Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Event coreference resolution is the task of clustering event mentions that refer to the same entity or situation in text and performing operations like linking, information completion, and validation. Existing methods model this task as a text similarity problem, focusing solely on semantic information, neglecting key features like event trigger words and subject.
- coreference resolution
- relationship prediction
- universal information extraction
1. Introduction
Event coreference resolution (ECR) is a crucial natural language processing task that involves identifying and clustering together different textual mentions of the same event. The task holds significant importance in enabling a variety of downstream applications, including information extraction, question answering, text summarization, etc. [1,2]. For example, in the application of information extraction, ECR can help to build more coherent and complete knowledge graphs or databases by linking different mentions of the same event and correctly identifying and linking relevant information to answer questions accurately [3]. Figure 1 shows an example of the ECR task, where the input consists of two different segments of text and the output is the binary confidence of event coreference.
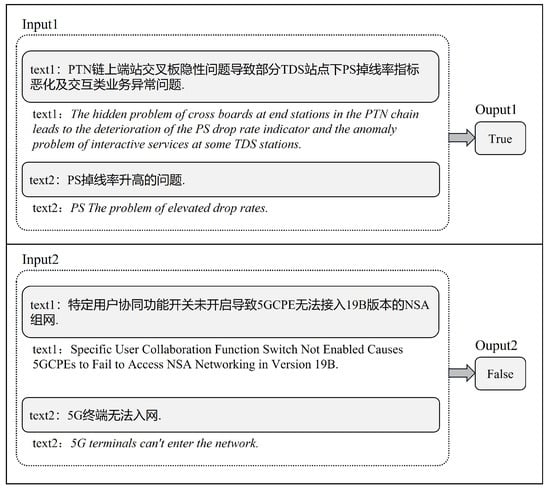
Figure 1. Example illustration of ECR task.
ECR is also an important part of constructing event graphs [4]. The entire process is similar to entity linking in knowledge graphs, where identical event nodes in the real world are clustered together, further improving and supplementing the various components of the event and saving them as a new node in the graph structure. Some researchers have modeled the ECR task as a text similarity calculation problem, using neural networks such as CNN (Convolutional Neural Network) [5] and RNN (Recurrent Neural Network) [6] to represent two pieces of text as vectors and determining whether they are coreferential by calculating the similarity between the vectors. With the emergence of pre-training models such as BERT [7], some researchers have used the output of pre-training models as the vector representation of text and calculated similarity. Others have used Siamese networks [8] to classify event pairs and determine if they are coreferential.
However, training neural networks such as CNN and RNN to represent text as vectors requires training parameters from scratch and is not suitable for small datasets [9]. In contrast, pre-training models only need to be fine-tuned after being pre-trained on a large corpus, which can achieve faster convergence speed when combined with downstream tasks. Additionally, determining event coreference based on whether the similarity reaches a threshold is biased, as there may not be a clear classification boundary for this task, making it difficult to determine the threshold, or there may not be a clear boundary at all. Using BERT for text representation or Siamese networks for text classification also fails to fully utilize the inherent next sentence prediction (NSP). Furthermore, the above techniques only focus on the semantic information of the event description text, ignoring a variety of key features such as event trigger words and event subjects, resulting in missing features.
To address the limitations of existing techniques, we propose a short text event coreference resolution method based on context prediction (referred to ECR-CP). The novelty of ECR-CP is illustrated from three perspectives. In more detail, from a problem-modeling perspective, we model the ECR task as a sentence-level relationship prediction issue by utilizing the NSP inherent in BERT. We consider pairs of events that can form a continuous sentence-level relationship to have coreferential relationships. This is consistent with human language habits, where coherent sentences in everyday conversations often describe the same fact. From a feature extraction perspective, we extract key information such as trigger words, argument roles, event types, and tense from event extraction and incorporate them as auxiliary features to improve the accuracy. From the algorithm performance perspective, BERT-based ECR-CP has a smaller training cost and achieves better performance in comparison to the other benchmark methods based on neural networks.
2. Short Text Event Coreference Resolution
ECR is one of the key subtasks in event extraction and fusion. However, early coreference resolution tasks mainly focused on the entity level. In the domain of entity coreference resolution, Kejriwal et al. [10] proposed an unsupervised algorithm pipeline for learning Disjunctive Normal Form (DNF) blocking schemes on Knowledge Graphs (KGs), as well as structurally heterogeneous tables that may not share a common schema. This approach aims to address entity resolution problems by mapping entities to blocks. Additionally, Šteflovič et al. [11] aim to enhance classifier performance metrics by incorporating the results of entity coreference analysis into the data preparation process for classification tasks.
Due to the complexity of events themselves, as well as a lack of relevant language resources, research on ECR both domestically and abroad started relatively late and has developed more slowly than event extraction techniques. The ACE2005 corpus [12] was the first to add coreference attributes to event information, and in 2015, the Knowledge Base Population (KBP) [13] began related evaluation tasks, laying the foundation for subsequent research.
Early research on ECR was mainly based on rule-based methods [14,15,16,17,18], but with the widespread application of machine learning methods. Recent research has mainly used traditional machine learning and neural network methods to complete ECR tasks [1]. A binary classifier is trained to determine whether two pieces of text refer to the same real-world event, and then coreferential events are optimized by clustering [19]. The differences in various methods mainly lie in the problem modeling, text feature extraction methods, and the internal details of the network model. Depending on whether manual annotation of language resources is required, ECR methods can be divided into three categories: supervised, semi-supervised, and unsupervised learning.
Among them, supervised learning is the earliest and most widely used research approach. For example, Fang et al. [20] designed a multi-layer CNN to extract event features, obtained deep semantic information, and further improved the performance of the coreference resolution algorithm by using multiple attention mechanisms. Dai et al. [21] enhanced the representation of event text features using a Siamese network framework and used the Circle Loss loss function to maximize intra-class event similarity and minimize inter-class event similarity. Liu et al. [22] trained a support vector machine (SVM) classifier based on more than 100 event features to determine whether the events refer to the same entity. Another attempt is made to utilize large amounts of out-of-domain text data.
Due to the high cost of manual annotation, many scholars have attempted to use semi-supervised methods to study ECR tasks. The main idea is to use a small amount of labeled data to construct a learning algorithm to learn data distribution and features, thus completing the labeling of unlabeled samples. For example, Sachan et al. [23] achieved good results on a small-scale training dataset by using active learning to select information-rich instances. Similarly, Chen et al. [24] employed active learning to select informative instances, indicating that only a small number of training sentences need to be annotated to achieve state-of-the-art performance in event coreference. Another attempt is made to utilize large amounts of out-of-domain text data [25].
Unsupervised learning methods completely eliminate the dependence on labeled data and are often probabilistic generative models. For example, Bejan et al. [26] constructed a generative, parameter-free Bayesian model based on hierarchical Dirichlet processes and infinite factorial hidden Markov models to achieve unsupervised ECR task learning. Chen et al. [27] addressed the relatively scarce research on an unsupervised Chinese event coreference resolution task by proposing a generative model. When evaluated on the ACE 2005 corpus, the performance of this model was comparable to that of supervised tasks.
In addition, the differences between various methods also lie in the scoring processing steps of coreference relationships, which can be divided into two models: event-pair models and event-ranking models [28,29]. The event-pair model [30,31,32] is a binary classification model that independently determines whether each event pair refers to the same entity and then aggregates events that refer to each other to form coreferential event clusters. The event-ranking model judges the current event’s coreference with all other candidate events and obtains a ranking result based on the degree of coreference, then divides the events into clusters according to a set threshold 𝜆.
This entry is adapted from the peer-reviewed paper 10.3390/app14020527
This entry is offline, you can click here to edit this entry!