Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Conventional deep neural networks face challenges in handling the increasing amount of information in real-world scenarios where it is impractical to gather all the training data at once. Incremental learning, also known as continual learning, provides a solution for lightweight and sustainable learning with neural networks.
- incremental learning
- knowledge distillation
- classifier discrepancy
1. Introduction
The advancements in hardware devices and the availability of vast amounts of data have led to improved performance of machine learning techniques across various domains, particularly deep learning. Deep learning has gained significant attention in the academic community. By automatically learning features from a huge amount of data, deep learning reduces the need for independent feature extraction, not only reducing human effort but also enhancing the accuracy and robustness of classification. As a result, research in the field of deep learning has experienced significant growth in recent years, particularly in computer vision [1].
Typically, a deep learning model necessitates an adequate amount of data in each category during training to achieve desirable outcomes. However, real-world data are often dynamic and ever-evolving. As the data volume increases, training a neural network model with the entire dataset becomes computationally intensive and time-consuming, posing challenges in effectively handling such scenarios. If only new data are utilized to update the model, the model may suffer from the issue of forgetting previously acquired knowledge, leading to a decline in performance. This phenomenon is commonly known as “catastrophic forgetting” [2]. As a potential solution to this problem, the concept of incremental learning has emerged.
Incremental learning, also known as lifelong learning or continuous learning, is a deep learning technique aimed at enabling models to effectively process and integrate new information while retaining existing knowledge, mirroring the natural learning process observed in humans. Compared to traditional machine learning approaches, incremental learning offers several advantages. It allows for training with new data at any time, with or without the inclusion of old data, and enables continuous learning based on existing models without the need for complete retraining, resulting in reduced time and computational costs. This approach enhances the model’s ability to adapt to evolving data, ensuring high efficiency and accuracy in dynamic environments, thus closely resembling the learning patterns observed in humans.
The challenge of catastrophic forgetting remains a significant obstacle in incremental learning. Some approaches have explored the utilization of a limited number of samples from old tasks stored in a memory bank to mitigate catastrophic forgetting. However, it should be noted that the loss of the old task dataset or privacy concerns may hinder the successful implementation of these approaches. Another challenge in the context of incremental learning pertains to maintaining the adaptability and accuracy of the model, a phenomenon commonly referred to as the “stability–plasticity dilemma”. The concept of stability in this context relates to the model’s ability to retain the knowledge acquired from previous tasks, while plasticity refers to its capacity to integrate new knowledge effectively. Just as humans face this dilemma when acquiring new knowledge, striking a balance between assimilating new tasks and preserving the essence of previously learned tasks becomes crucial. Finding the equilibrium within this complicated situation presents a significant challenge in the field of incremental learning.
Deep neural networks have demonstrated remarkable performance in the field of computer vision, which has motivated researchers to explore their application in addressing challenges associated with remote sensing images [3][4]. The processing of remote sensing images involves handling large volumes of data, which is a computationally intensive task. Furthermore, certain remote sensing images may contain sensitive data that could potentially become inaccessible over time. Therefore, incremental learning is an alternative approach that continuously adds new data samples to update deep neural networks, gradually learning new knowledge without retraining the entire network.
2. Scenarios of Incremental Learning
To assess a model’s ability for incremental learning, van de Ven et al. [5] proposed three incremental learning scenarios: task-incremental learning (Task-IL), domain-incremental learning (Domain-IL), and class-incremental learning (Class-IL).
In Task-IL, the algorithm gradually learns different tasks. During testing, the algorithm is aware of the specific task it should perform. The model architecture may incorporate task-specific components, such as independent output layers or separate networks, while sharing other parts of the network, such as weights or loss functions, across tasks. Task-IL aims to prevent catastrophic forgetting and explore effective ways to share learned features, optimize efficiency, and leverage information from one task to improve performance in other tasks. This scenario can be compared to learning different sports.
Domain-IL involves a consistent task problem structure with continuously changing input distributions. During testing, the model does not need to infer the task it belongs to but rather focuses on solving the current task at hand. Preventing catastrophic forgetting in Domain-IL remains challenging, and addressing this issue is an important unsolved challenge. An analogy in the real world is adapting to different protocols or driving in various weather conditions [6].
Class-IL requires the model to infer the task it is facing during testing and solve all previously trained tasks. After a series of classification tasks, the model must learn to distinguish all classes. The key challenge in Class-IL lies in effectively learning to differentiate previous classes that have not been observed together in the current task, which poses a significant challenge for deep neural networks [7][8].
3. Approaches of Incremental Learning
Following the research of De Lange et al. [9], the methods for implementing incremental learning are categorized into three main categories: replay methods, parameter isolation methods, and regularization-based methods. Figure 1 illustrates a tree-structured diagram of different incremental learning methods.
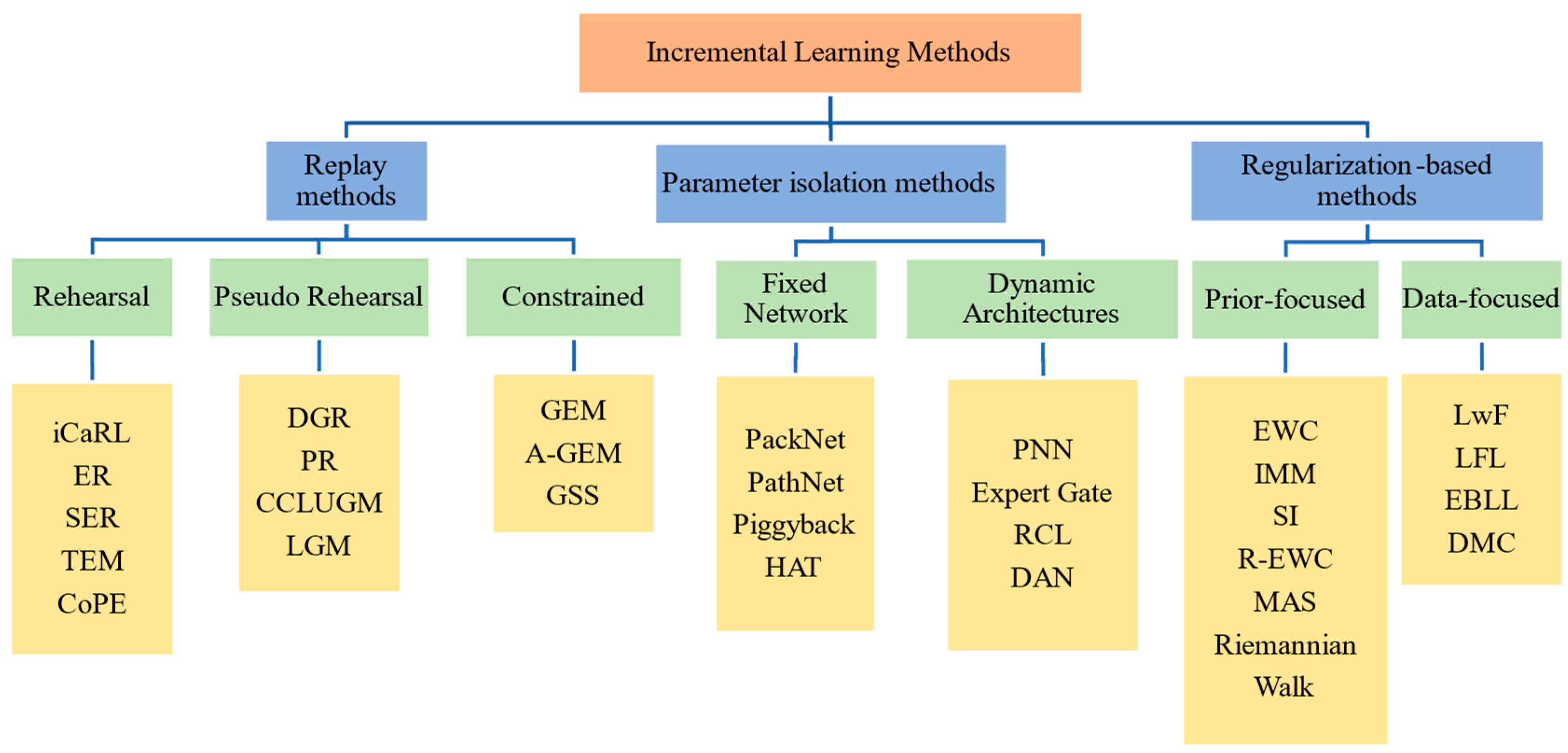
Figure 1. Categories of incremental learning approaches.
Replay methods involve storing samples in their original format or generating virtual samples (pseudo-data) using generative models. These samples from previous tasks are included in the training process to reduce forgetting. Replay methods can be further divided into two strategies. The first strategy is Rehearsal/Pseudo-Rehearsal, which retains a subset of representative samples from previous tasks and utilizes them during the training of new tasks. Representative learning methods, such as iCaRL [10], fall under this category.
To address concerns related to data privacy leakage and overfitting to retain old data, a variation of replay methods called Pseudo-Rehearsal is employed when previous samples are not available. This strategy involves inputting random numbers into a trained model to generate virtual samples that approximate the original sample data. DGR [11], for example, trains a deep generative model “generator” in the framework of generative adversarial networks to generate data similar to past data. However, it should be noted that the results of using the Pseudo-Rehearsal method are generally not as effective as the Rehearsal strategy. Another strategy known as Constrained Optimization restricts the optimization of the new task loss function to prevent interference from old tasks. GEM [12] is a representative algorithm that adopts this approach.
Parameter isolation methods aim to prevent forgetting by allocating different parameters for each task. Some methods within this category involve adding new branches for new tasks while freezing the parameters of old tasks [13] or providing dedicated model copies for each task [14] when the model architecture allows. For parameter isolation methods that maintain a static model architecture, specific portions are allocated to each task. During the training of a new task, the portions associated with previous tasks are masked to prevent parameter updates, thereby preserving the knowledge acquired from previous tasks. Representative methods include the PathNet [15], PackNet [16], and HAT [17].
Regularization-based methods introduce an additional regularization term in the loss function to consolidate previous knowledge when learning new data. These methods prioritize data privacy, reduce memory requirements, and avoid the use of old data for training. Examples of regularization-based methods include Learning without Forgetting (LwF) [18] and Elastic Weight Consolidation (EWC) [19]. LwF leverages the output distribution of the old model as knowledge and transfers it to the training of the new model. EWC calculates the importance of all neural network parameters to limit the degree of change in important parameters.
Among the three methods, the Rehearsal strategy (iCaRL) often outperforms the other two types of methods. This is because the Rehearsal strategy allows for the direct involvement of old data in training, resulting in improved performance. However, it does not fully meet the extreme situation of incremental learning, which demands the exclusion of old data. On the other hand, methods employing the Pseudo-Rehearsal strategy rely heavily on the quality of the generated samples. The overall learning outcomes are significantly compromised and even perform worse than the other two methods with a poor generator.
Although regularization-based methods avoid the use of old data, which aligns more closely with the real-world scenario that incremental learning aims to simulate, they are often vulnerable to domain changes between tasks, particularly when the domains differ significantly. This leads to the persistent problem of catastrophic forgetting. Consequently, many regularization-based methods employ knowledge distillation to retain knowledge from old tasks as much as possible to mitigate the issue of catastrophic forgetting.
4. Knowledge Distillation
To retain the knowledge of previous tasks, regularization-based methods often employ the technique of knowledge distillation (KD). Knowledge distillation is a model compression technique that effectively extracts knowledge from a more complex neural network model to produce a smaller and simpler model that can perform on par with the complex model. This technique has been widely utilized not only in incremental learning but also in various other fields, such as computer vision, natural language processing, speech recognition, and recommendation systems.
The concept of using knowledge distillation to compress models was first introduced by Bucilua et al. [20] in 2006, although no practical implementation was provided. In 2014, Hinton et al. [21] formally defined the term “distillation” and proposed a practical training process. The process involves a teacher–student model framework, where the teacher model is initially trained and then distilled to extract knowledge as teaching materials. This allows the student model to achieve performance comparable to the teacher model. Specifically, the teacher model can be an initial or trained model, while the student model is the model that needs to undergo training. The final output of the entire framework is based on the results obtained from training the student model.
In knowledge distillation, the architecture of the teacher–student relationship serves as a general carrier for knowledge transfer. The quality of knowledge acquisition and distillation from teacher to student is determined by the design of the teacher and student networks. Similar to human learning, students need to find suitable teachers from whom to learn. Therefore, in knowledge distillation, factors such as the type of knowledge, distillation strategy, and the structural relationship between the teacher and student models significantly impact the learning process of the student model. Most knowledge distillation methods utilize the output of a large deep model as knowledge [22][23][24]. Alternatively, some methods employ the activation functions or feature neurons of intermediate layers as knowledge [25][26][27][28].
In a survey conducted by Gou et al. [29], the authors categorized knowledge in knowledge distillation into three types: response-based knowledge, feature-based knowledge, and relation-based knowledge.
Response-based knowledge refers to the output of neurons in the last layer of the teacher model. The aim is to imitate the final predictions of the teacher model. This type of knowledge distillation is widely used in various tasks and applications, such as object detection [30] and semantic landmark localization. However, it has the limitation of relying solely on the output of the last layer, disregarding potential knowledge in hidden layers. Additionally, response-based knowledge distillation is primarily applicable to supervised learning problems.
Feature-based knowledge overcomes the limitation of neglecting hidden layers. In addition to the last layer output, intermediate layers’ output, specifically feature maps, can be utilized to improve the performance of the student model. For example, the Fitnets introduced by Romero et al. [31] adopted such an idea. Inspired by them, other methods have been proposed to match features during the distillation process indirectly [32][33][34]. While feature-based knowledge distillation provides valuable information for student model learning, challenges remain in selecting appropriate layers from the teacher and student models to match the feature representations effectively.
Relation-based knowledge explores relationships between different layers or different data samples, going beyond the specific layer outputs used in response-based and feature-based knowledge. For instance, Liu et al. [35] proposed a method that employs an instance relationship graph, where the knowledge transferred includes instance features, instance relationships, and feature space transformations across layers.
5. Out-of-Distribution Dataset
In the domain of computer vision, numerous studies have extensively explored the incorporation of external datasets to enhance the performance of target tasks. For instance, inductive transfer learning has been employed to transfer and reuse knowledge from labeled out-of-domain samples through external datasets [36][37]. Semisupervised learning approaches [38][39] aim to leverage the utility of unlabeled samples within the same domain, while the self-taught learning approach improves the performance of specific classification tasks using easily obtainable unlabeled data [40].
In a study by Yu et al. [41], auxiliary datasets were applied to unsupervised anomaly detection. The auxiliary dataset consists of unlabeled data, encompassing samples from known categories (referred to as in-distribution or ID samples) as well as datasets that deviate from the target task distribution (known as out-of-distribution (OOD) samples). OOD samples exhibit lower confidence levels, indicating their proximity to the classifier’s decision boundary. These samples are distinguished by analyzing the discrepancies between classifiers. Since OOD samples are not explicitly assigned to ID sample categories or lie far from the ID sample distribution, classifiers with varying parameters become perplexed and produce divergent outcomes. Consequently, OOD samples occupy the “gap” between the decision boundaries, thus enhancing the classifier’s classification performance on ID samples and facilitating the detection of OOD samples.
This entry is adapted from the peer-reviewed paper 10.3390/electronics13030583
References
- Li, J.; Wu, Y.; Zhang, H.; Wang, H. A Novel Unsupervised Segmentation Method of Canopy Images from UAV Based on Hybrid Attention Mechanism. Electronics 2023, 12, 4682.
- McCloskey, M.; Cohen, N.J. Catastrophic interference in connectionist networks: The sequential learning problem. In Psychology of Learning and Motivation; Elsevier: Amsterdam, The Netherlands, 1989; pp. 109–165.
- Devkota, N.; Kim, B.W. Deep Learning-Based Small Target Detection for Satellite–Ground Free Space Optical Communications. Electronics 2023, 12, 4701.
- Ma, S.; Chen, J.; Wu, S.; Li, Y. Landslide Susceptibility Prediction Using Machine Learning Methods: A Case Study of Landslides in the Yinghu Lake Basin in Shaanxi. Sustainability 2023, 15, 15836.
- van de Ven, G.M.; Tuytelaars, T.; Tolias, A.S. Three types of incremental learning. Nat. Mach. Intell. 2022, 4, 1185–1197.
- Mirza, M.J.; Masana, M.; Possegger, H.; Bischof, H. An efficient domain-incremental learning approach to drive in all weather conditions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, New Orleans, LA, USA, 19–20 June 2022.
- von Oswald, J.; Henning, C.; Sacramento, J.; Grewe, B.F. Continual learning with hypernetworks. In Proceedings of the International Conference on Learning Representations, Virtual Conference, 26–30 April 2020.
- Van de Ven, G.M.; Siegelmann, H.T.; Tolias, A.S. Brain-inspired replay for continual learning with artificial neural networks. Nat. Commun. 2020, 11, 4069.
- De Lange, M.; Aljundi, R.; Masana, M.; Parisot, S.; Jia, X.; Leonardis, A.; Slabaugh, G.; Tuytelaars, T. A continual learning survey: Defying forgetting in classification tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3366–3385.
- Rebuffi, S.-A.; Kolesnikov, A.; Sperl, G.; Lampert, C.H. iCaRL: Incremental Classifier and Representation Learning. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017.
- Shin, H.; Lee, J.K.; Kim, J.; Kim, J. Continual learning with deep generative replay. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017.
- Lopez-Paz, D.; Ranzato, M. Gradient episodic memory for continual learning. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017.
- Rusu, A.A.; Rabinowitz, N.C.; Desjardins, G.; Soyer, H.; Kirkpatrick, J.; Kavukcuoglu, K.; Pascanu, R.; Hadsell, R. Progressive neural networks. arXiv 2016, arXiv:1606.04671.
- Xu, J.; Zhu, Z. Reinforced continual learning. In Proceedings of the Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018.
- Fernando, C.; Banarse, D.S.; Blundell, C.; Zwols, Y.; Ha, D.R.; Rusu, A.A.; Pritzel, A.; Wierstra, D. PathNet: Evolution Channels Gradient Descent in Super Neural Networks. arXiv 2017, arXiv:1701.08734.
- Mallya, A.; Lazebnik, S. PackNet: Adding multiple tasks to a single network by iterative pruning. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018.
- Serra, J.; Suris, D.; Miron, M.; Karatzoglou, A. Overcoming catastrophic forgetting with hard attention to the task. In Proceedings of the International Conference on Machine Learning, Vancouver, BC, Canada, 30 April–3 May 2018.
- Li, Z.; Hoiem, D. Learning without forgetting. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2935–2947.
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; GrabskaBarwinska, A.; et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 144, 3521–3526.
- Bucilua, C.; Caruana, R.; Niculescu-Mizil, A. Model compression. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006.
- Hinton, G.; Vinyals, O.; Deans, J. Distilling the knowledge in a neural network. In Proceedings of the NIPS Deep Learning and Representation Learning Workshop, Montréal, QC, Canada, 7–12 December 2015.
- Kim, J.; Park, S.; Kwak, N. Paraphrasing complex network: Network compression via factor transfer. In Proceedings of the Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018.
- Ba, L.J.; Caruana, R. Do Deep nets really need to be deep? In Proceedings of the Neural Information Processing Systems, Montréal, QC, Canada, 8–13 December 2014.
- Mirzadeh, S.I.; Farajtabar, M.; Li, A.; Ghasemzadeh, H. Improved knowledge distillation via teacher assistant. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020.
- Huang, Z.; Wang, N. Like What You Like: Knowledge Distill via Neuron Selectivity Transfer. arXiv 2017, arXiv:1707.01219.
- Ahn, S.; Hu, S.; Damianou, A.; Lawrence, N.D.; Dai, Z. Variational information distillation for knowledge transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019.
- Heo, B.; Lee, M.; Yun, S.; Choi, J.Y. Knowledge transfer via distillation of activation boundaries formed by hidden neurons. In Proceedings of the the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019.
- Zagoruyko, S.; Komodakis, N. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017.
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge Distillation: A Survey. Int. J. Comput. Vis. 2021, 129, 1789–1819.
- Chen, G.; Choi, W.; Yu, X.; Han, T.; Chandraker, M. Learning efficient object detection models with knowledge distillation. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017.
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. FitNets: Hints for thin deep nets. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015.
- Passban, P.; Wu, Y.; Rezagholizadeh, M.; Liu, Q. ALP-KD: Attention-based layer projection for knowledge distillation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021.
- Chen, D.; Mei, J.P.; Zhang, Y.; Wang, C.; Wang, Z.; Feng, Y.; Chen, C. Cross-layer distillation with semantic calibration. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021.
- Wang, X.; Fu, T.; Liao, S.; Wang, S.; Lei, Z.; Mei, T. Exclusivity-consistency regularized knowledge distillation for face recognition. In Proceedings of the european conference on computer vision, Glasgow, UK, 23–28 August 2020.
- Liu, Y.; Cao, J.; Li, B.; Yuan, C.; Hu, W.; Li, Y.; Duan, Y. Knowledge distillation via instance relationship graph. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019.
- Csurka, G. A comprehensive survey on domain adaptation for visual applications. In Domain Adaptation in Computer Vision Applications; Springer: New York, NY, USA, 2017; pp. 1–35.
- Zhang, J.; Liang, C.; Kuo, C.C.J. A fully convolutional tri-branch network (FCTN) for domain adaptation. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018.
- Chapelle, O.; Scholkopf, B.; Zien, A. Semi-supervised learning. IEEE Trans. Neural Netw. 2009, 20, 542.
- Zhu, X. Semi-supervised learning literature survey. In Computer Science; University of Wisconsin-Madison: Madison, WI, USA, 2006; Volume 2, p. 4.
- Raina, R.; Battle, A.; Lee, H.; Packer, B.; Ng, A.Y. Self-taught learning: Transfer learning from unlabeled data. In Proceedings of the 24th International Conference on Machine Learning, Corvallis, OR, USA, 20–24 June 2007.
- Yu, Q.; Aizawa, K. Unsupervised out-of-distribution detection by maximum classifier discrepancy. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019.
This entry is offline, you can click here to edit this entry!