.; Dickmann, J.; Wöhler, C. Potential of radar for static object classification using deep learning methods. In Proceedings of the IEEE MTT-S International Conference on Microwaves for Intelligent Mobility (ICMIM), San Diego, CA, USA, 19–20 May 2016; pp. 1–4.
- Lombacher, J.; Laudt, K.; Hahn, M.; Dickmann, J.; Wöhler, C. Semantic radar grids. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 1170–1175.
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440.
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241.
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495.
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets In a metric space. In Proceedings of the Advances in Neural Information Processing Systems(NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108.
- Prophet, R.; Hoffmann, M.; Vossiek, M.; Li, G.; Sturm, C. Parking space detection from a radar based target list. In Proceedings of the 2017 IEEE MTT-S International Conference on Microwaves for Intelligent Mobility (ICMIM), Nagoya, Aichi, Japan, 19–21 March 2017; pp. 91–94.
- Scheiner, N.; Appenrodt, N.; Dickmann, J.; Sick, B. Radar-based feature design and multiclass classification for road user recognition. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 779–786.
- Obst, M.; Hobert, L.; Reisdorf, P. Multi-sensor data fusion for checking plausibility of V2V communications by vision-based multiple-object tracking. In Proceedings of the 2014 IEEE Vehicular Networking Conference (VNC), Paderborn, Germany, 3–5 December 2014; pp. 143–150.
- Kadow, U.; Schneider, G.; Vukotich, A. Radar-vision based vehicle recognition with evolutionary optimized and boosted features. In Proceedings of the 2007 IEEE Intelligent Vehicles Symposium (IV), Istanbul, Turkey, 13–15 June 2007; pp. 749–754.
- Chunmei, M.; Yinong, L.; Ling, Z.; Yue, R.; Ke, W.; Yusheng, L.; Zhoubing, X. Obstacles detection based on millimetre-wave radar and image fusion techniques. In Proceedings of the IET International Conference on Intelligent and Connected Vehicles (ICV), Chongqing, China, 22–23 September 2016.
- Alessandretti, G.; Broggi, A.; Cerri, P. Vehicle and guard rail detection using radar and vision data fusion. IEEE Trans. Intell. Transp. Syst. 2007, 8, 95–105.
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances In Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 91–99.
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788.
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37.
- Chavez-Garcia, R.O.; Burlet, J.; Vu, T.D.; Aycard, O. Frontal object perception using radar and mono-vision. In Proceedings of the 2012 IEEE Intelligent Vehicles Symposium (IV), Alcala de Henares, Spain, 3–7 June 2012; pp. 159–164.
- Garcia, F.; Cerri, P.; Broggi, A.; de la Escalera, A.; Armingol, J.M. Data fusion for overtaking vehicle detection based on radar and optical flow. In Proceedings of the 2012 IEEE Intelligent Vehicles Symposium (IV), Alcala de Henares, Spain, 3–7 June 2012; pp. 494–499.
- Zhong, Z.; Liu, S.; Mathew, M.; Dubey, A. Camera radar fusion for increased reliability In adas applications. Electron. Imaging 2018, 2018, 258.
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27.
- Fortmann, T.; Bar-Shalom, Y.; Scheffe, M. Sonar tracking of multiple targets using joint probabilistic data association. IEEE J. Ocean. Eng. 1983, 8, 173–184.
- Blackman, S.S. Multiple hypothesis tracking for multiple target tracking. IEEE Aerosp. Electron. Syst. Mag. 2004, 19, 5–18.
- Kalman, R.E. A New Approach to Linear Filtering and Prediction Problems. J. Basic Eng. 1960, 82, 35–45.
- Sorenson, H.W. Kalman Filtering: Theory and Application; IEEE: Piscataway, NJ, USA, 1985.
- Julier, S.J.; Uhlmann, J.K. Unscented filtering and nonlinear estimation. Proc. IEEE 2004, 92, 401–422.
- Yager, R.R. On the Dempster-Shafer framework and new combination rules. Inf. Sci. 1987, 41, 93–137.
- Chavez-Garcia, R.O.; Vu, T.D.; Aycard, O.; Tango, F. Fusion framework for moving-object classification. In Proceedings of the 16th International Conference on Information Fusion (FUSION), Istanbul, Turkey, 9–12 July 2013; pp. 1159–1166.
- Chavez-Garcia, R.O.; Aycard, O. Multiple sensor fusion and classification for moving object detection and tracking. IEEE Trans. Intell. Transp. Syst. 2015, 17, 525–534.
- Yu, R.; Li, A.; Morariu, V.I.; Davis, L.S. Visual relationship detection with internal and external linguistic knowledge distillation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1974–1982.
- Kim, H.t.; Song, B. Vehicle recognition based on radar and vision sensor fusion for automatic emergency braking. In Proceedings of the 2013 13th International Conference on Control, Automation and Systems (ICCAS), Gwangju, Korea, 20–23 October 2013; pp. 1342–1346.
- Gaisser, F.; Jonker, P.P. Road user detection with convolutional neural networks: An application to the autonomous shuttle WEpod. In Proceedings of the 2017 Fifteenth IAPR International Conference on Machine Vision Applications (MVA), Toyoda, Japan, 8–12 May 2017; pp. 101–104.
- Kato, T.; Ninomiya, Y.; Masaki, I. An obstacle detection method by fusion of radar and motion stereo. IEEE Trans. Intell. Transp. Syst. 2002, 3, 182–188.
- Sugimoto, S.; Tateda, H.; Takahashi, H.; Okutomi, M. Obstacle detection using millimeter-wave radar and its visualization on image sequence. In Proceedings of the 17th International Conference on Pattern Recognition (ICPR), Cambridge, UK, 26 August 2004; Volume 3, pp. 342–345.
- Bombini, L.; Cerri, P.; Medici, P.; Alessandretti, G. Radar-vision fusion for vehicle detection. In Proceedings of the International Workshop on Intelligent Transportation, Toronto, ON, Canada, 17–20 September 2006; pp. 65–70.
- Wang, X.; Xu, L.; Sun, H.; Xin, J.; Zheng, N. On-road vehicle detection and tracking using MMW radar and monovision fusion. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2075–2084.
- Nabati, R.; Qi, H. RRPN: Radar Region Proposal Network for Object Detection in Autonomous Vehicles. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3093–3097.
- John, V.; Mita, S. RVNet: Deep sensor fusion of monocular camera and radar for image-based obstacle detection In challenging environments. In Proceedings of the Pacific-Rim Symposium on Image and Video Technology (PSIVT), Sydney, Australia, 18–22 November 2019; pp. 351–364.
- Chang, S.; Zhang, Y.; Zhang, F.; Zhao, X.; Huang, S.; Feng, Z.; Wei, Z. Spatial Attention Fusion for Obstacle Detection Using MmWave Radar and Vision Sensor. Sensors 2020, 20, 956.
- Jo, K.; Kim, C.; Sunwoo, M. Simultaneous localization and map change update for the high definition map-based autonomous driving car. Sensors 2018, 18, 3145.
- Xiao, Z.; Yang, D.; Wen, T.; Jiang, K.; Yan, R. Monocular Localization with Vector HD Map (MLVHM): A Low-Cost Method for Commercial IVs. Sensors 2020, 20, 1870.
- Yoneda, K.; Hashimoto, N.; Yanase, R.; Aldibaja, M.; Suganuma, N. Vehicle localization using 76GHz omnidirectional millimeter-wave radar for winter automated driving. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 971–977.
- Holder, M.; Hellwig, S.; Winner, H. Real-time pose graph SLAM based on radar. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1145–1151.
- Adams, M.; Adams, M.D.; Jose, E. Robotic Navigation and Mapping with Radar; Artech House: Norwood, MA, USA, 2012.
- Hahnel, D.; Triebel, R.; Burgard, W.; Thrun, S. Map building with mobile robots In dynamic environments. In Proceedings of the 2003 IEEE International Conference on Robotics and Automation (ICRA), Taipei, Taiwan, 14–19 September 2003; Volume 2, pp. 1557–1563.
- Schreier, M.; Willert, V.; Adamy, J. Grid mapping In dynamic road environments: Classification of dynamic cell hypothesis via tracking. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 3 May–7 June 2014; pp. 3995–4002.
- Rapp, M.; Hahn, M.; Thom, M.; Dickmann, J.; Dietmayer, K. Semi-markov process based localization using radar In dynamic environments. In Proceedings of the IEEE 18th International Conference on Intelligent Transportation Systems (ITSC), Gran Canaria, Spain, 15–18 September 2015; pp. 423–429.