With the rapid development of automated vehicles (AVs), more and more demands are proposed towards environmental perception. Among the commonly used sensors, MMW radar plays an important role due to its low cost, adaptability In different weather, and motion detection capability. Radar can provide different data types to satisfy requirements for various levels of autonomous driving. The objective of this study is to present an overview of the state-of-the-art radar-based technologies applied In AVs. Although several published research papers focus on MMW Radars for intelligent vehicles, no general survey on deep learning applied In radar data for autonomous vehicles exists. Therefore, we try to provide related survey In this paper. First, we introduce models and representations from millimeter-wave (MMW) radar data. Secondly, we present radar-based applications used on AVs. For low-level automated driving, radar data have been widely used In advanced driving-assistance systems (ADAS). For high-level automated driving, radar data is used In object detection, object tracking, motion prediction, and self-localization. Finally, we discuss the remaining challenges and future development direction of related studies.
- MMW radar,autonomous driving,environmental perception,self-localization
1. Introduction
At present, the rapid development towards higher-level automated driving is one of the major trends In technology. Autonomous driving is an important direction to improve vehicle performance. Safe, comfortable, and efficient driving can be achieved by using a combination of a variety of different sensors, controllers, actuators, and other devices as well as using a variety of technologies such as environmental perception, high precision self-localization, decision-making, and motion planning. MMW radar, as a common and necessary perceptive sensor on automated vehicles, enables long measuring distance range, low cost, dynamic target detection capacity, and environmental adaptability, which enhances the overall stability, security, and reliability of the vehicle.
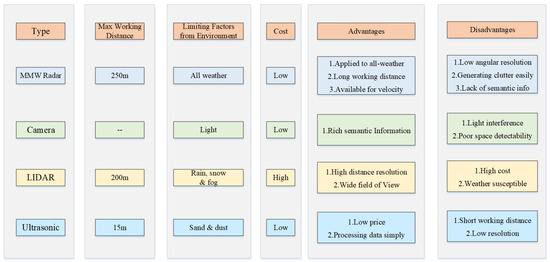
Based on the measuring principle and characteristics of millimeter waves, radar perception data has the following advantages compared with other common perceptive sensors such as visual sensors and LIDAR [1]: first, MMW radar has the capability of penetrating fog, smoke, and dust. It has good environmental adaptability to different lighting conditions and weather. Secondly, Long Range Radar (LRR) can detect targets withIn the range of 250 m. This is of great significance to the safe driving of cars. Thirdly, MMW radar can measure targets’ relative velocity (resolution up to 0.1 m/s) according to the Doppler effect, which is very important for motion prediction and driving decision. Due to these characteristics of MMW radar and its low cost, it is an irreplaceable sensor on intelligent vehicles and has been already applied to production cars, especially for advanced driving-assistance systems (ADAS).
However, MMW radar also has some disadvantages [2,3]: first, the angular resolution of radar is relatively low. To improve the angular resolution, the signal bandwidth needs to be increased, which costs more computing resources accordingly. Second, radar measurements lack semantic information which makes it impossible to fully meet perception requirements In high-level automated driving. Third, clutter cannot be completely filtered out of radar measurements, leading to false detections which are hard to eliminate In the subsequent data processing. More detailed comparisons between MMW radar and other on-board sensors are listed In Figure 1.
2. MMW Radar Perception Approaches
2.1. Object Detection and Tracking
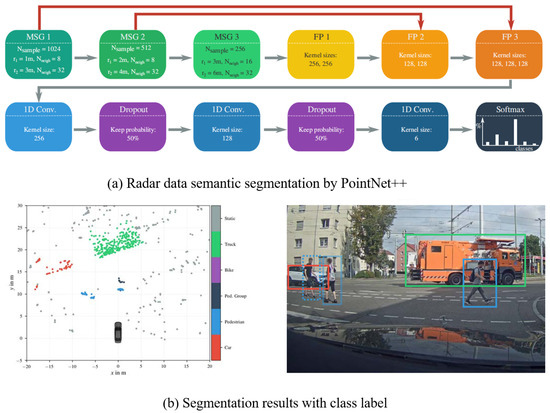
2.1.1. Radar-Only
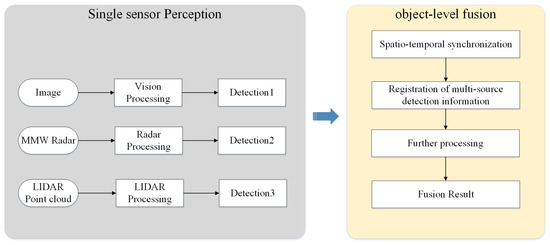
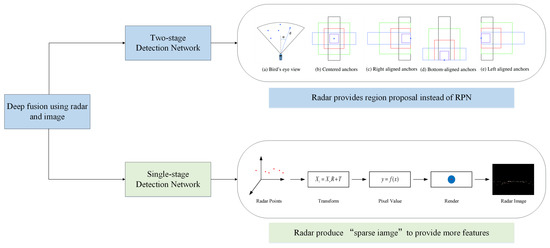
2.1.2. Sensor Fusion
2.2. Radar-Based Vehicle Self-Localization
For highly automated driving, accurate pose (i.e., position and orientation) estimation in a highly dynamic environment is essential but challenging. Autonomous vehicles commonly rely on satellite-based localization systems to localize globally when driving. However, in some special situations such as near tall buildings or inside tunnels, signal shielding may occur which disturbs satellite visibility. An important compensation method to realize vehicle localization is based on environmental sensing. When a vehicle is driving, sensors record distinctive features along the road called landmarks. These landmarks are stored in a public database, and accurate pose information is obtained through highly precise reference measuring. When a vehicle drives along the same road again, the same sensor builds a local environmental map and extract features from the map. These features are then associated with landmarks and help to estimate the vehicle pose regarding landmarks. The vehicle’s global pose is deduced from the landmarks’ accurate reference pose information. Technologies used in this process include the sensor perception algorithm, environmental map construction, and self-vehicle pose estimation. Meanwhile, as the driving environment changes with time, environment mapping also needs the support of map updating technology [81].
To realize vehicle localization and map updating, different mapping methods are used with different sensors. For ranging sensors, the LIDAR is typically used to represent environmental information in related algorithms due to its high resolution and precision. For vision sensors, feature-based spatial representation methods such as the vector map are usually established which take less memory but more computational cost than the former. Compared with LIDAR and camera, radar-based localization algorithms are less popular because data semantic features provided by radar are not obvious and the point cloud is relatively sparse [82]. Nevertheless, recent research works begin to attach importance to radar-based vehicle self-localization [83,84]. Since radar sensors are indifferent to changing weather, inexpensive, capable of detection through penetrability, and can also provide characteristic information needed by environmental mapping and localization [3]. Thus, radar-based localization is a reliable complementary methods of other localization techniques and the research work is challenging but meaningful [85]. Through multiple radar measurements, a static environment map can be established, and interesting areas can be extracted according to different map types. Then these areas can be matched with landmarks which have been stored in the public database. Finally, the vehicle localization result can be obtained through pose estimation. This process is illustrated in Figure 9. According to the distinction of mapping methods, radar-based localization algorithms are often presented in three kinds: OGM, AGM, and point cloud map. In addition, according to the different map data formats, different association methods and estimation methods can be applied. For OGM, classical SLAM algorithms which use state filters such as EKF and PF are often chosen to realize further data processing. Or we can regard OGM as an intermediate model for features-based spatial expression and combine graph-SLAM with OGM to accomplish feature matching. While using AGM as the map representation, algorithms such as Rough-Cough are applied to match interesting areas with landmarks. As to point cloud map, Cluster-SLAM is proposed to realize localization.
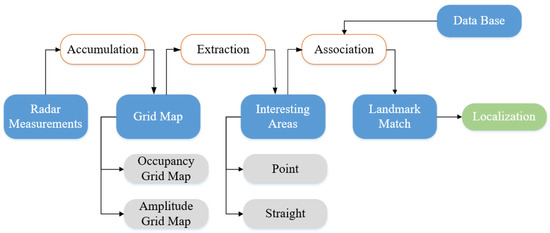
The most direct method to realize radar-based self-localization is building OGMs and extracting the relevant interested environmental information from OGMs. However, this method is only suitable to establish a static localization system. Some scholars adjust the measurement model to make it adaptable for dynamic detection [88] or track dynamic targets In the process of map construction [89]. These methods only improve the localization of short-term dynamic environment. In [17], through random analysis of interesting area from prior measurements and the semi-Markov chain theory, multiple measurements based on OGMs are unified to the same framework. This approach can improve localization effect when the environment is in long-term change, but still cannot solve the problem of complete SLAM.
3. Conclusions
In summary, in the face of dynamic driving environment and complex weather conditions, MMW radar is an irreplaceable selection among the commonly used autonomous perception sensors. in the field of autonomous driving, many modeling and expressions from radar data have been realized. In addition, various applications or studies have been realized in the fields of active safety, detection and tracking, vehicle self-localization, and HD map updating.
Due to the low resolution and the lack of semantic features, radar-related technologies for object detection and map updating is still insufficient compared with other perception sensors in high autonomous driving. However, radar-based research works have been increasing due to the irreplaceable advantage of the radar sensor. Improving the quality and imaging capability of MMW radar data as well as exploring the radar sensors’ use potentiality makes considerable sense if we wish to get full understanding of the driving environment.
This entry is adapted from the peer-reviewed paper 10.3390/s20247283