Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Subjects:
Construction & Building Technology
Leveraging natural language processing models using a large volume of text data in the construction safety domain offers a unique opportunity to improve understanding of safety accidents and the ability to learn from them.
- large language model
- generative pre-trained transformer
- fine-tuning
1. Introduction
An unprecedented volume of digital data, approximately 330 million terabytes daily, is now available [1]. Looking ahead to the next two years leading up to 2025, the global production of data is projected to soar beyond 181 zettabytes [2]. A significant portion of this data exists in unstructured forms, encompassing text, images, and videos, making up an estimated 80% of the total [3]. This surge in data presents the challenge of information overload, where the sheer volume surpasses the capabilities for effective processing and analysis [4]. This issue is particularly pronounced for unstructured free-text data, which traditionally relies on human intervention to extract meaningful insights [5]. Therefore, the development of automated techniques for processing natural language text is becoming increasingly vital.
The construction sector is also witnessing a data surge and an increasing emphasis on leveraging written text, particularly within the domain of construction safety through digital accident reports [6,7]. The ability to learn from past accidents, incidents, and near misses holds paramount importance in preventing future injuries [6,8,9,10]. Safety reports, in particular, serve as invaluable resources for safety managers, providing insights into the conditions and events that lead to accidents. This information is crucial for implementing interventions and ensuring positive safety outcomes. Traditionally, all construction-related disasters, including accidents, incidents, and near-misses, have been documented in safety reports using unstructured or semi-structured free-text formats. These reports encompass event descriptions, timing information, and location details [11,12]. However, analyzing accident report data is often laborious and time-consuming, demanding profound understanding of safety to extract meaningful insights [11,13]. The conventional approach involves the manual classification of accident cases, typically undertaken by safety professionals [11,14]. This method requires a meticulous review of detailed textual accident reports to categorize accidents based on various accident-related attributes. Furthermore, beyond consuming substantial resources, manual classification is susceptible to human bias and errors, potentially leading to incomplete or inaccurate analyses.
The advancements in artificial intelligence (AI) now allow for the automated processing, organization, and handling of free-text data, streamlining this analytical process [15]. Specifically, text rule-based, machine, and deep learning approaches have been showing potential in predicting anticipated danger and enhancing the understanding of accident causation. For instance, Zhang et al. [16] developed models aimed at classifying 11 causes of accidents, such as instances of being caught-in-between objects, the collapse of objects, electrocution, exposure to chemical substances, among others, utilizing accident report data and machine learning algorithms. The results of their study demonstrated the average F1 score for 11 causes of accidents was 0.68, showcasing the effectiveness of their proposed ensemble model with optimized weights. Separately, Baker et al. [17] developed machine learning models (e.g., random forest, extreme gradient boosting, and linear support vector machine) to predict four safety outcomes, such as injury severity, injury type, the body part impacted, and accident type. The results showed 84.84% in F1 scores for severity prediction. These studies underscore the significance of leveraging advanced modeling techniques to gain insights into the diverse factors contributing to accidents and improve safety measures. Nevertheless, previous research in this domain has primarily concentrated on the development of traditional machine and deep learning methods. These methods involve the manual extraction of text features, which are subsequently fed into a classifier [11]. These approaches contain several inherent limitations such as limited scalability/generalization, difficulty in analyzing free-from text, high dimensionality, and limited adaptability to new tasks. Although traditional machine/deep learning-based approaches have made significant strides in the natural language processing (NLP) of the construction domain, such limitations must be mitigated by incorporating more generative and powerful AI models [18].
Recently, large language models (LLMs), particularly those built on the transformer architecture, such as the generative pre-trained transformer (GPT), present notable advantages for classification tasks compared to traditional machine learning and deep learning models [19,20]. The transformer’s ability to capture contextual information, employ end-to-end learning without manual feature engineering, utilize attention mechanisms for distinct understanding, and leverage transfer learning for improved performance make it well-suited for tasks that require a comprehension of accident-related text data [21]. Additionally, its adaptability to varied input lengths, multimodal capabilities, and efficient parallelization contribute to its efficacy in handling the complexities of accident classification, marking a significant advancement over more traditional approaches in the field [22]. Despite these potential benefits of LLM, leveraging GPT models is still an explanatory stage in the construction accident domain. Further research and validation are needed to assess the model’s performance, generalizability across diverse accident scenarios, and its interpretability in the context of safety-critical applications. Additionally, addressing domain-specific challenges and tailoring the model to the unique characteristics of construction-related text data via the fine-tuning method is crucial for maximizing the effectiveness of GPT-based approaches in accident classification within the construction industry.
2. Generative Pre-Trained Transformers
The adoption of NLP analysis presents a transformative shift in the realm of construction site safety [23]. NLP, equipped with its ability to sift through extensive textual data, provides a robust framework for uncovering subtle patterns and correlations within accident records [24,25]. This enables stakeholders to access distinctive insights into the fundamental reasons behind accidents, enabling the creation of proactive and specific safety measures to avert the recurrence of similar incidents [26,27]. By leveraging the capabilities of NLP, construction site managers and safety experts can optimize their decision-making processes, bolstering the efficacy of accident analysis and fortifying the overall safety standards within the construction industry [28]. This transition to NLP-driven analysis signifies a progressive stride toward a more data-driven and proactive approach to accident prevention, ultimately fostering a safer working environment for construction personnel and mitigating potential risks associated with complex construction operations.
Specifically, recent developments in NLP have created novel opportunities for the automated examination of textual records related to accidents [17,23,29,30]. By applying NLP techniques, pertinent information can be extracted from unstructured free-text data, enabling an effective categorization of accidents based on various parameters [31]. Numerous studies have emphasized the efficacy of NLP in automating accident classification, resulting in improved efficiency and reduced prejudice. Table 1 presents a summary of the NLP models used in the literature to predict construction accidents. Specifically, Tixier et al. [32] demonstrated analyzing unstructured incident reports utilizing the NLP model, yielding significant results with F1 score values of 0.96, respectively. Similarly, Zhang et al. [16] employed text mining and NLP methods to investigate construction accident reports, utilizing various machine learning models, with the optimized ensemble model showcasing the highest F1 score of 0.68. Cheng et al. [33] introduced the Symbiotic Gated Recurrent Unit for the classification of construction site accidents, achieving an average weighted F1 score of 0.69, outperforming other AI techniques. Additionally, Kim & Chi [34] developed a system for managing construction accident knowledge, demonstrating notable recall, precision, and F1 score values of 0.71, 0.93, and 0.80, respectively.
Table 1. Natural Language Processing and Construction Injury Classification Literature.
| Authors (Year) | Task | Source Data | Text Fields | Outperformed Method | Accuracy |
|---|---|---|---|---|---|
| Tixierc, A.J.P., et al. (2020) [6] | Prediction of 6 incident type, 4 injury type, 6 body part, 2 severity from injury reports | A dataset of 90,000 incident reports from global oil refineries | Title, accident details, detail, root cause |
TF-IDF + SVM | 71.55% |
| Kim, H., Jang, Y., Kang, H. & Yi, J.S. (2022) [35] | Classification of 5 accident case from accident reports | Korea Occupational Safety and Health Agency | Accident case | CNN | 52% |
| Zhang, Jinyue, et al. (2020) [14] | Classification of 11 accident categories from accident reports | Occupational Safety and Health Administration | Accident narratives | BERT | 80% |
| Goh, Y.M. & Ubeynarayana, C.U. (2017) [36] | Classification of 11 labels of accident causes or types from accident reports | Occupational Safety and Health Administration | Accident narratives | SVM | 62% |
| Zhang, Fan, et al. (2019) [16] | Classification of 11 causes of accidents from accident reports | Occupational Safety and Health Administration | Fatality and catastrophe investigation summary reports | Ensemble | 68% |
| Cheng, M.Y., Kusoemo, D. & Gosno, R.A. (2020) [33] | Classification of 11 labels of accident causes or types from accident reports | Occupational Safety and Health Administration | Accident narratives | Hybrid model | 69% |
These research efforts emphasize the importance of employing advanced NLP-based modeling techniques to gain a comprehensive understanding of the various factors influencing accidents and to improve safety protocols. However, as mentioned in the Introduction, current studies have predominantly focused on developing conventional machine and deep learning methods, which entail manually extracting text features and inputting them into a classifier [15,29,36]. These approaches come with inherent limitations, including limited scalability and generalization, difficulties in analyzing free-form text, high dimensionality, and a lack of adaptability to new tasks. While traditional machine and deep learning methods have made strides in NLP within the construction domain, overcoming these limitations requires the incorporation of more innovative, generative, and robust AI models.
Recently, LLMs, particularly those built on the transformer architecture such as GPT, developed by OpenAI, present notable advantages for various NLP tasks, including classification, compared to traditional machine learning and deep learning models [20,37]. These models are trained on vast datasets, enabling them to generate human-like text based on the input they receive. The adaptability and proficiency of GPT models in processing and generating natural language have the potential to significantly impact and facilitate various aspects in diverse fields, ranging from education and customer service to research and industries.
The capacity of GPT to generate text resembling human writing can be attributed to its deployment of the transformer model. The transformer model employed in GPT is depicted in Figure 1. The model employs a decoder structure with 96 repeated layers. These layers allow the model to progressively refine its understanding of the input text, enabling it to generate coherent and contextually relevant outputs [38]. The repeated stacking of decoder layers, coupled with attention mechanisms and residual connections, ensures the model’s proficiency in tasks such as language translation and text generation, particularly classification [39,40]. The transformer demonstrates proficiency in capturing contextual information, implementing end-to-end learning without manual feature engineering, employing attention mechanisms for nuanced comprehension, and leveraging transfer learning to improve performance [41]. These qualities make it well-suited for tasks that require an in-depth understanding of unstructured free-text data pertaining to accidents [21]. Additionally, its adaptability to diverse input lengths, multimodal capabilities, and efficient parallelization collectively contribute to its efficacy in tackling the complexities inherent in accident classification [42]. This marks a significant advancement over traditional approaches in the field, reflecting a substantial progress in the capabilities of NLP models. Despite these potential benefits of LLM, there still exists a knowledge gap on how to better utilize pre-trained GPT models through fine- and hyperparameter-tunings with enhancing explainability for construction accident classification. This research is anticipated to contribute to the expanding knowledge base on NLP applications in safety management, providing practical insights for safety professionals, researchers, and policymakers dedicated to enhancing safety practices within the industry.
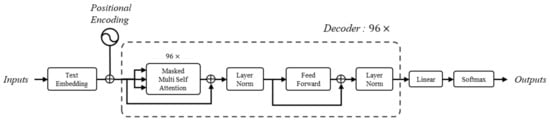
Figure 1. Transformer architecture used in a generative pre-trained transformer.
This entry is adapted from the peer-reviewed paper 10.3390/app14020664
This entry is offline, you can click here to edit this entry!